Learning When to Translate for Multilingual Reasoning
Pith reviewed 2026-06-28 14:24 UTC · model grok-4.3
The pith
Reinforcement learning trains reasoning models to translate non-English inputs only when direct understanding is unreliable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
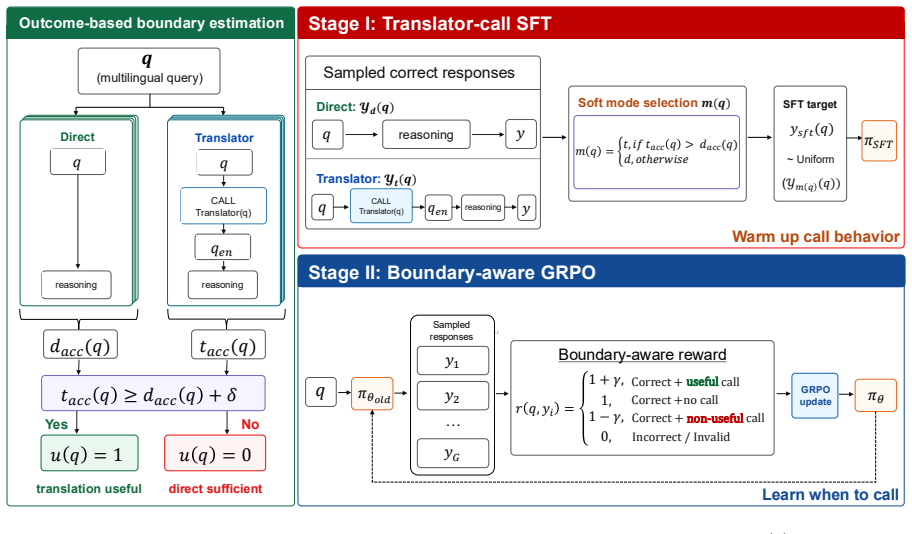
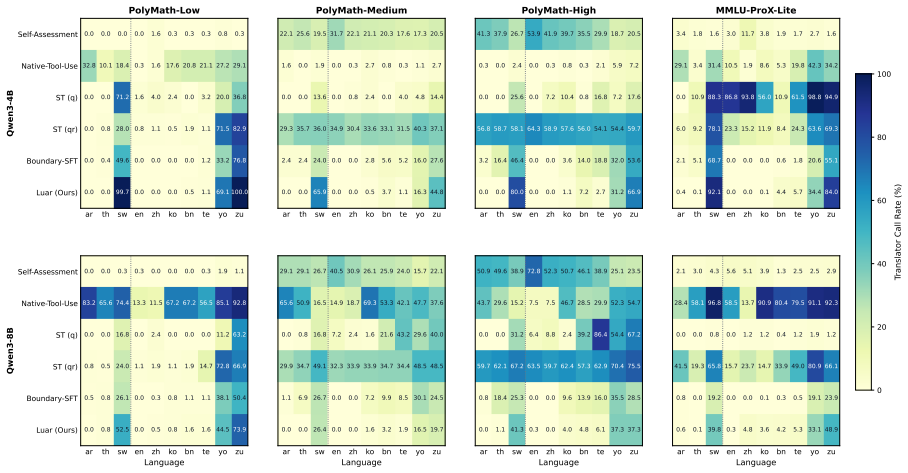
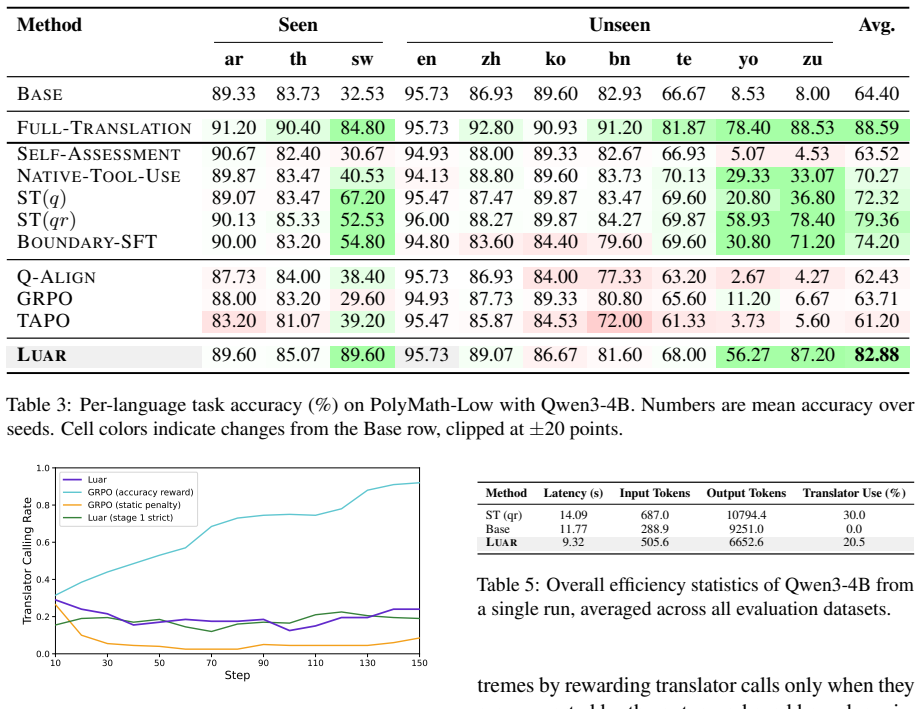
Luar trains the model to choose between solving the original input directly and reasoning over its English translation, with a reward that encourages translation only when translator-augmented reasoning is expected to substantially outperform direct reasoning. On multilingual reasoning benchmarks the method outperforms GRPO and other training-based baselines, with particularly large gains on low-resource languages. Analysis shows the model avoids unnecessary translations when direct reasoning suffices and extends its translator-call behavior to unseen low-resource languages.
What carries the argument
Luar, a Language Understanding Boundary-aware Reinforcement Learning framework that rewards the model for selecting translation only when it yields a large expected performance gain over direct reasoning.
If this is right
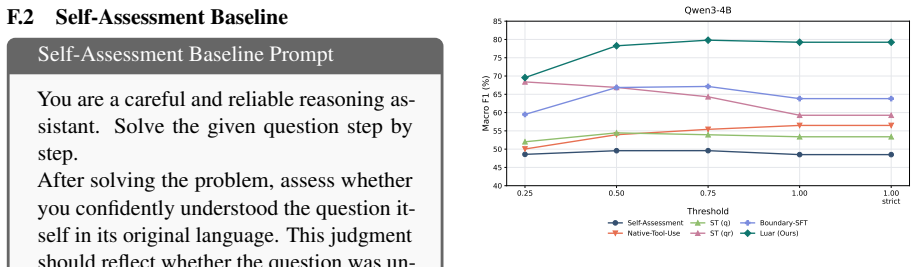
- The trained model avoids unnecessary translation calls when direct reasoning from the original input is reliable.
- Accuracy improvements are largest on low-resource languages where understanding failures are most common.
- Translator invocation behavior learned on seen languages transfers to unseen low-resource languages.
- Overall performance exceeds standard GRPO training and other baselines across multilingual reasoning benchmarks.
Where Pith is reading between the lines
- Selective translation could reduce average inference cost by skipping translation for inputs the model already understands.
- The same boundary-learning approach might be applied to deciding when to use other input transformations or external tools during reasoning.
- If the learned decision boundary proves stable across domains, it could serve as a general mechanism for models to request clarification or augmentation only when needed.
Load-bearing premise
Reinforcement learning can reliably train the model to estimate when translator-augmented reasoning will substantially outperform direct reasoning from the original input.
What would settle it
A controlled experiment showing that Luar-trained models either translate at the same rate as an always-translate baseline or produce lower accuracy than direct-reasoning baselines on low-resource languages would falsify the central claim.
Figures


read the original abstract
Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, but still exhibit substantial multilingual reasoning gaps, largely due to language-understanding failures in non-English inputs. English translation can mitigate these failures by expressing non-English inputs in a form that RLMs can more reliably interpret, yet translating every input is unnecessary when the model can reason reliably from the original query. To address this challenge, we propose Luar, a Language Understanding Boundary-aware Reinforcement Learning framework that trains RLMs to selectively invoke translation when direct understanding is unreliable. Luar trains the model to choose between solving the original input directly and reasoning over its English translation, encouraging translation only when translator-augmented reasoning is expected to substantially outperform direct reasoning. Across multilingual reasoning benchmarks, Luar outperforms standard GRPO and other training-based baselines, with particularly large gains on low-resource languages. Further analysis shows that Luar avoids unnecessary translation in cases where direct reasoning is sufficient, while extending its translator-call behavior to unseen low-resource languages. Together, our work suggests a selective approach to multilingual reasoning: RLMs can learn to invoke translation only when their direct understanding is unreliable. The project will be made publicly available at https://github.com/deokhk/LUAR
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Luar, a Language Understanding Boundary-aware Reinforcement Learning framework that trains reasoning language models to selectively invoke English translation for non-English inputs only when direct reasoning from the original input is unreliable. The approach uses a reward based on final answer correctness while discouraging unnecessary translations. It claims that Luar outperforms standard GRPO and other training-based baselines on multilingual reasoning benchmarks, with particularly large gains on low-resource languages, and that the learned behavior generalizes to unseen low-resource languages while avoiding unneeded translations.
Significance. If the empirical results hold, the work offers a practical method for improving multilingual reasoning in RLMs through learned selective translation, which could reduce unnecessary computation and close performance gaps especially for low-resource languages. The RL formulation that rewards correctness while penalizing excess translations is a coherent way to learn the decision boundary. The stated commitment to public release of the project at the provided GitHub link supports reproducibility and potential follow-up work.
minor comments (2)
- Abstract: The claim of outperformance is stated without any quantitative results, dataset names, or baseline scores, making it difficult to gauge the magnitude of gains even at a high level.
- The description of the training objective mentions a reward for correctness and a penalty for unnecessary calls, but does not specify the exact form of the combined reward or how the 'substantially outperform' threshold is operationalized.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work and for recommending minor revision. The referee accurately captures the core idea of Luar as a selective translation approach via reinforcement learning. No major comments were provided in the report, so we have no specific points requiring rebuttal or revision.
Circularity Check
No significant circularity identified
full rationale
The paper proposes Luar, an RL framework that trains a policy to decide between direct reasoning and translation-augmented reasoning, with rewards based on final answer correctness. The abstract and provided description contain no equations, fitted parameters presented as predictions, self-citations used as load-bearing uniqueness theorems, or any reduction where a claimed result is definitionally equivalent to its inputs. The method is a standard selective RL setup whose claimed generalization and efficiency gains are presented as empirical outcomes rather than constructed by the training objective itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models? , author=. 2026 , eprint=
2026
-
[2]
Question Translation Training for Better Multilingual Reasoning
Zhu, Wenhao and Huang, Shujian and Yuan, Fei and She, Shuaijie and Chen, Jiajun and Birch, Alexandra. Question Translation Training for Better Multilingual Reasoning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.498
-
[3]
2025 , eprint=
Understand, Solve and Translate: Bridging the Multilingual Mathematical Reasoning Gap , author=. 2025 , eprint=
2025
-
[4]
2024 , eprint=
xCoT: Cross-lingual Instruction Tuning for Cross-lingual Chain-of-Thought Reasoning , author=. 2024 , eprint=
2024
-
[5]
MAPO : Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization
She, Shuaijie and Zou, Wei and Huang, Shujian and Zhu, Wenhao and Liu, Xiang and Geng, Xiang and Chen, Jiajun. MAPO : Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.539
-
[6]
B ench MAX : A Comprehensive Multilingual Evaluation Suite for Large Language Models
Huang, Xu and Zhu, Wenhao and Hu, Hanxu and He, Conghui and Li, Lei and Huang, Shujian and Yuan, Fei. B ench MAX : A Comprehensive Multilingual Evaluation Suite for Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.909
-
[7]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
PolyMath: Evaluating Mathematical Reasoning in Multilingual Contexts , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[8]
2025 , journal=
Crosslingual Reasoning through Test-Time Scaling , author=. 2025 , journal=
2025
-
[9]
2026 , eprint=
Cross-lingual Collapse: How Language-Centric Foundation Models Shape Reasoning in Large Language Models , author=. 2026 , eprint=
2026
-
[10]
2025 , journal=
Language Matters: How Do Multilingual Input and Reasoning Paths Affect Large Reasoning Models? , author=. 2025 , journal=
2025
-
[11]
2026 , eprint=
What Makes Good Multilingual Reasoning? Disentangling Reasoning Traces with Measurable Features , author=. 2026 , eprint=
2026
-
[12]
When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy
Qi, Jirui and Chen, Shan and Xiong, Zidi and Fern \'a ndez, Raquel and Bitterman, Danielle and Bisazza, Arianna. When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1103
-
[13]
The Fourteenth International Conference on Learning Representations , year=
Long Chain-of-Thought Reasoning Across Languages , author=. The Fourteenth International Conference on Learning Representations , year=
-
[14]
2026 , eprint=
Self-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training , author=. 2026 , eprint=
2026
-
[15]
2024 , eprint=
Multilingual Large Language Model: A Survey of Resources, Taxonomy and Frontiers , author=. 2024 , eprint=
2024
-
[16]
MindMerger: Efficiently Boosting
Zixian Huang and Wenhao Zhu and Gong Cheng and Lei Li and Fei Yuan , booktitle=. MindMerger: Efficiently Boosting. 2024 , url=
2024
-
[17]
L ang B ridge: Multilingual Reasoning Without Multilingual Supervision
Yoon, Dongkeun and Jang, Joel and Kim, Sungdong and Kim, Seungone and Shafayat, Sheikh and Seo, Minjoon. L ang B ridge: Multilingual Reasoning Without Multilingual Supervision. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.405
-
[18]
A Survey of Multilingual Reasoning in Language Models
Ghosh, Akash and Datta, Debayan and Saha, Sriparna and Agarwal, Chirag. A Survey of Multilingual Reasoning in Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.474
-
[19]
MMLU - P ro X : A Multilingual Benchmark for Advanced Large Language Model Evaluation
Xuan, Weihao and Yang, Rui and Qi, Heli and Zeng, Qingcheng and Xiao, Yunze and Feng, Aosong and Liu, Dairui and Xing, Yun and Wang, Junjue and Gao, Fan and Lu, Jinghui and Jiang, Yuang and Li, Huitao and Li, Xin and Yu, Kunyu and Dong, Ruihai and Gu, Shangding and Li, Yuekang and Xie, Xiaofei and Juefei-Xu, Felix and Khomh, Foutse and Yoshie, Osamu and C...
-
[20]
2024 , url=
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , booktitle=. 2024 , url=
2024
-
[21]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[22]
2026 , eprint=
Med-CoReasoner: Reducing Language Disparities in Medical Reasoning via Language-Informed Co-Reasoning , author=. 2026 , eprint=
2026
-
[23]
2026 , eprint=
OpenAI o1 System Card , author=. 2026 , eprint=
2026
-
[24]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool Use , author=. 2025 , eprint=
2025
-
[26]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[27]
Kydlíček, Hynek , license =
-
[28]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[29]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[30]
2025 , howpublished =
OpenAI , title =. 2025 , howpublished =
2025
-
[31]
The Eleventh International Conference on Learning Representations , year=
Language models are multilingual chain-of-thought reasoners , author=. The Eleventh International Conference on Learning Representations , year=
-
[32]
2025 , note=
DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL , author=. 2025 , note=
2025
-
[33]
2026 , eprint=
Ministral 3 , author=. 2026 , eprint=
2026
-
[34]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[36]
Cross-lingual prompting: Improving zero-shot chain-of- thought reasoning across languages
Qin, Libo and Chen, Qiguang and Wei, Fuxuan and Huang, Shijue and Che, Wanxiang. Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.163
-
[37]
Wen, Bingbing and Yao, Jihan and Feng, Shangbin and Xu, Chenjun and Tsvetkov, Yulia and Howe, Bill and Wang, Lucy Lu , title =. Transactions of the Association for Computational Linguistics , volume =. 2025 , month =. doi:10.1162/tacl_a_00754 , url =
-
[38]
R -Tuning: Instructing Large Language Models to Say ` I Don ' t Know'
Zhang, Hanning and Diao, Shizhe and Lin, Yong and Fung, Yi and Lian, Qing and Wang, Xingyao and Chen, Yangyi and Ji, Heng and Zhang, Tong. R -Tuning: Instructing Large Language Models to Say ` I Don ' t Know'. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
-
[39]
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Liu, Chaoqun and Zhang, Wenxuan and Zhao, Yiran and Luu, Anh Tuan and Bing, Lidong. Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2...
-
[40]
2025 , eprint=
KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality , author=. 2025 , eprint=
2025
-
[41]
2025 , eprint=
TruthRL: Incentivizing Truthful LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[42]
arXiv preprint arXiv:2503.09516 , year=
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[43]
Li, Xiaoxi and Dong, Guanting and Jin, Jiajie and Zhang, Yuyao and Zhou, Yujia and Zhu, Yutao and Zhang, Peitian and Dou, Zhicheng. Search-o1: Agentic Search-Enhanced Large Reasoning Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.276
-
[44]
2025 , eprint=
Reinforced Internal-External Knowledge Synergistic Reasoning for Efficient Adaptive Search Agent , author=. 2025 , eprint=
2025
-
[45]
SMART : Self-Aware Agent for Tool Overuse Mitigation
Qian, Cheng and Acikgoz, Emre Can and Wang, Hongru and Chen, Xiusi and Sil, Avirup and Hakkani-T. SMART : Self-Aware Agent for Tool Overuse Mitigation. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.239
-
[46]
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.845
-
[47]
arXiv preprint arXiv:2508.03140 , year=
RCP-Merging: Merging Long Chain-of-Thought Models with Domain-Specific Models by Considering Reasoning Capability as Prior , author=. arXiv preprint arXiv:2508.03140 , year=
-
[48]
arXiv preprint arXiv:2502.09056 , year=
Adapting Language-Specific LLMs to a Reasoning Model in One Day via Model Merging--An Open Recipe , author=. arXiv preprint arXiv:2502.09056 , year=
-
[49]
arXiv preprint arXiv:2605.09548 , year=
Crosslingual On-Policy Self-Distillation for Multilingual Reasoning , author=. arXiv preprint arXiv:2605.09548 , year=
-
[50]
arXiv preprint arXiv:2602.05940 , year=
Self-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training , author=. arXiv preprint arXiv:2602.05940 , year=
-
[51]
arXiv preprint arXiv:2603.25419 , year=
TAPO: Translation Augmented Policy Optimization for Multilingual Mathematical Reasoning , author=. arXiv preprint arXiv:2603.25419 , year=
-
[52]
arXiv preprint arXiv:2507.05418 , year=
Learn globally, speak locally: Bridging the gaps in multilingual reasoning , author=. arXiv preprint arXiv:2507.05418 , year=
-
[53]
2025 , eprint=
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs , author=. 2025 , eprint=
2025
-
[54]
The State and Fate of Linguistic Diversity and Inclusion in the
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[55]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[56]
Popovi \'c , Maja. chr F ++: words helping character n-grams. Proceedings of the Second Conference on Machine Translation. 2017. doi:10.18653/v1/W17-4770
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.