Explaining Machine Learning and Memorization with Statistical Mechanics
Pith reviewed 2026-07-01 06:02 UTC · model grok-4.3
The pith
Statistical mechanics applied to associative memory models reveals the low-dimensional structure of neural network learning and the basis for adversarial vulnerabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By studying connections between different formulations of dense associative memory and restricted Boltzmann machines, statistical mechanics methods can characterize the regimes in which these models learn versus memorize and thereby expose the physical-like mechanisms behind the low-dimensional trajectories taken during training and the origins of adversarial confusion.
What carries the argument
Statistical mechanics analysis of dense associative memory (DAM) and restricted Boltzmann machines (RBM), with emphasis on inter-model connections that simplify analytical calculations of learning versus memorization.
If this is right
- Improved understanding of low-dimensional learning trajectories can be used to design training algorithms that remain inside the effective subspace and converge faster.
- Characterizing memorization regimes in DAM and RBM supplies quantitative criteria for when a network has begun to overfit rather than generalize.
- The same statistical mechanics framework identifies the energy-landscape features responsible for adversarial examples, suggesting concrete modifications to network architecture or loss functions.
- Analytical connections between DAM and RBM versions reduce the computational cost of studying larger networks that fit data with mixed learning and memorization.
Where Pith is reading between the lines
- The same low-dimensional subspace description may apply to modern deep networks trained with gradient descent, offering a route to dimension-reduction techniques that do not require explicit regularization.
- If the statistical mechanics mapping holds, one could test whether adversarial robustness improves when networks are explicitly constrained to the learned subspace during inference.
- The approach suggests examining whether other generative models exhibit analogous memorization transitions that can be located with partition-function techniques.
Load-bearing premise
The low-dimensional structure observed in neural network training corresponds to a genuine physical-like phenomenon that statistical mechanics can usefully describe.
What would settle it
Empirical measurements of adversarial attack success rates on DAM or RBM networks that systematically deviate from the predictions obtained via the statistical mechanics mapping to low-dimensional subspaces.
Figures










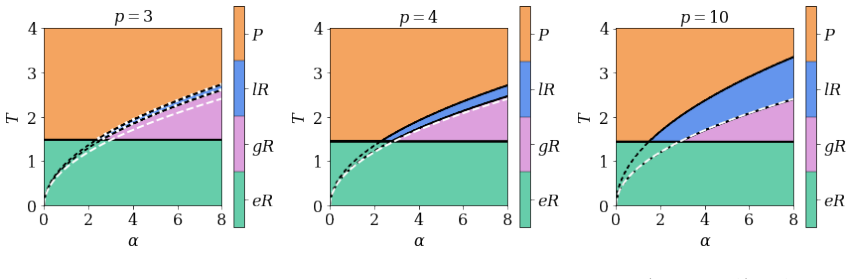
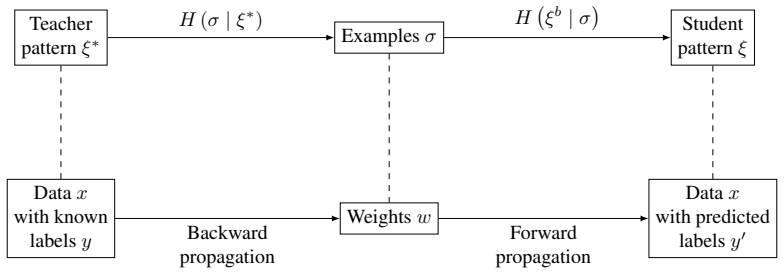
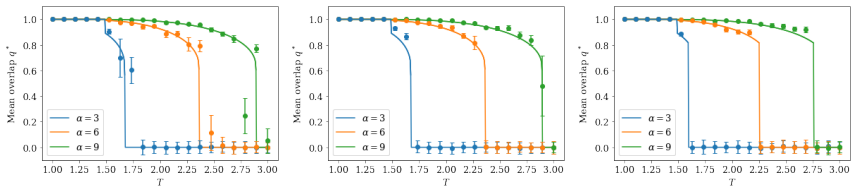


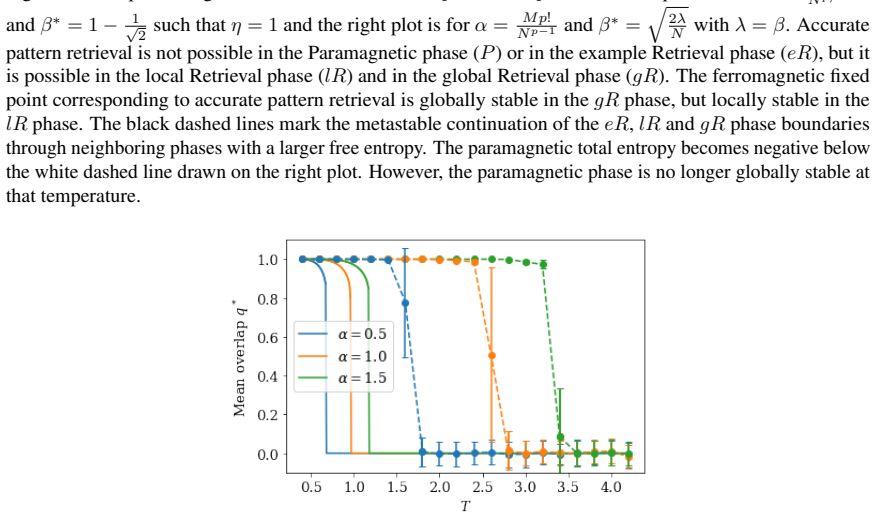
































read the original abstract
Artificial neural networks (NNs) and machine learning (ML) algorithms are poorly understood from a theoretical perspective, which makes it difficult to fully realize their potential and overcome their weaknesses. For instance, ML algorithms train NN weights by moving them along a low-dimensional subspace of their allowed values, but this implicitly low-dimensional learning structure is not properly exploited to improve training because its nature is not well understood. Moreover, trained NNs are easily confused by pervasive adversarial attacks whose theoretical underpinnings are still unclear. This thesis aims to improve our theoretical understanding of NNs and ML, with a particular focus on adversarial attacks and implicitly low-dimensional learning. For this purpose, we use mathematical tools from statistical mechanics to study different types of NNs and ways in which they can fit the data. In particular, we study two classes of models that fit the data with various degrees of learning and memorization: dense associative memory (DAM) and restricted Boltzmann machines (RBM). In the process, we investigate connections between different versions of these models that are useful to make analytical investigations more efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a thesis that applies statistical mechanics tools to dense associative memory (DAM) and restricted Boltzmann machines (RBM) to investigate implicitly low-dimensional learning in neural network training and the underpinnings of adversarial attacks, while also examining connections between model variants to facilitate analytical progress.
Significance. If the promised derivations and connections are carried through rigorously, the work could provide a physics-inspired framework for understanding generalization and robustness in ML; however, the abstract frames the contributions as aims rather than completed analyses with explicit results or validations.
major comments (2)
- [Abstract] Abstract (third paragraph): the central claims that DAM/RBM analyses 'reveal the nature of implicitly low-dimensional learning' and 'the underpinnings of adversarial attacks' are stated programmatically without any derivations, fitted quantities, or error analysis supplied, leaving the load-bearing assertions unevaluated.
- [Abstract] Abstract (second paragraph): the assumption that low-dimensional structure in NN training constitutes an equilibrium-like physical phenomenon amenable to stat-mech analysis of energy-based models is load-bearing for the claimed explanations; if the structure instead arises from SGD geometry or loss-landscape curvature, the DAM/RBM results would not transfer. A concrete test would be to check whether the equilibrium predictions match SGD-trained networks on identical tasks.
Simulated Author's Rebuttal
We thank the referee for their review of our thesis manuscript. We address the major comments point by point below, clarifying the scope of the completed analyses while acknowledging where the presentation can be improved.
read point-by-point responses
-
Referee: [Abstract] Abstract (third paragraph): the central claims that DAM/RBM analyses 'reveal the nature of implicitly low-dimensional learning' and 'the underpinnings of adversarial attacks' are stated programmatically without any derivations, fitted quantities, or error analysis supplied, leaving the load-bearing assertions unevaluated.
Authors: The abstract provides a high-level overview of the thesis goals and contributions. The full manuscript contains the detailed statistical mechanics derivations for both DAM and RBM models, including explicit calculations of energy functions, phase transitions, and connections between model variants that quantify low-dimensional structure and robustness properties. These are supported by analytical results on memorization capacity and adversarial vulnerability. We agree the abstract could more explicitly reference these completed results rather than framing them only as aims, and will revise it accordingly. revision: yes
-
Referee: [Abstract] Abstract (second paragraph): the assumption that low-dimensional structure in NN training constitutes an equilibrium-like physical phenomenon amenable to stat-mech analysis of energy-based models is load-bearing for the claimed explanations; if the structure instead arises from SGD geometry or loss-landscape curvature, the DAM/RBM results would not transfer. A concrete test would be to check whether the equilibrium predictions match SGD-trained networks on identical tasks.
Authors: We acknowledge this is a substantive point about the validity of the equilibrium approximation. The manuscript justifies the stat-mech approach by showing that the energy-based DAM and RBM models capture the effective low-dimensional fitting behavior and robustness characteristics observed in trained networks, with explicit mappings between model parameters and learning outcomes. We argue these models are chosen for their analytical tractability in revealing mechanisms that transfer to more general NNs. A direct head-to-head comparison of equilibrium predictions versus SGD dynamics on identical tasks is not included, as the thesis prioritizes deriving closed-form insights over numerical benchmarking; however, the work discusses the conditions under which the approximation is expected to hold. revision: partial
Circularity Check
No circularity detected; derivation self-contained
full rationale
The provided abstract and context contain no equations, fitted parameters, or self-citations that reduce any claimed prediction or result to its inputs by construction. The work applies standard statistical mechanics tools to established models (DAM, RBM) to analyze low-dimensional learning and adversarial attacks. No load-bearing step is shown to be self-definitional, a renamed fit, or dependent on an unverified author citation chain. The central claims rest on external mathematical tools and model properties rather than tautological re-derivation of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A committee of neural networks for traffic sign classification
Dan Cires ¸an, Ueli Meier, Jonathan Masci, and J¨urgen Schmidhuber. “A committee of neural networks for traffic sign classification”. In:The 2011 International Joint Conference on Neural Networks. 2011, pp. 1918–1921.DOI:10.1109/IJCNN.2011.6033458
-
[2]
OpenAI et al.GPT-4 Technical Report. 2024. arXiv: 2303 . 08774 [cs.CL].URL: https : //arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Highly accurate protein structure prediction with AlphaFold
John Jumper et al. “Highly accurate protein structure prediction with AlphaFold”. In:Nature596.7873 (Aug. 2021), pp. 583–589.ISSN: 1476-4687.DOI: 10.1038/s41586- 021- 03819- 2 .URL: https://doi.org/10.1038/s41586-021-03819-2
-
[4]
Accurate structure prediction of biomolecular interactions with AlphaFold 3
Josh Abramson et al. “Accurate structure prediction of biomolecular interactions with AlphaFold 3”. In:Nature630.8016 (June 2024), pp. 493–500.ISSN: 1476-4687.DOI: 10.1038/s41586-024- 07487-w.URL:https://doi.org/10.1038/s41586-024-07487-w
-
[5]
AlphaFold2 and its applications in the fields of biology and medicine
Zhenyu Yang, Xiaoxi Zeng, Yi Zhao, and Runsheng Chen. “AlphaFold2 and its applications in the fields of biology and medicine”. In:Signal Transduction and Targeted Therapy8.1 (Mar. 2023), p. 115. ISSN: 2059-3635.DOI: 10.1038/s41392- 023- 01381- z.URL: https://doi.org/10. 1038/s41392-023-01381-z
-
[6]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. “High- Resolution Image Synthesis With Latent Diffusion Models”. In:Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). June 2022, pp. 10684–10695.DOI: 10.48550/arXiv.2112.10752
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.10752 2022
-
[8]
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. “Gradient-based learning applied to document recognition”. In:Proceedings of the IEEE86.11 (1998), pp. 2278–2324.DOI: 10.1109/5.726791
-
[9]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks”. In:International Conference on Learning Representations. 2019.DOI: https: / / doi . org / 10 . 48550 / arXiv . 1803 . 03635.URL: https : / / openreview . net / forum?id=rJl-b3RcF7. 148
2019
-
[10]
The training process of many deep networks explores the same low-dimensional manifold
Jialin Mao et al. “The training process of many deep networks explores the same low-dimensional manifold”. In:Proceedings of the National Academy of Sciences121.12 (2024), e2310002121.DOI: 10. 1073/pnas.2310002121. eprint: https://www.pnas.org/doi/pdf/10.1073/pnas. 2310002121.URL:https://www.pnas.org/doi/abs/10.1073/pnas.2310002121
-
[11]
Evasion Attacks against Machine Learning at Test Time
Battista Biggio et al. “Evasion Attacks against Machine Learning at Test Time”. In:Machine Learning and Knowledge Discovery in Databases. Ed. by Hendrik Blockeel, Kristian Kersting, Siegfried Nijssen, and Filip ˇZelezn´y. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013, pp. 387–402.ISBN: 978-3-642-40994-3.DOI:https://doi.org/10.1007/978-3-642-40994-3_25
-
[12]
Intriguing properties of neural networks
Christian Szegedy et al. “Intriguing properties of neural networks”. In:arXiv e-prints, arXiv:1312.6199 (Dec. 2013), arXiv:1312.6199.DOI: 10 . 48550 / arXiv . 1312 . 6199. arXiv: 1312 . 6199 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[13]
Adversarial Attacks on Traffic Sign Recog- nition: A Survey
Svetlana Pavlitska, Nico Lambing, and J. Marius Z¨ollner. “Adversarial Attacks on Traffic Sign Recog- nition: A Survey”. In:2023 3rd International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME). 2023, pp. 1–6.DOI: 10 . 1109 / ICECCME57830 . 2023.10252727
-
[14]
ImageNet: A large-scale hierarchical image database
Jia Deng et al. “ImageNet: A large-scale hierarchical image database”. In:2009 IEEE Conference on Computer Vision and Pattern Recognition. 2009, pp. 248–255.DOI: 10.1109/CVPR.2009. 5206848
-
[15]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. “EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES”. In:stat1050, arXiv:1412.6572 (2015), p. 20.DOI: 10.48550/ arXiv . 1412 . 6572. arXiv: 1412 . 6572 [stat.ML].URL: https : / / doi . org / 10 . 48550/arXiv.1412.6572
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Modeling the Influence of Data Structure on Learning in Neural Networks: The Hidden Manifold Model
Sebastian Goldt, Marc M´ezard, Florent Krzakala, and Lenka Zdeborov´a. “Modeling the Influence of Data Structure on Learning in Neural Networks: The Hidden Manifold Model”. In:Phys. Rev. X10 (4 Dec. 2020), p. 041044.DOI: 10.1103/PhysRevX.10.041044.URL: https://link.aps. org/doi/10.1103/PhysRevX.10.041044
-
[17]
Generalisa- tion error in learning with random features and the hidden manifold model*
Federica Gerace, Bruno Loureiro, Florent Krzakala, Marc M´ezard, and Lenka Zdeborov´a. “Generalisa- tion error in learning with random features and the hidden manifold model*”. In:Journal of Statistical Mechanics: Theory and Experiment2021.12 (Dec. 2021), p. 124013.DOI: 10 . 1088 / 1742 - 5468/ac3ae6.URL:https://dx.doi.org/10.1088/1742-5468/ac3ae6
-
[18]
Kasimir Tanner, Matteo Vilucchio, Bruno Loureiro, and Florent Krzakala.A High Dimensional Statistical Model for Adversarial Training: Geometry and Trade-Offs. 2024.DOI: 10 . 48550 / arXiv.2402.05674. arXiv: 2402.05674 [stat.ML].URL: https://arxiv.org/abs/ 2402.05674
-
[19]
Matteo Vilucchio, Nikolaos Tsilivis, Bruno Loureiro, and Julia Kempe.On the Geometry of Regular- ization in Adversarial Training: High-Dimensional Asymptotics and Generalization Bounds. 2024. DOI: 10 . 48550 / arXiv . 2410 . 16073. arXiv: 2410 . 16073 [stat.ML].URL: https : //arxiv.org/abs/2410.16073. 149
-
[20]
On the existence of consistent adversarial attacks in high-dimensional linear classification
Matteo Vilucchio, Lenka Zdeborov ´a, and Bruno Loureiro.On the existence of consistent adversarial attacks in high-dimensional linear classification. 2025.DOI: 10.48550/arXiv.2506.12454 . arXiv:2506.12454 [stat.ML].URL:https://arxiv.org/abs/2506.12454
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.12454 2025
-
[21]
Jean Barbier, Francesco Camilli, Minh-Toan Nguyen, Mauro Pastore, and Rudy Skerk.Optimal generalisation and learning transition in extensive-width shallow neural networks near interpolation
- [22]
-
[23]
WORLD SCIENTIFIC, 2023.DOI: 10.1142/13341
Patrick Charbonneau et al.Spin Glass Theory and Far Beyond. WORLD SCIENTIFIC, 2023.DOI: 10.1142/13341. eprint: https://www.worldscientific.com/doi/pdf/10.1142/ 13341.URL:https://www.worldscientific.com/doi/abs/10.1142/13341
-
[24]
Neural networks and physical systems with emergent collective computational abilities
J. J. Hopfield. “Neural networks and physical systems with emergent collective computational abilities.” In:Proceedings of the National Academy of Sciences79.8 (1982), pp. 2554–2558.DOI: 10.1073/ pnas.79.8.2554. eprint: https://www.pnas.org/doi/pdf/10.1073/pnas.79.8. 2554.URL:https://www.pnas.org/doi/abs/10.1073/pnas.79.8.2554
-
[25]
Training Products of Experts by Minimizing Contrastive Divergence
Geoffrey E. Hinton. “Training Products of Experts by Minimizing Contrastive Divergence”. In:Neural Computation14.8 (2002), pp. 1771–1800.DOI:10.1162/089976602760128018
-
[26]
High order correlation model for associative memory
H. H. Chen et al. “High order correlation model for associative memory”. In:AIP Conference Proceedings151.1 (Aug. 1986), pp. 86–99.ISSN: 0094-243X.DOI: 10.1063/1.36224 . eprint: https://pubs.aip.org/aip/acp/article- pdf/151/1/86/12091820/86\_1\ _online.pdf.URL:https://doi.org/10.1063/1.36224
-
[27]
Nonlinear discriminant functions and associative memories
Demetri Psaltis and Cheol Hoon Park. “Nonlinear discriminant functions and associative memories”. In:AIP Conference Proceedings151.1 (Aug. 1986), pp. 370–375.ISSN: 0094-243X.DOI: 10.1063/ 1.36241 . eprint: https://pubs.aip.org/aip/acp/article- pdf/151/1/370/ 12091772/370\_1\_online.pdf.URL:https://doi.org/10.1063/1.36241
-
[29]
Multiconnected neural network models
E Gardner. “Multiconnected neural network models”. In:Journal of Physics A: Mathematical and General20.11 (Aug. 1987), p. 3453.DOI: 10.1088/0305-4470/20/11/046 .URL: https: //dx.doi.org/10.1088/0305-4470/20/11/046
-
[30]
Capacities of multiconnected memory models
Horn, D. and Usher, M. “Capacities of multiconnected memory models”. In:J. Phys. France49.3 (1988), pp. 389–395.DOI: 10.1051/jphys:01988004903038900 .URL: https://doi. org/10.1051/jphys:01988004903038900
-
[31]
Dense Associative Memory for Pattern Recognition
Dmitry Krotov and John J. Hopfield. “Dense Associative Memory for Pattern Recognition”. In: Advances in Neural Information Processing Systems. Ed. by D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett. V ol. 29. NIPS’16. Barcelona, Spain: Curran Associates, Inc., 2016, pp. 1180– 1188.ISBN: 9781510838819.DOI: 10 . 48550 / arXiv . 1606 . 01164. arXiv...
2016
-
[32]
Spectral dynamics of learning in restricted Boltzmann machines
A. Decelle, G. Fissore, and C. Furtlehner. “Spectral dynamics of learning in restricted Boltzmann machines”. In:Europhysics Letters119.6 (Nov. 2017), p. 60001.DOI: 10.1209/0295- 5075/ 119/60001.URL:https://dx.doi.org/10.1209/0295-5075/119/60001
-
[35]
Waddington landscape for prototype learning in generalized Hopfield networks
Nacer Eddine Boukacem et al. “Waddington landscape for prototype learning in generalized Hopfield networks”. In:Phys. Rev. Res.6 (3 July 2024), p. 033098.DOI: 10.1103/PhysRevResearch. 6 . 033098.URL: https : / / link . aps . org / doi / 10 . 1103 / PhysRevResearch . 6 . 033098
-
[36]
Nicolas Bereux, Aur´elien Decelle, Cyril Furtlehner, Lorenzo Rosset, and Beatriz Seoane.Fast training and sampling of Restricted Boltzmann Machines. 15 figures, 31 pages. Singaour, Singapore, Apr. 2025.DOI: 10.48550/arXiv.2405.15376.URL: https://inria.hal.science/hal- 04885777
-
[37]
Dense Associative Memory is Robust to Adversarial Inputs
Dmitry Krotov and John Hopfield. “Dense Associative Memory Is Robust to Adversarial Inputs”. In: Neural Computation30.12 (Dec. 2018), pp. 3151–3167.ISSN: 0899-7667.DOI: 10.1162/neco_ a_01143. arXiv: 1701.00939 [cs.LG].URL: https://doi.org/10.1162/neco%5C_ a%5C_01143
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/neco_ 2018
-
[38]
Yang Song et al.Score-Based Generative Modeling through Stochastic Differential Equations. 2021. arXiv:2011.13456 [cs.LG].URL:https://arxiv.org/abs/2011.13456
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Hopfield Networks is All You Need
Hubert Ramsauer et al. “Hopfield Networks is All You Need”. In:International Conference on Learning Representations. 2021.DOI: 10.48550/arXiv.2008.02217. arXiv: 2008.02217 [cs.NE].URL:https://openreview.net/forum?id=tL89RnzIiCd
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2008.02217 2021
-
[40]
Phase transitions in Restricted Boltzmann Machines with generic priors
Adriano Barra, Giuseppe Genovese, Peter Sollich, and Daniele Tantari. “Phase transitions in restricted Boltzmann machines with generic priors”. In:Phys. Rev. E96 (4 Oct. 2017), p. 042156.DOI: 10. 1103/PhysRevE.96.042156 . arXiv: 1612.03132 [cond-mat.dis-nn] .URL: https: //link.aps.org/doi/10.1103/PhysRevE.96.042156
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physreve.96.042156 2017
-
[41]
Aurelien Decelle, Sungmin Hwang, Jacopo Rocchi, and Daniele Tantari. “Inverse problems for structured datasets using parallel TAP equations and restricted Boltzmann machines”. In:Scientific Reports11, 19990 (Oct. 2021), p. 19990.DOI: 10 . 1038 / s41598 - 021 - 99353 - 2. arXiv: 1906.11988 [cond-mat.dis-nn]. 151
-
[42]
Replica Symmetry Breaking in Dense Hebbian Neural Networks
Linda Albanese, Francesco Alemanno, Andrea Alessandrelli, and Adriano Barra. “Replica Symmetry Breaking in Dense Hebbian Neural Networks”. In:Journal of Statistical Physics189.2, 24 (Nov. 2022), p. 24.ISSN: 1572-9613.DOI: 10.1007/s10955-022-02966-8 . arXiv: 2111.12997 [cond-mat.dis-nn].URL:https://doi.org/10.1007/s10955-022-02966-8
-
[43]
Minimal model of permutation symme- try in unsupervised learning
Tianqi Hou, K Y Michael Wong, and Haiping Huang. “Minimal model of permutation symme- try in unsupervised learning”. In:Journal of Physics A: Mathematical and Theoretical52.41 (Sept. 2019), p. 414001.DOI: 10 . 1088 / 1751 - 8121 / ab3f3f . arXiv: 1904 . 13052 [cond-mat.dis-nn].URL:https://dx.doi.org/10.1088/1751-8121/ab3f3f
-
[44]
Hopfield model with planted patterns: A teacher-student self-supervised learning model
Francesco Alemanno, Luca Camanzi, Gianluca Manzan, and Daniele Tantari. “Hopfield model with planted patterns: A teacher-student self-supervised learning model”. In:Applied Mathematics and Computation458 (2023), p. 128253.ISSN: 0096-3003.DOI: https://doi.org/10.1016/ j.amc.2023.128253 . arXiv: 2304.13710 [cond-mat.dis-nn] .URL: https://www. sciencedirect....
-
[45]
The effect of priors on Learning with Restricted Boltzmann Ma- chines
Gianluca Manzan and Daniele Tantari. “The effect of priors on Learning with Restricted Boltzmann Ma- chines”. In:Physica A: Statistical Mechanics and its Applications674 (2025), p. 130766.ISSN: 0378- 4371.DOI: 10.1016/j.physa.2025.130766 .URL: https://www.sciencedirect. com/science/article/pii/S0378437125004182
-
[46]
Dense Hopfield networks in the teacher-student setting
Robin Th´eriault and Daniele Tantari. “Dense Hopfield networks in the teacher-student setting”. In: SciPost Phys.17 (2024), p. 040.DOI: 10.21468/SciPostPhys.17.2.040 .URL: https: //scipost.org/10.21468/SciPostPhys.17.2.040
-
[47]
Modeling structured data learning with Restricted Boltzmann machines in the teacher–student setting
Robin Th ´eriault, Francesco Tosello, and Daniele Tantari. “Modeling structured data learning with Restricted Boltzmann machines in the teacher–student setting”. In:Neural Networks189 (2025), p. 107542.ISSN: 0893-6080.DOI: https : / / doi . org / 10 . 1016 / j . neunet . 2025.107542.URL: https://www.sciencedirect.com/science/article/pii/ S0893608025004216
-
[48]
Saddle hierarchy in dense associative memory
Robin Th´eriault and Daniele Tantari. “Saddle hierarchy in dense associative memory”. In:Machine Learning: Science and Technology7.1 (Jan. 2026), p. 015001.DOI: 10 . 1088 / 2632 - 2153 / ae3051.URL:https://doi.org/10.1088/2632-2153/ae3051
-
[49]
On the quantitative analysis of deep belief networks
Ruslan Salakhutdinov and Iain Murray. “On the quantitative analysis of deep belief networks”. In:Proceedings of the 25th International Conference on Machine Learning. ICML ’08. Helsinki, Finland: Association for Computing Machinery, 2008, pp. 872–879.ISBN: 9781605582054.DOI: 10.1145/1390156.1390266.URL:https://doi.org/10.1145/1390156.1390266
work page doi:10.1145/1390156.1390266.url:https://doi.org/10.1145/1390156.1390266 2008
-
[50]
Associative recall of memory without errors
I. Kanter and H. Sompolinsky. “Associative recall of memory without errors”. In:Phys. Rev. A35 (1 Jan. 1987), pp. 380–392.DOI: 10.1103/PhysRevA.35.380.URL: https://link.aps. org/doi/10.1103/PhysRevA.35.380
-
[51]
Increasing the capacity of a hopfield network without sacrificing functionality
Amos Storkey. “Increasing the capacity of a hopfield network without sacrificing functionality”. In: Artificial Neural Networks — ICANN’97. Ed. by Wulfram Gerstner, Alain Germond, Martin Hasler, and Jean-Daniel Nicoud. Berlin, Heidelberg: Springer Berlin Heidelberg, 1997, pp. 451–456. 152
1997
-
[52]
On the equivalence of Hopfield networks and Boltzmann Machines
Adriano Barra, Alberto Bernacchia, Enrica Santucci, and Pierluigi Contucci. “On the equivalence of Hopfield networks and Boltzmann Machines”. In:Neural Networks34 (2012), pp. 1–9.ISSN: 0893-6080.DOI: https://doi.org/10.1016/j.neunet.2012.06.003 .URL: https: //www.sciencedirect.com/science/article/pii/S0893608012001608
-
[53]
Daydreaming Hopfield Networks and their surprising effectiveness on correlated data
Ludovica Serricchio et al. “Daydreaming Hopfield Networks and their surprising effectiveness on correlated data”. In:Neural Networks186 (2025), p. 107216.ISSN: 0893-6080.DOI: https://doi. org/10.1016/j.neunet.2025.107216 .URL: https://www.sciencedirect.com/ science/article/pii/S0893608025000954
-
[54]
Psychology press, 2005.ISBN: 9781410612403.DOI:https://doi.org/10.4324/9781410612403
Donald Olding Hebb.The organization of behavior: A neuropsychological theory. Psychology press, 2005.ISBN: 9781410612403.DOI:https://doi.org/10.4324/9781410612403
-
[55]
Storing Infinite Numbers of Patterns in a Spin-Glass Model of Neural Networks
Daniel J. Amit, Hanoch Gutfreund, and H. Sompolinsky. “Storing Infinite Numbers of Patterns in a Spin-Glass Model of Neural Networks”. In:Phys. Rev. Lett.55 (14 Sept. 1985), pp. 1530–1533.DOI: 10.1103/PhysRevLett.55.1530 .URL: https://link.aps.org/doi/10.1103/ PhysRevLett.55.1530
-
[56]
Statistical mechanics of neural networks near saturation
Daniel J Amit, Hanoch Gutfreund, and H Sompolinsky. “Statistical mechanics of neural networks near saturation”. In:Annals of Physics173.1 (1987), pp. 30–67.ISSN: 0003-4916.DOI: https://doi. org/10.1016/0003-4916(87)90092-3 .URL: https://www.sciencedirect.com/ science/article/pii/0003491687900923
-
[57]
Information storage in neural networks with low levels of activity
Daniel J. Amit, Hanoch Gutfreund, and H. Sompolinsky. “Information storage in neural networks with low levels of activity”. In:Phys. Rev. A35 (5 Mar. 1987), pp. 2293–2303.DOI: 10.1103/PhysRevA. 35.2293.URL:https://link.aps.org/doi/10.1103/PhysRevA.35.2293
-
[58]
The perceptron: A probabilistic model for information storage and organization in the brain
F. Rosenblatt. “The perceptron: A probabilistic model for information storage and organization in the brain.” In:Psychological Review65.6 (1958), pp. 386–408.DOI: 10.1037/h0042519.URL: https://doi.org/10.1037/h0042519
-
[59]
Maximum Likelihood from Incomplete Data Via the EM Algorithm
A. P. Dempster, N. M. Laird, and D. B. Rubin. “Maximum Likelihood from Incomplete Data Via the EM Algorithm”. In:Journal of the Royal Statistical Society: Series B (Methodological)39.1 (1977), pp. 1–22.DOI: https://doi.org/10.1111/j.2517-6161.1977.tb01600.x . eprint: https://rss.onlinelibrary.wiley.com/doi/pdf/10.1111/j.2517- 6161 . 1977 . tb01600 . x.URL...
-
[60]
Sebastian Ruder.An overview of gradient descent optimization algorithms. 2017. arXiv:1609.04747 [cs.LG].URL:https://arxiv.org/abs/1609.04747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[61]
Statistical physics of inference: thresholds and algorithms
Lenka Zdeborov´a and Florent Krzakala. “Statistical physics of inference: thresholds and algorithms”. In:Advances in Physics65.5 (2016), pp. 453–552.DOI: 10.1080/00018732.2016.1211393. arXiv: 1511 . 02476 [cond-mat.stat-mech].URL: https : / / doi . org / 10 . 1080 / 00018732.2016.1211393
-
[62]
E Gardner and B Derrida. “Three unfinished works on the optimal storage capacity of networks”. In: Journal of Physics A: Mathematical and General22.12 (June 1989), p. 1983.DOI: 10.1088/0305- 4470/22/12/004.URL:https://dx.doi.org/10.1088/0305-4470/22/12/004. 153
-
[63]
First-order transition to perfect generalization in a neural network with binary synapses
G´eza Gy ¨orgyi. “First-order transition to perfect generalization in a neural network with binary synapses”. In:Phys. Rev. A41 (12 June 1990), pp. 7097–7100.DOI: 10 . 1103 / PhysRevA . 41.7097.URL:https://link.aps.org/doi/10.1103/PhysRevA.41.7097
-
[64]
Large Associative Memory Problem in Neurobiology and Ma- chine Learning
Dmitry Krotov and John J. Hopfield. “Large Associative Memory Problem in Neurobiology and Ma- chine Learning”. In:International Conference on Learning Representations. 2021.DOI: 10.48550/ arXiv.2008.06996 . arXiv: 2008.06996 [q-bio.NC] .URL: https://openreview. net/forum?id=X4y_10OX-hX
-
[65]
Dmitry Krotov, Benjamin Hoover, Parikshit Ram, and Bao Pham.Modern Methods in Associative Memory. 2025. arXiv: 2507 . 06211 [cs.LG].URL: https : / / arxiv . org / abs / 2507 . 06211
2025
-
[66]
Benjamin Hoover et al. “Memory in Plain Sight: A Survey of the Uncanny Resemblances between Diffusion Models and Associative Memories”. In:arXiv e-prints, arXiv:2309.16750 (Sept. 2023), arXiv:2309.16750.DOI:10.48550/arXiv.2309.16750. arXiv:2309.16750 [cs.LG]
-
[67]
Attention in a Family of Boltzmann Machines Emerging From Modern Hopfield Networks
Toshihiro Ota and Ryo Karakida. “Attention in a Family of Boltzmann Machines Emerging From Modern Hopfield Networks”. In:Neural Computation35.8 (July 2023), pp. 1463–1480.ISSN: 0899- 7667.DOI: 10 . 1162 / neco _ a _ 01597. eprint: https : / / direct . mit . edu / neco / article- pdf/35/8/1463/2143211/neco\_a\_01597.pdf .URL: https://doi. org/10.1162/neco%...
-
[68]
In Search of Dispersed Memories: Generative Diffusion Models Are Associative Memory Networks
Luca Ambrogioni. “In Search of Dispersed Memories: Generative Diffusion Models Are Associative Memory Networks”. In:Entropy26.5 (2024).ISSN: 1099-4300.DOI: 10.3390/e26050381.URL: https://www.mdpi.com/1099-4300/26/5/381
- [69]
-
[70]
Restricted Boltzmann machines for collaborative filtering
Ruslan Salakhutdinov, Andriy Mnih, and Geoffrey Hinton. “Restricted Boltzmann machines for collaborative filtering”. In:Proceedings of the 24th International Conference on Machine Learning. ICML ’07. Corvalis, Oregon, USA: Association for Computing Machinery, 2007, pp. 791–798.ISBN: 9781595937933.DOI: 10.1145/1273496.1273596.URL: https://doi.org/10.1145/ ...
-
[71]
Some generalized order-disorder transformations
Renfrey Burnard Potts. “Some generalized order-disorder transformations”. In:Mathematical proceed- ings of the cambridge philosophical society. V ol. 48. 1. Cambridge University Press. 1952, pp. 106– 109.DOI:10.1017/S0305004100027419
-
[72]
The potts model
Fa-Yueh Wu. “The potts model”. In:Reviews of modern physics54.1 (1982), p. 235.DOI: 10.1103/ RevModPhys.54.235
1982
-
[73]
Restricted Boltzmann machine: Recent advances and mean- field theory*
Aur´elien Decelle and Cyril Furtlehner. “Restricted Boltzmann machine: Recent advances and mean- field theory*”. In:Chinese Physics B30.4 (Apr. 2021), p. 040202.DOI: 10.1088/1674-1056/ abd160.URL:https://dx.doi.org/10.1088/1674-1056/abd160. 154
-
[74]
Exact results and critical properties of the Ising model with competing interactions
H Nishimori. “Exact results and critical properties of the Ising model with competing interactions”. In:Journal of Physics C: Solid State Physics13.21 (July 1980), p. 4071.DOI: 10.1088/0022- 3719/13/21/012.URL:https://dx.doi.org/10.1088/0022-3719/13/21/012
-
[75]
Oxford University Press, July 2001.ISBN: 9780198509417.DOI: 10
Hidetoshi Nishimori.Statistical Physics of Spin Glasses and Information Processing: An Introduction. Oxford University Press, July 2001.ISBN: 9780198509417.DOI: 10 . 1093 / acprof : oso / 9780198509417.001.0001. eprint: https://academic.oup.com/book/5185/book- pdf/54038185/acprof-9780198509400.pdf .URL: https://doi.org/10.1093/ acprof:oso/9780198509417.001.0001
-
[76]
Spin Glass Identities and the Nishimori Line
Pierluigi Contucci, Cristian Giardin`a, and Hidetoshi Nishimori. “Spin Glass Identities and the Nishi- mori Line”. In:Spin Glasses: Statics and Dynamics. Ed. by Anne Boutet de Monvel and Anton Bovier. Basel: Birkh ¨auser Basel, 2009, pp. 103–121.DOI: https://doi.org/10.1007/978- 3- 7643-9891-0_4. arXiv:0805.0754 [cond-mat.dis-nn]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978- 2009
-
[77]
The Nishimori line and Bayesian Statistics
Yukito Iba. “The Nishimori line and Bayesian statistics”. In:Journal of Physics A Mathematical General32.21 (May 1999), pp. 3875–3888.DOI: 10.1088/0305-4470/32/21/302 . arXiv: cond-mat/9809190 [cond-mat.dis-nn]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1088/0305-4470/32/21/302 1999
-
[78]
Algorithmic barriers from phase transitions
Dimitris Achlioptas and Amin Coja-Oghlan. “Algorithmic Barriers from Phase Transitions”. In: 2008 49th Annual IEEE Symposium on Foundations of Computer Science. 2008, pp. 793–802.DOI: 10.1109/FOCS.2008.11. arXiv:0803.2122 [math.CO]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/focs.2008.11 2008
-
[80]
Quiet Planting in the Locked Constraint Satisfaction Problems
Lenka Zdeborov´a and Florent Krzakala. “Quiet Planting in the Locked Constraint Satisfaction Prob- lems”. In:SIAM Journal on Discrete Mathematics25.2 (2011), pp. 750–770.DOI: 10 . 1137 / 090750755. arXiv: 0902.4185 [cond-mat.stat-mech].URL: https://doi.org/10. 1137/090750755
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[81]
Exponential Capacity of Dense Associative Memories
Carlo Lucibello and Marc M´ezard. “Exponential Capacity of Dense Associative Memories”. In:Phys. Rev. Lett.132 (7 Feb. 2024), p. 077301.DOI: 10.1103/PhysRevLett.132.077301 .URL: https://link.aps.org/doi/10.1103/PhysRevLett.132.077301
-
[82]
Using Boltzmann Machines for probability estimation
Bert Kappen. “Using Boltzmann Machines for probability estimation”. In:ICANN ’93. Ed. by Stan Gielen and Bert Kappen. London: Springer London, 1993, pp. 521–526.ISBN: 978-1-4471-2063-6
1993
-
[83]
Deterministic learning rules for boltzmann machines
Hilbert J. Kappen. “Deterministic learning rules for boltzmann machines”. In:Neural Networks 8.4 (1995), pp. 537–548.ISSN: 0893-6080.DOI: https : / / doi . org / 10 . 1016 / 0893 - 6080(94)00112- Y.URL: https://www.sciencedirect.com/science/article/ pii/089360809400112Y
-
[84]
Symmetry Breaking and Training from Incomplete Data with Radial Basis Boltzmann Machines
Marcel J. Nijman and Hilbert J. Kappen. “Symmetry Breaking and Training from Incomplete Data with Radial Basis Boltzmann Machines”. In:International Journal of Neural Systems08.03 (1997), pp. 301–315.DOI: 10.1142/S0129065797000318. eprint: https://doi.org/10.1142/ S0129065797000318.URL:https://doi.org/10.1142/S0129065797000318. 155
-
[86]
Non- linear excitation of zonal flows by turbulent energy flux
Martin Kloppenburg and Paul Tavan. “Deterministic annealing for density estimation by multivariate normal mixtures”. In:Phys. Rev. E55 (3 Mar. 1997), R2089–R2092.DOI: 10.1103/PhysRevE. 55.R2089.URL:https://link.aps.org/doi/10.1103/PhysRevE.55.R2089
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.