LLM-as-a-Judge in Healthcare: A Scoping Analysis of Applications, Methods, and Human Alignment
Pith reviewed 2026-06-29 23:16 UTC · model grok-4.3
The pith
A review of 134 studies maps LLM-as-a-Judge uses in healthcare and finds moderate to strong human alignment that varies by task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
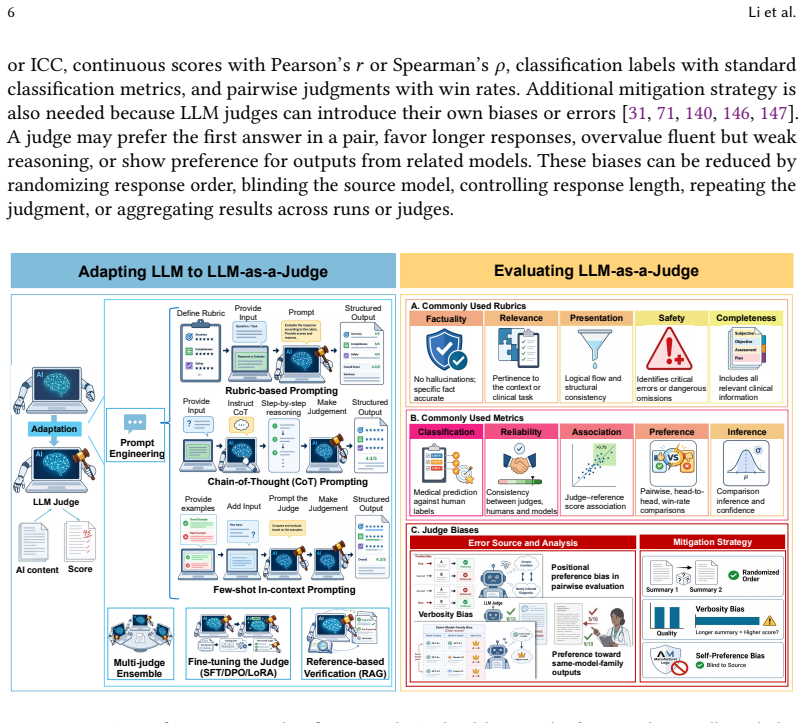
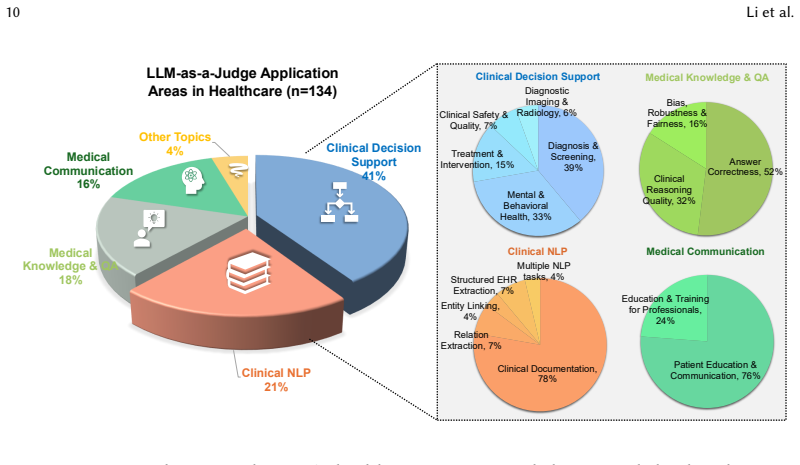
The review establishes that LLM-as-a-Judge appears most often in clinical decision support, clinical NLP, medical knowledge QA, and medical communication. OpenAI models serve as judges in the largest share of studies, nearly every study employs prompt engineering, and ensemble, multi-agent, or retrieval-augmented variants appear as frequent extensions. Among the subset of studies that include human validation, LLM judgments align moderately to strongly with expert judgments, although the degree of agreement differs markedly across tasks.
What carries the argument
The PRISMA-guided scoping review that screens five databases and codes each study on health scenario, judge configuration, technical approach, and validation design.
If this is right
- LLM-as-a-Judge can serve as a scalable evaluation tool inside clinical decision support and medical QA when human validation is performed.
- Prompt engineering remains the dominant technique, with ensemble and multi-agent designs as practical extensions.
- Reliability must be checked per task because alignment strength is not uniform.
- Clinical adoption requires continued attention to model choice and validation rigor rather than blanket deployment.
Where Pith is reading between the lines
- If the task-dependent alignment pattern persists, developers could prioritize validation effort on high-variability tasks first.
- The observed dominance of certain models suggests testing whether open-source alternatives achieve comparable agreement in the same healthcare scenarios.
- The concentration in four areas points to possible gaps in domains such as patient-facing monitoring or surgical planning that future studies could address.
Load-bearing premise
The 134 studies found through the database search form a representative sample of LLM-as-a-Judge work in healthcare and that the coding categories accurately reflect the main methodological differences.
What would settle it
A new literature search that locates many additional studies with markedly different application distributions or substantially lower human-LLM agreement rates would undermine the reported patterns.
Figures










read the original abstract
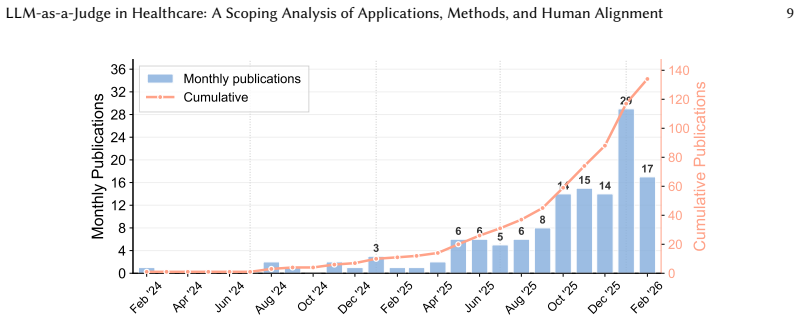
Large language models (LLMs) are increasingly deployed across healthcare applications, including clinical documentation, diagnostic reasoning, medicine recommendation, and medical education. Their outputs are largely unstructured clinical text, which is difficult to reliably evaluate at scale. LLM-as-a-Judge, in which an LLM evaluates another system's output against task-specific criteria, offers a scalable alternative and is increasingly used in clinical evaluation, yet its validity in healthcare remains underexamined. Existing reviews focus on general-purpose LLM evaluation or on risk framework, rather than systematically characterizing how LLM-as-a-Judge is applied in healthcare and how well their judgments align with human experts. We therefore conduct a PRISMA-guided comprehensive review of LLM-as-a-Judge applications in healthcare, searching five databases for studies published between January 2023 and February 2026. After screening 541 records, 134 studies meet the eligibility and are coded by health scenario, judge configuration, technical approach, and validation design. LLM-as-a-Judge is concentrated in clinical decision support, clinical natural language processing (NLP), medical knowledge and question answering (QA), and medical communication. OpenAI models are the most frequently used judges, and prompt engineering appears in nearly all studies, with ensemble, multi-agent, and retrieval-augmented designs as common extensions. Among studies reporting human validation, LLM judges often show moderate to strong alignment with expert judgments, although reliability varies substantially across tasks. Overall, this review positions LLM-as-a-Judge as a promising framework for scalable healthcare AI evaluation, while emphasizing that its clinical value depends on model design and rigorous validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a PRISMA-guided scoping review of LLM-as-a-Judge applications in healthcare. It searched five databases for studies from January 2023 to February 2026, screened 541 records, and included 134 studies that were coded on health scenario, judge configuration, technical approach, and validation design. Findings indicate concentration in clinical decision support, clinical NLP, medical QA, and communication; dominance of OpenAI models; near-universal use of prompt engineering with extensions like ensembles and RAG; and, among studies reporting human validation, moderate to strong alignment with expert judgments (with substantial task-to-task variability). The paper positions LLM-as-a-Judge as a promising scalable evaluation framework whose clinical value depends on model design and rigorous validation.
Significance. If the included corpus is representative and the coding reliable, the review supplies a useful field map that documents current practices and the uneven state of human-alignment evidence. This is valuable for guiding future work on scalable clinical AI evaluation. The PRISMA structure and multi-database search are strengths that lend some transparency to the synthesis.
major comments (1)
- [Methods] Methods (screening and coding description): The PRISMA process is summarized at a high level (541 records screened to 134 included), but the manuscript does not report the exact search strings, detailed eligibility criteria, or inter-coder reliability statistics for either the initial screening or the subsequent coding of health scenario, judge configuration, and validation design. This is load-bearing for the central claims, because statements about prevalence of applications and the frequency/strength of human alignment inherit any selection or reporting bias present in the 134-study sample.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on our scoping review. We address the single major comment below and will revise the manuscript accordingly to improve transparency.
read point-by-point responses
-
Referee: [Methods] Methods (screening and coding description): The PRISMA process is summarized at a high level (541 records screened to 134 included), but the manuscript does not report the exact search strings, detailed eligibility criteria, or inter-coder reliability statistics for either the initial screening or the subsequent coding of health scenario, judge configuration, and validation design. This is load-bearing for the central claims, because statements about prevalence of applications and the frequency/strength of human alignment inherit any selection or reporting bias present in the 134-study sample.
Authors: We agree that the current high-level summary of the PRISMA process limits reproducibility and that detailed reporting of search strings, eligibility criteria, and inter-coder reliability is necessary to support the prevalence and alignment claims. In the revised manuscript we will add the exact search strings used in each of the five databases, a complete enumerated list of eligibility criteria, and inter-coder reliability statistics (percentage agreement and Cohen’s kappa) for both the title/abstract screening and the full-text coding phases. revision: yes
Circularity Check
No circularity: scoping review with no derivations or predictions
full rationale
This is a PRISMA-guided scoping review that screens 541 records to include 134 studies, codes them by health scenario/judge configuration/validation design, and summarizes descriptive patterns such as concentration in clinical decision support and moderate-to-strong human alignment where reported. No equations, fitted parameters, predictions, or self-citation chains exist that could reduce any claim to its inputs by construction. The work is a literature synthesis whose central statements are empirical summaries of the screened corpus; the representativeness concern raised by the skeptic is a question of external validity and reporting transparency, not circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PRISMA guidelines for scoping reviews provide a valid and unbiased method for identifying and coding relevant studies
Reference graph
Works this paper leans on
-
[1]
Zandee van Rilland, Poonam Laxmappa Hosamani, Kevin R
Asad Aali, Vasiliki Bikia, Maya Varma, Nicole Chiou, Sophie Ostmeier, Arnav Singhvi, Magdalini Paschali, Ashwin Kumar, Andrew Johnston, Karimar Amador-Martinez, Eduardo Juan Perez Guerrero, Paola Naovi Cruz Rivera, Sergios Gatidis, Christian Bluethgen, Eduardo Pontes Reis, Eddy D. Zandee van Rilland, Poonam Laxmappa Hosamani, Kevin R. Keet, Minjoung Go, E...
-
[2]
Tassallah Abdullahi, Shrestha Ghosh, Hamish S Fraser, Daniel León Tramontini, Adeel Abbasi, Ghada Bourjeily, Carsten Eickhoff, and Ritambhara Singh. 2026. The Persona Paradox: Medical Personas as Behavioral Priors in Clinical Language Models.arXiv preprint arXiv:2601.05376(2026)
-
[3]
Ali Abedi, Charlene H Chu, and Shehroz S Khan. 2026. Evidence-Informed Guidance on Cannabidiol Use in Older Adults: Development and Evaluation of Retrieval-Augmented Large Language Models.arXiv preprint arXiv:2604.09548 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Moaiz Abrar, Yusuf Sermet, and Ibrahim Demir. 2025. An empirical evaluation of large language models on consumer health questions.BioMedInformatics5, 1 (2025), 12
2025
- [5]
-
[6]
Shefayat E Shams Adib, Ahmed Alfey Sani, Ekramul Alam Esham, Ajwad Abrar, and Tareque Mohmud Chowdhury
- [7]
-
[8]
Kiran Adnan, Rehan Akbar, Siak Wang Khor, and Adnan Bin Amanat Ali. 2020. Role and challenges of unstructured big data in healthcare.Data management, analytics and innovation(2020), 301–323
2020
- [9]
-
[10]
Abdel-Karim Al Tamimi, Jacob Andrews, Jacqueline Benfield, Cath Sweby, Chris Gilmartin, Rebecca Lindley, Diane Trusson, Molly Dziunka, Dee Webster, and Kathryn Radford. 2026. Development and Qualitative Evaluation of R-Speak: Acceptability and Usability of a Smartphone App System Using AI to Enhance Communication in People With Expressive Aphasia. (2026)
2026
- [11]
-
[12]
Elham Asgari, Nina Montaña-Brown, Magda Dubois, Saleh Khalil, Jasmine Balloch, Joshua Au Yeung, and Dominic Pimenta. 2025. A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation. NPJ digital medicine8, 1 (2025), 274
2025
-
[13]
Abeer Badawi, Elahe Rahimi, Md Tahmid Rahman Laskar, Sheri Grach, Lindsay Bertrand, Lames Danok, Prathiba Dhanesh, Jimmy Xiangji Huang, Frank Rudzicz, and Elham Dolatabadi. 2026. When can we trust llms in mental LLM-as-a-Judge in Healthcare: A Scoping Analysis of Applications, Methods, and Human Alignment 25 health? large-scale benchmarks for reliable llm...
2026
- [14]
-
[15]
Kate H Bentley, Luca Belli, Adam M Chekroud, Emily J Ward, Emily R Dworkin, Emily Van Ark, Kelly M Johnston, Will Alexander, Millard Brown, and Matt Hawrilenko. 2026. VERA-MH: Reliability and Validity of an Open-Source AI Safety Evaluation in Mental Health.arXiv preprint arXiv:2602.05088(2026)
-
[16]
Matthias Blondeel, Noel Codella, Sam Preston, Hao Qiu, Leonardo Schettini, Frank Tuan, Wen-wai Yim, Smitha Saligrama, Mert Öz, Shrey Jain, Matthew P. Lungren, and Thomas Osborne. 2025. Healthcare Agent Orchestrator (HAO) for Patient Summarization in Molecular Tumor Boards.arXiv preprint arXiv:2509.06602(2025)
- [17]
-
[18]
Marco Bolpagni, Simone De Carli, Leonardo Sanna, Mauro Dragoni, and Silvia Gabrielli. 2025. VALISE: A Virtual Agent Laboratory for Instruction-Following Simulation and Evaluation of LLM-Powered Digital Health Interventions. InFrontiers in Artificial Intelligence and Applications. Vol. 413. 5096–5099
2025
- [19]
- [20]
- [21]
- [22]
-
[23]
Xiuyuan Chen, Tao Sun, Dexin Su, Ailing Yu, Junwei Liu, Zhe Chen, Gangzeng Jin, Xin Wang, Jingnan Liu, Hansong Xiao, Hualei Zhou, Dongjie Tao, Chunxiao Guo, Minghui Yang, Yuan Xia, Jing Zhao, Qianrui Fan, Yanyun Wang, Shuai Zhen, Kezhong Chen, Jun Wang, Zewen Sun, Heng Zhao, Tian Guan, Shaodong Wang, Geyun Chang, Jiaming Deng, Hongchengcheng Chen, Kexin F...
-
[24]
Yuhao Chen, Bo Wen, and Farhana Zulkernine. 2025. A Multiagent Summarization and Auto-Evaluation Framework for Medical Text: Development and Evaluation Study.JMIR AI4 (2025), e75932
2025
-
[25]
Zhihui Chen and Mengling Feng. 2025. Med-Banana-50K: A Cross-modality Large-Scale Dataset for Text-guided Medical Image Editing.arXiv preprint arXiv:2511.00801(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Miller, Majid Afshar, and Yanjun Gao
He Cheng, Yifu Wu, Saksham Khatwani, Maya Kruse, Dmitriy Dligach, Timothy A. Miller, Majid Afshar, and Yanjun Gao. 2026. Scaling Biomedical Knowledge Graph Retrieval for Interpretable Reasoning: Applications to Clinical Diagnosis Prediction.medRxiv(2026). doi:10.64898/2026.01.12.26343957
-
[27]
Cheng-Han Chiang, Hung-yi Lee, and Michal Lukasik. 2025. Tract: Regression-aware fine-tuning meets chain-of- thought reasoning for llm-as-a-judge. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2934–2952
2025
-
[28]
Philip Chung, Akshay Swaminathan, Alex J. Goodell, Yeasul Kim, S. Momsen Reincke, Lichy Han, Ben Deverett, Mohammad Amin Sadeghi, Abdel-Badih Ariss, Marc Ghanem, David Seong, Andrew A. Lee, Caitlin E. Coombes, Brad Bradshaw, Mahir A. Sufian, Hyo Jung Hong, Teresa P. Nguyen, Mohammad R. Rasouli, Komal Kamra, Mark A. Burbridge, James C. McAvoy, Roya Saffary...
-
[29]
Ionut, Croitoru, Cristina Elena Turcu, and Corneliu Octavian Turcu. 2026. Privacy-by-Design in AI-Assisted Systems for Caregivers of Children with Autism: A Secure Multi-Agent Architecture.Applied Sciences16, 4 (2026), 2157
2026
-
[30]
Churpek, Anoop Mayampurath, Frank Liao, Cherodeep Goswami, Karen K
Emma Croxford, Yanjun Gao, Elliot First, Nicholas Pellegrino, Miranda Schnier, John Caskey, Madeline Oguss, Graham Wills, Guanhua Chen, Dmitriy Dligach, Matthew M. Churpek, Anoop Mayampurath, Frank Liao, Cherodeep Goswami, Karen K. Wong, Brian W. Patterson, and Majid Afshar. 2025. Evaluating clinical AI summaries with large language models as judges.npj D...
2025
-
[31]
Corey Curran, Nafis Neehal, Keerthiram Murugesan, and Kristin P Bennett. 2024. Examining trustworthiness of llm-as-a-judge systems in a clinical trial design benchmark. In2024 IEEE International Conference on Big Data (BigData). 26 Li et al. IEEE, 4627–4631
2024
-
[32]
Hong-Jie Dai, Zheng-Hao Li, An-Tai Lu, Bo-Tsz Shain, Ming-Ta Li, Tatheer Hussain Mir, Kuang-Te Wang, Min-I Su, Pei-Kang Liu, and Ming-Ju Tsai. 2025. Model selection meets clinical semantics: Optimizing ICD-10-CM prediction via LLM-as-Judge evaluation, redundancy-aware sampling, and section-aware fine-tuning.arXiv preprint arXiv:2509.18846 (2025)
-
[33]
Amanda Dawson and Sergei Ananyan. 2017. The Role of Unstructured Data in Healthcare Analytics. InActionable Intelligence in Healthcare. Auerbach Publications, 241–262
2017
-
[34]
Iker De la Iglesia, Iakes Goenaga, Johanna Ramirez-Romero, Jose Maria Villa-Gonzalez, Josu Goikoetxea, and Ander Barrena. 2025. Ranking Over Scoring: Towards Reliable and Robust Automated Evaluation of LLM-Generated Medical Explanatory Arguments. InProceedings of the 31st International Conference on Computational Linguistics. 9456–9471
2025
-
[35]
Fajardo V Diego, Oleksii Proniakin, Victoria-Elisabeth Gruber, and Razvan Marinescu. 2026. MedPI: Evaluating AI Systems in Medical Patient-facing Interactions.medRxiv(2026), 2025–12
2026
- [36]
-
[37]
Jinru Ding, Lu Lu, Chao Ding, Mouxiao Bian, Jiayuan Chen, Wenrao Pang, Ruiyao Chen, Xinwei Peng, Renjie Lu, Sijie Ren, Guanxu Zhu, Xiaoqin Wu, Zhiqiang Liu, Rongzhao Zhang, Luyi Jiang, Bing Han, Yunqiu Wang, and Jie Xu. 2025. MedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Age...
-
[38]
Zachary Ellis, Jared Joselowitz, Yash Deo, Yajie Vera He, Anna Kalygina, Aisling Higham, Mana Rahimzadeh, Yan Jia, Ibrahim Habli, and Ernest Lim. 2026. Wer is unaware: Assessing how asr errors distort clinical understanding in patient facing dialogue. InProceedings of the 16th International Workshop on Spoken Dialogue System Technology. 391–417
2026
- [39]
-
[40]
Yushi Feng, Junye Du, Yingying Hong, Qifan Wang, and Lequan Yu. 2026. PASS: Probabilistic Agentic Supernet Sampling for Interpretable and Adaptive Chest X-Ray Reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 30717–30725
2026
- [41]
-
[42]
Aya E Fouda, Abdelrahman A Hassan, Radwa J Hanafy, and Mohammed E Fouda. 2026. PsychiatryBench: a multi-task benchmark for LLMs in psychiatry.npj Digital Medicine(2026)
2026
-
[43]
Yasuko Fukataki, Wakako Hayashi, Megumi Kitayama, and Yoichi M Ito. 2026. Measurement of retrieved chunk quality from real-world knowledge in retrieval-augmented generation: A Phase 1 foundational study.medRxiv(2026), 2026–01
2026
- [44]
-
[45]
Cool, Zahir Kanjee, Andrew S
Ethan Goh, Robert Gallo, Jason Hom, Eric Strong, Yingjie Weng, Hannah Kerman, Joséphine A. Cool, Zahir Kanjee, Andrew S. Parsons, Neera Ahuja, Eric Horvitz, Daniel Yang, Arnold Milstein, Andrew P. J. Olson, Adam Rodman, and Jonathan H. Chen. 2024. Large language model influence on diagnostic reasoning: a randomized clinical trial.JAMA network open7, 10 (2...
2024
-
[46]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Zhouchi Lin, Bowen Zhang, Lionel Ni, Wen Gao, Yuanzhuo Wang, and Jian Guo. 2024. A survey on llm-as-a-judge.The Innovation(2024)
2024
-
[47]
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. 2025. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Jaewook Han, Beomgi So, Whanbo Jung, Minwoo Kim, Hoon Kim, and Daun Shin. 2026. Optimizing small lo- cal language models for culturally competent mental health counseling: comparative evaluation with GPT-4o by psychiatrists.JMIR Preprints(2026). doi:10.2196/preprints.92470
-
[49]
Ryan Han, Julián N Acosta, Zahra Shakeri, John PA Ioannidis, Eric J Topol, and Pranav Rajpurkar. 2024. Randomised controlled trials evaluating artificial intelligence in clinical practice: a scoping review.The lancet digital health6, 5 (2024), e367–e373
2024
-
[50]
HM Hasan, Housam Khalifa Bashier, Jiayi Dai, Mi-Young Kim, and Randy Goebel. 2025. Reason2Decide: Rationale- Driven Multi-Task Learning.arXiv preprint arXiv:2512.20074(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Qing He, Dongsheng Bi, Jianrong Lu, Minghui Yang, Zixiao Chen, Jiacheng Lu, Jing Chen, Nannan Du, Xiao Cu, Sijing Wu, Peng Xiang, Yinyin Hu, Yi Guo, Chunpu Li, Shaoyang Li, Zhuo Dong, Ming Jiang, Shuai Guo, Liyun Feng, LLM-as-a-Judge in Healthcare: A Scoping Analysis of Applications, Methods, and Human Alignment 27 Jin Peng, Jian Wang, Jinjie Gu, and Junw...
-
[52]
Zhe He, Balu Bhasuran, Qiao Jin, Shubo Tian, Karim Hanna, Cindy Shavor, Lisbeth Garcia Arguello, Patrick Murray, and Zhiyong Lu. 2024. Quality of answers of generative large language models versus peer users for interpreting laboratory test results for lay patients: evaluation study.Journal of medical Internet research26 (2024), e56655
2024
- [53]
-
[54]
Pedram Hosseini, Jessica M Sin, Bing Ren, Bryceton G Thomas, Elnaz Nouri, Ali Farahanchi, and Saeed Hassanpour
- [55]
-
[56]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, and Weizhu Chen. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
- [57]
-
[58]
Dongsuk Jang, Ziyao Shangguan, Kyle Tegtmeyer, Anurag Gupta, Jan T Czerminski, Sophie Chheang, and Arman Cohan. 2025. MedTutor: A Retrieval-Augmented LLM System for Case-Based Medical Education. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 319–353
2025
-
[59]
Kennedy, Sebastian Lobentanzer, and Georg Fuellen
Hans Jarchow, Christoph Bobrowski, Steffi Falk, Andreas Hermann, Anton Kulaga, Johann-Christian Põder, Maxim- ilian Unfried, Nikolay Usanov, Bijan Zendeh, Brian K. Kennedy, Sebastian Lobentanzer, and Georg Fuellen. 2025. Benchmarking large language models for personalized, biomarker-based health intervention recommendations.NPJ Digital Medicine8, 1 (2025), 631
2025
-
[60]
Dulhan Jayalath, Shashwat Goel, Thomas Foster, Parag Jain, Suchin Gururangan, Cheng Zhang, Anirudh Goyal, and Alan Schelten. 2025. Compute as teacher: Turning inference compute into reference-free supervision.arXiv preprint arXiv:2509.14234(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [61]
- [62]
-
[63]
Tomiris Kaumenova, Subhankar Chakraborty, Eric Fosler-Lussier, Kebire Gofar, Isaiah Metcalf, Andrew Perrault, and Michael White. 2025. Evaluating Large Language Models for Colonoscopy Preparation Assistance: Correctness and Diversity in Synthetic Dialogues.medRxiv(2025), 2025–11
2025
- [64]
-
[65]
Edward Kim, Richard Foty, Manil Shrestha, and Vicki Seyfert-Margolis. 2025. Conformal prediction and verification of large language model extractions in EHR data. InProceedings of the AAAI Symposium Series, Vol. 7. 539–546
2025
- [66]
-
[67]
Yubin Kim, Hyewon Jeong, Shan Chen, Shuyue Stella Li, Chanwoo Park, Mingyu Lu, Kumail Alhamoud, Jimin Mun, Cristina Grau, Minseok Jung, Rodrigo Gameiro, Lizhou Fan, Eugene Park, Tristan Lin, Joonsik Yoon, Wonjin Yoon, Maarten Sap, Yulia Tsvetkov, Paul Liang, Xuhai Xu, Xin Liu, Chunjong Park, Hyeonhoon Lee, Hae Won Park, Daniel McDuff, Samir Tulebaev, and ...
-
[68]
Masamune Kobayashi, Masato Mita, and Mamoru Komachi. 2024. Large language models are state-of-the-art evaluator for grammatical error correction. InProceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024). 68–77
2024
-
[69]
Veysel Kocaman, Mustafa Aytuğ Kaya, Andrei Marian Feier, and David Talby. 2025. Clinical Large Language Model Evaluation by Expert Review (CLEVER): Framework Development and Validation.JMIR AI4, 1 (2025), e72153
2025
-
[70]
Sunjun Kweon, Jiyoun Kim, Heeyoung Kwak, Dongchul Cha, Hangyul Yoon, Kwanghyun Kim, Jeewon Yang, Se- unghyun Won, and Edward Choi. 2024. Ehrnoteqa: An llm benchmark for real-world clinical practice using discharge summaries.Advances in Neural Information Processing Systems37 (2024), 124575–124611
2024
-
[71]
Jethro CC Kwong, Lauren Erdman, Adree Khondker, Marta Skreta, Anna Goldenberg, Melissa D McCradden, Ar- mando J Lorenzo, and Mandy Rickard. 2022. The silent trial-the bridge between bench-to-bedside clinical AI applications.Frontiers in digital health4 (2022), 929508
2022
- [72]
-
[73]
Md Tahmid Rahman Laskar, Israt Jahan, Elham Dolatabadi, Chun Peng, Enamul Hoque, and Jimmy Huang. 2025. Improving automatic evaluation of large language models (LLMs) in biomedical relation extraction via LLMs-as- the-judge. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 25483–25497
2025
-
[74]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[75]
A Scoping Review of LLM-as-a-Judge in Healthcare and the MedJUDGE Framework
Chenyu Li, Zohaib Akhtar, Mingu Kwak, Yuelyu Ji, Hang Zhang, Tracey Obi, Yufan Ren, Xizhi Wu, Sonish Sivarajku- mar, Harold P. Lehmann, Shyam Visweswaran, Michael J. Becich, Danielle L. Mowery, Renxuan Liu, Haoyang Sun, and Yanshan Wang. 2026. A Scoping Review of LLM-as-a-Judge in Healthcare and the MedJUDGE Framework.arXiv preprint arXiv:2604.25933(2026)...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.25933 2026
-
[76]
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. 2025. From generation to judgment: Opportunities and challenges of llm-as-a-judge. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2757–2791
2025
-
[77]
Haitao Li, Junjie Chen, Qingyao Ai, Zhumin Chu, Yujia Zhou, Qian Dong, and Yiqun Liu. 2025. Calibraeval: Calibrating prediction distribution to mitigate selection bias in llms-as-judges. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 16537–16552
2025
-
[78]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. Llms-as-judges: a comprehensive survey on llm-based evaluation methods.arXiv preprint arXiv:2412.05579(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Hanyang Li, Xiao He, Adarsh Subbaswamy, Patrick Vossler, Alexej Gossmann, Karandeep Singh, and Jean Feng. 2026. Scaling medical device regulatory science using large language models.npj Digital Medicine(2026)
2026
-
[80]
Kunning Li, Jianbin Guo, Zhaoyang Shang, Yiqing Liu, Hongmin Du, Lingling Liu, Yuping Zhao, and Lifeng Dong
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.