FashionLens: Toward Versatile Fashion Image Retrieval via Task-Adaptive Learning
Pith reviewed 2026-05-22 05:58 UTC · model grok-4.3
The pith
FashionLens unifies fashion image retrieval across diverse tasks using adaptive query calibration and sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FashionLens is proposed as a unified framework based on Multimodal Large Language Models for versatile fashion image retrieval. It incorporates a Proposal-Guided Spherical Query Calibrator that dynamically shifts query representations into task-aligned metric spaces via adaptive spherical linear interpolation to handle divergent matching objectives, and a Gradient-Guided Adaptive Sampling strategy that automatically re-weights tasks based on realtime learning difficulty and the data scale prior to mitigate optimization imbalance. Experiments demonstrate state-of-the-art performance across diverse retrieval scenarios on the U-FIRE benchmark and robust generalization to unseen tasks.
What carries the argument
The Proposal-Guided Spherical Query Calibrator, which uses adaptive spherical linear interpolation to align query representations with task-specific metric spaces, and the Gradient-Guided Adaptive Sampling, which re-weights tasks according to learning difficulty and data scale.
If this is right
- Achieves state-of-the-art results on a wide range of fashion retrieval tasks in the U-FIRE benchmark.
- Generalizes effectively to retrieval tasks not seen during training.
- Supports multiple query formats and search intentions within a single model.
Where Pith is reading between the lines
- The adaptive calibration technique might help in other areas where different tasks have conflicting goals, such as general visual search.
- Creating a unified benchmark like U-FIRE could push the field toward more general-purpose retrieval systems rather than task-specific ones.
- Real-world e-commerce platforms could reduce the number of separate models needed for different search features.
Load-bearing premise
The two proposed components, the query calibrator and the adaptive sampling strategy, can successfully resolve differences in matching goals and training imbalances between tasks.
What would settle it
A direct comparison showing that FashionLens does not outperform previous methods on multiple retrieval scenarios in U-FIRE or fails to perform well on the held-out generalization datasets would disprove the central claim.
Figures



read the original abstract
Fashion image retrieval is a cornerstone of modern e-commerce systems. A unified framework that supports diverse query formats and search intentions is highly desired in practice. However, existing approaches focus on narrow retrieval tasks and do not fully capture such diversity. Therefore, in this work, we aim to develop a unified framework capable of handling diverse realistic fashion retrieval scenarios, achieving truly versatile fashion image retrieval. To establish a data foundation, we first introduce U-FIRE, a comprehensive benchmark that consolidates fragmented fashion datasets into a unified collection, supplemented by two manually curated datasets for testing generalization. Building upon this, we propose FashionLens, a unified framework based on Multimodal Large Language Models. To handle divergent matching objectives, we design a Proposal-Guided Spherical Query Calibrator that dynamically shifts query representations into task-aligned metric spaces via adaptive spherical linear interpolation. Additionally, to mitigate the optimization imbalance caused by varying task complexities and data scales, we develop a Gradient-Guided Adaptive Sampling strategy that automatically re-weights tasks based on realtime learning difficulty and the data scale prior. Experiments on U-FIRE show that FashionLens achieves state-of-the-art performance across diverse retrieval scenarios and generalizes robustly to unseen tasks. The data and code are publicly released at https://github.com/haokunwen/FashionLens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces U-FIRE, a consolidated benchmark merging fragmented fashion retrieval datasets plus two new manually curated sets for generalization testing. It proposes FashionLens, an MLLM-based unified framework that adds a Proposal-Guided Spherical Query Calibrator (adaptive spherical linear interpolation to shift queries into task-aligned spaces) and a Gradient-Guided Adaptive Sampling strategy (re-weighting tasks by realtime difficulty and data-scale prior) to handle divergent objectives and optimization imbalance. Experiments are claimed to show SOTA performance across diverse scenarios on U-FIRE together with robust generalization to unseen tasks.
Significance. If the empirical results hold, the work would be significant for moving fashion retrieval from narrow task-specific models toward a single versatile framework, which is practically relevant for e-commerce. The creation of U-FIRE as a unified benchmark is a concrete community resource. The two proposed modules constitute a plausible attempt to address multi-task optimization challenges that are common in retrieval settings.
major comments (2)
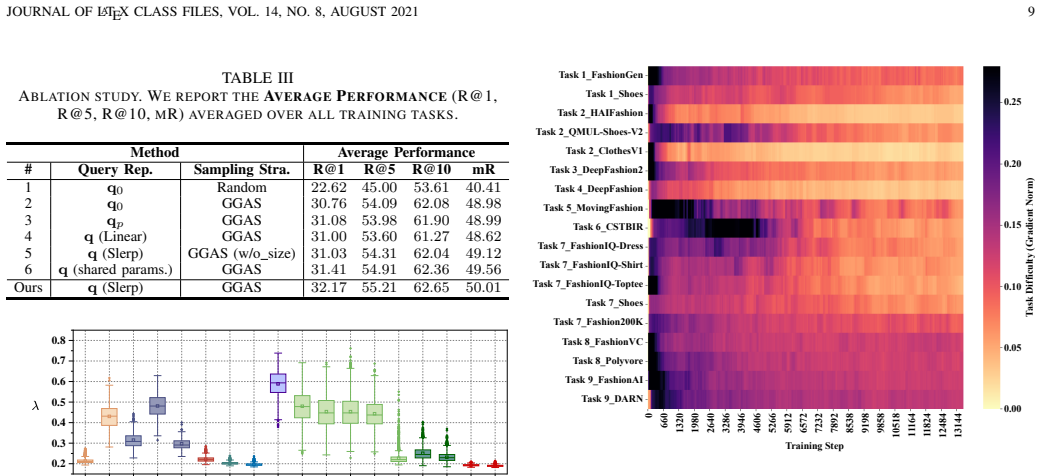
- [Experiments] Experiments section: the central SOTA and generalization claims rest on the two new modules, yet no ablation numbers, per-component metric deltas, baseline comparisons, or analysis under varying task complexities and data scales are supplied. This leaves the load-bearing assertion that the Proposal-Guided Spherical Query Calibrator and Gradient-Guided Adaptive Sampling resolve divergent matching objectives and optimization imbalance as an unverified assumption rather than a demonstrated result.
- [§3.2] §3.2 (Proposal-Guided Spherical Query Calibrator): the description of adaptive spherical linear interpolation is given, but without quantitative evidence showing improved task alignment or retrieval metrics when the module is ablated, it is impossible to confirm that the mechanism actually mitigates the stated objective mismatch.
minor comments (2)
- [§3.2] Clarify whether the spherical interpolation is performed in the original embedding space or a projected space, and provide the exact interpolation formula.
- [§4] Add a table or figure that explicitly lists the constituent datasets of U-FIRE together with their sizes and task types.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and agree that additional experimental validation is needed to strengthen the claims regarding our proposed modules.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central SOTA and generalization claims rest on the two new modules, yet no ablation numbers, per-component metric deltas, baseline comparisons, or analysis under varying task complexities and data scales are supplied. This leaves the load-bearing assertion that the Proposal-Guided Spherical Query Calibrator and Gradient-Guided Adaptive Sampling resolve divergent matching objectives and optimization imbalance as an unverified assumption rather than a demonstrated result.
Authors: We acknowledge that the current experiments section emphasizes overall SOTA performance on U-FIRE without providing detailed component-wise ablations, metric deltas, or analyses across task complexities and data scales. This is a valid point, and the manuscript would benefit from such evidence. In the revised version, we will add comprehensive ablation studies, including per-component contributions with quantitative deltas, baseline comparisons, and evaluations under varying task complexities and data scales to demonstrate how the Proposal-Guided Spherical Query Calibrator and Gradient-Guided Adaptive Sampling address divergent objectives and optimization imbalance. revision: yes
-
Referee: [§3.2] §3.2 (Proposal-Guided Spherical Query Calibrator): the description of adaptive spherical linear interpolation is given, but without quantitative evidence showing improved task alignment or retrieval metrics when the module is ablated, it is impossible to confirm that the mechanism actually mitigates the stated objective mismatch.
Authors: We agree that quantitative ablation evidence is required to substantiate the role of the Proposal-Guided Spherical Query Calibrator. The current manuscript describes the adaptive spherical linear interpolation but lacks the corresponding ablation metrics. We will incorporate ablation experiments in the revision that report improvements in task alignment and retrieval metrics when the module is included versus ablated, thereby confirming its contribution to mitigating objective mismatch. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces U-FIRE as a consolidated benchmark and proposes FashionLens as a new MLLM-based framework with two explicitly designed modules (Proposal-Guided Spherical Query Calibrator using adaptive spherical linear interpolation, and Gradient-Guided Adaptive Sampling for re-weighting). Performance claims rest on experimental results across retrieval scenarios and generalization tests rather than any mathematical derivation that reduces to fitted inputs or self-referential definitions. No equations or steps in the provided text exhibit self-definitional loops, fitted parameters called predictions, or load-bearing self-citations that force the central claims by construction. The framework builds on standard multimodal models with independent new components, making the derivation self-contained and empirically grounded.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal Large Language Models provide a suitable base for fine-tuning on retrieval tasks with divergent objectives.
Reference graph
Works this paper leans on
-
[1]
Neural compat- ibility modeling with attentive knowledge distillation,
X. Song, F. Feng, X. Han, X. Yang, W. Liu, and L. Nie, “Neural compat- ibility modeling with attentive knowledge distillation,” inProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2018, pp. 5–14
work page 2018
-
[2]
Category-aware mul- timodal attention network for fashion compatibility modeling,
P. Jing, K. Cui, W. Guan, L. Nie, and Y . Su, “Category-aware mul- timodal attention network for fashion compatibility modeling,”IEEE Transactions on Multimedia, vol. 25, pp. 9120–9131, 2023
work page 2023
-
[3]
Multi-modal and multi-domain embedding learning for fashion retrieval and analysis,
X. Gu, Y . Wong, L. Shou, P. Peng, G. Chen, and M. S. Kankanhalli, “Multi-modal and multi-domain embedding learning for fashion retrieval and analysis,”IEEE Transactions on Multimedia, vol. 21, no. 6, pp. 1524–1537, 2019
work page 2019
-
[4]
L. Xiao and T. Yamasaki, “A multihead continual learning framework for fine-grained fashion image retrieval with contrastive learning and expo- nential moving average distillation,”IEEE Transactions on Multimedia, pp. 1–10, 2026
work page 2026
-
[5]
Q. Yu, F. Liu, Y . Song, T. Xiang, T. M. Hospedales, and C. C. Loy, “Sketch me that shoe,” inIEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016, pp. 799–807
work page 2016
-
[6]
Deepfashion: Powering robust clothes recognition and retrieval with rich annotations,
Z. Liu, P. Luo, S. Qiu, X. Wang, and X. Tang, “Deepfashion: Powering robust clothes recognition and retrieval with rich annotations,” inIEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016, pp. 1096–1104
work page 2016
-
[7]
Movingfashion: a benchmark for the video-to-shop challenge,
M. Godi, C. Joppi, G. Skenderi, and M. Cristani, “Movingfashion: a benchmark for the video-to-shop challenge,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. IEEE, 2022, pp. 517–525
work page 2022
-
[8]
Fashionbert: Text and image matching with adaptive loss for cross- modal retrieval,
D. Gao, L. Jin, B. Chen, M. Qiu, P. Li, Y . Wei, Y . Hu, and H. Wang, “Fashionbert: Text and image matching with adaptive loss for cross- modal retrieval,” inProceedings of the International ACM SIGIR Con- ference on Research and Development in Information Retrieval. ACM, 2020, pp. 2251–2260
work page 2020
-
[9]
Fame-vil: Multi-tasking vision-language model for heterogeneous fashion tasks,
X. Han, X. Zhu, L. Yu, L. Zhang, Y . Song, and T. Xiang, “Fame-vil: Multi-tasking vision-language model for heterogeneous fashion tasks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2023, pp. 2669–2680
work page 2023
-
[10]
Fash- ionsap: Symbols and attributes prompt for fine-grained fashion vision- language pre-training,
Y . Han, L. Zhang, Q. Chen, Z. Chen, Z. Li, J. Yang, and Z. Cao, “Fash- ionsap: Symbols and attributes prompt for fine-grained fashion vision- language pre-training,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2023, pp. 15 028– 15 038
work page 2023
-
[11]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the International Conference on Machine Learning. PMLR, 2021, pp. 8748–8763
work page 2021
-
[12]
J. Li, D. Li, C. Xiong, and S. C. H. Hoi, “BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation,” inProceedings of the International Conference on Machine Learning. PMLR, 2022, pp. 12 888–12 900
work page 2022
-
[13]
Uniir: Training and benchmarking universal multimodal information retrievers,
C. Wei, Y . Chen, H. Chen, H. Hu, G. Zhang, J. Fu, A. Ritter, and W. Chen, “Uniir: Training and benchmarking universal multimodal information retrievers,” inProceedings of the European Conference on Computer Vision. Springer, 2024, pp. 387–404
work page 2024
-
[14]
Vlm2vec: Training vision-language models for massive multimodal embedding tasks,
Z. Jiang, R. Meng, X. Yang, S. Yavuz, Y . Zhou, and W. Chen, “Vlm2vec: Training vision-language models for massive multimodal embedding tasks,” inProceedings of the International Conference on Learning Representations. OpenReview.net, 2025
work page 2025
-
[15]
VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents
R. Meng, Z. Jiang, Y . Liu, M. Su, X. Yang, Y . Fu, C. Qin, Z. Chen, R. Xu, C. Xiong, Y . Zhou, W. Chen, and S. Yavuz, “Vlm2vec- v2: Advancing multimodal embedding for videos, images, and visual documents,”CoRR, vol. abs/2507.04590, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Loss-balanced task weighting to reduce negative transfer in multi-task learning,
S. Liu, Y . Liang, and A. Gitter, “Loss-balanced task weighting to reduce negative transfer in multi-task learning,” inProceedings of the AAAI Conference on Artificial Intelligence. AAAI Press, 2019, pp. 9977– 9978
work page 2019
-
[17]
J. Zhou, Q. Yu, C. Luo, and J. Zhang, “Feature decomposition for reducing negative transfer: A novel multi-task learning method for recommender system (student abstract),” inProceedings of the AAAI Conference on Artificial Intelligence. AAAI Press, 2023, pp. 16 390– 16 391
work page 2023
-
[18]
Dual alignment-enhanced fashion vision-language pre-training,
W. Guan, K. Wang, X. Song, K. Zhang, X. Chang, and S. Zhang, “Dual alignment-enhanced fashion vision-language pre-training,”ACM Trans- actions on Multimedia Computing, Communications and Applications, just Accepted
-
[19]
Fashion-Gen: The Generative Fashion Dataset and Challenge
N. Rostamzadeh, S. Hosseini, T. Boquet, W. Stokowiec, Y . Zhang, C. Jauvin, and C. Pal, “Fashion-gen: The generative fashion dataset and challenge,”CoRR, vol. abs/1806.08317, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Fashion IQ: A new dataset towards retrieving images by natural language feedback,
H. Wu, Y . Gao, X. Guo, Z. Al-Halah, S. Rennie, K. Grauman, and R. Feris, “Fashion IQ: A new dataset towards retrieving images by natural language feedback,” inIEEE Conference on Computer Vision and Pattern Recognition. Computer Vision Foundation / IEEE, 2021, pp. 11 307–11 317
work page 2021
-
[21]
Bridging modalities: Improving universal multi- modal retrieval by multimodal large language models,
X. Zhang, Y . Zhang, W. Xie, M. Li, Z. Dai, D. Long, P. Xie, M. Zhang, W. Li, and M. Zhang, “Bridging modalities: Improving universal multi- modal retrieval by multimodal large language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2025, pp. 9274–9285
work page 2025
-
[22]
Mm- embed: Universal multimodal retrieval with multimodal LLMS,
S. Lin, C. Lee, M. Shoeybi, J. Lin, B. Catanzaro, and W. Ping, “Mm- embed: Universal multimodal retrieval with multimodal LLMS,” inPro- ceedings of the International Conference on Learning Representations. OpenReview.net, 2025
work page 2025
-
[23]
Simple but effective raw-data level multimodal fusion for composed image retrieval,
H. Wen, X. Song, X. Chen, Y . Wei, L. Nie, and T. Chua, “Simple but effective raw-data level multimodal fusion for composed image retrieval,” inProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2024, pp. 229–239
work page 2024
-
[24]
Modeling instant user intent and content-level transition for sequential fashion recommendation,
Y . Ding, Y . Ma, W. K. Wong, and T. Chua, “Modeling instant user intent and content-level transition for sequential fashion recommendation,” IEEE Transactions on Multimedia, vol. 24, pp. 2687–2700, 2022
work page 2022
-
[25]
Learning fashion compatibility with context conditioning embedding,
Z. Lu, Y . Hu, C. Yu, Y . Chen, and B. Zeng, “Learning fashion compatibility with context conditioning embedding,”IEEE Transactions on Multimedia, vol. 25, pp. 5516–5526, 2023
work page 2023
-
[26]
Dialog-based interactive image retrieval,
X. Guo, H. Wu, Y . Cheng, S. Rennie, G. Tesauro, and R. S. Feris, “Dialog-based interactive image retrieval,” inAdvances in Neural Infor- mation Processing Systems, 2018, pp. 676–686
work page 2018
-
[27]
HAIFIT: human-centered AI for fashion image translation,
J. Jiang, X. Li, W. Yu, and D. Wu, “HAIFIT: human-centered AI for fashion image translation,”CoRR, vol. abs/2403.08651, 2024
-
[28]
Simple yet efficient: Towards self-supervised FG-SBIR with unified sample feature alignment,
J. Jiang, D. Wu, Z. Jiang, and W. Yu, “Simple yet efficient: Towards self-supervised FG-SBIR with unified sample feature alignment,”CoRR, vol. abs/2406.11551, 2024
-
[29]
Y . Ge, R. Zhang, X. Wang, X. Tang, and P. Luo, “Deepfashion2: A versatile benchmark for detection, pose estimation, segmentation and re-identification of clothing images,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Computer Vision Foundation / IEEE, 2019, pp. 5337–5345
work page 2019
-
[30]
Composite sketch+text queries for retrieving objects with elusive names and com- plex interactions,
P. Gatti, K. Parikh, D. P. Paul, M. Gupta, and A. Mishra, “Composite sketch+text queries for retrieving objects with elusive names and com- plex interactions,” inAAAI Conference on Artificial Intelligence. AAAI Press, 2024, pp. 1869–1877
work page 2024
-
[31]
Automatic spatially-aware fashion concept discovery,
X. Han, Z. Wu, P. X. Huang, X. Zhang, M. Zhu, Y . Li, Y . Zhao, and L. S. Davis, “Automatic spatially-aware fashion concept discovery,” in IEEE International Conference on Computer Vision. IEEE Computer Society, 2017, pp. 1472–1480
work page 2017
-
[32]
Neurostylist: Neural compatibility modeling for clothing matching,
X. Song, F. Feng, J. Liu, Z. Li, L. Nie, and J. Ma, “Neurostylist: Neural compatibility modeling for clothing matching,” inProceedings of the ACM on Multimedia Conference. ACM, 2017, pp. 753–761
work page 2017
-
[33]
Learning fashion compatibil- ity with bidirectional lstms,
X. Han, Z. Wu, Y . Jiang, and L. S. Davis, “Learning fashion compatibil- ity with bidirectional lstms,” inProceedings of the ACM on Multimedia Conference. ACM, 2017, pp. 1078–1086
work page 2017
-
[34]
Fashionai: A hierarchical dataset for fashion understanding,
X. Zou, X. Kong, W. Wong, C. Wang, Y . Liu, and Y . Cao, “Fashionai: A hierarchical dataset for fashion understanding,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Computer Vision Foundation / IEEE, 2019, pp. 296–304
work page 2019
-
[35]
Cross-domain image retrieval with a dual attribute-aware ranking network,
J. Huang, R. S. Feris, Q. Chen, and S. Yan, “Cross-domain image retrieval with a dual attribute-aware ranking network,” inProceedings of the IEEE International Conference on Computer Vision. IEEE Computer Society, 2015, pp. 1062–1070
work page 2015
-
[36]
Q. Team, “Qwen3-vl technical report,”CoRR, vol. abs/2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inPro- ceedings of the International Conference on Learning Representations. OpenReview.net, 2022
work page 2022
-
[38]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inProceedings of the International Conference on Learning Represen- tations. OpenReview.net, 2019
work page 2019
-
[39]
Scaling deep contrastive learning batch size under memory limited setup,
L. Gao, Y . Zhang, J. Han, and J. Callan, “Scaling deep contrastive learning batch size under memory limited setup,” inProceedings of the Workshop on Representation Learning for NLP. Association for Computational Linguistics, 2021, pp. 316–321
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.