Uncertainty-Aware Budget Allocation for Adaptive Test-Time Reasoning
Pith reviewed 2026-06-29 18:26 UTC · model grok-4.3
The pith
Allocating extra samples to high-uncertainty questions via marginal-greedy on single-generation negative log-likelihood raises reasoning accuracy over uniform sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
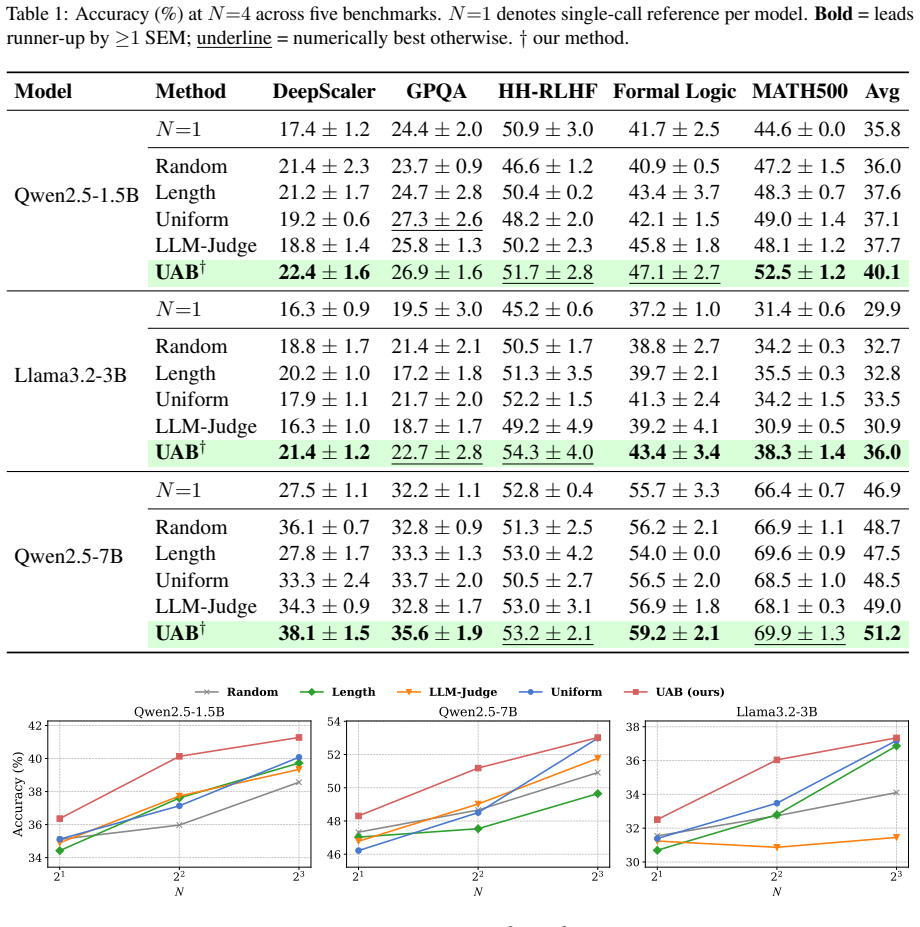
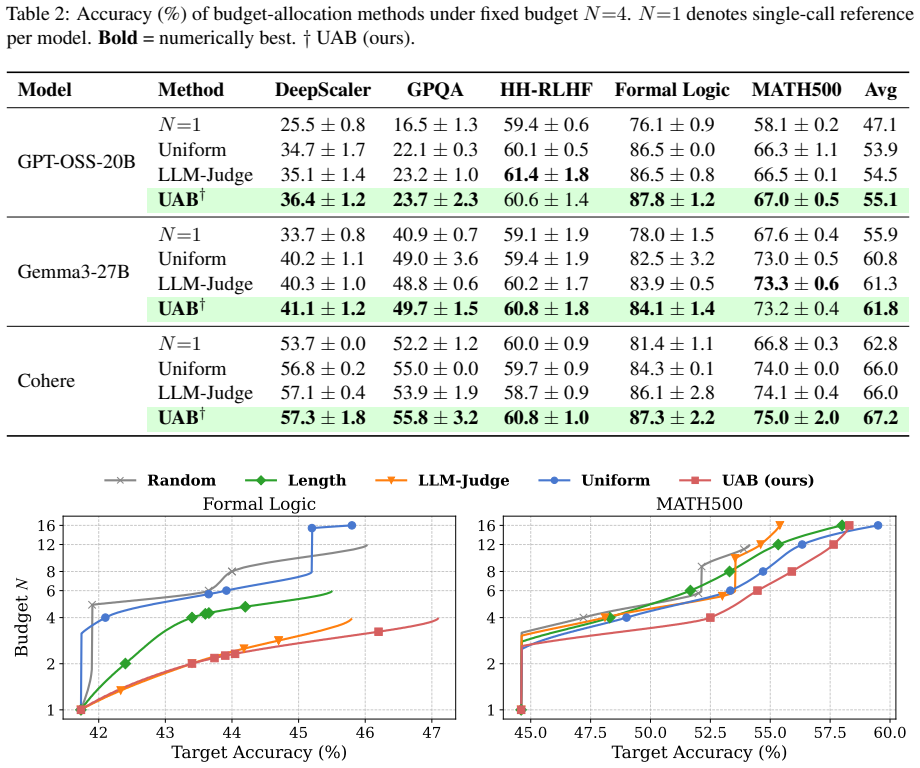
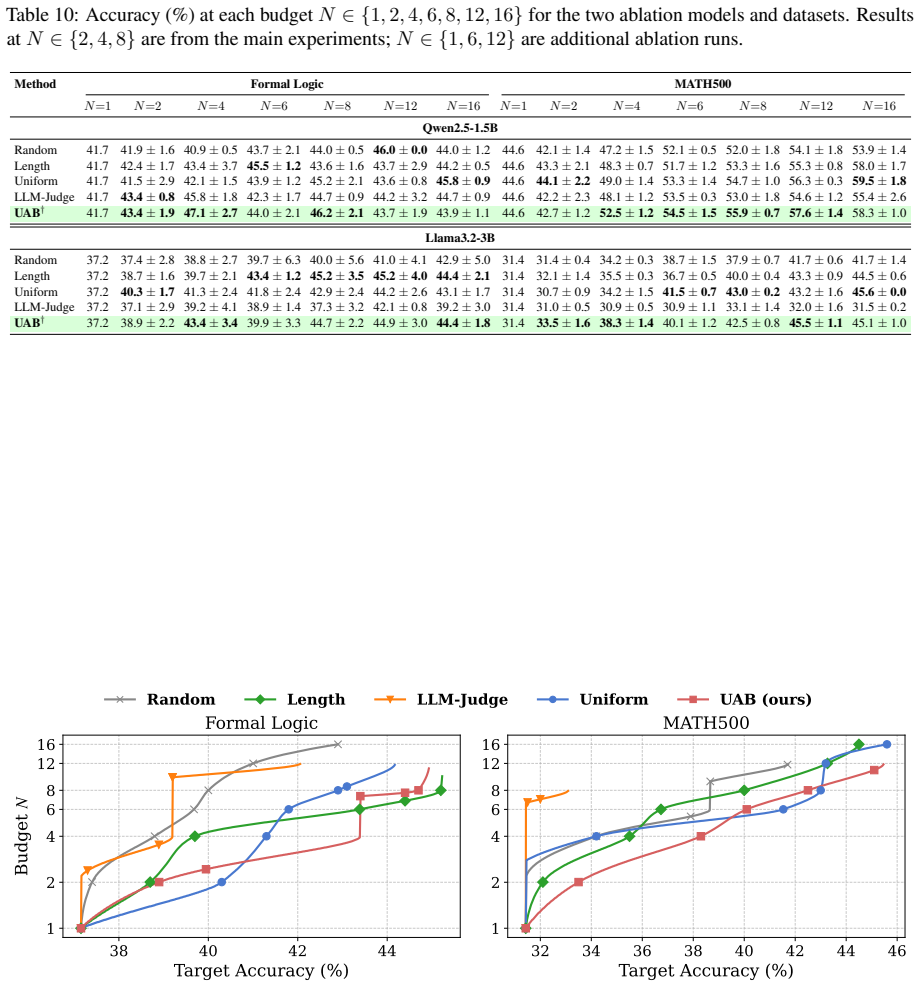
UAB is a concave integer optimization framework that reallocates a fixed sampling budget based on per-question uncertainty estimated at no additional inference cost. In Phase 1 every question receives one generation whose average negative log-likelihood serves as the difficulty signal while also counting toward the final vote. In Phase 2 the remaining budget is allocated by a marginal-greedy algorithm that solves a concave coverage-maximization surrogate exactly, giving more samples to uncertain questions and fewer to confident ones.
What carries the argument
Marginal-greedy algorithm solving the concave coverage-maximization surrogate for budget allocation driven by average negative log-likelihood signals from the first generation.
If this is right
- Accuracy improves by up to 3 percent on average and 5 percent on individual benchmarks relative to uniform allocation.
- Gains are largest in low-resource regimes where total samples per question are small.
- The approach applies to both open-weight and black-box models from 1.5 B to 27 B parameters.
- No auxiliary model or second LLM call is required because the uncertainty signal comes from the first generation itself.
Where Pith is reading between the lines
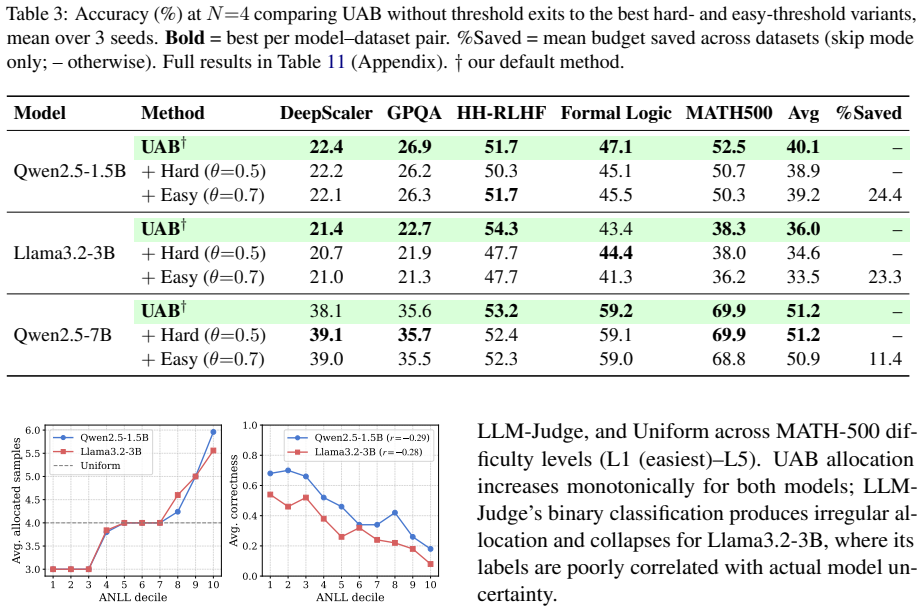
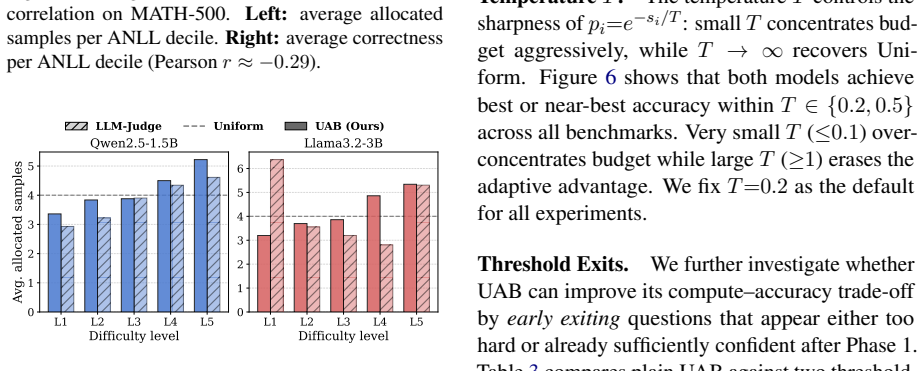
- The same ANLL signal could be used to decide when to stop sampling early for very confident questions, freeing budget for other questions.
- Combining UAB with existing chain-of-thought or self-consistency variants might compound the accuracy lift.
- If the concave surrogate is a good proxy for actual accuracy gain, similar marginal-greedy allocation could apply to other adaptive test-time techniques such as tree search or tool use.
Load-bearing premise
The average negative log-likelihood from one generation is a reliable signal of how much additional sampling that question still needs.
What would settle it
On a new reasoning benchmark, run uniform sampling versus UAB with the same total budget per question and observe whether the accuracy ordering reverses or stays flat.
Figures


read the original abstract
Sampling multiple responses improves language model reasoning, but uniform compute allocation is inefficient: easy questions are over-sampled while hard questions remain under-explored. We propose Uncertainty-Aware Budget Allocation (UAB), a concave integer optimization framework that reallocates a fixed sampling budget based on per-question uncertainty estimated at no additional inference cost. In Phase 1, every question receives one generation; its average negative log-likelihood (ANLL), extracted directly from output log-probabilities, serves as a difficulty signal while the generation contributes to the final vote. In Phase 2, the remaining budget is allocated by a marginal-greedy algorithm that solves a concave coverage-maximization surrogate exactly: uncertain questions receive more sampling budget while confident questions receive fewer additional samples. Evaluated on six open-weight and black-box models spanning 1.5B to 27B parameters and five reasoning benchmarks covering math, logic, and preference tasks, UAB outperforms baselines by up to +3% in average accuracy and up to +5% on individual benchmarks, with the largest gains in low-resource settings, requiring no auxiliary model or additional LLM call. Code is publicly available at https://github.com/manhitv/UAB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Uncertainty-Aware Budget Allocation (UAB), a two-phase procedure for adaptive test-time sampling in LLM reasoning. Phase 1 assigns one generation to each question and extracts its average negative log-likelihood (ANLL) directly from output log-probabilities as a difficulty signal; Phase 2 reallocates the remaining fixed budget via a marginal-greedy algorithm that exactly solves a concave coverage-maximization surrogate. Across six models (1.5B–27B parameters) and five reasoning benchmarks, UAB is reported to improve average accuracy by up to +3% and individual-benchmark accuracy by up to +5%, with largest gains in low-resource regimes and no auxiliary models or extra LLM calls required. Code is released publicly.
Significance. If the empirical claims hold, the work supplies a practical, zero-overhead technique for improving reasoning performance by reallocating a fixed sampling budget according to intrinsic model uncertainty. The public code release supports reproducibility and enables direct follow-up experiments.
major comments (2)
- [Abstract, Phase 1 description] Abstract, Phase 1 description: the central claim that ANLL from a single generation serves as a reliable per-question difficulty signal for the marginal-greedy allocator rests on an unverified assumption that ANLL ranks questions by expected coverage improvement from additional samples. No correlation analysis, ablation against alternative signals, or direct validation against per-question accuracy gains is described, leaving the reported accuracy improvements dependent on an unexamined experimental choice.
- [Abstract, Evaluation paragraph] Abstract, Evaluation paragraph: the stated gains (+3% average accuracy, +5% on individual benchmarks) are presented without accompanying experimental details such as standard deviations across runs, number of trials, statistical significance tests, or ablations that isolate the marginal-greedy allocator from uniform sampling or the initial sample, making it impossible to assess whether the performance delta is robust or attributable to the proposed method.
minor comments (1)
- [Abstract] The abstract refers to a 'concave integer optimization framework' and 'concave coverage-maximization surrogate' without stating the precise objective function or the exact form of the marginal-greedy update rule; a short equation or pseudocode excerpt would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the validation of the ANLL signal and the reporting of experimental results. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, Phase 1 description] Abstract, Phase 1 description: the central claim that ANLL from a single generation serves as a reliable per-question difficulty signal for the marginal-greedy allocator rests on an unverified assumption that ANLL ranks questions by expected coverage improvement from additional samples. No correlation analysis, ablation against alternative signals, or direct validation against per-question accuracy gains is described, leaving the reported accuracy improvements dependent on an unexamined experimental choice.
Authors: We agree that the manuscript does not present correlation analysis between ANLL and per-question accuracy gains, nor ablations against alternative signals such as output entropy or self-consistency variance. The choice of ANLL is motivated by its zero-cost extraction from the single generation's log-probabilities and its direct relation to model uncertainty. In revision we will add a dedicated analysis section reporting Pearson/Spearman correlations of ANLL with observed accuracy improvements from additional samples, plus ablations replacing ANLL with entropy-based and variance-based signals while keeping the marginal-greedy allocator fixed. revision: yes
-
Referee: [Abstract, Evaluation paragraph] Abstract, Evaluation paragraph: the stated gains (+3% average accuracy, +5% on individual benchmarks) are presented without accompanying experimental details such as standard deviations across runs, number of trials, statistical significance tests, or ablations that isolate the marginal-greedy allocator from uniform sampling or the initial sample, making it impossible to assess whether the performance delta is robust or attributable to the proposed method.
Authors: The referee correctly notes the absence of these details. The current manuscript reports point estimates only. In the revision we will expand the evaluation section to report mean accuracy and standard deviation over five independent runs, include paired t-test p-values against baselines, and add explicit ablations that (i) replace the marginal-greedy allocator with uniform allocation of the remaining budget and (ii) compare full UAB against using only the Phase-1 sample. These changes will allow readers to assess robustness and isolate the contribution of the allocator. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper extracts ANLL directly from the single generation's output log-probabilities in Phase 1 and applies a marginal-greedy algorithm that solves the concave coverage-maximization surrogate exactly in Phase 2. No step reduces by construction to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled from prior work; the surrogate objective is independent of the final accuracy metric, and gains are measured on external benchmarks. The derivation is therefore self-contained against the stated inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The marginal-greedy algorithm solves the concave coverage-maximization surrogate exactly
Reference graph
Works this paper leans on
-
[1]
Optimal self-consistency for efficient rea- soning with large language models.arXiv preprint arXiv:2511.12309. Bennett Fox. 1966. Discrete optimization via marginal analysis.Management science, 13(3):210–216. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
work page internal anchor Pith review arXiv 1966
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Ja- cob Steinhardt. 2021. Measuring mathematical prob- lem solving with the MATH dataset.arXiv preprint arXiv:2103.03874. Shiyu Ji, Yixuan Wang, Yijun Liu, Qingfu Zhu, and ...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. 2024. Generating with confidence: Uncertainty quantifica- tion for black-box large language models.Transac- tions on Machine Learning Research, 2024. Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. Selfcheckgpt: Zero-resource black-box hallucina- ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
For any feasible N and each question i, the telescoping identity (empty sums equal zero) gives: fi(Ni)−f i(N ∗ i ) = Ni−1X n=N ∗ i ∆i(n)− N ∗ i −1X n=Ni ∆i(n). (9) To see this: if Ni > N ∗ i , the first sum telescopes fi(N ∗ i )→f i(Ni) and the second is empty; if Ni < N ∗ i , the second sum telescopes fi(Ni)→ fi(N ∗ i ) with a sign flip and the first is ...
1966
-
[5]
Task” describes the evaluation format; “Size
quantifies disagreement among multiple stochastic samples from the model. Given a ques- tion xi, we draw K independent Phase-1 samples, parse each into a final answer, and compute the Shannon entropy of the empirical answer distri- bution: H(x i) =− P v∈Vi qv lnq v, where qv is 12 Table 5: Wall-clock time (s) per full-dataset run at bud- getN=4.Bold= fast...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.