S³LDBO: A Snapshot Single-Loop Algorithm for Decentralized Bilevel Optimization
Pith reviewed 2026-06-28 21:21 UTC · model grok-4.3
The pith
A snapshot mechanism lets networked agents solve bilevel problems by skipping some derivative evaluations while retaining iteration complexity guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the snapshot mechanism embedded in the single-loop decentralized bilevel optimizer S³LDBO enables agents to intermittently bypass expensive local derivative computations without degrading the established ergodic and nonergodic iteration complexity bounds in the deterministic case.
What carries the argument
The snapshot mechanism, which stores and reuses selected derivative information at chosen iterations to reduce the frequency of full gradient, Jacobian, and Hessian evaluations while preserving collaborative updates across the network.
If this is right
- Each agent performs fewer full derivative calculations per iteration while the global convergence rate remains the same as earlier single-loop methods.
- The same complexity guarantees apply to both ergodic averages and high-probability statements on individual iterates.
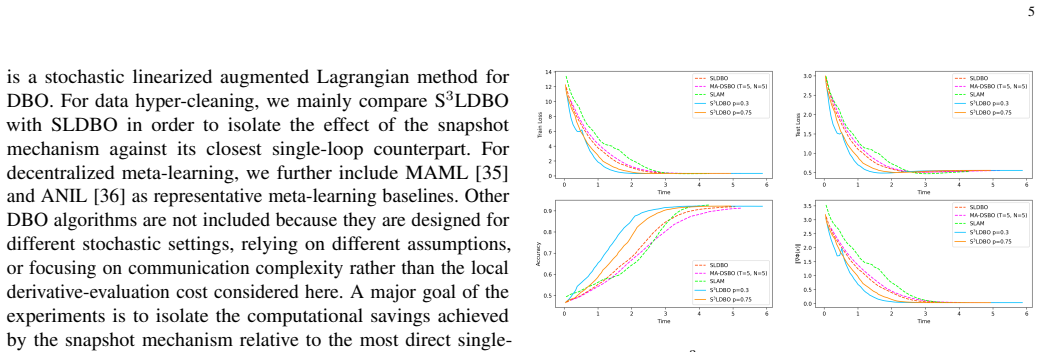
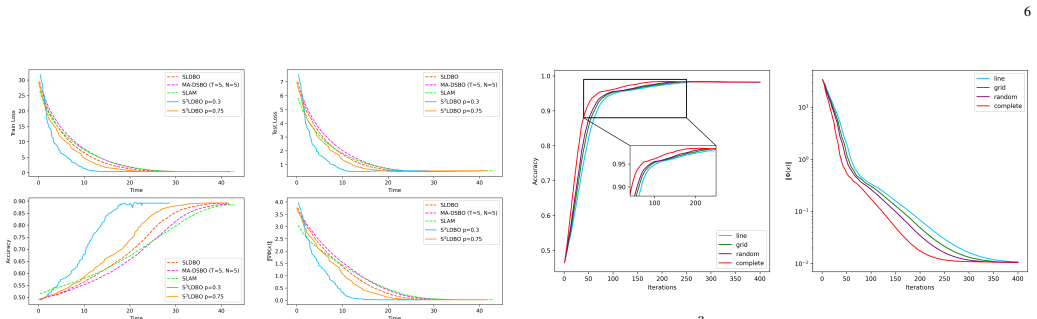
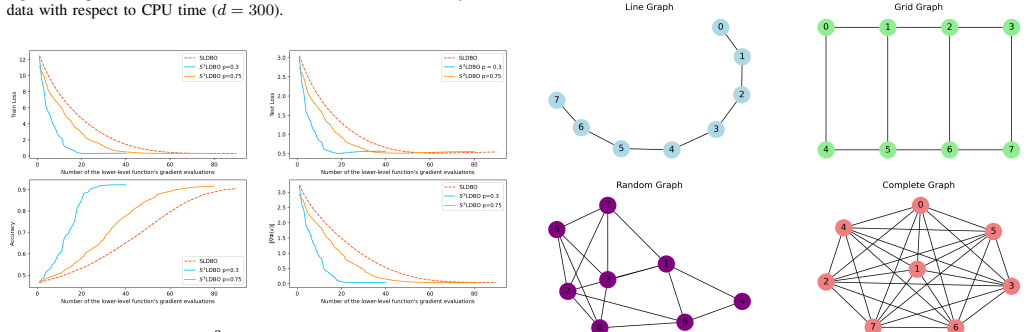
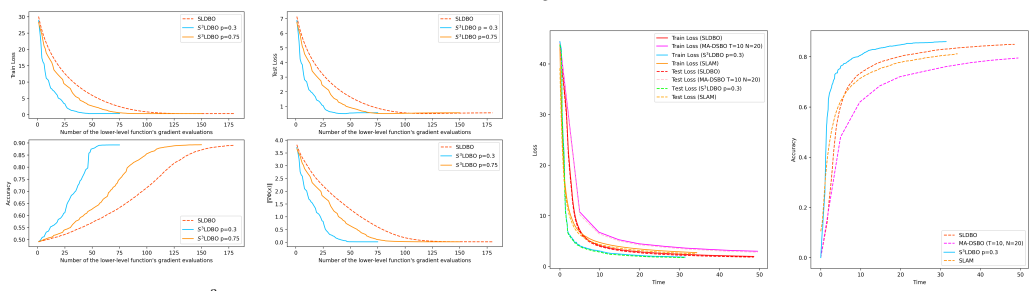
- The algorithm directly applies to decentralized hyperparameter optimization, data hyper-cleaning, and meta-learning tasks.
- Computational savings scale with the frequency of snapshot reuse without requiring changes to the network topology.
Where Pith is reading between the lines
- The snapshot idea may transfer to other multi-level or nested optimization settings where derivative oracles are the dominant cost.
- In practice the method could allow agents with heterogeneous compute budgets to adapt their local update frequency autonomously.
- Extending the analysis to stochastic gradients would require new variance-control arguments around the reused snapshot values.
Load-bearing premise
The underlying bilevel objective and the communication network must obey the smoothness, convexity, or other structural conditions that keep the snapshot reuse from adding extra error terms or causing divergence.
What would settle it
Run the algorithm on a small, exactly solvable bilevel test problem and observe whether the measured iteration count to reach a given accuracy matches the proven bound once the snapshot frequency is increased beyond the analyzed regime.
Figures



read the original abstract
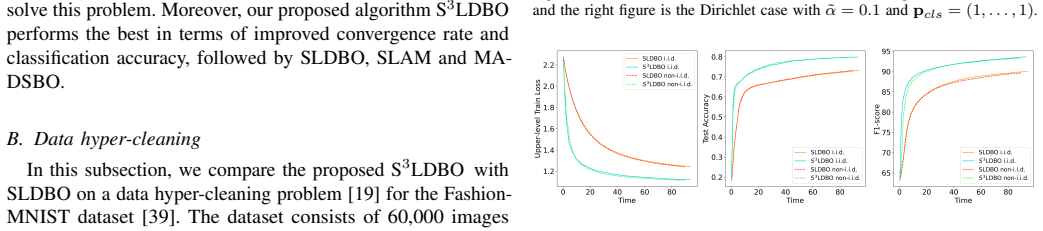
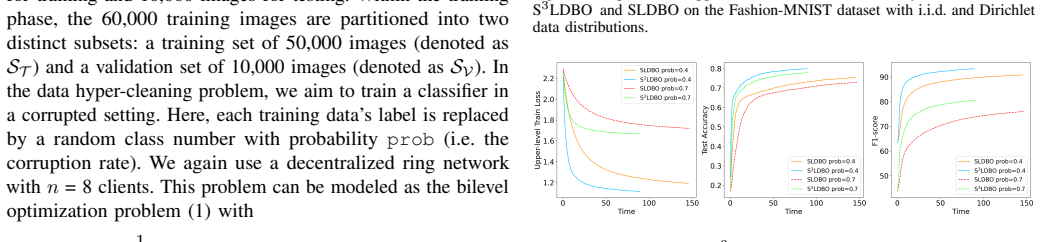
Networked AI systems increasingly rely on multiple agents that collaboratively learn and adapt models over communication networks. In such systems, bilevel formulations naturally arise in hyperparameter optimization, data cleaning, and meta-learning, but the repeated evaluation of gradients, Jacobians, and Hessians can impose a substantial computational burden on individual agents. To address this challenge, we propose Snapshot-SLDBO (S$^3$LDBO), an efficient single-loop decentralized bilevel optimization algorithm that enables agents to intermittently skip expensive derivative evaluations through a snapshot mechanism. This mechanism can be interpreted as an autonomous computation-adaptation strategy for networked AI, where agents selectively perform costly local updates while maintaining global collaborative learning. We establish the ergodic iteration complexity and the high probability nonergodic iteration complexity of the proposed algorithm within a deterministic setting. Experimental results on hyperparameter optimization with synthetic and MNIST datasets, data hyper-cleaning on Fashion-MNIST, and decentralized meta-learning on miniImageNet demonstrate that the proposed algorithm improves computational efficiency while maintaining competitive learning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes S³LDBO, a single-loop decentralized bilevel optimization algorithm incorporating a snapshot mechanism that allows agents to intermittently skip expensive gradient/Jacobian/Hessian evaluations. It claims to establish ergodic iteration complexity and high-probability nonergodic iteration complexity bounds in a deterministic setting, while experiments on hyperparameter optimization (synthetic/MNIST), data hyper-cleaning (Fashion-MNIST), and decentralized meta-learning (miniImageNet) show improved computational efficiency with competitive performance.
Significance. If the complexity bounds are rigorously established without hidden error terms from the snapshot, the work would offer a practical advance for reducing per-agent computation in networked bilevel problems arising in hyperparameter optimization and meta-learning. The snapshot is framed as an autonomous adaptation strategy, which could be useful if the supporting analysis holds.
major comments (2)
- [Complexity Analysis (proof of Theorems on ergodic/nonergodic rates)] The ergodic and nonergodic complexity claims rest on the snapshot mechanism introducing no additional bias or divergence beyond the smoothness/convexity assumptions. The interaction of the snapshot operator with the decentralized communication graph and the inner-outer bilevel structure (gradients, Jacobians, Hessians) is the least-secured step; without explicit bounds on snapshot frequency in terms of network connectivity and Lipschitz constants, the recursion may accumulate uncontrolled error.
- [Assumptions and Main Results] The weakest assumption—that the bilevel problems and network satisfy conditions under which the snapshot preserves the stated iteration complexity bounds without extra error terms—is load-bearing. If violated, the deterministic-setting guarantees do not follow, directly affecting the central claim that S³LDBO achieves the reported rates.
minor comments (2)
- [Algorithm Description and Experiments] Clarify the precise rule for choosing snapshot intervals and how it is implemented in the decentralized setting to aid reproducibility of the reported efficiency gains.
- [Numerical Experiments] The experimental protocols (e.g., choice of snapshot frequency, network topology, and baseline implementations) should include more detail on hyperparameter sensitivity to confirm that post-hoc choices do not affect the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on our manuscript. We address the major comments point by point below, providing clarifications on the complexity analysis and assumptions while maintaining the integrity of the presented results.
read point-by-point responses
-
Referee: [Complexity Analysis (proof of Theorems on ergodic/nonergodic rates)] The ergodic and nonergodic complexity claims rest on the snapshot mechanism introducing no additional bias or divergence beyond the smoothness/convexity assumptions. The interaction of the snapshot operator with the decentralized communication graph and the inner-outer bilevel structure (gradients, Jacobians, Hessians) is the least-secured step; without explicit bounds on snapshot frequency in terms of network connectivity and Lipschitz constants, the recursion may accumulate uncontrolled error.
Authors: We appreciate the referee's focus on the snapshot mechanism. In the proofs of the ergodic and nonergodic complexity results (Theorems 1 and 2 in Section 4, with full details in Appendix B), the snapshot operator is analyzed as introducing a controlled perturbation whose magnitude is bounded using the Lipschitz constants of the gradient, Jacobian, and Hessian mappings. The interaction with the communication graph is handled via standard consensus error bounds that depend on the graph's spectral gap; these terms are explicitly carried through the recursion and absorbed into the overall O(1/T) rate under the given step-size choices. The snapshot frequency is not fixed arbitrarily but is governed by the algorithm parameters such that the accumulated error remains compatible with the stated rates; no uncontrolled divergence occurs because the deterministic setting and strong convexity/smoothness assumptions ensure contraction dominates the perturbation. We can add a dedicated remark or corollary in the revision to make these bounding steps more explicit if desired. revision: partial
-
Referee: [Assumptions and Main Results] The weakest assumption—that the bilevel problems and network satisfy conditions under which the snapshot preserves the stated iteration complexity bounds without extra error terms—is load-bearing. If violated, the deterministic-setting guarantees do not follow, directly affecting the central claim that S³LDBO achieves the reported rates.
Authors: The assumptions in Section 3 (smoothness, strong convexity of the inner problem, bounded gradients, and connected graph) are standard and sufficient for the snapshot to preserve the rates. The main theorems explicitly state that the complexity bounds hold when these conditions are met, with the snapshot error controlled as part of the analysis rather than introducing hidden terms. The deterministic setting eliminates stochastic noise, allowing the perturbation from intermittent skipping to be bounded deterministically without affecting the ergodic and high-probability nonergodic guarantees. We believe the load-bearing nature is addressed by the explicit conditions in the theorem statements. revision: no
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes S³LDBO as a new single-loop decentralized bilevel algorithm incorporating a snapshot mechanism to reduce derivative evaluations, then derives ergodic and high-probability nonergodic iteration complexities under standard smoothness/convexity/network assumptions in a deterministic setting. These bounds follow from the algorithm recursion and problem structure without any reduction to fitted parameters, self-definitional quantities, or load-bearing self-citations. The snapshot error control is an explicit modeling assumption rather than a derived claim that collapses to the input. No renaming of known results or ansatz smuggling appears. The central claims remain independent of the paper's own fitted values or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Edge learning for b5g networks with distributed signal processing: Semantic communication, edge computing, and wireless sensing,
W. Xu, Z. Yang, D. W. K. Ng, M. Levorato, Y . C. Eldar, and M. Debbah, “Edge learning for b5g networks with distributed signal processing: Semantic communication, edge computing, and wireless sensing,”IEEE Journal of Selected Topics in Signal Processing, vol. 17, no. 1, pp. 9–39, 2023
2023
-
[2]
Decentralized federated learning with unreliable communications,
H. Ye, L. Liang, and G. Y . Li, “Decentralized federated learning with unreliable communications,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 3, pp. 487–500, 2022
2022
-
[3]
Multitask diffusion adaptation over networks with common latent representations,
J. Chen, C. Richard, and A. H. Sayed, “Multitask diffusion adaptation over networks with common latent representations,”IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 3, pp. 563–579, 2017
2017
-
[4]
Bilevel programming for hyperparameter optimization and meta-learning,
L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil, “Bilevel programming for hyperparameter optimization and meta-learning,” in Proceedings of the 35th International Conference on Machine Learning, vol. 80. PMLR, 2018, pp. 1568–1577
2018
-
[5]
Meta-learning with implicit gradients,
A. Rajeswaran, C. Finn, S. M. Kakade, and S. Levine, “Meta-learning with implicit gradients,” inAdvances in Neural Information Processing Systems, vol. 32. Curran Associates, Inc., 2019
2019
-
[6]
Convergence of meta-learning with task-specific adaptation over partial parameters,
K. Ji, J. D. Lee, Y . Liang, and H. V . Poor, “Convergence of meta-learning with task-specific adaptation over partial parameters,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 11 490–11 500
2020
-
[7]
Hyperparameter optimization with approximate gradient,
F. Pedregosa, “Hyperparameter optimization with approximate gradient,” inProceedings of The 33rd International Conference on Machine Learning, vol. 48. PMLR, 2016, pp. 737–746
2016
-
[8]
Difference of convex algorithms for bilevel programs with applications in hyperparameter selection,
J. J. Ye, X. Yuan, S. Zeng, and J. Zhang, “Difference of convex algorithms for bilevel programs with applications in hyperparameter selection,” Mathematical Programming, vol. 198, no. 1-2, pp. 1583–1616, 2023
2023
-
[9]
A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor-critic,
M. Hong, H.-T. Wai, Z. Wang, and Z. Yang, “A two-timescale stochastic algorithm framework for bilevel optimization: Complexity analysis and application to actor-critic,”SIAM Journal on Optimization, vol. 33, no. 1, pp. 147–180, 2023
2023
-
[10]
Optimal learning from verified training data,
N. Bishop, L. Tran-Thanh, and E. Gerding, “Optimal learning from verified training data,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 9520–9529
2020
-
[11]
Revisiting and advancing fast adversarial training through the lens of bi- level optimization,
Y . Zhang, G. Zhang, P. Khanduri, M. Hong, S. Chang, and S. Liu, “Revisiting and advancing fast adversarial training through the lens of bi- level optimization,” inProceedings of the 39th International Conference on Machine Learning, vol. 162. PMLR, 2022, pp. 26 693–26 712
2022
-
[12]
Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent,
X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent,” inAdvances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017
2017
-
[13]
Approximation Methods for Bilevel Programming
S. Ghadimi and M. Wang, “Approximation methods for bilevel program- ming,”arXiv preprint arXiv:1802.02246, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
On the iteration complexity of hypergradient computation,
R. Grazzi, L. Franceschi, M. Pontil, and S. Salzo, “On the iteration complexity of hypergradient computation,” inProceedings of the 37th International Conference on Machine Learning, vol. 119. PMLR, 2020, pp. 3748–3758
2020
-
[15]
Bilevel optimization: Convergence analysis and enhanced design,
K. Ji, J. Yang, and Y . Liang, “Bilevel optimization: Convergence analysis and enhanced design,” inProceedings of the 38th International Conference on Machine Learning, vol. 139. PMLR, 2021, pp. 4882– 4892
2021
-
[16]
Will bilevel optimizers benefit from loops,
K. Ji, M. Liu, Y . Liang, and L. Ying, “Will bilevel optimizers benefit from loops,” inAdvances in Neural Information Processing Systems, vol. 35. Curran Associates, Inc., 2022, pp. 3011–3023
2022
-
[17]
Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems,
T. Chen, Y . Sun, and W. Yin, “Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems,” inAdvances in Neural Information Processing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 25 294–25 307
2021
-
[18]
A framework for bilevel optimization that enables stochastic and global variance reduction algorithms,
M. Dagr ´eou, P. Ablin, S. Vaiter, and T. Moreau, “A framework for bilevel optimization that enables stochastic and global variance reduction algorithms,” inAdvances in Neural Information Processing Systems, vol. 35. Curran Associates, Inc., 2022, pp. 26 698–26 710
2022
-
[19]
Truncated back- propagation for bilevel optimization,
A. Shaban, C.-A. Cheng, N. Hatch, and B. Boots, “Truncated back- propagation for bilevel optimization,” inProceedings of the Twenty- Second International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, vol. 89. PMLR, 2019, pp. 1723–1732
2019
-
[20]
A general descent aggregation framework for gradient-based bi-level optimization,
R. Liu, P. Mu, X. Yuan, S. Zeng, and J. Zhang, “A general descent aggregation framework for gradient-based bi-level optimization,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 38–57, 2023
2023
-
[21]
Averaged method of multipliers for bi-level optimization without lower-level strong convexity,
R. Liu, Y . Liu, W. Yao, S. Zeng, and J. Zhang, “Averaged method of multipliers for bi-level optimization without lower-level strong convexity,” inProceedings of the 40th International Conference on Machine Learning, vol. 202. PMLR, 2023, pp. 21 839–21 866
2023
-
[22]
Towards gradient-based bilevel optimization with non-convex followers and beyond,
R. Liu, Y . Liu, S. Zeng, and J. Zhang, “Towards gradient-based bilevel optimization with non-convex followers and beyond,” inAdvances in Neural Information Processing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 8662–8675
2021
-
[23]
Decentralized bilevel optimization,
X. Chen, M. Huang, and S. Ma, “Decentralized bilevel optimization,” Optimization Letters, 2024
2024
-
[24]
Decentralized stochastic bilevel optimization with improved per-iteration complexity,
X. Chen, M. Huang, S. Ma, and K. Balasubramanian, “Decentralized stochastic bilevel optimization with improved per-iteration complexity,” in Proceedings of the 40th International Conference on Machine Learning, vol. 202. PMLR, 2023, pp. 4641–4671
2023
-
[25]
Decentralized gossip-based stochastic bilevel optimization over communication networks,
S. Yang, X. Zhang, and M. Wang, “Decentralized gossip-based stochastic bilevel optimization over communication networks,” inAdvances in Neural Information Processing Systems, vol. 35. Curran Associates, Inc., 2022, pp. 238–252
2022
-
[26]
On the convergence of distributed stochastic bilevel optimization algorithms over a network,
H. Gao, B. Gu, and M. T. Thai, “On the convergence of distributed stochastic bilevel optimization algorithms over a network,” inProceedings of The 26th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, vol. 206. PMLR, 2023, pp. 9238–9281
2023
-
[27]
A stochastic linearized augmented Lagrangian method for 10 decentralized bilevel optimization,
S. Lu, S. Zeng, X. Cui, M. Squillante, L. Horesh, B. Kingsbury, J. Liu, and M. Hong, “A stochastic linearized augmented Lagrangian method for 10 decentralized bilevel optimization,” inAdvances in Neural Information Processing Systems, vol. 35. Curran Associates, Inc., 2022, pp. 30 638– 30 650
2022
-
[28]
A single-loop algorithm for decentralized bilevel optimization,
Y . Dong, S. Ma, J. Yang, and C. Yin, “A single-loop algorithm for decentralized bilevel optimization,”Mathematics of Operations Research, vol. 0, no. 0, 2025
2025
-
[29]
Decentralized bilevel optimization: A perspective from transient iteration complexity,
B. Kong, S. Zhu, S. Lu, X. Huang, and K. Yuan, “Decentralized bilevel optimization: A perspective from transient iteration complexity,”Journal of Machine Learning Research, vol. 26, no. 240, pp. 1–64, 2025
2025
-
[30]
On the Communication Complexity of Decentralized Stochastic Bilevel Optimization
Y . Zhang, M. T. Thai, J. Wu, and H. Gao, “On the communica- tion complexity of decentralized bilevel optimization.”arXiv preprint arXiv:2311.11342, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Optimal gradient tracking for decentralized optimization,
Z. Song, L. Shi, S. Pu, and M. Yan, “Optimal gradient tracking for decentralized optimization,”Mathematical Programming, vol. 207, no. 1–2, p. 1–53, 2024
2024
-
[32]
Distributed stochastic gradient tracking methods,
S. Pu and A. Nedi ´c, “Distributed stochastic gradient tracking methods,” Mathematical Programming, vol. 187, no. 1-2, pp. 409–457, 2021
2021
-
[33]
On the convergence analysis of the decentralized projected gradient descent,
W. Choi and J. Kim, “On the convergence analysis of the decentralized projected gradient descent,”arXiv preprint arXiv:2303.08412, 2023
-
[34]
Decentralized gradient descent maximization method for com- posite nonconvex strongly-concave minimax problems,
Y . Xu, “Decentralized gradient descent maximization method for com- posite nonconvex strongly-concave minimax problems,”SIAM Journal on Optimization, vol. 34, no. 1, pp. 1006–1044, 2024
2024
-
[35]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inProceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, D. Precup and Y . W. Teh, Eds., vol. 70. PMLR, 06–11 Aug 2017, pp. 1126–1135
2017
-
[36]
Rapid learning or feature reuse? towards understanding the effectiveness of MAML,
A. Raghu, M. Raghu, S. Bengio, and O. Vinyals, “Rapid learning or feature reuse? towards understanding the effectiveness of MAML,” in 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020
2020
-
[37]
mpi4py: Status update after 12 years of development,
L. Dalcin and Y .-L. L. Fang, “mpi4py: Status update after 12 years of development,”Computing in Science & Engineering, vol. 23, no. 4, pp. 47–54, 2021
2021
-
[38]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[39]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms.”arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
T. H. Hsu, H. Qi, and M. Brown, “Measuring the effects of non- identical data distribution for federated visual classification,”arXiv preprint arXiv:1909.06335, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[41]
On penalty-based bilevel gradient descent method,
H. Shen and T. Chen, “On penalty-based bilevel gradient descent method,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 202. PMLR, 2023, pp. 30 992–31 015
2023
-
[42]
Matching networks for one shot learning,
O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra, “Matching networks for one shot learning,” inAdvances in Neural Information Processing Systems, D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, Eds., vol. 29. Curran Associates, Inc., 2016
2016
-
[43]
Dif-maml: Decentralized multi-agent meta-learning,
M. Kayaalp, S. Vlaski, and A. H. Sayed, “Dif-maml: Decentralized multi-agent meta-learning,”IEEE Open Journal of Signal Processing, vol. 3, pp. 71–93, 2022
2022
-
[44]
ImageNet Large Scale Visual Recognition Challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,”International Journal of Computer Vision (IJCV), vol. 115, no. 3, pp. 211–252, 2015
2015
-
[45]
Beck,First-order Methods in Optimization
A. Beck,First-order Methods in Optimization. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2017, vol. 25
2017
-
[46]
Nesterov,Lectures on Convex Optimization, 2nd ed
Y . Nesterov,Lectures on Convex Optimization, 2nd ed. Springer, Cham, 2018, vol. 137. 11 APPENDIXA COMPLETE PROOF OF THE CONVERGENCE RESULTS In this appendix, we provide the proof of our convergence results, i.e., Theorem III.2 and Theorem III.3. Assumptions II.1 and II.2 are used throughout the proof. Recall that rv :=L F,0/σ and ρ is defined in Assumpti...
2018
-
[47]
Notation, constants, and roadmap:For convenience in the subsequent convergence proof, we rewrite the kth iteration of Algorithm 1 in a more concise form as follows, together with (4), (5) and (6): zk y,i =t k y,i +ξ k(dk y,i −d k ˜y,i)/p, y k+1 i = Xn j=1 wij(yk j −βz k y,j),(8a) ˜yk+1 i =ξ kyk i + (1−ξ k)˜yk i , t k+1 y,i = Xn j=1 wij tk y,j +ξ k(dk y,j ...
-
[48]
−n∥¯zk+1 x −¯zk x∥2
Some lemmas for consensus error of Algorithm 1:Recall that¯x k,¯yk,¯vk, ¯dk x, ¯dk y, ¯dk v, ¯dk ˜x, ¯dk ˜y, ¯dk ˜v, ¯tk x, ¯tk y, ¯tk v,¯zk x,¯zk y and ¯zk v are defined in (12). Let Fk be the sigma field generated by {ξj}0≤j≤k−1 and Ek[·] be the conditional expectation taken over Fk. Then, for any k≥0 , the variables {xk i , yk i , vk i , dk x,i, dk y,i...
-
[49]
For anyk >0,Φ(¯x k)and∇Φ(¯x k)are also measurable with respect toF k
Some lemmas for convergence rate of Algorithm 1:Recall that Φ(x) =F(x, y ∗(x)) denotes the overall objective function. For anyk >0,Φ(¯x k)and∇Φ(¯x k)are also measurable with respect toF k. Lemma A.12.The sequence{(x k i , yk i , vk i )}generated by(8)satisfies Ek h Φ(¯xk+1)−Φ(¯xk) i ≤ − α 2 ∥∇Φ(¯xk)∥2 − (1/α−L Φ) 2 Ek h ∥¯xk+1 −¯xk∥2 i + 5αL2 f,1 2 ∥¯vk −...
-
[50]
Proof of Theorem III.2.: Proof.By using Cauchy-Schwarz inequality again, we derive Ek h ∥¯yk+1 −y ∗(¯xk+1)∥2 i ≤ 1 + βσ 4 Ek h ∥¯yk+1 −y ∗(¯xk)∥2 i + 1 + 4 βσ Ek h ∥y∗(¯xk+1)−y ∗(¯xk)∥2 i . By taking into account (38), the first inequality in (48), andβσ≤1, we obtain Ek h ∥¯yk+1−y∗(¯xk+1)∥2 i ≤ 1− βσ 4 Ek h ∥¯yk −y ∗(¯xk)∥2 i + 15βL2 f,1 4nσ Ek h nX i=1 ∥...
-
[51]
Therefore, the term ∥∇Φ(¯xk)∥2 + 1 n Pn i=1 ∥xk i −¯xk∥2 + 1 n Pn i=1 ∥yk i −¯yk∥2 approaches 0 in expectation as k→ ∞
Proof of Theorem III.3.: Proof.From (54) and (55), we can establish the following inequality: E h Vk+1 −V k i ≤ − α 2 E h ∥∇Φ(¯xk)∥2 i − A4 n E h nX i=1 ∥xk i −¯xk∥2 i − A5 n E h nX i=1 ∥yk i −¯yk∥2 i , which yields P∞ k=0 E h ∥∇Φ(¯xk)∥2 + 1 n Pn i=1 ∥xk i −¯xk∥2 + 1 n Pn i=1 ∥yk i −¯yk∥2 i ≤V 0/C3 <∞, where C3 = min{α/2, A 4, A5}. Therefore, the term ∥∇Φ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.