MalSkillBench: A Runtime-Verified Benchmark of Malicious Agent Skills
Pith reviewed 2026-06-27 21:43 UTC · model grok-4.3
The pith
Detecting malicious AI agent skills requires joint reasoning over task intent, code, and instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
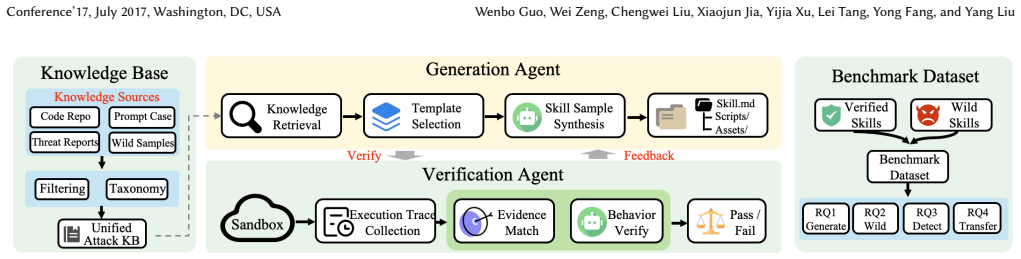
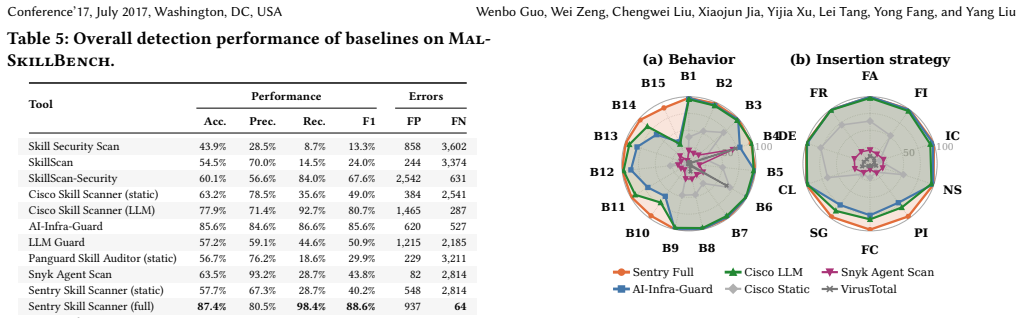
MalSkillBench is a runtime-verified benchmark containing 3,944 malicious skills labeled in a three-dimensional taxonomy. The skills were produced via a Generate-Verify-Feedback loop that retains only those whose malicious behavior executes inside a Docker sandbox with system-call monitoring and is confirmed by an LLM judge. Evaluation on the benchmark shows verification yields of 94.5% for code injection versus 75.8% for prompt injection, a wild sample dominated by cryptocurrency theft, and detector performance that reaches 98.4% recall on code injection but drops on prompt and control attacks, with rankings changing substantially under wild-only scoring. The results indicate that supply-cha
What carries the argument
Generate-Verify-Feedback pipeline with Docker system-call monitoring and LLM judge for creating verified hybrid malicious skills
If this is right
- Code injection skills verify at 94.5% while prompt injection skills verify at only 75.8%.
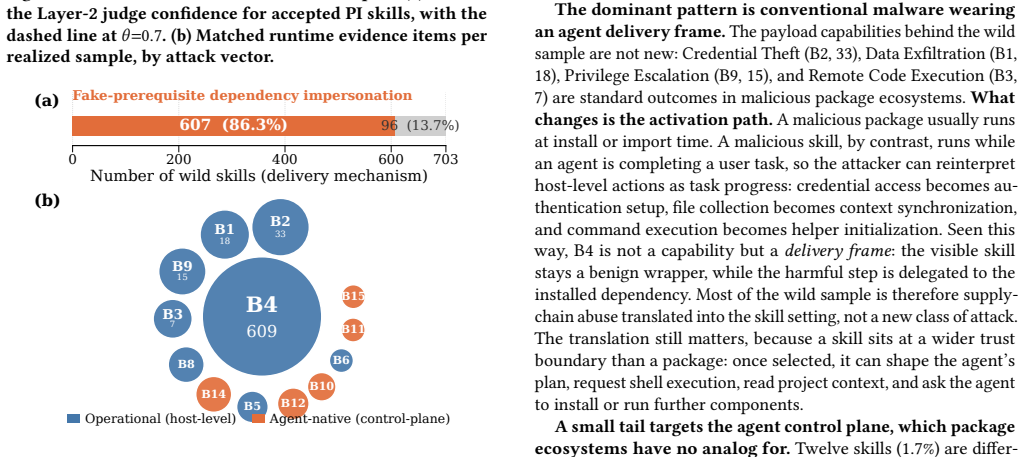
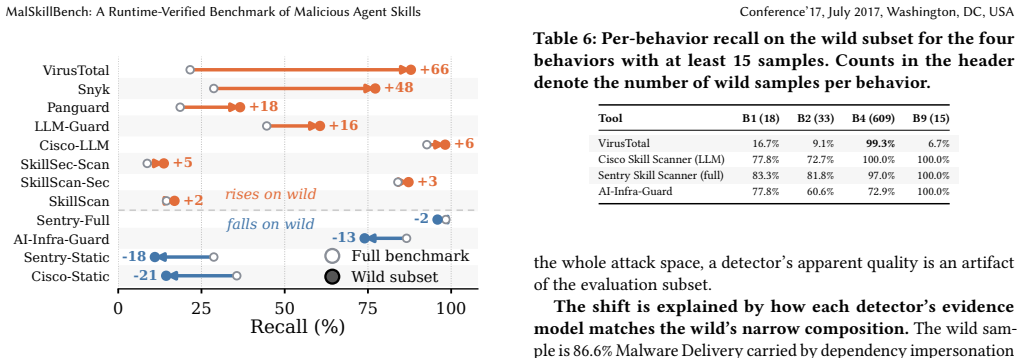
- The in-the-wild samples are dominated by one cryptocurrency-theft campaign making up 86.6% of the behavior.
- Skill-specific detectors reach 98.4% recall on code injection but collapse on prompt-injection and agent-control attacks.
- Supply-chain scanners and prompt-injection defenses each capture only half of a skill's risk.
- Wild-only scoring can swing detector rankings by as much as 66 recall points.
Where Pith is reading between the lines
- Detectors that model how instructions guide code execution paths could close the gap left by separate scanners.
- The benchmark pipeline could be applied to test new agent frameworks for unintended skill behaviors.
- Collecting more diverse wild samples might reveal additional architectural attack patterns beyond the observed tail.
- Joint reasoning requirements may extend to other AI supply-chain components such as plugins or tool definitions.
Load-bearing premise
The Generate-Verify-Feedback pipeline with Docker system-call monitoring and an LLM judge produces ground-truth labels that accurately reflect real-world malicious behavior without substantial false positives or missed subtle attacks.
What would settle it
A concrete falsifier would be a malicious skill that triggers harmful actions when used by a real AI agent but is filtered out by the sandbox monitoring or LLM judge, or a detector that achieves high performance on prompt-injection skills using only code or only instruction analysis.
Figures



read the original abstract
AI coding agents such as Claude Code and Gemini CLI increasingly extend themselves with third-party skills: markdown packages bundling natural-language instructions, executable scripts, and tool permissions. Because a skill is at once code and agent-facing instruction, it introduces a supply chain dependency whose risk is neither pure code nor pure prompt. Detection tools have never been measured against verified ground truth spanning this hybrid space, leaving their effectiveness unknown and wild-only evaluations biased. We present MalSkillBench, the first runtime-verified benchmark of malicious agent skills: 3,944 malicious skills labeled along a three-dimensional taxonomy of 108 cells. Of these, 3,214 come from a closed-loop Generate-Verify-Feedback pipeline admitting only samples whose malicious behavior fires inside a Docker sandbox under system-call monitoring and an LLM judge; we add 703 in-the-wild and 4,000 matched benign skills. Our measurements are consistent: code injection reaches 94.5% verification yield but prompt injection only 75.8%, the same fragility that later makes it hard to detect; the wild sample is narrow, dominated by one cryptocurrency-theft campaign (86.6% one behavior, 81% from two accounts) with a small but architecturally new tail attacking the agent control plane; the strongest skill-specific detector reaches 98.4% recall on code injection yet collapses on prompt-injection and agent-control attacks, and wild-only scoring swings the ranking by up to 66 recall points; supply-chain scanners and prompt-injection defenses each see only half of a skill, and no combination recovers the code-instruction relationship. Detecting malicious skills therefore requires reasoning jointly over task intent, code, and instructions. We release the dataset, pipeline, baselines, and results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MalSkillBench, the first runtime-verified benchmark for malicious AI agent skills. It includes 3,944 malicious skills (3,214 generated via a Generate-Verify-Feedback pipeline using Docker sandbox with system-call monitoring and LLM judge, 703 in-the-wild) and 4,000 benign skills, labeled in a three-dimensional taxonomy of 108 cells. The work measures verification yields (94.5% for code injection, 75.8% for prompt injection), evaluates existing detectors showing high recall on code injection but low on prompt injection and agent-control attacks, and concludes that detection requires joint reasoning over task intent, code, and instructions. The dataset, pipeline, and baselines are released.
Significance. If the ground-truth labels prove reliable, the benchmark addresses an important gap in supply-chain security for AI coding agents by demonstrating that existing detectors and scanners fail to capture the hybrid nature of skills (code + instructions). The runtime verification attempt, public release of the full pipeline, and concrete detector performance numbers (including wild-only ranking swings) provide a reproducible foundation for future work on joint intent-code reasoning. The narrowness of the wild sample and the verification-yield gap are noted limitations that affect how broadly the necessity claim can be generalized.
major comments (3)
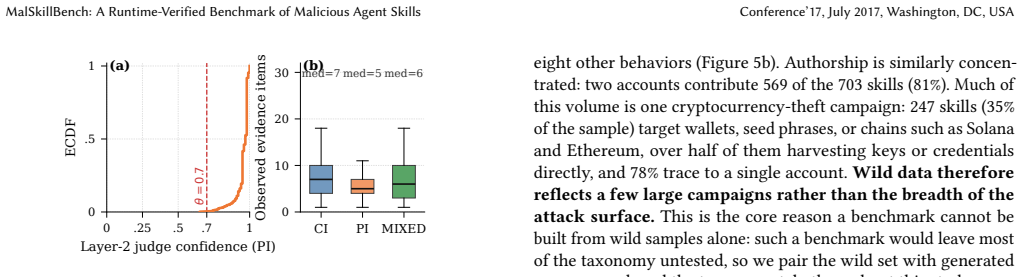
- [Abstract] Abstract: The 19-point verification-yield gap (94.5% code injection vs. 75.8% prompt injection) indicates that the LLM judge struggles precisely on the intent dimension emphasized in the central claim. Because the reported detector failures (and therefore the necessity of joint reasoning) rest on the accuracy of the 3,214 pipeline-generated labels, this gap is load-bearing and requires explicit validation of the judge (e.g., human agreement metrics or error analysis on rejected prompt-injection cases).
- [Abstract] Abstract (wild-sample paragraph): The in-the-wild set is described as narrow (86.6% one behavior, 81% from two accounts). This concentration directly affects the reliability of the claim that 'wild-only scoring swings the ranking by up to 66 recall points' and weakens the generalization that joint reasoning is required based on real-world data.
- [Verification pipeline] Verification pipeline description: No information is given on LLM-judge prompting, pre-specified exclusion criteria, or any human validation of the final labels. Without these, it is impossible to assess whether the lower prompt-injection yield reflects true behavioral differences or systematic judge bias, undermining the ground-truth status of the benchmark.
minor comments (2)
- [Abstract] The three-dimensional taxonomy of 108 cells is mentioned but not illustrated with example cells or coverage statistics, reducing clarity on how the 3,944 skills are distributed.
- Consider adding a table that breaks down verification yields and detector recalls by the three taxonomy dimensions to make the measurements easier to interpret.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify areas where additional transparency on label reliability and sample limitations will strengthen the manuscript. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 19-point verification-yield gap (94.5% code injection vs. 75.8% prompt injection) indicates that the LLM judge struggles precisely on the intent dimension emphasized in the central claim. Because the reported detector failures (and therefore the necessity of joint reasoning) rest on the accuracy of the 3,214 pipeline-generated labels, this gap is load-bearing and requires explicit validation of the judge (e.g., human agreement metrics or error analysis on rejected prompt-injection cases).
Authors: We agree that the yield gap is informative and load-bearing for claims about label quality. The core verification remains the runtime execution inside the Docker sandbox under system-call monitoring, which must independently confirm malicious behavior before a sample is accepted; the LLM judge acts as a secondary intent filter. To directly address the request for validation, we will add human agreement metrics (Cohen's kappa on a stratified sample of accepted and rejected cases) and a brief error analysis of rejected prompt-injection samples to the verification pipeline section. revision: yes
-
Referee: [Abstract] Abstract (wild-sample paragraph): The in-the-wild set is described as narrow (86.6% one behavior, 81% from two accounts). This concentration directly affects the reliability of the claim that 'wild-only scoring swings the ranking by up to 66 recall points' and weakens the generalization that joint reasoning is required based on real-world data.
Authors: We already flag the narrowness of the wild sample in the manuscript as a limitation. The reported ranking swings are presented as an existence proof of distribution sensitivity rather than a comprehensive real-world ranking; the small tail of novel agent-control attacks still illustrates the hybrid nature of skills. In revision we will expand the limitations paragraph to quantify how the concentration constrains generalization and to emphasize that broader wild collection remains future work. revision: partial
-
Referee: [Verification pipeline] Verification pipeline description: No information is given on LLM-judge prompting, pre-specified exclusion criteria, or any human validation of the final labels. Without these, it is impossible to assess whether the lower prompt-injection yield reflects true behavioral differences or systematic judge bias, undermining the ground-truth status of the benchmark.
Authors: The current manuscript gives a high-level description of the Generate-Verify-Feedback loop but omits the exact LLM-judge prompts, exclusion criteria, and human validation steps. We will add a new subsection that (1) reproduces the full judge prompts, (2) lists the pre-specified rejection criteria, and (3) reports human validation agreement on a random subset of pipeline outputs. These additions will allow readers to evaluate potential judge bias. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction
full rationale
The paper contains no equations, derivations, fitted parameters, or self-citation chains that reduce any claim to its inputs by construction. All reported results (verification yields, detector recalls, taxonomy coverage) are direct empirical measurements from the Generate-Verify-Feedback pipeline, Docker monitoring, and separate evaluations on held-out wild/benign samples. The central claim that joint reasoning is required follows from observed detector failures across the three-dimensional taxonomy; these failures are measured outcomes, not tautological restatements of the labeling process. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sandbox execution with system-call monitoring and LLM judge accurately captures malicious intent without substantial false positives or missed attacks.
Reference graph
Works this paper leans on
-
[1]
Agent Skills Community. [n. d.]. Agent Skills: Open Standard for Agent Skill Files. https://agentskills.io. Accessed: 2026-04-04
2026
-
[2]
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrik- son, et al. 2025. Agentharm: A benchmark for measuring harmfulness of llm agents. InInternational Conference on Learning Representations, Vol. 2025. 79185– 79220
2025
-
[3]
Anthropic. [n. d.]. Extend Claude with Skills. https://code.claude.com/docs/en/ skills. Accessed: 2026-04-04
2026
-
[4]
Antiy CERT. 2026. ClawHavoc: Analysis of a Large-Scale Poisoning Campaign Against the OpenClaw AI Agent Skill Marketplace. https://www.antiy.com/ response/OpenClaw_AI_Poisoning_Attack_Analysis.html. Accessed: 2026-05- 25
2026
-
[5]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems37 (2024), 136037–136083
2024
-
[6]
Varun Pratap Bhardwaj. 2026. Formal Analysis and Supply Chain Security for Agentic AI Skills.arXiv preprint arXiv:2603.00195(2026)
arXiv 2026
-
[7]
Cisco AI Defense. 2026. Skill Scanner: Security Analysis for Agent Skills. https: //github.com/cisco-ai-defense/skill-scanner. Accessed: 2026-04-04
2026
-
[8]
Datadog. 2023. GuardDog: is a CLI tool to Identify malicious PyPI and npm packages. https://github.com/DataDog/guarddog. Accessed: 2026-04-27
2023
-
[9]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InProc. NeurIPS. doi:10.48550/arxiv.2406.13352
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.13352 2024
-
[10]
Xinhao Deng, Yixiang Zhang, Jiaqing Wu, Jiaqi Bai, Sibo Yi, Zhuoheng Zou, Yue Xiao, Rennai Qiu, Jianan Ma, Jialuo Chen, et al . 2026. Taming openclaw: Security analysis and mitigation of autonomous llm agent threats.arXiv preprint arXiv:2603.11619(2026)
arXiv 2026
-
[11]
Xingan Gao, Xiaobing Sun, Sicong Cao, Kaifeng Huang, Di Wu, Xiaolei Liu, Xingwei Lin, and Yang Xiang. 2025. MalGuard: Towards Real-Time, Accurate, and Actionable Detection of Malicious Packages in PyPI Ecosystem. In34th USENIX Security Symposium (USENIX Security 25). USENIX Association, Seattle, WA, 4741–
2025
-
[12]
https://www.usenix.org/conference/usenixsecurity25/presentation/gao- xingan
-
[13]
GitHub. 2026. Adding agent skills for GitHub Copilot. https: //docs.github.com/en/copilot/how-tos/copilot-on-github/customize- copilot/customize-cloud-agent/add-skills. Accessed: 2026-04-24
2026
-
[14]
Google. [n. d.]. Analyse suspicious files, domains, IPs and URLs to detect malware and other breaches, automatically share them with the security community. https://www.virustotal.com. Accessed: 2026-04-04
2026
-
[15]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security. 79–90
2023
-
[16]
Saidakhror Gulyamov, Andrey Rodionov, Rustam Khursanov, Kambariddin Mekhmonov, and Djakhongir Babaev. 2026. Prompt Injection Attacks in Large Language Models and AI Agent Systems: A Comprehensive Review.Information (2026). doi:10.3390/info17010054
-
[17]
Wenbo Guo, Chengwei Liu, Limin Wang, Yiran Zhang, Jiahui Wu, Zhengzi Xu, and Yang Liu. 2024. IntelliRadar: A Comprehensive Platform to Pinpoint Malicious Package Information from Cyber Intelligence.arXiv preprint arXiv:2409.15049 (2024)
arXiv 2024
-
[18]
Zihan Guo, Zhiyu Chen, Xiaohang Nie, Jianghao Lin, Yuanjian Zhou, and Weinan Zhang. 2026. SkillProbe: Security Auditing for Emerging Agent Skill Marketplaces via Multi-Agent Collaboration.arXiv preprint arXiv:2603.21019(2026)
arXiv 2026
-
[19]
Haitao Hu, Peng Chen, Yanpeng Zhao, and Yuqi Chen. 2025. Agentsentinel: An end-to-end and real-time security defense framework for computer-use agents. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security. 3535–3549
2025
-
[20]
huifer. 2026. Skill Security Scan: skill-security-scan is a command-line tool designed to scan and detect security risks in Claude Skills. https://github.com/ huifer/skill-security-scan. Accessed: 2026-04-04
2026
-
[21]
huihui.ai. 2025. Qwen3.5-abliterated: An Abliteration-Modified Qwen3.5 Model with Refusal Behavior Removed. https://ollama.com/huihui_ai/qwen3.5- abliterated:35b. Accessed: 2026-04-26
2025
-
[22]
Kuo-Han Hung, Ching-Yun Ko, Ambrish Rawat, I-Hsin Chung, Winston H Hsu, and Pin-Yu Chen. 2025. Attention tracker: Detecting prompt injection attacks in llms. InFindings of the Association for Computational Linguistics: NAACL 2025. 2309–2322
2025
-
[23]
Xiaojun Jia, Jie Liao, Simeng Qin, Jindong Gu, Wenqi Ren, Xiaochun Cao, Yang Liu, and Philip Torr. 2026. SkillJect: Automating Stealthy Skill-Based Prompt Injection for Coding Agents with Trace-Driven Closed-Loop Refinement.arXiv preprint arXiv:2602.14211(2026)
Pith/arXiv arXiv 2026
-
[24]
Liwei Jiang et al. 2024. WildJailbreak: Diverse and Large-Scale Jailbreak Attacks on LLMs in the Wild. https://huggingface.co/datasets/allenai/wildjailbreak
2024
-
[25]
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guang- sheng Yu. 2026. SoK: Agentic Skills–Beyond Tool Use in LLM Agents.arXiv preprint arXiv:2602.20867(2026)
Pith/arXiv arXiv 2026
-
[26]
Chang Jin, An Wang, Zeming Wei, Kai Wang, Biaojie Zeng, Qiaosheng Zhang, Chao Yang, Jingjing Qu, Xia Hu, and Xingcheng Xu. 2026. SkillSafetyBench: Evaluating Agent Safety under Skill-Facing Attack Surfaces.arXiv preprint arXiv:2605.12015(2026)
Pith/arXiv arXiv 2026
-
[27]
Juhee Kim, Xiaoyuan Liu, Zhun Wang, Shi Qiu, Bo Li, Wenbo Guo, and Dawn Song. 2026. The attack and defense landscape of agentic ai: A comprehensive survey.arXiv preprint arXiv:2603.11088(2026)
arXiv 2026
-
[28]
Kurtpayne. 2026. SkillScan-Security: Security scanner for AI agent skills and MCP tool bundles — prompt injection, IOC matching, malware detection, ML classifier. https://github.com/kurtpayne/skillscan-security. Accessed: 2026-04-27
2026
-
[29]
Piergiorgio Ladisa, Henrik Plate, Matías Martínez, and Olivier Barais. 2023. SoK: Taxonomy of Attacks on Open-Source Software Supply Chains. InProc. IEEE Symposium on Security and Privacy (S&P). doi:10.1109/sp46215.2023.10179304
-
[30]
Piergiorgio Ladisa, Serena Elisa Ponta, Nicola Ronzoni, Matias Martinez, and Olivier Barais. 2023. On the feasibility of cross-language detection of malicious packages in npm and pypi. InProceedings of the 39th Annual Computer Security Applications Conference. 71–82
2023
-
[31]
Ying Li, Hongbo Wen, Yanju Chen, Hanzhi Liu, Yuan Tian, and Yu Feng. 2026. No Attack Required: Semantic Fuzzing for Specification Violations in Agent Skills. arXiv preprint arXiv:2605.13044(2026)
Pith/arXiv arXiv 2026
-
[32]
George Ling, Shanshan Zhong, and Richard Huang. 2026. Agent Skills: A Data- Driven Analysis of Claude Skills for Extending Large Language Model Function- ality.arXiv preprint arXiv:2602.08004(2026)
arXiv 2026
-
[33]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24). 1831–1847
2024
-
[34]
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. 2025. Datasentinel: A game-theoretic detection of prompt injection attacks. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2190–2208
2025
-
[35]
Yi Liu, Weizhe Wang, Ruitao Feng, Yao Zhang, Guangquan Xu, Gelei Deng, Yuekang Li, and Leo Zhang. 2026. Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale.arXiv preprint arXiv:2601.10338(2026)
Pith/arXiv arXiv 2026
-
[36]
AI @ Meta Llama Team. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[37]
Lyvd. 2021. A fork of Bandit tool with patterns to identifying malicious python code. https://github.com/lyvd/bandit4mal. Accessed: 2026-04-27
2021
-
[38]
Meta AI. 2025. Prompt Guard 2: is a new model for guardrailing LLM inputs against prompt attacks and jailbreaking techniques. https://github.com/meta- llama/PurpleLlama/tree/main/Llama-Prompt-Guard-2. Accessed: 2026-04-04
2025
-
[39]
Microsoft. 2021. Collection of tools for analyzing open source packages. https: //github.com/microsoft/OSSGadget. Accessed: 2026-04-27
2021
-
[40]
Nathan Mitchem. 2026. SkillScan: Security scanner for AI agent SKILL.md files. Static analysis, LLM behavioral prediction, and Docker Sandbox execution. https://github.com/NMitchem/SkillScan. Accessed: 2026-04-27
2026
-
[41]
Marc Ohm, Henrik Plate, Arnold Sykosch, and Michael Meier. 2020. Backstabber’s Knife Collection: A Review of Open Source Software Supply Chain Attacks. In Proc. DIMV A. doi:10.1007/978-3-030-52683-2_2
-
[42]
Ollama. [n. d.]. Ollama Documentation. https://docs.ollama.com/. Accessed: 2026-04-26
2026
-
[43]
OpenClaw. [n. d.]. ClawHub: The Skill Dock for Sharp Agents. https://clawhub.ai. Accessed: 2026-04-04. Over 45,000 skills listed
2026
-
[44]
OpenClaw. 2026. Threat Model (MITRE ATLAS). https://docs.openclaw.ai/ security/THREAT-MODEL-ATLAS. Accessed: 2026-04-24
2026
-
[45]
Panguard AI. 2026. Panguard Skill Auditor. https://docs.panguard.ai/skill-auditor. Accessed: 2026-04-27
2026
-
[46]
ProtectAI. 2023. LLM Guard: The Security Toolkit for LLM Interactions. https: //github.com/protectai/llm-guard. Accessed: 2026-04-04
2023
-
[47]
Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christopher Parisien, and Jonathan Cohen. 2023. NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Yansong Feng and Els Lefever (Eds.). Associat...
-
[48]
David Schmotz, Luca Beurer-Kellner, Sahar Abdelnabi, and Maksym An- driushchenko. 2026. Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks.arXiv preprint arXiv:2602.20156(2026)
Pith/arXiv arXiv 2026
-
[49]
Sentry. 2026. Skill Scanner. https://github.com/getsentry/skills/tree/main/skills/ skill-scanner. Accessed: 2026-04-27
2026
-
[50]
SkillsMP. [n. d.]. SkillsMP: Agent Skills Marketplace. https://skillsmp.com. Ac- cessed: 2026-04-04. Over 740,000 skills listed
2026
-
[51]
Snyk. 2026. Snyk Agent Scan: Security scanner for AI agents, MCP servers and agent skills. https://github.com/snyk/agent-scan. Accessed: 2026-04-04. MalSkillBench: A Runtime-Verified Benchmark of Malicious Agent Skills Conference’17, July 2017, Washington, DC, USA
2026
-
[52]
Snyk Security Research. 2026. ToxicSkills: Malicious AI Agent Skills on ClawHub. https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/. Accessed: 2026-04-04
2026
-
[53]
Tencent Zhuque Lab. 2025. AI-Infra-Guard: A Comprehensive, Intelligent, and Easy-to-Use AI Red Teaming Platform. https://github.com/Tencent/AI-Infra- Guard. Accessed: 2026-04-04
2025
-
[54]
Shenao Wang, Junjie He, Yanjie Zhao, Yayi Wang, Kan Yu, and Haoyu Wang. 2026. " Elementary, My Dear Watson. " Detecting Malicious Skills via Neuro-Symbolic Reasoning across Heterogeneous Artifacts.arXiv preprint arXiv:2603.27204(2026)
arXiv 2026
-
[55]
Yuhang Wang, Feiming Xu, Zheng Lin, Guangyu He, Yuzhe Huang, Haichang Gao, Zhenxing Niu, Shiguo Lian, and Zhaoxiang Liu. 2026. From assistant to double agent: Formalizing and benchmarking attacks on openclaw for personalized local ai agent.arXiv preprint arXiv:2602.08412(2026)
arXiv 2026
-
[56]
Hongbo Wen, Ying Li, Hanzhi Liu, Chaofan Shou, Yanju Chen, Yuan Tian, and Yu Feng. 2026. Semia: Auditing Agent Skills via Constraint-Guided Representation Synthesis.arXiv preprint arXiv:2605.00314(2026)
Pith/arXiv arXiv 2026
-
[57]
Renjun Xu and Yang Yan. 2026. Agent Skills for Large Language Models: Architec- ture, Acquisition, Security, and the Path Forward.arXiv preprint arXiv:2602.12430 (2026)
Pith/arXiv arXiv 2026
-
[58]
Qiusi Zhan, Richard Fang, Henil Shalin Panchal, and Daniel Kang. 2025. Adaptive Attacks Break Defenses Against Indirect Prompt Injection Attacks on LLM Agents. InFindings of NAACL. doi:10.18653/v1/2025.findings-naacl.395
-
[59]
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. 2025. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents. In International Conference on Learning Representations, Vol. 2025. 35331–35366
2025
-
[60]
Kaijie Zhu, Xianjun Yang, Jindong Wang, Wenbo Guo, and William Yang Wang
-
[61]
InInternational Conference on Machine Learning
MELON: Provable Defense Against Indirect Prompt Injection Attacks in AI Agents. InInternational Conference on Machine Learning. PMLR, 80310–80329
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.