Organize then Retrieve: Hierarchical Memory Navigation for Efficient Agents
Pith reviewed 2026-06-27 10:05 UTC · model grok-4.3
The pith
HORMA organizes LLM agent experiences into a file-system hierarchy and retrieves via RL navigation to cut token use while preserving task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
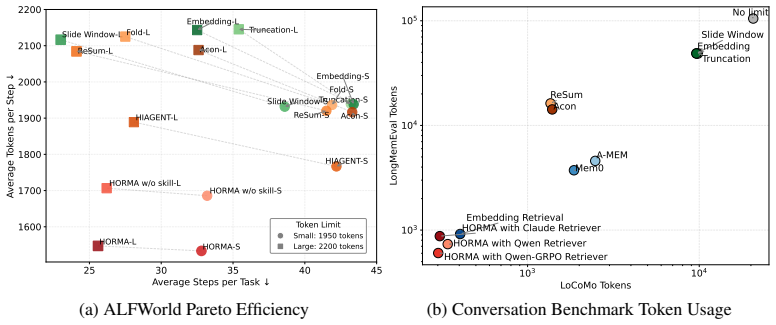
HORMA decomposes agent working memory into a construction module that iteratively builds a file-system-like hierarchy of summarized entities linked to raw trajectories and a navigation module that trains a reinforcement-learning policy to traverse the hierarchy and return the smallest context sufficient for the current step. On long-horizon benchmarks this yields higher task success under fixed context budgets and reduces token consumption to at most 22.17 percent of baseline usage in extended conversation settings while generalizing to unseen tasks.
What carries the argument
The hierarchical file-system-like memory structure whose construction module distinguishes missing-information failures from overloaded-context failures and whose navigation module uses a trained RL policy to select minimal traversals.
If this is right
- Task success rises under fixed context budgets on ALFWorld, LoCoMo, and LongMemEval.
- Token consumption drops to at most 22.17 percent of baseline in long-conversation settings.
- Efficiency-performance trade-offs improve relative to compression or similarity-retrieval baselines.
- Performance on unseen tasks remains competitive without retraining the navigation policy.
Where Pith is reading between the lines
- The same hierarchy-plus-navigation pattern could be tested on long-document QA or multi-turn tool use where context budgets are similarly constrained.
- Replacing the RL navigator with a cheaper heuristic traversal would test whether learned selection is necessary or whether static rules suffice.
- Extending the hierarchy depth on tasks longer than those in the current benchmarks would reveal whether the refinement loop scales or saturates.
Load-bearing premise
The construction module can reliably tell apart failures caused by missing information from failures caused by misleading or overloaded context.
What would settle it
A controlled run on ALFWorld in which the construction module is replaced by random or uniform hierarchy updates and task success remains unchanged or improves would falsify the value of the failure-type distinction.
Figures

read the original abstract
Large language model (LLM) agents struggle with long-horizon tasks due to their inherent statelessness, requiring all task-relevant information to be encoded in growing input contexts. The resulting degraded reasoning quality, increased inference cost, and higher latency necessitate efficient working memory mechanisms. However, existing approaches either rely on lossy compression or similarity-based retrieval, which often fail to capture temporal structure and causal dependencies required for multi-step agentic tasks. In this work, we present HORMA, a Hierarchical Organize-and-Retrieve Memory Agent that organizes experience into a file-system-like hierarchical structure, where summarized entities are linked to the corresponding raw trajectories, enabling efficient access without losing detailed information. HORMA decomposes working memory into two stages: structured memory construction and navigation-based retrieval. The construction module iteratively refines how experiences are structured by distinguishing between failures caused by missing information and those caused by misleading or overloaded context. The navigation module retrieves task-relevant context by traversing the hierarchy using a lightweight agent trained with reinforcement learning to select minimal yet sufficient context, thereby reducing latency along the critical execution path. Across ALFWorld, LoCoMo, and LongMemEval, HORMA improves task performance under constrained context budgets while requiring at most 22.17% of the baseline token usage in long conversation tasks. Compared to existing methods, it consistently achieves better efficiency-performance trade-offs and generalizes effectively to unseen tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HORMA, a Hierarchical Organize-and-Retrieve Memory Agent for LLM-based agents tackling long-horizon tasks. It decomposes working memory into a construction module that builds a file-system-like hierarchy of summarized entities linked to raw trajectories, iteratively refined by distinguishing missing-information failures from misleading/overloaded-context failures, and a navigation module that uses an RL-trained lightweight agent to traverse the hierarchy and retrieve minimal sufficient context. Experiments on ALFWorld, LoCoMo, and LongMemEval are reported to show improved task performance under constrained context budgets, with token usage at most 22.17% of baseline in long conversations, better efficiency-performance trade-offs than existing methods, and effective generalization to unseen tasks.
Significance. If the empirical results hold under rigorous validation, HORMA offers a concrete advance over lossy compression or similarity-based retrieval by preserving temporal and causal structure while enabling efficient access. The hierarchical organization plus RL navigation could reduce inference costs and latency for agentic systems, with the reported token reduction and generalization claims representing potentially high-impact outcomes if reproducible.
major comments (3)
- [Abstract] Abstract: The central claims of performance gains, 22.17% token usage, and superior efficiency-performance trade-offs are stated without any reference to experimental details such as baselines, number of trials, statistical tests, or ablation studies. This absence prevents assessment of whether the data support the claims.
- [Construction module] Construction module description: The iterative refinement process relies on accurately distinguishing failures due to missing information versus misleading/overloaded context, yet no concrete mechanism (heuristic, prompt template, or learned classifier) is specified for making this distinction, which is load-bearing for the claimed structure quality.
- [Navigation module] Navigation module: The RL training for the navigator is described as selecting minimal yet sufficient context, but the reward function, state representation, and training details are not provided, leaving the reported efficiency gains dependent on an unspecified optimization process.
minor comments (1)
- [Abstract] The abstract mentions generalization to unseen tasks but does not specify how the train/test split was constructed or what constitutes an unseen task.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional detail will improve clarity and reproducibility. We address each major comment below and will incorporate the necessary revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of performance gains, 22.17% token usage, and superior efficiency-performance trade-offs are stated without any reference to experimental details such as baselines, number of trials, statistical tests, or ablation studies. This absence prevents assessment of whether the data support the claims.
Authors: We agree that the abstract would benefit from explicit references to the experimental setup. In the revised version we will add a concise clause noting the baselines (standard full-context agents, similarity-based retrieval, and compression baselines), that results are reported as averages over multiple trials, and that ablation studies together with statistical comparisons appear in the experimental section. This will allow readers to assess the claims without expanding the abstract beyond its length limit. revision: yes
-
Referee: [Construction module] Construction module description: The iterative refinement process relies on accurately distinguishing failures due to missing information versus misleading/overloaded context, yet no concrete mechanism (heuristic, prompt template, or learned classifier) is specified for making this distinction, which is load-bearing for the claimed structure quality.
Authors: The referee is correct that the current manuscript does not specify the concrete mechanism used to distinguish the two failure modes. We will revise the construction-module section to include the exact decision procedure: a lightweight heuristic that checks for entity coverage in the generated summary against the raw trajectory, followed by an LLM prompt that classifies residual failures as missing-information versus overloaded-context. The full prompt template and pseudocode will be added to the appendix. revision: yes
-
Referee: [Navigation module] Navigation module: The RL training for the navigator is described as selecting minimal yet sufficient context, but the reward function, state representation, and training details are not provided, leaving the reported efficiency gains dependent on an unspecified optimization process.
Authors: We acknowledge that the navigation-module description omits the RL implementation details required for reproducibility. In the revision we will add a subsection that defines the state (current hierarchy node embedding plus task embedding), the reward function (task-success indicator minus normalized token cost plus a sufficiency bonus derived from downstream agent performance), and the training procedure (PPO with the specific hyperparameters and episode budget). These additions will make the source of the efficiency gains explicit. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical agent architecture (HORMA) with a construction module for hierarchical structuring and an RL-trained navigation module for retrieval. No equations, derivations, or self-citations appear in the provided abstract or description that reduce performance claims (e.g., 22.17% token usage or benchmark gains) to quantities defined by the same fitted parameters or inputs. The method is presented as an independent pipeline evaluated on external benchmarks (ALFWorld, LoCoMo, LongMemEval), with no load-bearing steps matching the enumerated circularity patterns. This is the expected non-finding for a systems/empirical paper without mathematical self-reference.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward function for navigator
axioms (1)
- domain assumption Hierarchical structure can capture temporal structure and causal dependencies required for multi-step tasks
Reference graph
Works this paper leans on
-
[1]
Why does the effective context length of LLMs fall short? InProceedings of the International Conference on Learning Representations, 2025
Chenxin An, Jun Zhang, Ming Zhong, Lei Li, Shansan Gong, Yao Luo, Jingjing Xu, and Lingpeng Kong. Why does the effective context length of LLMs fall short? InProceedings of the International Conference on Learning Representations, 2025
2025
-
[2]
The Claude 3 model family: Opus, Sonnet, Haiku
Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku. https://www.anthropic. com/news/claude-3-family, 2024. Accessed: 2026-05-12
2024
-
[3]
Mem0: Building production-ready AI agents with scalable long-term memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. InProceedings of the European Conference on Artificial Intelligence (ECAI), 2025
2025
-
[4]
Pan, Yuxin Jiang, and Kam-Fai Wong
Yiming Du, Baojun Wang, Yifan Xiang, Zhaowei Wang, Wenyu Huang, Boyang Xue, Bin Liang, Xingshan Zeng, Fei Mi, Haoli Bai, Lifeng Shang, Jeff Z. Pan, Yuxin Jiang, and Kam-Fai Wong. Memory-t1: Reinforcement learning for temporal reasoning in multi-session agents. In International Conference on Learning Representations, 2026
2026
-
[5]
Deepseek-r1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645:633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, et al. Deepseek-r1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645:633–638, 2025
2025
-
[6]
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large lan- guage model
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large lan- guage model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pages 32779–32798, July 2025
2025
-
[7]
Wei-Chieh Huang, Weizhi Zhang, Yueqing Liang, Yuanchen Bei, Yankai Chen, et al. Rethinking memory mechanisms of foundation agents in the second half: A survey.arXiv preprint arXiv:2602.06052, 2026
arXiv 2026
-
[8]
LLMLingua: Com- pressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LLMLingua: Com- pressing prompts for accelerated inference of large language models. In Houda Bouamor, Juan 10 Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13358–13376, Singapore, December 2023. Association f...
2023
-
[9]
LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pap...
2024
-
[10]
Chen, Xu Yuan, Ye Jia, Jiancheng Tu, Chen Li, Peter H
Zhuohang Jiang, Pangjing Wu, Ziran Liang, Peter Q. Chen, Xu Yuan, Ye Jia, Jiancheng Tu, Chen Li, Peter H. F. Ng, and Qing Li. Hibench: Benchmarking LLMs capability on hierarchical structure reasoning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’25). ACM, 2025
2025
-
[11]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025
2025
-
[12]
Disentangling memory and reasoning ability in large language models
Mingyu Jin, Weidi Luo, Sitao Cheng, Xinyi Wang, Wenyue Hua, Ruixiang Tang, William Yang Wang, and Yongfeng Zhang. Disentangling memory and reasoning ability in large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguis- t...
2025
-
[13]
Memory os of AI agent
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory os of AI agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
2025
-
[14]
Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A. Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. Acon: Optimizing context compression for long-horizon LLM agents.arXiv preprint arXiv:2510.00615, 2025
Pith/arXiv arXiv 2025
-
[15]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online,...
2020
-
[16]
LLMs get lost in multi- turn conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. LLMs get lost in multi- turn conversation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[17]
Andrew Kyle Lampinen, Martin Engelcke, Yuxuan Li, Arslan Chaudhry, and James L. McClel- land. Latent learning: Episodic memory complements parametric learning by enabling flexible reuse of experiences.arXiv preprint arXiv:2509.16189, 2025
arXiv 2025
-
[18]
Compressing context to enhance inference efficiency of large language models
Yucheng Li, Bo Dong, Chenghua Lin, and Frank Guerin. Compressing context to enhance inference efficiency of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[19]
Zhuofeng Li, Haoxiang Zhang, Cong Wei, Pan Lu, Ping Nie, Yi Lu, Yuyang Bai, Shangbin Feng, Hangxiao Zhu, Ming Zhong, Yuyu Zhang, Jianwen Xie, Yejin Choi, James Zou, Jiawei Han, Wenhu Chen, Jimmy Lin, Dongfu Jiang, and Yu Zhang. Beyond semantic similarity: Rethinking retrieval for agentic search via direct corpus interaction.arXiv preprint arXiv:2605.05242, 2026
Pith/arXiv arXiv 2026
-
[20]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. 11
2024
-
[21]
Miao Lu, Weiwei Sun, Weihua Du, Zhan Ling, Xuesong Yao, Kang Liu, and Jiecao Chen. Scaling LLM multi-turn RL with end-to-end summarization-based context management.arXiv preprint arXiv:2510.06727, 2025
arXiv 2025
-
[22]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[23]
Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, et al. Skill-pro: Learn- ing reusable skills from experience via non-parametric ppo for LLM agents.arXiv preprint arXiv:2602.01869, 2026
Pith/arXiv arXiv 2026
-
[24]
Patil, Kevin Lin, Sarah Wooders, and Joseph E
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. Memgpt: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[25]
Vicky Zhao, Lili Qiu, and Jianfeng Gao
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Jianfeng Gao. Secom: On memory construction and retrieval for personalized conversational agents. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[27]
On context utilization in summariza- tion with large language models
Mathieu Ravaut, Aixin Sun, Nancy Chen, and Shafiq Joty. On context utilization in summariza- tion with large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2764–2781, Bangkok, Thailand, August 2024. Associatio...
2024
-
[28]
MemInsight: Autonomous memory augmentation for LLM agents
Rana Salama, Jason Cai, Michelle Yuan, Anna Currey, Monica Sunkara, Yi Zhang, and Yassine Benajiba. MemInsight: Autonomous memory augmentation for LLM agents. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33136– 33152,...
2025
-
[29]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[31]
Alfworld: Aligning text and embodied environments for interactive learning.International Conference on Learning Representation, 2021
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.International Conference on Learning Representation, 2021
2021
-
[32]
Content-based file classification and organization system using LLMs.Electronics, 15(7):1524, 2026
Wonbin Son and Hyungjoon Kim. Content-based file classification and organization system using LLMs.Electronics, 15(7):1524, 2026
2026
-
[33]
Changzhi Sun, Xiangyu Chen, Jixiang Luo, Dell Zhang, and Xuelong Li. Beyond heuristics: A decision-theoretic framework for agent memory management.arXiv preprint arXiv:2512.21567, 2025
arXiv 2025
-
[34]
Scaling long-horizon LLM agent via context-folding.arXiv preprint arXiv:2510.11967, 2025
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon LLM agent via context-folding.arXiv preprint arXiv:2510.11967, 2025
arXiv 2025
-
[35]
Hindsight credit assignment for long-horizon LLM agents.arXiv preprint arXiv:2603.08754, 2026
Hui-Ze Tan, Xiao-Wen Yang, Hao Chen, Jie-Jing Shao, Yi Wen, Yuteng Shen, Weihong Luo, Xiku Du, Lan-Zhe Guo, and Yu-Feng Li. Hindsight credit assignment for long-horizon LLM agents.arXiv preprint arXiv:2603.08754, 2026. 12
arXiv 2026
-
[36]
Jiongxiao Wang, Qiaojing Yan, Yawei Wang, Yijun Tian, Soumya Smruti Mishra, et al. Rein- forcement learning for self-improving agent with skill library.arXiv preprint arXiv:2512.17102, 2025
Pith/arXiv arXiv 2025
-
[37]
Recursively summarizing enables long-term dialogue memory in large language models.Neurocomputing, 639, 2025
Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, and Liang Ding. Recursively summarizing enables long-term dialogue memory in large language models.Neurocomputing, 639, 2025
2025
-
[38]
Taiyi Wang, Sian Gooding, Florian Hartmann, Oriana Riva, and Edward Grefenstette. A subgoal- driven framework for improving long-horizon LLM agents.arXiv preprint arXiv:2603.19685, 2026
arXiv 2026
-
[39]
Mem-α: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911, 2025
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, et al. Mem-α: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911, 2025
Pith/arXiv arXiv 2025
-
[40]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022
2022
-
[41]
Long- memeval: Benchmarking chat assistants on long-term interactive memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory. InInternational Conference on Learning Representations, 2025
2025
-
[42]
Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Xinmiao Yu, Dingchu Zhang, Yong Jiang, Pengjun Xie, Fei Huang, Minhao Cheng, Shuai Wang, Hong Cheng, and Jingren Zhou. Resum: Unlocking long-horizon search intelligence via context summarization.arXiv preprint arXiv:2509.13313, 2025
arXiv 2025
-
[43]
Yanchen Wu, Tenghui Lin, Yingli Zhou, Fangyuan Zhang, Qintian Guo, Xun Zhou, Sibo Wang, Xilin Liu, Yuchi Ma, and Yixiang Fang. Memory in the LLM era: Modular architectures and strategies in a unified framework.arXiv preprint arXiv:2604.01707, 2026
Pith/arXiv arXiv 2026
-
[44]
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. SkillRL: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
Pith/arXiv arXiv 2026
-
[45]
Structmem: Structured memory for long-horizon behavior in LLMs.arXiv preprint arXiv:2604.21748, 2026
Buqiang Xu, Yijun Chen, Jizhan Fang, Ruobin Zhong, Yunzhi Yao, Yuqi Zhu, Lun Du, and Shumin Deng. Structmem: Structured memory for long-horizon behavior in LLMs.arXiv preprint arXiv:2604.21748, 2026
Pith/arXiv arXiv 2026
-
[46]
A-mem: Agentic memory for LLM agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for LLM agents. InAdvances in Neural Information Processing Systems, 2025
2025
-
[47]
Pan, Hinrich Schütze, V olker Tresp, and Yunpu Ma
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Schütze, V olker Tresp, and Yunpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2026
2026
-
[48]
Chengyuan Yang, Zequn Sun, Wei Wei, and Wei Hu. Beyond static summarization: Proactive memory extraction for LLM agents.arXiv preprint arXiv:2601.04463, 2026
arXiv 2026
-
[49]
React: Synergizing reasoning and acting in language models.International Conference on Learning Representation, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.International Conference on Learning Representation, 2023
2023
-
[50]
Meta context engineer- ing via agentic skill evolution.arXiv preprint arXiv:2601.21557, 2026
Haoran Ye, Xuning He, Vincent Arak, Haonan Dong, and Guojie Song. Meta context engineer- ing via agentic skill evolution.arXiv preprint arXiv:2601.21557, 2026
arXiv 2026
-
[51]
Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu Wang, Xixi Wu, Xinmiao Yu, Yong Jiang, Dingchu Zhang, Hong Cheng, and Jingren Zhou. Agentfold: Long-horizon web agents with proactive context management.arXiv preprint arXiv:2510.24699, 2025. doi: 10.48550/arXiv.2510.24699. 13
-
[52]
Compact: Compressing retrieved documents actively for question answering
Chanwoong Yoon, Taewhoo Lee, Hyeon Hwang, Minbyul Jeong, and Jaewoo Kang. Compact: Compressing retrieved documents actively for question answering. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[53]
Memagent: Reshaping long-context LLM with multi-conv RL-based memory agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context LLM with multi-conv RL-based memory agent. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[54]
Polyskill: Learning generalizable skills through polymorphic abstraction for continual learning
Simon Yu, Gang Li, Weiyan Shi, and Peng Qi. Polyskill: Learning generalizable skills through polymorphic abstraction for continual learning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[55]
Qianhao Yuan, Jie Lou, Zichao Li, Jiawei Chen, Yaojie Lu, Hongyu Lin, Le Sun, Debing Zhang, and Xianpei Han. Memsearcher: Training LLMs to reason, search and manage memory via end-to-end reinforcement learning.arXiv preprint arXiv:2511.02805, 2025
Pith/arXiv arXiv 2025
-
[56]
Optimizing generative ai by backpropagating language model feedback.Nature, 639(8055):609–616, 2025
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. Optimizing generative ai by backpropagating language model feedback.Nature, 639(8055):609–616, 2025
2025
-
[57]
On the structural memory of LLM agents.arXiv preprint arXiv:2412.15266, 2024
Ruihong Zeng, Jinyuan Fang, Siwei Liu, and Zaiqiao Meng. On the structural memory of LLM agents.arXiv preprint arXiv:2412.15266, 2024
arXiv 2024
-
[58]
Large language models are semi-parametric reinforcement learning agents
Danyang Zhang, Lu Chen, Situo Zhang, Hongshen Xu, Zihan Zhao, and Kai Yu. Large language models are semi-parametric reinforcement learning agents. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[59]
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents.arXiv preprint arXiv:2602.02474, 2026
Pith/arXiv arXiv 2026
-
[60]
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, et al. MemRL: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192, 2026
Pith/arXiv arXiv 2026
-
[61]
Yuxiang Zhang, Jiangming Shu, Ye Ma, Xueyuan Lin, Shangxi Wu, and Jitao Sang. Mem- ory as action: Autonomous context curation for long-horizon agentic tasks.arXiv preprint arXiv:2510.12635, 2025
Pith/arXiv arXiv 2025
-
[62]
Zeyu Zhang, Quanyu Dai, Rui Li, Xiaohe Bo, Xu Chen, and Zhenhua Dong. Learn to memorize: Optimizing LLM-based agents with adaptive memory framework.arXiv preprint arXiv:2508.16629, 2025
arXiv 2025
-
[63]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI Conference on Artificial Intelligence, pages 19724–19731, 2024
2024
-
[64]
Memento: Fine-tuning LLM agents without fine-tuning LLMs.arXiv preprint arXiv:2508.16153, 2025
Huichi Zhou, Yihang Chen, Siyuan Guo, Xue Yan, Kin Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, and Jun Wang. Memento: Fine-tuning LLM agents without fine-tuning LLMs.arXiv preprint arXiv:2508.16153, 2025
arXiv 2025
-
[65]
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841, 2025
Pith/arXiv arXiv 2025
-
[66]
Linearrag: Linear graph retrieval augmented generation on large-scale corpora
Luyao Zhuang, Shengyuan Chen, Yilin Xiao, Huachi Zhou, Yujing Zhang, Hao Chen, Qinggang Zhang, and Xiao Huang. Linearrag: Linear graph retrieval augmented generation on large-scale corpora. InThe Fourteenth International Conference on Learning Representations, 2026. 14 A Dataset and Experiment Setup Table 4 summarizes the benchmarks and dataset splits use...
2026
-
[67]
take (object) from (receptacle)
-
[68]
move (object) to (receptacle)
-
[69]
toggle (object) (receptacle)
-
[70]
clean (object) with (receptacle)
-
[71]
heat (object) with (receptacle)
-
[72]
cool (object) with (receptacle)
-
[73]
think: (your thought) , where (object) refers to manipulable objects and (receptacle) refers to receptacles or locations in the environment
-
[74]
If the environment output: Nothing happens, that means the previous action is invalid and you should try more options
-
[75]
Before taking a new object, make sure you have placed down any object you are currently holding
You can only hold one object at a time. Before taking a new object, make sure you have placed down any object you are currently holding
-
[76]
You should not assume or anticipate the feedback
-
[77]
Even if you have planned multiple steps ahead, you should only execute one action at a time, which aligns with subgoal
-
[78]
Do not proceed with any further exploration or actions until you receive the feedback from the environment after your action
-
[79]
better planning
Do not keep thinking. Your response should use one of the following formats: <your next action> think: <your thoughts>. Here are two examples. <example1> <example2> Here is the task <task>. 21 D.2: LoCoMo Answer Prompt Based on the following conversation, answer the question with a short, precise answer. Use the date/time information derived or concluded ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.