Does RoPE Prevent or Degrade Retrieval Heads? A Mechanistic Analysis Across Model Families
Pith reviewed 2026-06-26 14:56 UTC · model grok-4.3
The pith
RoPE does not prevent retrieval heads but zeroing their lowest-frequency dimensions degrades long-context recall in a dose-dependent way.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
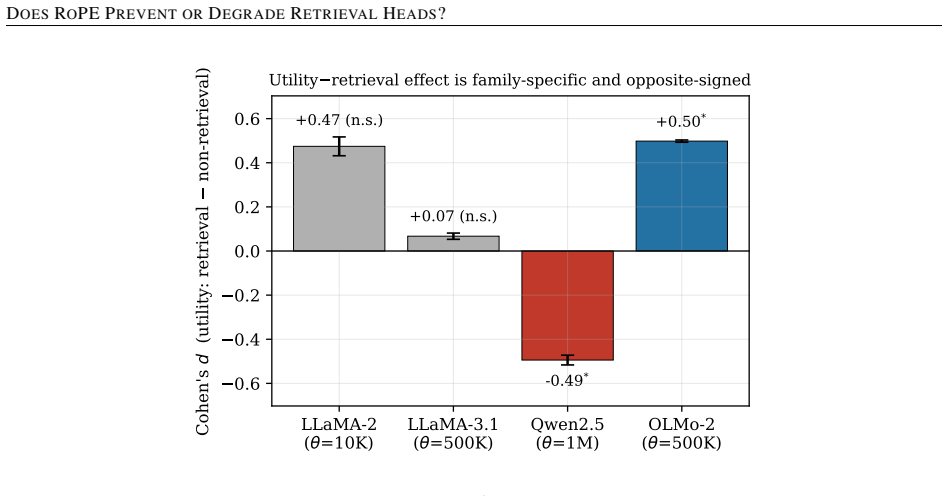
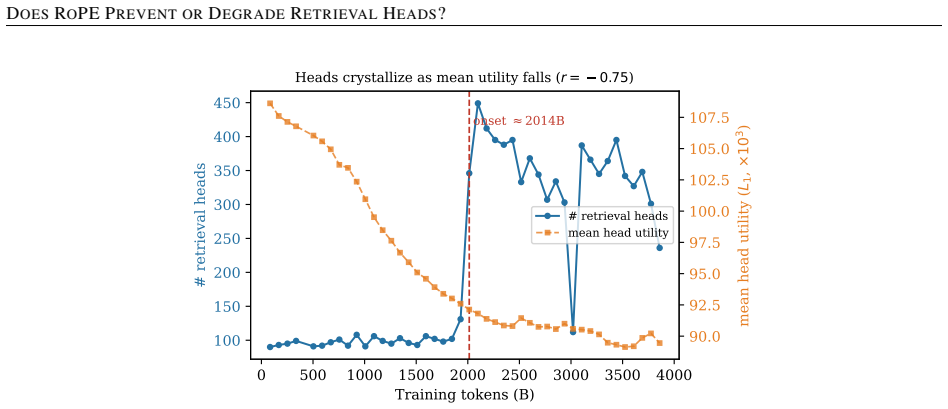
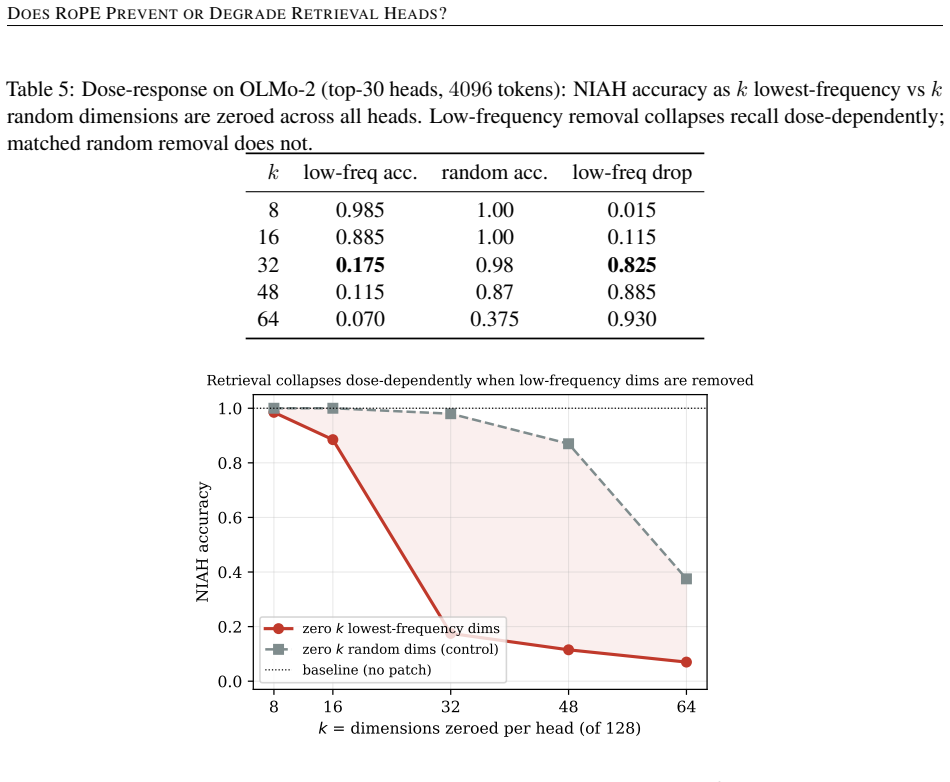
Retrieval heads are causally necessary for long-context recall: masking the 87 detected heads in OLMo-2 collapses recall from 1.00 to 0.00 while masking matched random heads has no effect. Higher RoPE theta does not reduce retrieval-head count. Zeroing the lowest-frequency RoPE dimensions of retrieval heads degrades recall dose-dependently from 1.00 to 0.18 when 32 of 128 dimensions are zeroed, an effect absent when the same number of random dimensions are zeroed; the causal variable is RoPE frequency rather than norm-utility, and the direction holds across all five models patched.
What carries the argument
Retrieval heads identified through needle-in-a-haystack tests, with their lowest-frequency RoPE dimensions serving as the controlled causal variable for recall degradation.
If this is right
- Masking all detected retrieval heads eliminates long-context recall ability while random masking does not.
- Higher RoPE theta values do not reduce the number of retrieval heads formed.
- Zeroing low-frequency RoPE dimensions inside retrieval heads produces graded, head-specific degradation in recall.
- The degradation is driven by RoPE frequency rather than head norm or utility.
- The frequency-specific effect replicates across multiple model lineages and scales.
Where Pith is reading between the lines
- Models could potentially gain long-context robustness by protecting low-frequency RoPE dimensions during training or inference.
- The head- and task-specific pattern implies retrieval heads may specialize in particular copying operations rather than general recall.
- Similar controlled zeroing experiments could be run on other position-embedding schemes to test whether frequency dependence is unique to RoPE.
Load-bearing premise
The paired-seed needle-in-a-haystack task with the chosen context lengths and insertion positions isolates the contribution of retrieval heads without substantial confounding from other attention or feed-forward mechanisms.
What would settle it
A replication experiment in which zeroing the lowest-frequency RoPE dimensions inside the detected retrieval heads produces no greater drop in recall than zeroing an equal number of random dimensions.
Figures
read the original abstract
Retrieval heads, attention heads that copy information from earlier context to the current position, have been proposed as the mechanistic substrate for long-context recall. Rotary position embeddings (RoPE) rotate queries and keys by frequencies decaying with a base hyperparameter theta, and a natural hypothesis is that this rotation either prevents retrieval heads from forming or degrades their function. We test both across four open-weight 7-8B models spanning multi-head and grouped-query attention and a 100x range of theta, using paired-seed needle-in-a-haystack tests, layer-clustered permutation, and causal head-masking. (i) Retrieval heads are causally necessary: masking the 87 detected heads in OLMo-2 collapses recall from 1.00 to 0.00, while masking matched random heads has no effect; this replicates in Qwen. (ii) Higher theta does not reduce retrieval-head count (LLaMA-3.1 at theta=500K has 47 heads vs LLaMA-2 at theta=10K with 42), refuting the prevention hypothesis. (iii) The norm-utility relation is family-specific and significant in opposite directions (Qwen d=-0.49, OLMo d=+0.50, both significant; LLaMA null); since OLMo and LLaMA-3.1 share theta=500K yet differ, the effect is not theta-driven. (iv) Building on Chiang and Yogatama (2025), a controlled patch shows that zeroing the lowest-frequency RoPE dimensions of retrieval heads degrades recall dose-dependently (1.00 to 0.18 when 32 of 128 dimensions are zeroed, vs 0.98 for random dimensions); the effect is head-specific and task-specific. The causal variable is RoPE frequency, not norm-utility. The direction holds in all five models patched (OLMo-2, Qwen2.5-7B/14B, Gemma-2, Mistral) across four lineages and two scales. We do not claim cross-model magnitude. Code and a paired-seed harness are released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RoPE neither prevents nor degrades retrieval heads in a general way: higher theta values do not reduce retrieval-head counts across model families, norm-utility correlations are family-specific rather than theta-driven, and zeroing the lowest-frequency RoPE dimensions of retrieval heads produces a dose-dependent, head-specific degradation in needle-in-a-haystack recall while the same operation on random dimensions does not. It further shows that the detected retrieval heads are causally necessary, as masking all 87 in OLMo-2 drops recall from 1.00 to 0.00 with no effect from matched random heads, with replication in Qwen and patching results holding across five models from four lineages.
Significance. If the results hold, the work supplies causal evidence against the prevention hypothesis and identifies low-frequency RoPE dimensions as a contributing factor to retrieval-head function, strengthened by controlled interventions (masking and dimension zeroing), replication across model families and scales, and the public release of code plus the paired-seed harness.
major comments (1)
- [Abstract (i) and experimental-design paragraph] Abstract (i) and experimental-design paragraph: the central necessity claim (masking the 87 retrieval heads collapses recall from 1.00 to 0.00 while random heads do not) rests on the paired-seed NIAH configuration isolating retrieval-head contributions; without explicit controls demonstrating that other attention heads or FFN pathways cannot compensate under the chosen context lengths and insertion positions, the head-specific causal conclusion is load-bearing yet under-supported.
minor comments (3)
- [Abstract] Abstract: the criteria used to detect the 87 retrieval heads (and the analogous counts in other models) are not stated; these should be specified with the exact thresholds or metrics employed.
- [Abstract (iii)] Abstract (iii): the reported values d=-0.49 and d=+0.50 for the norm-utility relation should be clarified as Pearson/Spearman correlations, effect sizes, or another statistic, and the associated p-values or confidence intervals should be given.
- [Abstract (iv)] Abstract (iv): the precise context lengths, needle insertion positions, and number of trials per condition in the NIAH tests are not reported; these details are needed to assess task specificity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below, providing our strongest honest defense of the causal claims while remaining open to clarification if needed.
read point-by-point responses
-
Referee: Abstract (i) and experimental-design paragraph: the central necessity claim (masking the 87 retrieval heads collapses recall from 1.00 to 0.00 while random heads do not) rests on the paired-seed NIAH configuration isolating retrieval-head contributions; without explicit controls demonstrating that other attention heads or FFN pathways cannot compensate under the chosen context lengths and insertion positions, the head-specific causal conclusion is load-bearing yet under-supported.
Authors: The random-head masking provides the explicit control for other attention heads. Masking matched random (non-retrieval) attention heads produces no drop in recall, demonstrating that generic attention-head capacity cannot compensate for the specific loss of retrieval heads. The complete collapse to 0.00 when only the 87 retrieval heads are masked—while every FFN layer and all remaining attention heads stay fully operational—directly shows that FFN pathways plus non-retrieval attention heads are insufficient under the tested context lengths and needle positions. The paired-seed design further ensures that differences are attributable to head identity rather than positional or seed variance. This is the standard causal-ablation logic used in mechanistic interpretability; the head-specific, dose-dependent patching results across five models supply convergent evidence. We therefore maintain that the controls are present and sufficient; no revision is required on this point. revision: no
Circularity Check
No circularity: claims rest on direct empirical interventions
full rationale
The paper's load-bearing results derive from external interventions (head masking, dimension zeroing) and measured recall in paired-seed NIAH tasks, not from any equation, fitted parameter, or self-citation that reduces to the target claim by construction. The masking result (87 heads collapse recall 1.00→0.00) and the frequency-zeroing dose-response are falsifiable observations on held-out model behavior; the Chiang and Yogatama (2025) citation is used only to motivate the patching method, not to derive the necessity or frequency effect. No self-definitional loops, fitted-input predictions, or uniqueness theorems appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Needle-in-a-haystack tests with paired seeds accurately isolate retrieval-head function for long-context recall.
Reference graph
Works this paper leans on
-
[1]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4895–4901, Singapore,
2023
-
[2]
Ting-Rui Chiang and Dani Yogatama
https://www.reddit .com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama _models_to_have/. Ting-Rui Chiang and Dani Yogatama. The rotary position embedding may cause dimension inefficiency in attention heads for long-distance retrieval. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 13552–13562, Vienna, Austria,
2025
-
[3]
RoPE Distinguishes Neither Positions Nor Tokens in Long Contexts, Provably
Association for Computational Linguistics. Yufeng Du, Phillip Harris, Minyang Tian, Eliu A. Huerta, Srikanth Ronanki, Subendhu Rongali, Aram Galstyan, and Hao Peng. RoPE distinguishes neither positions nor tokens in long contexts, provably.arXiv preprint arXiv:2605.15514,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Yoav Gelberg, Koshi Eguchi, Takuya Akiba, and Edoardo Cetin
https://transformer-circuits.pub/2021/framewo rk/index.html. Yoav Gelberg, Koshi Eguchi, Takuya Akiba, and Edoardo Cetin. Extending the context of pretrained LLMs by dropping their positional embeddings.arXiv preprint arXiv:2512.12167,
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gummadi, Manish Gupta, and Abhilasha Ravichander
Mohammad Aflah Khan, Krishna P. Gummadi, Manish Gupta, and Abhilasha Ravichander. Fractional rotation, full potential? investigating performance and convergence of partial RoPE.arXiv preprint arXiv:2603.11611,
-
[7]
From Interpretability to Performance: Optimizing Retrieval Heads for Long-Context Language Models
Youmi Ma and Naoaki Okazaki. From interpretability to performance: Optimizing retrieval heads for long-context language models.arXiv preprint arXiv:2601.11020,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole
https://transformer-circuits.pub/2022/in-context-learn ing-and-induction-heads/index.html. Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient context window extension of large language models. InThe Twelfth International Conference on Learning Representations (ICLR),
2022
-
[9]
Qwen Team, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Luke Zettlemoyer, Ali Farhadi, Noah A. Smith, and Hannaneh Hajishirzi. 2 OLMo 2 furious.arXiv preprint arXiv:2501.00656,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
21 DOESROPE PREVENT ORDEGRADERETRIEVALHEADS? Table 10: Layer-A per seed (seeds 42/123/2024): retrieval-head count, Cohen’sd for the utility difference, and the layer-clustered permutationp. Model Seed #Headsd p clustered LLaMA-2-7B 42 420.43 0.65 123 360.51 0.28 2024 330.48 0.36 LLaMA-3.1-8B 42 470.07 0.9998 123 490.08 0.9999 2024 500.05 0.9997 Qwen2.5-7B...
2024
-
[13]
Seed low_freq freq
The frequency effect is larger than OLMo’s and significant in every seed, with the same head- and task-specificity pattern (perplexity rises more than in OLMo). Seed low_freq freq. eff. ctrl ppl. ratio spec. ratio McNemarp 42 0.280−0.7200.895 1.099 0.1389×10 −44 123 0.340−0.6550.985 1.080 0.1217×10 −40 2024 0.305−0.6950.890 1.127 0.1823×10 −42 Table 13: F...
2024
-
[14]
separate detection run Qwen-7B 58; LLaMA-3.1 51 24 DOESROPE PREVENT ORDEGRADERETRIEVALHEADS? Table 17: Experimental settings by stage. Stage Settings Detection (Layer A) contexts{1024,2048,4096,8192}; positions{0.1,0.25,0.5,0.75,0.9}; 100samples; retrieval threshold0.1; seeds{42,123,2024} Knockout (Layer D) contexts{1024,2048,4096};50samples; mask all det...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.