Turing Patterns for Multimedia: Reaction-Diffusion Multi-Modal Fusion for Language-Guided Video Moment Retrieval
Pith reviewed 2026-06-28 15:43 UTC · model grok-4.3
The pith
Video-language alignment modeled as a reaction-diffusion process creates emergent patterns that adaptively fuse modalities for moment retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reimagining video-language alignment as a reaction-diffusion process in which video features diffuse across time and text-video interactions serve as nonlinear reactions, the RDMF framework produces emergent patterns that improve modality alignment and moment retrieval, with mathematical guarantees of stability drawn from Turing instability analysis of the Gray-Scott model.
What carries the argument
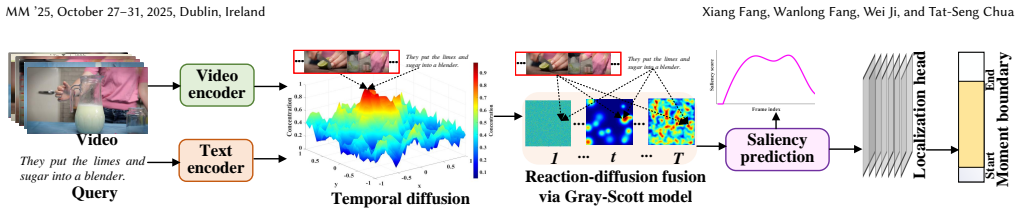
Reaction-Diffusion Multimodal Fusion (RDMF) module based on the Gray-Scott model, where diffusion spreads video context temporally and nonlinear reactions between modalities generate adaptive alignment patterns.
If this is right
- The fusion module integrates directly with pretrained video and text encoders plus DETR-style heads for both moment retrieval and saliency prediction.
- Turing instability criteria provide explicit conditions for stable pattern formation and convergence of the fusion process.
- The approach supplies a new biologically grounded paradigm that can replace or augment conventional multimodal fusion layers.
- Preliminary results indicate potential gains in identifying salient video moments over existing methods.
Where Pith is reading between the lines
- The same reaction-diffusion dynamics could be tested on other video-language tasks such as highlight detection or dense video captioning.
- Emergent patterns might be inspected post-training to reveal which temporal regions receive amplified alignment.
- Because the module is built from standard differential-equation discretizations, it may admit efficient GPU implementations without custom attention kernels.
Load-bearing premise
That modeling video and text interactions as a reaction-diffusion process will generate emergent patterns that adaptively improve alignment beyond what static cross-attention achieves.
What would settle it
A controlled comparison on a standard benchmark such as Charades-STA or ActivityNet Captions in which the RDMF fusion module yields equal or lower retrieval accuracy than a matched static cross-attention baseline.
Figures


read the original abstract
Video-language models are pivotal for tasks such as moment retrieval and highlight detection, yet they often struggle to capture the dynamic, non-linear interactions between temporal video sequences and textual semantics. Existing approaches, relying on static cross-attention or prompt-tuning mechanisms, fail to adaptively model the evolving relationships between modalities, leading to suboptimal alignment and limited generalization. Inspired by systems biology, we propose \textbf{Reaction-Diffusion Multimodal Fusion (RDMF)}, a novel framework that reimagines video-language alignment as a reaction-diffusion (RD) process, drawing on the principles of pattern formation introduced by Alan Turing. In RDMF, video features diffuse across time to capture temporal context, while text-video interactions are modeled as non-linear reactions that amplify relevant features and suppress noise, forming emergent patterns akin to biological systems. Leveraging the Gray-Scott RD model, we design a computationally efficient fusion module that integrates video and text representations, supported by rigorous mathematical analysis of stability and convergence using Turing instability criteria. Our framework is theoretically grounded, employing advanced mathematical tools to ensure stable pattern formation, and is practically viable, incorporating standard components like pretrained encoders and DETR-style heads for moment retrieval and saliency prediction. RDMF represents a pioneering interdisciplinary approach, bridging systems biology and multimedia research to address the limitations of conventional multimodal fusion. Preliminary experiments demonstrate its potential to outperform existing methods in identifying salient video moments, offering a new paradigm for video-language tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Reaction-Diffusion Multimodal Fusion (RDMF) for language-guided video moment retrieval. It reinterprets video-text alignment as a Gray-Scott reaction-diffusion process in which video features diffuse temporally and text-video interactions act as nonlinear reactions, generating emergent Turing patterns for improved modality alignment. The work claims a rigorous mathematical analysis of stability and convergence via Turing instability criteria, uses pretrained encoders and DETR-style heads, and reports that preliminary experiments indicate outperformance over existing methods.
Significance. If the claimed stability analysis holds and the discretized RD system is shown to operate inside the Turing regime while producing alignment-improving patterns, the approach would constitute a genuinely novel interdisciplinary contribution that could address limitations of static cross-attention in dynamic multimodal settings.
major comments (2)
- [Abstract] Abstract: the central claim that the RDMF module is 'supported by rigorous mathematical analysis of stability and convergence using Turing instability criteria' is load-bearing, yet the manuscript supplies no Jacobian, dispersion relation, trace/determinant conditions, or verification that the chosen Gray-Scott coefficients and discrete temporal diffusion operator satisfy the inequalities required for positive real-part eigenvalues; without these the assertion that emergent patterns improve alignment cannot be evaluated.
- [Abstract] Abstract: the claim that 'preliminary experiments demonstrate its potential to outperform existing methods' is load-bearing for practical viability, yet no datasets, baselines, metrics, or quantitative results are reported, leaving the empirical support for the modeling choice unverifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where the manuscript's claims require additional substantiation. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the RDMF module is 'supported by rigorous mathematical analysis of stability and convergence using Turing instability criteria' is load-bearing, yet the manuscript supplies no Jacobian, dispersion relation, trace/determinant conditions, or verification that the chosen Gray-Scott coefficients and discrete temporal diffusion operator satisfy the inequalities required for positive real-part eigenvalues; without these the assertion that emergent patterns improve alignment cannot be evaluated.
Authors: We acknowledge that the current version of the manuscript states the existence of a stability analysis but does not supply the explicit derivations. In the revised manuscript we will add a dedicated subsection (and appendix) that presents the Jacobian matrix of the discretized Gray-Scott system, derives the dispersion relation under the chosen temporal diffusion operator, states the trace/determinant conditions, and verifies that the selected coefficients place the system inside the Turing-unstable regime with positive real-part eigenvalues. This will allow direct evaluation of the claim that the emergent patterns improve modality alignment. revision: yes
-
Referee: [Abstract] Abstract: the claim that 'preliminary experiments demonstrate its potential to outperform existing methods' is load-bearing for practical viability, yet no datasets, baselines, metrics, or quantitative results are reported, leaving the empirical support for the modeling choice unverifiable.
Authors: The present manuscript contains only the qualitative statement about preliminary experiments. We will expand the paper with a new Experiments section that reports quantitative results on standard language-guided moment retrieval benchmarks (Charades-STA, ActivityNet Captions), using established baselines (Moment-DETR, 2D-TAN, etc.) and metrics (R@1, mIoU). The abstract will be updated to reference these concrete results rather than the current placeholder phrasing. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description present the RDMF module as a design choice inspired by the Gray-Scott model, with a claimed mathematical analysis of stability via Turing criteria. No equations, self-citations, fitted parameters renamed as predictions, or uniqueness theorems are quoted that reduce any claimed result to its own inputs by construction. The framework is described as reimagining alignment as an RD process, but this is an ansatz and modeling decision rather than a derivation that loops back on itself. The paper is self-contained against external benchmarks in the provided text, with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gray-Scott reaction and diffusion coefficients
axioms (2)
- domain assumption Video features can be usefully modeled as diffusing across time while text-video interactions behave as non-linear reactions that amplify relevant features and suppress noise.
- domain assumption Turing instability criteria guarantee stable pattern formation and convergence for the fusion module.
Reference graph
Works this paper leans on
-
[1]
Fuyao Cai, Daizong Liu, Xiang Fang, Jixiang Yu, Keke Tang, and Pan Zhou
-
[2]
In2025 IEEE International Conference on Multimedia and Expo (ICME)
Imperceptible Beam-Sensitive Adversarial Attacks for LiDAR-based Object Detection in Autonomous Driving. In2025 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6. Turing Patterns for Multimedia: Reaction-Diffusion Multi-Modal Fusion for Language-Guided Video Moment Retrieval MM ’25, October 27–31, 2025, Dublin, Ireland
2025
-
[3]
Xiaowen Cai, Daizong Liu, Xiaoye Qu, Xiang Fang, Jianfeng Dong, Keke Tang, Pan Zhou, Lichao Sun, and Wei Hu. 2026. Towards building model/prompt- transferable attackers against large vision-language models.Advances in Neural Information Processing Systems38 (2026), 174022–174058
2026
-
[4]
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexan- der Kirillov, and Sergey Zagoruyko. 2020. End-to-end object detection with transformers. InEuropean conference on computer vision. Springer, 213–229
2020
-
[5]
Jingyuan Chen, Xinpeng Chen, Lin Ma, Zequn Jie, and Tat-Seng Chua. 2018. Tem- porally grounding natural sentence in video. InProceedings of the 2018 conference on empirical methods in natural language processing. 162–171
2018
-
[6]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[7]
Wanlong Fang, Tianle Zhang, and Alvin Chan. 2026. To align or not to align: Strategic multimodal representation alignment for optimal performance. InPro- ceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 21056–21064
2026
-
[8]
Wanlong Fang, Tianle Zhang, Wen Tao, and Alvin Chan. 2026. Towards Un- derstanding Modality Interaction in Multimodal Language Models via Partial Information Decomposition. InInternational Conference on Machine Learning
2026
-
[9]
Xiang Fang. 2026. Advancing Out-of-Distribution Detection Across Diverse Scenarios. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 41042–41043
2026
-
[10]
Xiang Fang, Arvind Easwaran, and Blaise Genest. 2025. Adaptive Multi-prompt Contrastive Network for Few-shot Out-of-distribution Detection. InInternational Conference on Machine Learning
2025
-
[11]
Xiang Fang, Arvind Easwaran, Blaise Genest, and Ponnuthurai Nagaratnam Suganthan. 2025. Adaptive Hierarchical Graph Cut for Multi-granularity Out-of- distribution Detection.IEEE Transactions on Artificial Intelligence(2025)
2025
-
[12]
Xiang Fang, Arvind Easwaran, Blaise Genest, and Ponnuthurai Nagaratnam Sug- anthan. 2025. Your data is not perfect: Towards cross-domain out-of-distribution detection in class-imbalanced data.Expert Systems with Applications(2025)
2025
-
[13]
Xiang Fang and Wanlong Fang. 2026. Disentangling Adversarial Prompts: A Semantic-Graph Defense for Robust LLM Security. InProceedings of the AAAI Conference on Artificial Intelligence
2026
-
[14]
Xiang Fang and Wanlong Fang. 2026. SLAP: The Semantic Least Action Principle for Variational Video-Language Modeling. InInternational Conference on Machine Learning
2026
-
[15]
Xiang Fang, Wanlong Fang, and Wei Ji. 2026. Immuno-VLM: Immunizing Large Vision-Language Models via Generative Semantic Antibodies for Open-World Trustworthiness. InInternational Conference on Machine Learning
2026
-
[16]
Xiang Fang, Wanlong Fang, Daizong Liu, Xiaoye Qu, Jianfeng Dong, Pan Zhou, Renfu Li, Zichuan Xu, Lixing Chen, Panpan Zheng, et al. 2024. Not all inputs are valid: Towards open-set video moment retrieval using language. InProceedings of the 32nd ACM International Conference on Multimedia. 28–37
2024
-
[17]
Xiang Fang, Wanlong Fang, and Changshuo Wang. 2025. Hierarchical Semantic- Augmented Navigation: Optimal Transport and Graph-Driven Reasoning for Vision-Language Navigation. InAdvances in Neural Information Processing Sys- tems
2025
-
[18]
Xiang Fang, Wanlong Fang, and Changshuo Wang. 2026. CogniVerse: Revolution- izing Multi-modal Retrieval-Augmented Generation with Cognitive Reflection and Geometric Reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2026
-
[19]
Xiang Fang, Wanlong Fang, and Changshuo Wang. 2026. Unveiling the Fragility of Vision-Language Models: Multi-Modal Adversarial Synergy via Texture- Constrained Perturbations and Cross-Modal Optimization. InProceedings of the AAAI Conference on Artificial Intelligence
2026
-
[20]
Xiang Fang, Wanlong Fang, Changshuo Wang, Daizong Liu, Keke Tang, Jianfeng Dong, Pan Zhou, and Beibei Li. 2025. Multi-pair temporal sentence grounding via multi-thread knowledge transfer network. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 2915–2923
2025
-
[21]
Xiang Fang, Wanlong Fang, Changshuo Wang, Daizong Liu, Keke Tang, Jianfeng Dong, Pan Zhou, and Beibei Li. 2025. Multi-Pair Temporal Sentence Ground- ing via Multi-Thread Knowledge Transfer Network. InProceedings of the AAAI Conference on Artificial Intelligence
2025
-
[22]
Xiang Fang, Wanlong Fang, Changshuo Wang, Xiaoye Qu, and Daizong Liu
-
[23]
InProceedings of the AAAI Conference on Artificial Intelligence
Rethinking Video-language Model From the Language Input Perspective. InProceedings of the AAAI Conference on Artificial Intelligence
-
[24]
Xiang Fang, Wanlong Fang, Changshuo Wang, Keke Tang, Daizong Liu, Siyi Wang, and Wei Ji. 2026. Towards Unified Vision-Language Models With Incom- plete Multi-Modal Inputs. InProceedings of the AAAI Conference on Artificial Intelligence
2026
-
[25]
Xiang Fang and Yuchong Hu. 2020. Double self-weighted multi-view clustering via adaptive view fusion.arXiv preprint arXiv:2011.10396(2020)
Pith/arXiv arXiv 2020
-
[26]
Xiang Fang, Yuchong Hu, Pan Zhou, and Dapeng Wu. 2021. Animc: A soft approach for autoweighted noisy and incomplete multiview clustering.IEEE Transactions on Artificial Intelligence3, 2 (2021), 192–206
2021
-
[27]
Xiang Fang, Yuchong Hu, Pan Zhou, and Dapeng Oliver Wu. 2020. V3H: View variation and view heredity for incomplete multiview clustering.IEEE Transac- tions on Artificial Intelligence1, 3 (2020), 233–247
2020
-
[28]
Xiang Fang, Yuchong Hu, Pan Zhou, and Dapeng Oliver Wu. 2021. Unbalanced in- complete multi-view clustering via the scheme of view evolution: Weak views are meat; strong views do eat.IEEE Transactions on Emerging Topics in Computational Intelligence6, 4 (2021), 913–927
2021
-
[29]
Xiang Fang, Daizong Liu, Wanlong Fang, Pan Zhou, Yu Cheng, Keke Tang, and Kai Zou. 2023. Annotations Are Not All You Need: A Cross-modal Knowledge Transfer Network for Unsupervised Temporal Sentence Grounding. InFindings of the Association for Computational Linguistics: EMNLP 2023. 8721–8733
2023
-
[30]
Xiang Fang, Daizong Liu, Wanlong Fang, Pan Zhou, Zichuan Xu, Wenzheng Xu, Junyang Chen, and Renfu Li. 2024. Fewer Steps, Better Performance: Efficient Cross-Modal Clip Trimming for Video Moment Retrieval Using Language. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 1735–1743
2024
-
[31]
Xiang Fang, Daizong Liu, Pan Zhou, and Yuchong Hu. 2022. Multi-modal cross- domain alignment network for video moment retrieval.IEEE Transactions on Multimedia25 (2022), 7517–7532
2022
-
[32]
Xiang Fang, Daizong Liu, Pan Zhou, and Guoshun Nan. 2023. You can ground earlier than see: An effective and efficient pipeline for temporal sentence ground- ing in compressed videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2448–2460
2023
-
[33]
Xiang Fang, Daizong Liu, Pan Zhou, Zichuan Xu, and Ruixuan Li. 2023. Hierarchi- cal local-global transformer for temporal sentence grounding.IEEE Transactions on Multimedia(2023)
2023
-
[34]
Xiang Fang, Zeyu Xiong, Wanlong Fang, Xiaoye Qu, Chen Chen, Jianfeng Dong, Keke Tang, Pan Zhou, Yu Cheng, and Daizong Liu. 2024. Rethinking Weakly- supervised Video Temporal Grounding From a Game Perspective. InEuropean Conference on Computer Vision. Springer
2024
-
[35]
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. 2019. Slow- fast networks for video recognition. InProceedings of the IEEE/CVF international conference on computer vision. 6202–6211
2019
-
[36]
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. 2017. Tall: Temporal activity localization via language query. InProceedings of the IEEE international conference on computer vision. 5267–5275
2017
-
[37]
Peter Gray and Stephen K Scott. 1983. Autocatalytic reactions in the isothermal, continuous stirred tank reactor: isolas and other forms of multistability.Chemical Engineering Science38, 1 (1983), 29–43
1983
-
[38]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision- language representation learning with noisy text supervision. InInternational conference on machine learning. PMLR, 4904–4916
2021
-
[39]
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles
-
[40]
InProceedings of the IEEE international conference on computer vision
Dense-captioning events in videos. InProceedings of the IEEE international conference on computer vision. 706–715
-
[41]
Mingjin Kuai, You Qin, Xiang Fang, Wei Ji, and Roger Zimmermann. 2026. Dy- namic Graph-enhanced Event Refinement for Temporal Sentence Grounding of Micro-moments.IEEE Transactions on Multimedia(2026)
2026
-
[42]
Huashuo Lei, Xiaowen Cai, Daizong Liu, Xiang Fang, Xiaoye Qu, Jianfeng Dong, Jixiang Yu, and Keyan Jin. 2025. Exploring Disentangled Appearance-Motion Contexts for Temporal Activity Localization. In2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8
2025
-
[43]
Jie Lei, Tamara L Berg, and Mohit Bansal. 2021. Detecting moments and highlights in videos via natural language queries.Advances in Neural Information Processing Systems34 (2021), 11846–11858
2021
-
[44]
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. 2023. Univtg: To- wards unified video-language temporal grounding. InProceedings of the IEEE/CVF international conference on computer vision. 2794–2804
2023
-
[45]
Daizong Liu, Xiaowen Cai, Junhao Dong, Zhongliang Guo, Xiaoye Qu, Runwei Guan, Xiang Fang, and Dengpan Ye. 2026. Attacking Gray-Box Large Vision- Language Models with Adaptive SVD-Structured Adversarial Alignment. In International Conference on Machine Learning
2026
-
[46]
Daizong Liu, Xiang Fang, Wei Hu, and Pan Zhou. 2023. Exploring optical-flow- guided motion and detection-based appearance for temporal sentence grounding. IEEE Transactions on Multimedia25 (2023), 8539–8553
2023
-
[47]
Daizong Liu, Xiang Fang, Xiaoye Qu, Jianfeng Dong, He Yan, Yang Yang, Pan Zhou, and Yu Cheng. 2024. Unsupervised domain adaptative temporal sentence localization with mutual information maximization. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 3567–3575
2024
-
[48]
Daizong Liu, Xiang Fang, Pan Zhou, Xing Di, Weining Lu, and Yu Cheng. 2023. Hypotheses tree building for one-shot temporal sentence localization. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 37. 1640–1648
2023
-
[49]
Daizong Liu, Xiaoye Qu, Xiang Fang, Jianfeng Dong, Pan Zhou, Guoshun Nan, Keke Tang, Wanlong Fang, and Yu Cheng. 2024. Towards robust temporal activity localization learning with noisy labels. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 16630–16642. MM ’25, Oc...
2024
-
[50]
Daizong Liu, Mingyu Yang, Xiaoye Qu, Pan Zhou, Xiang Fang, Keke Tang, Yao Wan, and Lichao Sun. 2024. Pandora’s box: Towards building universal attackers against real-world large vision-language models.Advances in Neural Information Processing Systems37 (2024), 52127–52158
2024
-
[51]
Daizong Liu, Jiahao Zhu, Xiang Fang, Zeyu Xiong, Huan Wang, Renfu Li, and Pan Zhou. 2023. Conditional video diffusion network for fine-grained temporal sentence grounding.IEEE Transactions on Multimedia26 (2023), 5461–5476
2023
-
[52]
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. 2022. Video swin transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3202–3211
2022
-
[53]
WonJun Moon, Sangeek Hyun, SuBeen Lee, and Jae-Pil Heo. 2023. Correlation- guided query-dependency calibration for video temporal grounding.arXiv preprint arXiv:2311.08835(2023)
arXiv 2023
-
[54]
WonJun Moon, Sangeek Hyun, SangUk Park, Dongchan Park, and Jae-Pil Heo
-
[55]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Query-dependent video representation for moment retrieval and highlight detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 23023–23033
-
[56]
2003.Mathematical biology: II: spatial models and biomedical applications
James Dickson Murray and James Dickson Murray. 2003.Mathematical biology: II: spatial models and biomedical applications. Vol. 18. Springer
2003
-
[57]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[58]
Keke Tang, Chao Hou, Weilong Peng, Xiang Fang, Zhize Wu, Yongwei Nie, Wenping Wang, and Zhihong Tian. 2025. Simplification is all you need against out-of-distribution overconfidence. InProceedings of the Computer Vision and Pattern Recognition Conference. 5030–5040
2025
-
[59]
Keke Tang, Wenyu Zhao, Weilong Peng, Xiang Fang, Xiaodong Cui, Peican Zhu, and Zhihong Tian. 2024. Reparameterization head for efficient multi-input networks. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 6190–6194
2024
-
[60]
Alan Mathison Turing. 1990. The chemical basis of morphogenesis.Bulletin of mathematical biology52, 1 (1990), 153–197
1990
-
[61]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[62]
Changshuo Wang, Xiang Fang, and Prayag Tiwari. 2025. DyPolySeg: Taylor Series-Inspired Dynamic Polynomial Fitting Network for Few-shot Point Cloud Semantic Segmentation. InForty-second International Conference on Machine Learning
2025
-
[63]
Changshuo Wang, Shuting He, Xiang Fang, Jiawei Han, Zhonghang Liu, Xin Ning, Weijun Li, and Prayag Tiwari. 2025. Point clouds meets physics: Dynamic acoustic field fitting network for point cloud understanding. InProceedings of the Computer Vision and Pattern Recognition Conference. 22182–22192
2025
-
[64]
Changshuo Wang, Shuting He, Xiang Fang, Zhijian Hu, Jia-Hong Huang, Yixian Shen, and Prayag Tiwari. 2026. Reasoning beyond points: A visual introspec- tive approach for few-shot 3d segmentation.Advances in Neural Information Processing Systems38 (2026), 117394–117414
2026
-
[65]
Changshuo Wang, Shuting He, Xiang Fang, Weijun Li, Yixian Shen, Mingkun Xu, Zhongtian Sun, and Prayag Tiwari. 2026. TopAdapter: Topology-Aware Prompt Tuning for Efficient Point Cloud Understanding.International Conference on Machine Learning(2026)
2026
-
[66]
Changshuo Wang, Shuting He, Xiang Fang, Fangzhe Nan, and Prayag Tiwari
-
[67]
InProceedings of the 33rd ACM International Conference on Multimedia
Seeing the Overlooked: Bio-Visual Inspired Weak Saliency Feedback Trans- former for Person Re-identification. InProceedings of the 33rd ACM International Conference on Multimedia. 3192–3201
-
[68]
Changshuo Wang, Shuting He, Xiang Fang, Meiqing Wu, Siew-Kei Lam, and Prayag Tiwari. 2025. Taylor series-inspired local structure fitting network for few- shot point cloud semantic segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 7527–7535
2025
-
[69]
Changshuo Wang, Zhijian Hu, Xiang Fang, Zai Yang Yu, Yibin Wu, Mingkun Xu, Yusong Wang, Xingyu Gao, and Prayag Tiwari. 2026. Biologically-Inspired Evolutionary Domain Symbiosis for Few-shot and Zero-shot Point Cloud Seman- tic Segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 9666–9674
2026
-
[70]
Changshuo Wang, Weijun Li, Shuting He, Xiang Fang, Xingyu Gao, Zhonghang Liu, Prayag Tiwari, and Dimitrios Kanoulas. 2026. From Coarse to Fine: Deep Prototype Refinement Network for Few-Shot Point Cloud Semantic Segmentation. International Conference on Machine Learning(2026)
2026
-
[71]
Junyi Wang, Jinjiang Li, Guodong Fan, Yakun Ju, Xiang Fang, and Alex C Kot
-
[72]
Prototype-driven structure synergy network for remote sensing images segmentation.IEEE Transactions on Geoscience and Remote Sensing(2025)
2025
-
[73]
Siyi Wang, Suman Dutta, Wei Jie Bryan Lee, Jerrie Feng, Xiang Fang, and Anupam Chattopadhyay. 2025. Reducing T-Depth and T-Count in Quantum Multiplication Using Compressor Primitives. InProceedings of the Great Lakes Symposium on VLSI 2025. 35–40
2025
-
[74]
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, et al . 2022. Internvideo: General video foundation models via generative and discriminative learning.arXiv preprint arXiv:2212.03191(2022)
Pith/arXiv arXiv 2022
-
[75]
Zeyu Xiong, Daizong Liu, Xiang Fang, Xiaoye Qu, Jianfeng Dong, Jiahao Zhu, Keke Tang, and Pan Zhou. 2024. Rethinking video sentence grounding from a tracking perspective with memory network and masked attention.IEEE Transac- tions on Multimedia26 (2024), 11204–11218
2024
-
[76]
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. 2021. Videoclip: Contrastive pre-training for zero-shot video-text understanding. InProceedings of the 2021 conference on empirical methods in natural language processing. 6787– 6800
2021
-
[77]
Hai Yan, Haijian Ma, Xiaowen Cai, Daizong Liu, Zenghui Yuan, Xiaoye Qu, Jianfeng Dong, Runwei Guan, Xiang Fang, Hongyang He, et al . 2026. Fit the distribution: Cross-image/prompt adversarial attacks on multimodal large lan- guage models.Advances in Neural Information Processing Systems38 (2026), 75204–75247
2026
-
[78]
Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. 2022. Tubedetr: Spatio-temporal video grounding with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16442– 16453
2022
-
[79]
Guide Yang, Chao Hou, Weilong Peng, Xiang Fang, Yongwei Nie, Peican Zhu, and Keke Tang. 2025. EOOD: Entropy-based Out-of-distribution Detection. In 2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8
2025
-
[80]
Hao Zhang, Aixin Sun, Wei Jing, and Joey Tianyi Zhou. 2020. Span-based localiz- ing network for natural language video localization. InProceedings of the 58th annual meeting of the association for computational linguistics. 6543–6554
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.