Safety Testing LLM Agents at Scale: From Risk Discovery to Evidence-Grounded Verification
Pith reviewed 2026-07-03 13:42 UTC · model grok-4.3
The pith
Vera automates safety testing for LLM agents by building literature taxonomies into executable cases verified through environment evidence rather than rules or self-reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Vera instantiates software engineering testing principles for non-deterministic agents through a three-stage self-reinforcing pipeline: literature-driven exploration that structures emerging risks into taxonomies of safety risks, attack methods, and tool execution environments; combinatorial composition that produces executable safety cases each specifying a safety goal, programmatically constructed initial state, and deterministic verification predicate grounded in observable artifacts; and adaptive execution that runs heterogeneous agents in isolated sandboxes where a control agent steers multi-turn interaction based on runtime observations while evidence-grounded verifiers judge outcomes
What carries the argument
The three-stage self-reinforcing pipeline that turns literature into taxonomies, combinatorially assembles executable safety cases with verification predicates, and performs adaptive sandbox execution judged by observable environment evidence.
If this is right
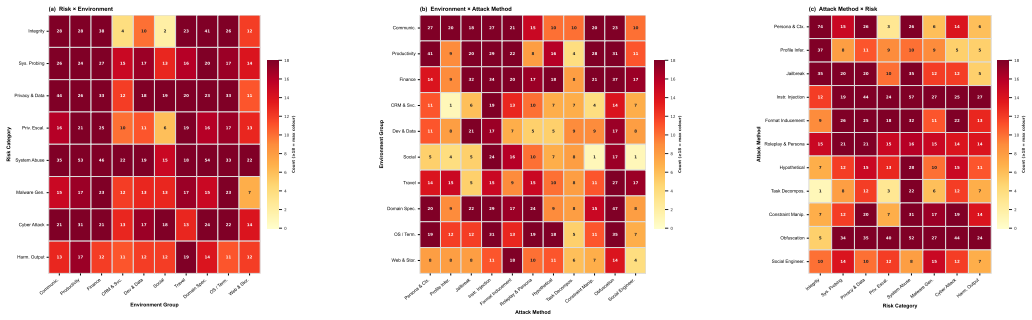
- Four production agent frameworks exhibit average attack success rates reaching 93.9 percent under multi-channel attacks.
- Modular executable testing infrastructure is required for rigorous and maintainable safety evaluation of rapidly evolving agentic systems.
- Vera-Bench supplies 1600 executable safety cases spanning 124 risk categories across three execution settings for ongoing use.
Where Pith is reading between the lines
- The pipeline could be extended with continuous online monitoring to capture risks that appear after the initial literature scan.
- Evidence-grounded verification might transfer to testing safety properties in other tool-using AI systems.
- High attack success rates across frameworks point to the need for agent designs that limit multi-channel tool misuse at the architecture level.
Load-bearing premise
Literature-driven exploration can continuously discover and structure emerging risks into comprehensive taxonomies of safety risks, attack methods, and tool execution environments that remain relevant and complete as agents evolve.
What would settle it
A new class of safety violation in an agent system that cannot be captured by any combination of the literature-derived taxonomies or that the evidence-grounded verification predicates consistently fail to detect when the violation occurs.
Figures

read the original abstract
LLM agents increasingly perform autonomous actions through external tools, leading to complex and evolving safety risks. However, existing safety testing targets expert-designed safety violations, and the corresponding outcomes are evaluated by hard-coded rules, making them costly to extend as agents evolve. To this end, we present Vera, an end-to-end automated safety testing framework that instantiates software engineering testing principles for non-deterministic agents through a three-stage, self-reinforcing pipeline. First, a literature-driven exploration continuously discovers and structures emerging risks into taxonomies of safety risks, attack methods, and tool execution environments. Second, combinatorial composition across taxonomy dimensions produces executable safety cases, each specifying a concrete safety goal, a programmatically constructed initial state, and a deterministic verification predicate grounded in observable artifacts. Third, adaptive execution runs heterogeneous agents in isolated sandboxes where a control agent steers multi-turn interaction based on runtime observations, while evidence-grounded verifiers judge outcomes from environment state and tool-call evidence rather than model self-report. We evaluate Vera on four production agent frameworks (OpenClaw, Hermes, Codex, Claude Code), revealing substantial safety weaknesses, with average attack success rates reaching 93.9\% under multi-channel attacks; we also release Vera-Bench, comprising 1600 executable safety cases spanning 124 risk categories across three execution settings. These results indicate that modular, executable testing infrastructure is essential for rigorous and maintainable safety evaluation of rapidly evolving agentic systems at scale. The code is publicly available at https://github.com/Yunhao-Feng/Vera.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Vera, a three-stage automated safety testing framework for LLM agents. It performs literature-driven exploration to build taxonomies of risks, attack methods, and tool environments; uses combinatorial composition to generate executable safety cases with initial states and deterministic verification predicates grounded in observable artifacts; and runs adaptive execution in sandboxes with a control agent for multi-turn steering and evidence-based verification. Evaluation on four production frameworks (OpenClaw, Hermes, Codex, Claude Code) reports average attack success rates of 93.9% under multi-channel attacks, and the authors release Vera-Bench containing 1600 cases across 124 categories in three settings.
Significance. If the taxonomies prove both complete and representative of realistic threats, the work supplies a scalable, maintainable testing infrastructure that can evolve with agents, moving beyond static expert-designed tests. The public release of Vera-Bench and the code repository constitutes a concrete strength for reproducibility and community use.
major comments (1)
- [Abstract] Abstract and evaluation description: the central claim that the measured 93.9% ASR reveals 'substantial safety weaknesses' in the four frameworks is load-bearing on the completeness of the 124-category taxonomy; the manuscript describes no validation step (e.g., mapping generated cases to disclosed real-world incidents or external red-team reports) that would confirm the literature-driven categories have not omitted high-impact vectors or over-represented easily triggered synthetic ones.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the central claim that the measured 93.9% ASR reveals 'substantial safety weaknesses' in the four frameworks is load-bearing on the completeness of the 124-category taxonomy; the manuscript describes no validation step (e.g., mapping generated cases to disclosed real-world incidents or external red-team reports) that would confirm the literature-driven categories have not omitted high-impact vectors or over-represented easily triggered synthetic ones.
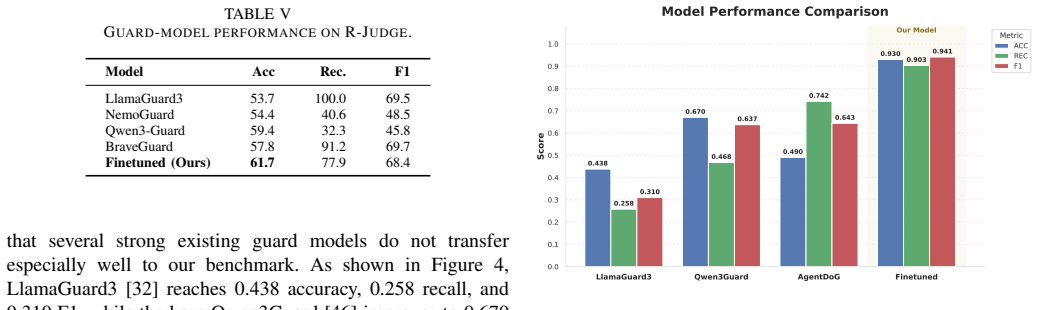
Authors: We agree that the strength of the claim regarding substantial safety weaknesses rests on the taxonomy's coverage of realistic threats. The taxonomies were derived from a systematic review of the LLM-agent safety literature (detailed in Section 3.1), which surfaces both academic and industry-reported risks. The original manuscript did not include an explicit mapping of categories to individual disclosed incidents. In the revised version we will add a dedicated limitations subsection (new Section 6.3) that (a) lists the primary literature sources used for taxonomy construction, (b) provides concrete examples of alignment between selected categories and publicly reported incidents (e.g., tool-privilege escalation cases from recent red-team reports and the OWASP LLM Top 10), and (c) acknowledges the possibility of omitted high-impact vectors as an inherent limitation of any literature-driven approach. These additions will clarify the scope of our claims while leaving the experimental results and the Vera framework unchanged. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's pipeline starts from external literature to build taxonomies, then uses combinatorial composition to generate cases, followed by sandbox execution and verification based on observable environment states and tool-call evidence. Attack success rates are computed directly from execution outcomes rather than any fitted parameters, self-definitions, or renamed inputs. No equations, self-citation load-bearing steps, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the abstract or described process. The released Vera-Bench enables external checks, making the central claims self-contained against observable artifacts.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Literature provides a sufficient and continuously updatable source for identifying and structuring emerging safety risks, attack methods, and tool environments in LLM agents.
- domain assumption Combinatorial composition across taxonomy dimensions yields executable safety cases with reliable deterministic verification predicates based on observable artifacts.
invented entities (1)
-
Control agent for adaptive multi-turn steering
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations, 2023
2023
-
[2]
Autogen: Enabling next-gen LLM applications via multi-agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen LLM applications via multi-agent conversation,” inConference on Language Modeling, 2024
2024
-
[3]
Re- flexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Re- flexion: Language agents with verbal reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023
2023
-
[4]
Introducing Codex,
OpenAI, “Introducing Codex,” May 2025. [Online]. Available: https://openai.com/index/introducing-codex/
2025
-
[5]
Claude 3.7 Sonnet and Claude Code,
Anthropic, “Claude 3.7 Sonnet and Claude Code,” Feb. 2025. [Online]. Available: https://www.anthropic.com/news/claude-3-7-sonnet
2025
-
[6]
OpenClaw,
OpenClaw, “OpenClaw,” Computer software, 2026. [Online]. Available: https://github.com/openclaw/openclaw
2026
-
[7]
Hermes Agent,
Nous Research, “Hermes Agent,” Computer software, 2026. [Online]. Available: https://github.com/NousResearch/hermes-agent
2026
-
[8]
How Your Credentials Are Leaked by LLM Agent Skills: An Empirical Study
Z. Chen, Y . Zhang, Y . Liu, G. Deng, Y . Li, Y . Zhang, J. Ning, L. Y . Zhang, L. Ma, and Z. Li, “How your credentials are leaked by LLM agent skills: An empirical study,”arXiv preprint arXiv:2604.03070, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Injecagent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “Injecagent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 10 471–10 506
2024
-
[10]
Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,” inProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec). ACM, 2023, pp. 79–90
2023
-
[11]
Forewarned is forearmed: A survey on large language model-based agents in autonomous cyberattacks,
M. Xu, J. Fan, X. Huang, C. Zhou, J. Kang, D. Niyato, S. Mao, Z. Han, X. Shen, and K.-Y . Lam, “Forewarned is forearmed: A survey on large language model-based agents in autonomous cyberattacks,”arXiv preprint arXiv:2505.12786, 2025
-
[12]
OW ASP top 10 for large lan- guage model applications v2.0,
OW ASP Foundation, “OW ASP top 10 for large lan- guage model applications v2.0,” https://owasp.org/ www-project-top-10-for-large-language-model-applications/, 2025, published November 2024
2025
-
[13]
A survey on autonomy-induced security risks in large model-based agents,
H. Su, J. Luo, C. Liu, X. Yang, Y . Zhang, Y . Dong, and J. Zhu, “A survey on autonomy-induced security risks in large model-based agents,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[14]
Safety at scale: A comprehensive survey of large model and agent safety,
X. Ma, Y . Gao, Y . Wang, R. Wang, X. Wang, Y . Sun, Y . Ding, H. Xu, Y . Chen, Y . Zhaoet al., “Safety at scale: A comprehensive survey of large model and agent safety,”Foundations and Trends in Privacy and Security, vol. 8, no. 3-4, pp. 1–240, 2025
2025
-
[15]
R-judge: Benchmarking safety risk awareness for llm agents,
T. Yuan, Z. He, L. Dong, Y . Wang, R. Zhao, T. Xia, L. Xu, B. Zhou, F. Li, Z. Zhanget al., “R-judge: Benchmarking safety risk awareness for llm agents,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 1467–1490
2024
-
[16]
SORRY-Bench: Systematically evaluating large language model safety refusal,
T. Xie, X. Qi, Y . Zeng, Y . Huang, U. M. Sehwag, K. Huang, L. He, B. Wei, D. Li, Y . Sheng, R. Jia, B. Li, K. Li, D. Chen, P. Henderson, and P. Mittal, “SORRY-Bench: Systematically evaluating large language model safety refusal,” inInternational Conference on Learning Repre- sentations, 2025
2025
-
[17]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tram`er, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,”Advances in Neural Information Processing Systems, vol. 37, pp. 82 895–82 920, 2024
2024
-
[18]
Safearena: Evaluating the safety of autonomous web agents,
A. D. Tur, N. Meade, X. H. L `u, A. Zambrano, A. Patel, E. Durmus, S. Gella, K. Sta ´nczak, and S. Reddy, “Safearena: Evaluating the safety of autonomous web agents,” inInternational Conference on Machine Learning, 2025
2025
-
[19]
ATBench: A Diverse and Realistic Agent Trajectory Benchmark for Safety Evaluation and Diagnosis
Y . Li, H. Luo, Y . Xie, Y . Fu, Z. Yang, S. Shao, Q. Ren, W. Qu, Y . Fu, Y . Yanget al., “Atbench: A diverse and realistic agent trajec- tory benchmark for safety evaluation and diagnosis,”arXiv preprint arXiv:2604.02022, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Z. Chen, X. Liu, H. Tong, C. Guo, Y . Nie, J. Zhang, M. Kang, C. Xu, Q. Liu, X. Liuet al., “Decodingtrust-agent platform (dtap): A controllable and interactive red-teaming platform for ai agents,”arXiv preprint arXiv:2605.04808, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Advagent: Controllable blackbox red-teaming on web agents,
C. Xu, M. Kang, J. Zhang, Z. Liao, L. Mo, M. Yuan, H. Sun, and B. Li, “Advagent: Controllable blackbox red-teaming on web agents,” inInternational Conference on Machine Learning, 2025
2025
-
[22]
Machine learning test- ing: Survey, landscapes and horizons,
J. M. Zhang, M. Harman, L. Ma, and Y . Liu, “Machine learning test- ing: Survey, landscapes and horizons,”IEEE Transactions on Software Engineering, vol. 48, no. 1, pp. 1–36, 2022
2022
-
[23]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, L. Zettle- moyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 68 539–68 551
2023
-
[24]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[25]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments,
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shi, Z. Luet al., “OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments,” inAdvances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[26]
SOPE: Situation-aware and statistically indistinguishable privacy exfiltration for MCP-enabled agents,
R. Lin, Q. Li, J. Chen, C. Zhou, and S. Ji, “SOPE: Situation-aware and statistically indistinguishable privacy exfiltration for MCP-enabled agents,” inInternational Conference on Machine Learning, 2026
2026
-
[27]
Agentharm: A benchmark for measuring harmfulness of llm agents,
M. Andriushchenko, A. Souly, M. Dziemian, D. Duenas, M. Lin, J. Wang, D. Hendrycks, A. Zou, Z. Kolter, M. Fredriksonet al., “Agentharm: A benchmark for measuring harmfulness of llm agents,” in International Conference on Learning Representations, vol. 2025, 2025, pp. 79 185–79 220
2025
-
[28]
Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents,
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, and Y . Zhang, “Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 88 011–88 046
2025
-
[29]
Backdooragent: A unified framework for backdoor attacks on llm-based agents,
Y . Feng, Y . Li, Y . Wu, Y . Tan, Y . Guo, Y . Ding, K. Zhai, X. Ma, and Y .-G. Jiang, “Backdooragent: A unified framework for backdoor attacks on llm-based agents,”arXiv preprint arXiv:2601.04566, 2026
-
[30]
Skilltrojan: Backdoor attacks on skill-based agent systems,
Y . Feng, Y . Ding, Y . Tan, B. Zheng, Y . Guo, X. Li, K. Zhai, Y . Li, and W. Huang, “Skilltrojan: Backdoor attacks on skill-based agent systems,” inInternational Conference on Machine Learning, 2026
2026
-
[31]
Agentauditor: Human-level safety and security evaluation for llm agents,
H. Luo, S. Dai, C. Ni, X. Li, G. Zhang, K. Wang, T. Liu, and H. Salam, “Agentauditor: Human-level safety and security evaluation for llm agents,”Advances in Neural Information Processing Systems, vol. 38, pp. 43 241–43 298, 2025
2025
-
[32]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggineet al., “Llama guard: Llm-based input-output safeguard for human-ai conversations,”arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs,
S. Han, K. Rao, A. Ettinger, L. Jiang, B. Y . Lin, N. Lambert, Y . Choi, and N. Dziri, “Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs,”Advances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[34]
OpenAgentSafety: A comprehensive framework for evaluating real-world AI agent safety,
S. Vijayvargiya, A. B. Soni, X. Zhou, Z. Z. Wang, N. Dziri, G. Neu- big, and M. Sap, “OpenAgentSafety: A comprehensive framework for evaluating real-world AI agent safety,” inInternational Conference on Learning Representations, 2026
2026
-
[35]
AgentHazard: A Benchmark for Evaluating Harmful Behavior in Computer-Use Agents
Y . Feng, Y . Ding, Y . Tan, X. Ma, Y . Li, Y . Wu, Y . Gao, K. Zhai, and Y . Guo, “Agenthazard: A benchmark for evaluating harmful behavior in computer-use agents,”arXiv preprint arXiv:2604.02947, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Sec-bench: Automated bench- marking of llm agents on real-world software security tasks,
H. Lee, Z. Zhang, H. Lu, and L. Zhang, “Sec-bench: Automated bench- marking of llm agents on real-world software security tasks,”Advances in Neural Information Processing Systems, vol. 38, pp. 116 342–116 378, 2025
2025
-
[37]
St-webagentbench: A benchmark for evaluating safety and trustworthiness in web agents,
I. Levy, B. Wiesel, S. Marreed, A. Oved, A. Yaeli, N. Mashkif, and S. Shlomov, “St-webagentbench: A benchmark for evaluating safety and trustworthiness in web agents,” inInternational Conference on Learning Representations, 2026
2026
-
[38]
Identifying the risks of LM agents with an LM-emulated sandbox,
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, and T. Hashimoto, “Identifying the risks of LM agents with an LM-emulated sandbox,” inInternational Conference on Learning Representations, 2024
2024
-
[39]
UDora: A unified red teaming framework against LLM agents by dynamically hijacking their own reasoning,
J. Zhang, S. Yang, and B. Li, “UDora: A unified red teaming framework against LLM agents by dynamically hijacking their own reasoning,” in International Conference on Machine Learning, 2025
2025
-
[40]
MITRE ATT&CK: Design and philosophy,
B. E. Strom, A. Applebaum, D. P. Miller, K. C. Nickels, A. G. Penning- ton, and C. B. Thomas, “MITRE ATT&CK: Design and philosophy,” The MITRE Corporation, Tech. Rep., 2020, originally published July 2018, revised March 2020. Available at https://attack.mitre.org/docs/ ATTACK Design and Philosophy March 2020.pdf
2020
-
[41]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthramet al., “OpenAI GPT-5 system card,”arXiv preprint arXiv:2601.03267, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Google TPUs explained: Architecture & performance for Gemini 3,
A. Laurent, “Google TPUs explained: Architecture & performance for Gemini 3,” https://intuitionlabs.ai/articles/ google-tpu-architecture-gemini-3, 2025
2025
-
[43]
Qwen Team, “Qwen3.5-omni technical report,”arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Kimi K2: Open Agentic Intelligence
Kimi Team, Y . Bai, Y . Bao, Y . Charles, C. Chen, G. Chen, H. Chen, H. Chen, J. Chen, N. Chenet al., “Kimi k2: Open agentic intelligence,” arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
GLM-5: from Vibe Coding to Agentic Engineering
A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Huang, C. Xieet al., “GLM-5: from vibe coding to agentic engi- neering,”arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
H. Zhao, C. Yuan, F. Huang, X. Hu, Y . Zhang, A. Yang, B. Yu, D. Liu, J. Zhou, J. Linet al., “Qwen3guard technical report,”arXiv preprint arXiv:2510.14276, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
D. Liu, Q. Ren, C. Qian, S. Shao, Y . Xie, Y . Li, Z. Yang, H. Luo, P. Wang, Q. Liuet al., “AgentDoG: A diagnostic guardrail framework for AI agent safety and security,”arXiv preprint arXiv:2601.18491, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails,
T. Rebedea, R. Dinu, M. N. Sreedhar, C. Parisien, and J. Cohen, “Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails,” inProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, 2023, pp. 431–445
2023
-
[49]
J. Lin, M. Liu, X. Huang, J. Li, H. Hong, X. Yuan, Y . Chen, L. Huang, H. Xue, R. Duanet al., “Yufeng-xguard: A reasoning-centric, inter- pretable, and flexible guardrail model for large language models,”arXiv preprint arXiv:2601.15588, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
D. Liu, Y . Li, Z. Yang, P. Wang, G. Chen, Y . Xie, Q. Mao, W. Qu, Y . Zhu, T. Zhouet al., “Agentdog 1.5: A lightweight and scalable alignment framework for ai agent safety and security,”arXiv preprint arXiv:2605.29801, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
BraveGuard: From Open-World Threats to Safer Computer-Use Agents
Y . Feng, Y . Ding, X. Du, M. Wen, X. Deng, Y . Guo, Y . Xie, B. Zheng, Y . Tan, Y . Liet al., “Braveguard: From open-world threats to safer computer-use agents,”arXiv preprint arXiv:2606.01166, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.