Probing-Guided Layer Selection from Self-Supervised Speech Models for Generalizable Audio Deepfake Detection
Pith reviewed 2026-07-01 01:32 UTC · model grok-4.3
The pith
Probing single layers identifies small sets from speech models that detect audio deepfakes more accurately across domains than using all layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
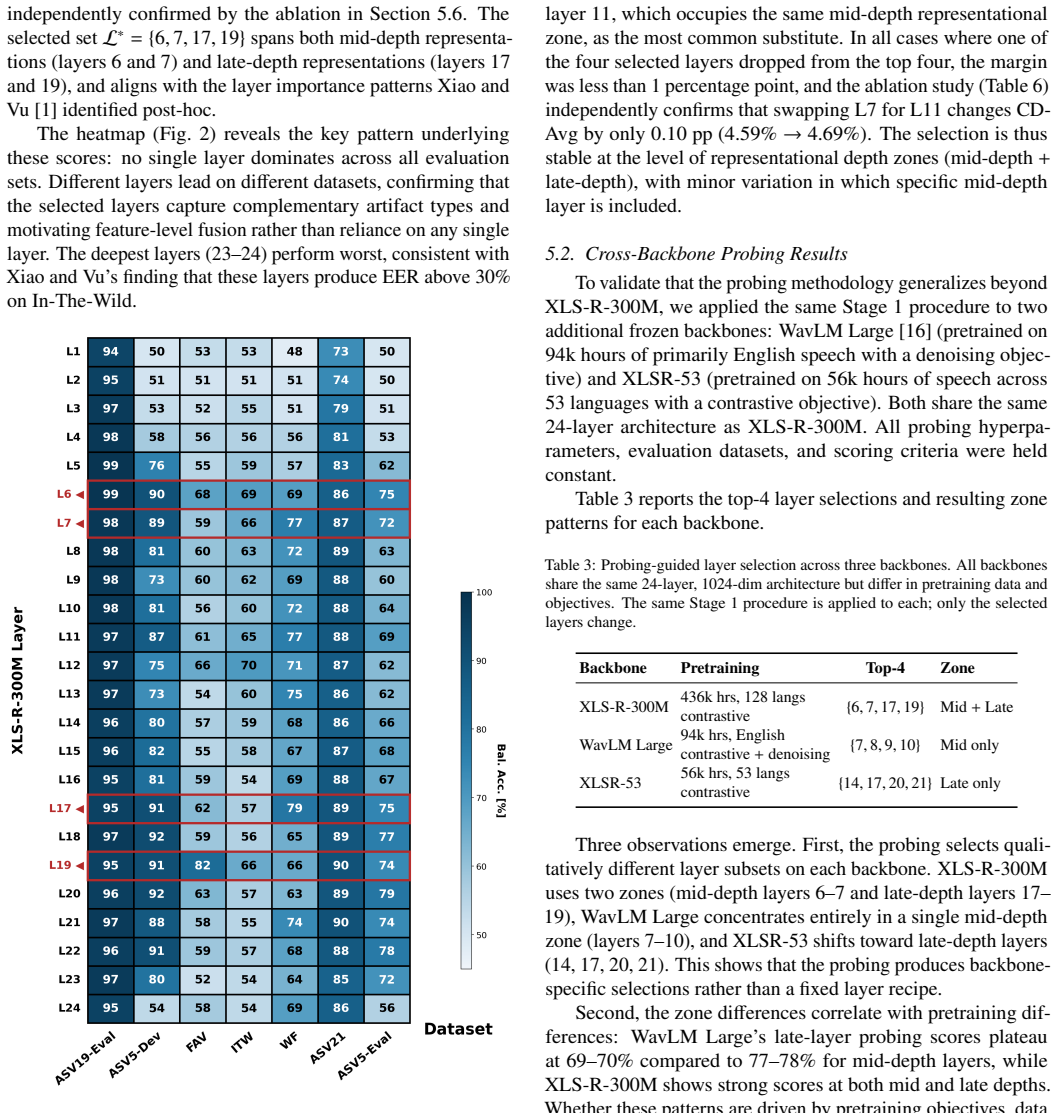
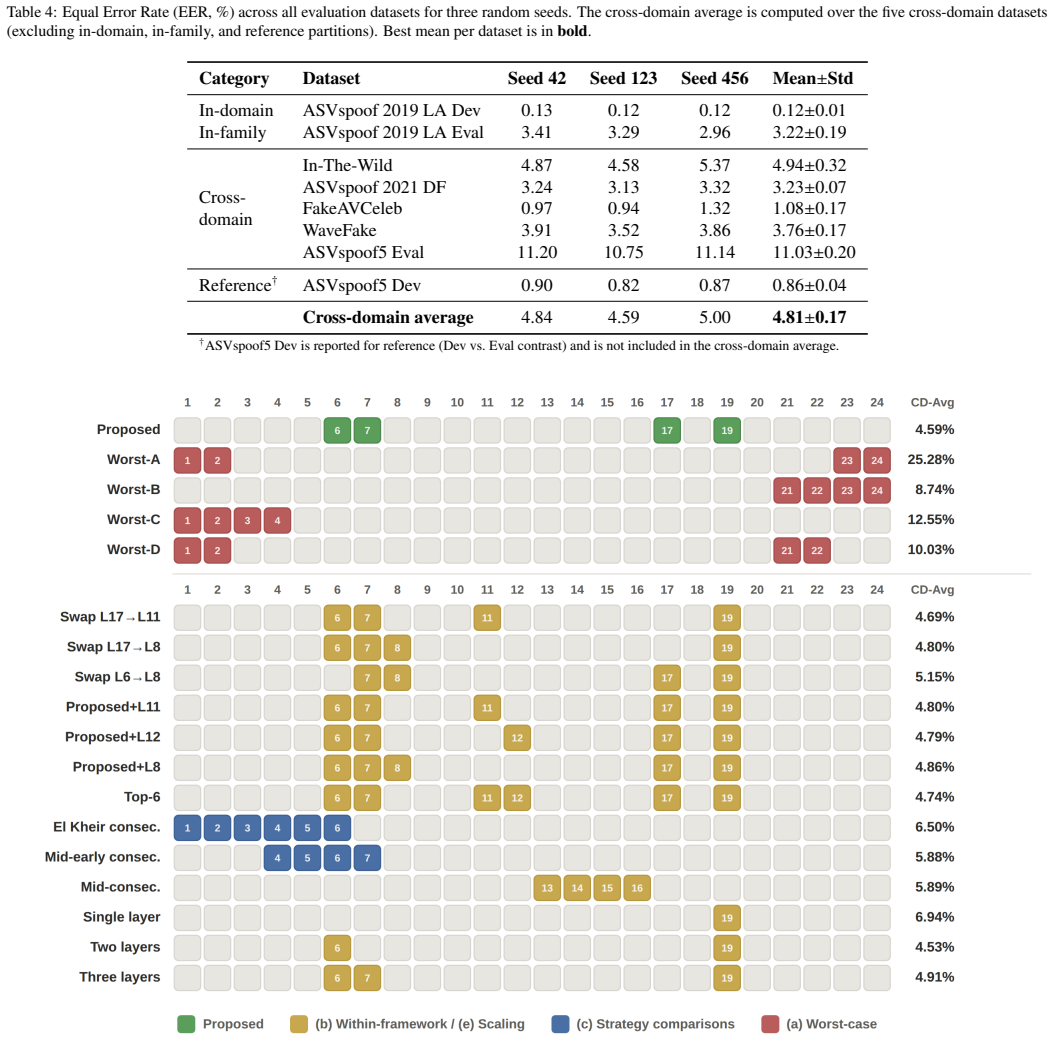
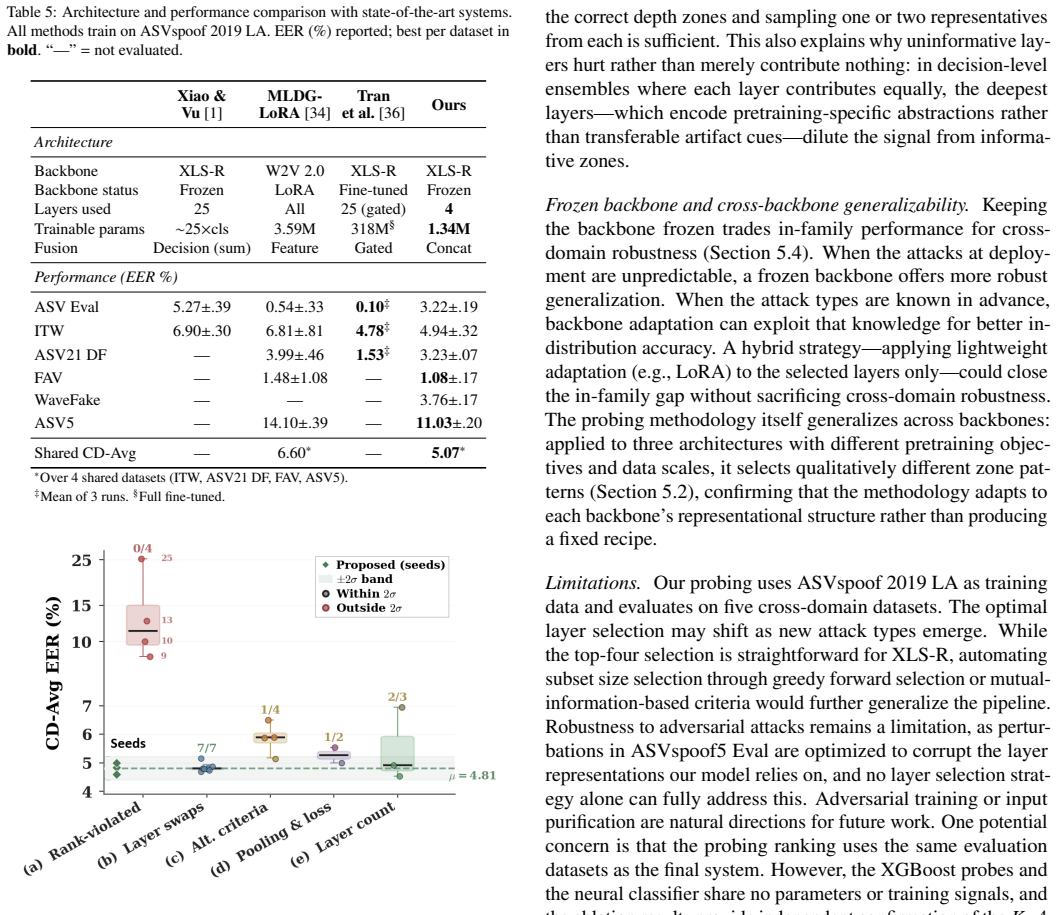
Informative layers cluster in depth zones instead of occupying single optimal positions, and the best selection is specific to each backbone model. On XLS-R-300M, four layers chosen by probing reach 4.94 percent equal error rate on in-the-wild data and 5.07 percent cross-domain average over four datasets, a 28 percent relative gain over the prior best frozen-backbone result that used all 25 layers with the same training data.
What carries the argument
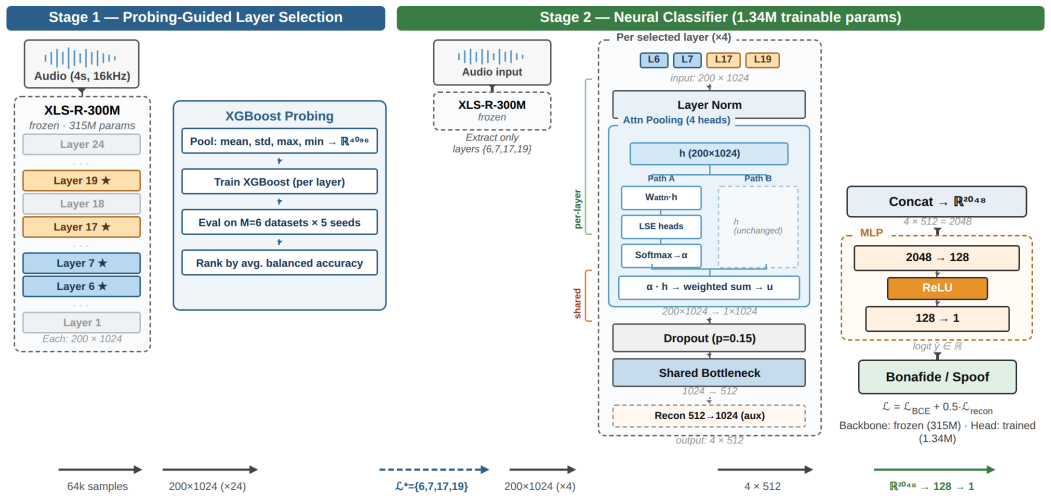
Two-stage process that first ranks each transformer layer by independent XGBoost probe accuracy on multiple domains, then fuses only the selected layers via per-layer attention pooling and a shared bottleneck inside a downstream classifier.
If this is right
- Four layers with 1.34 million trainable parameters outperform the full 25-layer model on both in-the-wild and cross-domain metrics.
- Swapping layers inside the same depth zone keeps performance within normal multi-seed variation, while selections outside the zone raise error rates by up to five times.
- Each backbone produces its own layer ranking rather than converging on one universal set of layers.
- The approach reduces trainable parameters while lowering cross-domain average error compared with indiscriminate full-layer fusion.
Where Pith is reading between the lines
- Zone clustering implies that selecting contiguous depth ranges could achieve similar gains without needing exact layer rankings.
- The same independent probing step could be tested on other audio classification tasks that currently rely on full multi-layer fusion.
- If the probe rankings transfer reliably, many SSL-based detectors may not require end-to-end fine-tuning once the right depth zone is identified.
Load-bearing premise
Rankings obtained by testing layers one at a time will still identify the best combination once those layers are joined through attention pooling in a single classifier.
What would settle it
Training the downstream attention classifier on the probed layers and finding that error rates match or exceed those obtained by using all layers or a random subset of equal size.
Figures
read the original abstract
Audio deepfake detection systems often fail to generalize across domains because they rely on features tied to specific attacks or recording conditions. Self-supervised speech models offer rich multi-layer representations, yet existing approaches either use a single layer or fuse all layers indiscriminately, and only reveal layer importance after training. We propose a model-agnostic, two-stage methodology that identifies informative depth zones before any task-specific model is trained. In the first stage, lightweight XGBoost probes evaluate each transformer layer's cross-domain discriminative power, producing a layer ranking. In the second stage, a compact neural classifier fuses only the selected layers through per-layer attention pooling and a shared bottleneck projection, while the backbone remains frozen. Applied across three backbones, the probing reveals two key findings. First, informative layers cluster in depth zones rather than at uniquely optimal positions: within-zone substitutions fall within multi-seed noise, while zone violations degrade performance by up to 5x. Second, the probing produces backbone-specific selections rather than a fixed layer recipe. On XLS-R-300M, four probing-selected layers with 1.34M trainable parameters achieve 4.94 +/- 0.32% equal error rate on In-The-Wild and 5.07% cross-domain average over four shared datasets, a 28% relative improvement over the best prior frozen-backbone result (Xiao and Vu, 2025) using all 25 layers with identical training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-stage, model-agnostic method for audio deepfake detection: lightweight XGBoost probes first rank individual layers of frozen self-supervised speech models (e.g., XLS-R-300M) by cross-domain discriminative power on external labels; the top-ranked layers are then fused via per-layer attention pooling and a shared bottleneck in a compact neural classifier (1.34M trainable parameters). Experiments across three backbones report that informative layers cluster in depth zones, within-zone substitutions stay within multi-seed noise, and zone violations degrade performance; on XLS-R-300M the selected four layers yield 4.94 +/- 0.32% EER on In-The-Wild and 5.07% cross-domain average, a 28% relative improvement over the prior 25-layer frozen baseline.
Significance. If the probing-to-fusion transfer holds, the work supplies a practical, low-cost way to identify task-relevant depth zones without end-to-end training and demonstrates that backbone-specific rather than universal layer recipes improve generalization while reducing parameters. The explicit multi-seed variance reporting and use of separate lightweight probes on frozen features are strengths that support reproducibility.
major comments (2)
- [Abstract / experimental results] Abstract and experimental results: the 28% relative EER gain is attributed to the probing-derived layer ranking, yet no ablation is reported that holds the attention-pooling + bottleneck architecture fixed while varying only the layer selection (probing-selected vs. random vs. bottom-k vs. consecutive zones). Without this control it remains possible that the improvement arises from using four layers instead of 25 or from the fusion mechanism itself rather than from the XGBoost ranking.
- [Zone-substitution result] Zone-substitution analysis: the claim that within-zone substitutions fall within multi-seed noise while zone violations degrade performance by up to 5x is load-bearing for the 'depth zones rather than unique layers' conclusion, but the manuscript does not quantify whether the probe ordering inside a zone is itself predictive once the joint attention model is trained; the reported consistency with clustering does not yet establish that the independent per-layer AUC ranking is the causal driver.
minor comments (1)
- Clarify in the methods whether the four shared datasets used for cross-domain averaging are exactly the same as those used for probe training or held-out; any overlap would affect the interpretation of 'cross-domain'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify gaps in experimental controls that we will address through additional ablations in the revised manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract and experimental results: the 28% relative EER gain is attributed to the probing-derived layer ranking, yet no ablation is reported that holds the attention-pooling + bottleneck architecture fixed while varying only the layer selection (probing-selected vs. random vs. bottom-k vs. consecutive zones). Without this control it remains possible that the improvement arises from using four layers instead of 25 or from the fusion mechanism itself rather than from the XGBoost ranking.
Authors: We agree that the manuscript lacks an ablation that isolates the probing-based selection while fixing the four-layer attention-pooling + bottleneck architecture. The 28% gain is reported against a 25-layer baseline that uses the identical fusion method, but this does not rule out benefits from layer count or fusion alone. We will add the requested controls (probing-selected vs. random 4-layer, bottom-k, and consecutive-zone selections) under the same multi-seed protocol and report the results in the revision. revision: yes
-
Referee: [Zone-substitution result] Zone-substitution analysis: the claim that within-zone substitutions fall within multi-seed noise while zone violations degrade performance by up to 5x is load-bearing for the 'depth zones rather than unique layers' conclusion, but the manuscript does not quantify whether the probe ordering inside a zone is itself predictive once the joint attention model is trained; the reported consistency with clustering does not yet establish that the independent per-layer AUC ranking is the causal driver.
Authors: The zone-substitution experiments demonstrate robustness to intra-zone swaps (within multi-seed variance) and degradation outside zones. This supports the depth-zone claim over unique-layer optimality. However, we acknowledge that the results do not directly test whether the specific intra-zone probe ranking remains predictive after joint training. In revision we will add within-zone permutation experiments that compare the probe-derived ordering against random intra-zone selections to quantify any additional benefit from the ranking. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's layer selection derives from independent per-layer XGBoost probes that compute cross-domain AUC on frozen features using external labels; these rankings are produced before and separately from the downstream attention-pooled neural classifier. No equation or procedure defines the probe output in terms of the final EER or classifier parameters, and the cited baseline (Xiao and Vu, 2025) is external. The chain therefore remains self-contained against external benchmarks with no self-definitional, fitted-input, or self-citation reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of selected layers =
4
axioms (1)
- domain assumption Individual transformer layers in SSL speech models carry domain-discriminative information measurable by lightweight probes
Reference graph
Works this paper leans on
-
[1]
Layer-wise decision fusion for fake audio detection using XLS-R,
Y . Xiao and N. T. Vu, “Layer-wise decision fusion for fake audio detection using XLS-R,” inProc. Interspeech, 2025
2025
-
[2]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wanget al., “Neural codec language models are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Audio deepfake detection: A survey,
J. Yi, C. Wang, J. Tao, X. Zhang, C. Y . Zhang, and Y . Zhao, “Audio deepfake detection: A survey,”arXiv preprint arXiv:2308.14970, 2023
-
[4]
Threat intelligence report 2024,
iProov, “Threat intelligence report 2024,” iProov, Tech. Rep., 2024
2024
-
[5]
The financial cost of deepfakes,
Deloitte Center for Financial Services, “The financial cost of deepfakes,” Deloitte, Tech. Rep., 2024
2024
-
[6]
Q1 2025 deepfake incident report,
Resemble AI, “Q1 2025 deepfake incident report,” Resem- ble AI, Tech. Rep., 2025
2025
-
[7]
A review of modern audio deepfake detection methods,
Z. Almutairi and A. Elgibreen, “A review of modern audio deepfake detection methods,”Algorithms, vol. 15, no. 5, p. 155, 2022
2022
-
[8]
Deepfakes generation and detection,
M. Masoodet al., “Deepfakes generation and detection,” Appl. Intell., vol. 53, pp. 3974–4026, 2023
2023
-
[9]
Does audio deepfake detection generalize?
N. M. Müller, P. Czempin, F. Dieckmann, A. Froghyar, and K. Böttinger, “Does audio deepfake detection generalize?” inProc. Interspeech, 2022, pp. 2783–2787
2022
-
[10]
AASIST: Audio anti-spoofing using integrated spectro-temporal graph attention networks,
J.-w. Junget al., “AASIST: Audio anti-spoofing using integrated spectro-temporal graph attention networks,” in Proc. ICASSP, 2022, pp. 6247–6251
2022
-
[11]
End-to-end anti-spoofing with RawNet2,
H. Tak, J. Patino, M. Todisco, A. Nautsch, N. Evans, and A. Larcher, “End-to-end anti-spoofing with RawNet2,” in Proc. ICASSP, 2021, pp. 6369–6373
2021
-
[12]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” inProc. NeurIPS, vol. 33, 2020, pp. 12449–12460
2020
-
[13]
Exploring wav2vec 2.0 on speaker verification and language identification,
Z. Fan, M. Li, S. Zhou, and B. Xu, “Exploring wav2vec 2.0 on speaker verification and language identification,” in Proc. Interspeech, 2021, pp. 1509–1513
2021
-
[14]
Emotion recognition from speech using wav2vec 2.0 embeddings,
L. Pepino, P. Riera, and L. Ferrer, “Emotion recognition from speech using wav2vec 2.0 embeddings,” inProc. Interspeech, 2021, pp. 3400–3404
2021
-
[15]
XLS-R: Self-supervised cross-lingual speech representation learning at scale,
A. Babuet al., “XLS-R: Self-supervised cross-lingual speech representation learning at scale,” inProc. Inter- speech, 2022, pp. 2278–2282
2022
-
[16]
WavLM: Large-scale self-supervised pre- training for full stack speech processing,
S. Chenet al., “WavLM: Large-scale self-supervised pre- training for full stack speech processing,”IEEE J. Sel. Topics Signal Process., vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[17]
Layer-wise analysis of a self-supervised speech representation model,
A. Pasad, J. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,” inProc. ASRU, 2021, pp. 914–921
2021
-
[18]
Comparative layer- wise analysis of self-supervised speech models,
A. Pasad, B. Shi, and K. Livescu, “Comparative layer- wise analysis of self-supervised speech models,” inProc. ICASSP, 2023, pp. 1–5
2023
-
[19]
Ex- posing AI-synthesized human voices using neural vocoder artifacts,
C. Sun, S. Jia, S. Hou, E. AlBadawy, and S. Lyu, “Ex- posing AI-synthesized human voices using neural vocoder artifacts,” inProc. CVPR Workshops, 2023
2023
-
[20]
ASVspoof 2019: Future horizons in spoofed and fake audio detection,
M. Todisco, X. Wang, V . Vestman, H. Delgado, M. Sahidul- lah, N. Evans, T. Kinnunen, and K. A. Lee, “ASVspoof 2019: Future horizons in spoofed and fake audio detection,” inProc. Interspeech, 2019, pp. 1008–1012
2019
-
[21]
P. Serrano, R. Duroselle, F. Angulo, J.-F. Bonastre, and O. Boeffard, “Improving out-of-domain audio deepfake detection via layer selection and fusion of SSL-based coun- termeasures,”arXiv preprint arXiv:2509.12003, 2025
-
[22]
Comprehensive layer-wise analysis of SSL models for audio deepfake detection,
Y . El Kheir, Y . Samih, S. Maharjan, T. Polzehl, and S. Möller, “Comprehensive layer-wise analysis of SSL models for audio deepfake detection,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 4070–4082. 12
2025
-
[23]
Towards generalisable and calibrated audio deepfake de- tection with self-supervised representations,
O. Pascu, A. Stan, D. Oneata, E. Oneata, and H. Cucu, “Towards generalisable and calibrated audio deepfake de- tection with self-supervised representations,” inProc. In- terspeech, 2024, pp. 4828–4832
2024
-
[24]
Can large-scale vocoded spoofed data improve speech spoofing countermeasure with a self-supervised front end?
X. Wang and J. Yamagishi, “Can large-scale vocoded spoofed data improve speech spoofing countermeasure with a self-supervised front end?” inProc. ICASSP, 2024, pp. 12631–12635
2024
-
[25]
Exploring self-supervised em- beddings and synthetic data augmentation for robust audio deepfake detection,
J. M. Martín-Doñaset al., “Exploring self-supervised em- beddings and synthetic data augmentation for robust audio deepfake detection,” inProc. Interspeech, 2024, pp. 2085– 2089
2024
-
[26]
Attentive merging of hidden embeddings from pre-trained speech model for anti-spoofing detection,
Z. Pan, T. Liu, H. B. Sailor, and Q. Wang, “Attentive merging of hidden embeddings from pre-trained speech model for anti-spoofing detection,” inProc. Interspeech, 2024, pp. 4838–4842
2024
-
[27]
ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech,
X. Wanget al., “ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech,” Comput. Speech Lang., vol. 64, p. 101114, 2020
2019
-
[28]
ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,
X. Liuet al., “ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 31, pp. 2507–2522, 2023
2021
-
[29]
ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,
X. Wanget al., “ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,”arXiv preprint arXiv:2408.08739, 2024
-
[30]
One-class learning to- wards synthetic voice spoofing detection,
Y . Zhang, F. Jiang, and Z. Duan, “One-class learning to- wards synthetic voice spoofing detection,”IEEE Signal Process. Lett., vol. 28, pp. 937–941, 2021
2021
-
[31]
RawBoost: A raw data boosting and augmentation method,
H. Tak, M. R. Kamble, J. Patino, M. Todisco, and N. W. D. Evans, “RawBoost: A raw data boosting and augmentation method,” inProc. ICASSP, 2022, pp. 6382–6386
2022
-
[32]
A study on data augmentation of reverberant speech,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudan- pur, “A study on data augmentation of reverberant speech,” inProc. ICASSP, 2017, pp. 5220–5224
2017
-
[33]
Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data aug- mentation,
H. Tak, M. Todisco, X. Wang, J.-w. Jung, J. Yamagishi, and N. Evans, “Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data aug- mentation,” inProc. Odyssey, 2022, pp. 112–119
2022
-
[34]
Generaliz- able speech deepfake detection via meta-learned LoRA,
J. Laakkonen, I. Kukanov, and V . Hautamäki, “Generaliz- able speech deepfake detection via meta-learned LoRA,” in Proc. Int. Conf. Mach. Learn. (ICML), PMLR 267, 2025
2025
-
[35]
Audio deepfake detection with self-supervised XLS-R and sensitive layer selection,
Q. Zhang, S. Wen, and T. Hu, “Audio deepfake detection with self-supervised XLS-R and sensitive layer selection,” inProc. ACM Multimedia, 2024
2024
-
[36]
Multi-level SSL feature gating for audio deepfake detection,
H. M. Tran, D. Lolive, A. Sini, A. Delhay, P.-F. Marteau, and D. Guennec, “Multi-level SSL feature gating for audio deepfake detection,” inProc. ACM Int. Conf. Multimedia (MM), 2025
2025
-
[37]
What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties,
A. Conneau, G. Kruszewski, G. Lample, L. Barrault, and M. Baroni, “What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties,” in Proc. ACL, 2018, pp. 2126–2136
2018
-
[38]
BERT rediscovers the classical NLP pipeline,
I. Tenney, D. Das, and E. Pavlick, “BERT rediscovers the classical NLP pipeline,” inProc. ACL, 2019, pp. 4593– 4601
2019
-
[39]
Probing classifiers: Promises, shortcomings, and advances,
Y . Belinkov, “Probing classifiers: Promises, shortcomings, and advances,”Comput. Linguist., vol. 48, no. 1, pp. 207– 219, 2022
2022
-
[40]
Improving self-supervised learning model for audio spoofing detection with layer- conditioned embedding fusion,
S. Sinha, S. Dey, and G. Saha, “Improving self-supervised learning model for audio spoofing detection with layer- conditioned embedding fusion,”Comput. Speech Lang., vol. 86, p. 101599, 2024
2024
-
[41]
XGBoost: A scalable tree boost- ing system,
T. Chen and C. Guestrin, “XGBoost: A scalable tree boost- ing system,” inProc. KDD, 2016, pp. 785–794
2016
-
[42]
ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection,
J. Yamagishi, X. Wang, M. Todisco,et al., “ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection,” inProc. ASVspoof Challenge Workshop, 2021
2021
-
[43]
FakeA VCeleb: A novel audio-video multimodal deepfake dataset,
H. Khalid, S. H. Woo, and S. S. Woo, “FakeA VCeleb: A novel audio-video multimodal deepfake dataset,” inProc. NeurIPS Datasets and Benchmarks, 2021
2021
-
[44]
WaveFake: A data set to facili- tate audio deepfake detection,
J. Frank and L. Schönherr, “WaveFake: A data set to facili- tate audio deepfake detection,” inProc. NeurIPS Datasets and Benchmarks, 2021
2021
-
[45]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normaliza- tion,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[46]
HuBERT: Self- supervised speech representation learning,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “HuBERT: Self- supervised speech representation learning,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 29, pp. 3451– 3460, 2021
2021
-
[47]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inProc. ICLR, 2022. 13
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.