Can Language Models Actually Retrieve In-Context? Drowning in Documents at Million Token Scale
Pith reviewed 2026-07-03 20:41 UTC · model grok-4.3
The pith
Language models with length-aware attention fixes can match dense retrieval at million-token scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
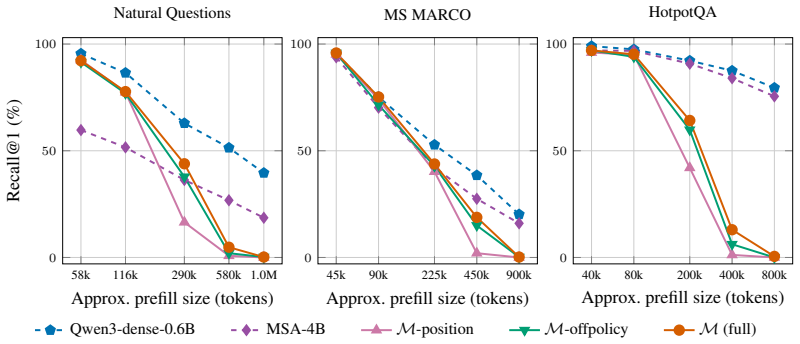
BlockSearch demonstrates that length-aware adjustments to the attention softmax and document-level sparse attention prevent irrelevant documents from dominating the normalized attention mass, allowing a small LM retriever to match dense retrieval performance at the million-token scale on standard benchmarks and exceed it on non-standard similarity tasks.
What carries the argument
Length-aware adjustments to the attention softmax combined with document-level sparse attention, which restore normalized mass on relevant documents as corpus length increases.
If this is right
- In-context retrieval becomes a practical alternative to vector retrieval at corpus scales used in real systems.
- Smaller models can handle context lengths far beyond training without collapse when attention is controlled by length.
- Performance gains appear on tasks whose similarity notion differs from embedding-based matching.
- Attention control under extreme context growth emerges as a distinct engineering challenge.
Where Pith is reading between the lines
- The same dilution mechanism may limit other long-context generation tasks beyond retrieval.
- Training regimes that explicitly vary corpus length during pretraining could reduce reliance on post-hoc fixes.
- Sparse attention at the document level might combine with other efficiency techniques for even larger contexts.
Load-bearing premise
Retrieval collapse stems mainly from attention dilution in the softmax denominator, and the proposed length-aware fixes plus sparse attention will restore performance at scale without introducing new offsetting failures.
What would settle it
An experiment showing that on a million-token corpus the gold document retains high pre-softmax logit but still receives low post-adjustment attention mass, or that the model fails to generalize beyond ten times its training length.
Figures


read the original abstract
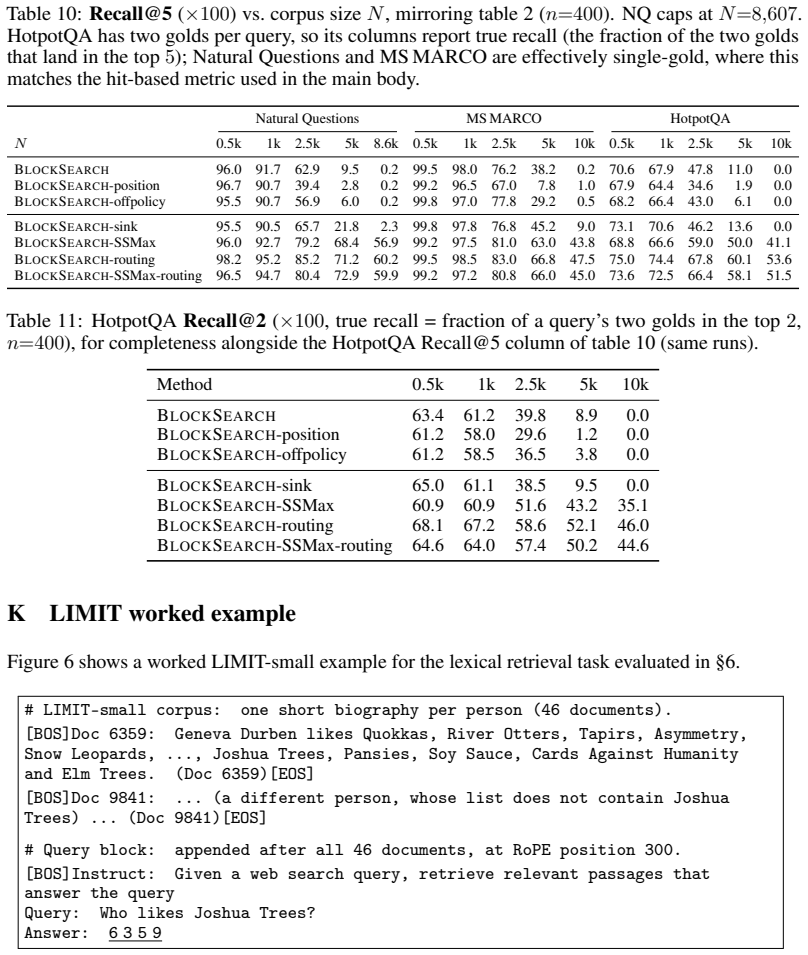
Language models (LMs) raise an intriguing alternative to vector-based retrieval: conditioning on an in-context corpus and directly generating a relevant answer. However, prior work has largely focused on proprietary systems or the smaller-scale reranking task, leaving corpus-scale in-context retrieval largely unexplored. In this work, we present the first systematic study of in-context retrieval on two scales practical retrievers demand: million-token corpora and length-generalization far beyond training-time sizes. We first introduce BlockSearch, a 0.6B LM retriever whose architectural and training modifications improve over prior LM baselines and length-generalize up to 10 times beyond its training regime. Nevertheless, retrieval still collapses under more extreme extrapolation. We trace this failure to an attention dilution effect: as the corpus grows, irrelevant documents dominate the softmax denominator, reducing the normalized mass on the gold document even when its pre-softmax score stays high. Motivated by this analysis, we introduce length-aware adjustments to the attention softmax and document-level sparse attention. With these modifications, at the million-token scale, our model matches dense retrieval on widely studied benchmarks (e.g, MS MARCO and NQ), while outperforming the concurrent model MSA despite being 7 times smaller. Furthermore, it significantly outperforms dense retrieval on tasks requiring entirely different notions of similarity, such as LIMIT, achieving a 3 times higher score. Together, our results position in-context retrieval a promising alternative to classical retrieval while emphasizing attention control under extreme context growth as a new challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to present the first systematic study of in-context retrieval at million-token corpora and extreme length generalization. It introduces BlockSearch, a 0.6B LM retriever with architectural/training modifications that improve over prior LM baselines and length-generalize up to 10x training regime. Retrieval still collapses under more extreme extrapolation, which the authors trace to attention dilution (irrelevant documents dominating the softmax denominator while gold-document pre-softmax scores remain high). Motivated by this, they propose length-aware adjustments to the attention softmax and document-level sparse attention. With these changes, the model is claimed to match dense retrieval on MS MARCO and NQ at the million-token scale, outperform the concurrent MSA model despite being 7 times smaller, and achieve a 3 times higher score than dense retrieval on LIMIT.
Significance. If the empirical results hold, the work would position in-context retrieval as a competitive alternative to classical dense retrieval, especially for tasks with non-vector notions of similarity, while identifying attention control under extreme context growth as a distinct scaling challenge. The size efficiency relative to MSA and the outperformance on LIMIT would be notable contributions if substantiated.
major comments (2)
- [Abstract] Abstract: The central performance claims (matching dense retrieval on MS MARCO/NQ at 1M tokens, 3x higher score on LIMIT, outperforming MSA while 7x smaller) are stated without any description of experimental setup, baselines, metrics, statistical tests, or controls, making it impossible to determine whether the data support the claims.
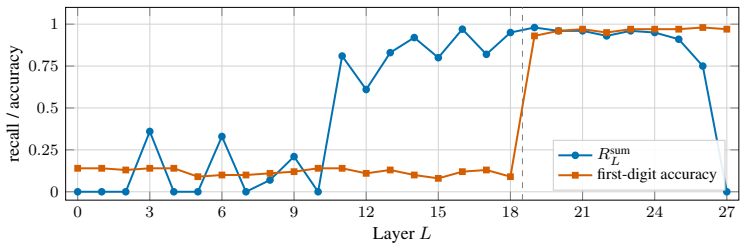
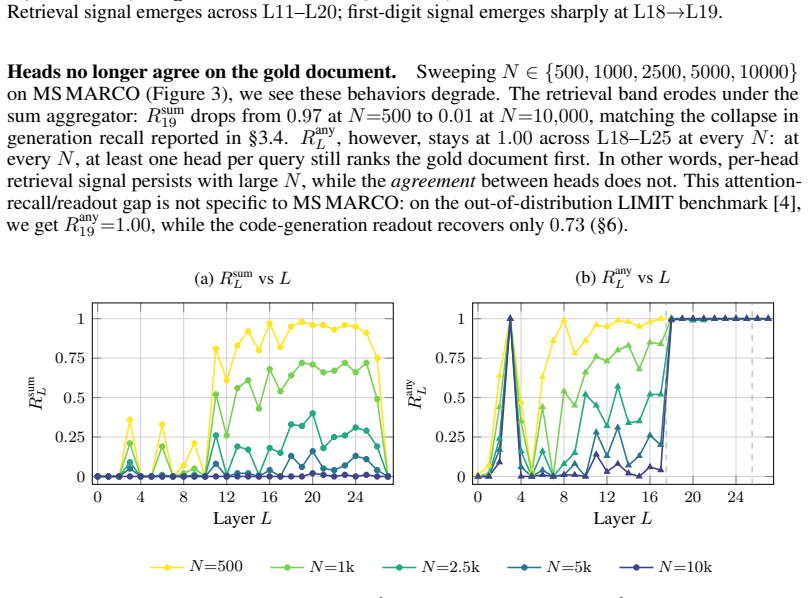
- [Abstract] Abstract: The diagnosis that collapse is due to attention dilution (with gold pre-softmax logits staying high) is presented without quantitative support such as measurements or plots of pre-softmax gold scores or attention mass across lengths from 10k to 1M tokens; this leaves open whether the proposed fixes address the primary failure mode or a secondary symptom.
minor comments (1)
- [Abstract] Abstract: The introduction of 'BlockSearch' and 'length-aware adjustments' would benefit from a brief parenthetical definition or pointer to the relevant section on first use.
Simulated Author's Rebuttal
We thank the referee for the feedback. We address the two major comments on the abstract below and will make targeted revisions for clarity while preserving the abstract's concise nature. Full experimental details and supporting analyses appear in the manuscript body.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (matching dense retrieval on MS MARCO/NQ at 1M tokens, 3x higher score on LIMIT, outperforming MSA while 7x smaller) are stated without any description of experimental setup, baselines, metrics, statistical tests, or controls, making it impossible to determine whether the data support the claims.
Authors: The abstract provides a high-level summary; the full experimental setup, baselines (dense retrieval and MSA), metrics, and controls are detailed in Sections 3 and 4 of the manuscript, with results on MS MARCO, NQ, and LIMIT. To improve accessibility, we will revise the abstract to briefly note the benchmarks and primary comparison models. revision: partial
-
Referee: [Abstract] Abstract: The diagnosis that collapse is due to attention dilution (with gold pre-softmax logits staying high) is presented without quantitative support such as measurements or plots of pre-softmax gold scores or attention mass across lengths from 10k to 1M tokens; this leaves open whether the proposed fixes address the primary failure mode or a secondary symptom.
Authors: The abstract summarizes the finding; quantitative measurements of pre-softmax scores, attention mass dilution, and length scaling (10k to 1M tokens) are presented with plots in Section 4.2 and Figure 3. We will revise the abstract to explicitly reference this supporting analysis. revision: partial
Circularity Check
No circularity; empirical benchmark results
full rationale
The paper presents its core results as direct empirical comparisons on standard retrieval benchmarks (MS MARCO, NQ, LIMIT) after applying architectural modifications. The attention-dilution diagnosis is offered as an observational motivation for the changes rather than a mathematical derivation; reported scores are measured against external baselines and are not reduced to quantities defined by internal fits, self-citations, or ansatzes. No load-bearing step equates a claimed prediction or uniqueness result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models can learn to retrieve by conditioning directly on a provided corpus.
invented entities (2)
-
BlockSearch
no independent evidence
-
length-aware adjustments to the attention softmax
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781, 2020
2020
-
[2]
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Bo- ratko, Yi Luan, Sébastien MR Arnold, Vincent Perot, Siddharth Dalmia, et al. Can long-context language models subsume retrieval, rag, sql, and more?arXiv preprint arXiv:2406.13121, 2024
-
[3]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[4]
On the theoretical limitations of embedding-based retrieval.arXiv preprint arXiv:2508.21038, 2025
Orion Weller, Michael Boratko, Iftekhar Naim, and Jinhyuk Lee. On the theoretical limitations of embedding-based retrieval.arXiv preprint arXiv:2508.21038, 2025
-
[5]
Scalable in-context ranking with generative models.arXiv preprint arXiv:2510.05396, 2025
Nilesh Gupta, Chong You, Srinadh Bhojanapalli, Sanjiv Kumar, Inderjit Dhillon, and Felix Yu. Scalable in-context ranking with generative models.arXiv preprint arXiv:2510.05396, 2025
-
[6]
Eliciting in-context retrieval and reasoning for long-context large language models
Yifu Qiu, Varun R Embar, Yizhe Zhang, Navdeep Jaitly, Shay B Cohen, and Benjamin Han. Eliciting in-context retrieval and reasoning for long-context large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 3176–3192, 2025
2025
-
[7]
Longbench v2: Towards deeper understanding and reason- ing on realistic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, et al. Longbench v2: Towards deeper understanding and reason- ing on realistic long-context multitasks. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3639–3664, 2025
2025
-
[8]
Context rot: How increasing input tokens impacts llm performance
Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts llm performance. Technical report, Chroma, July 2025
2025
-
[9]
Scalable-softmax is superior for attention.arXiv preprint arXiv:2501.19399, 2025
Ken M Nakanishi. Scalable-softmax is superior for attention.arXiv preprint arXiv:2501.19399, 2025
-
[10]
Understanding and Improving Length Generalization in Hierarchical Sparse Attention Models
Jiaqi Leng, Xiang Hu, Junxiong Wang, Jianguo Li, Wei Wu, and Yucheng Lu. Understanding and improving length generalization in hierarchical sparse attention models.arXiv preprint arXiv:2510.17196, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Softmax is not enough (for sharp size generalisation).arXiv preprint arXiv:2410.01104, 2024
Petar Veliˇckovi´c, Christos Perivolaropoulos, Federico Barbero, and Razvan Pascanu. Softmax is not enough (for sharp size generalisation).arXiv preprint arXiv:2410.01104, 2024. 11
-
[12]
Transformers need glasses! informa- tion over-squashing in language tasks.Advances in Neural Information Processing Systems, 37:98111–98142, 2024
Federico Barbero, Andrea Banino, Steven Kapturowski, Dharshan Kumaran, João G Araújo, Alex Vitvitskyi, Razvan Pascanu, and Petar Veliˇckovi´c. Transformers need glasses! informa- tion over-squashing in language tasks.Advances in Neural Information Processing Systems, 37:98111–98142, 2024
2024
-
[13]
Lucid: Attention with preconditioned representations.arXiv preprint arXiv:2602.10410, 2026
Sai Surya Duvvuri, Nirmal Patel, Nilesh Gupta, and Inderjit S Dhillon. Lucid: Attention with preconditioned representations.arXiv preprint arXiv:2602.10410, 2026
-
[14]
MoBA: Mixture of Block Attention for Long-Context LLMs
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, et al. Moba: Mixture of block attention for long-context llms. arXiv preprint arXiv:2502.13189, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Optimizing mixture of block attention.arXiv preprint arXiv:2511.11571, 2025
Guangxuan Xiao, Junxian Guo, Kasra Mazaheri, and Song Han. Optimizing mixture of block attention.arXiv preprint arXiv:2511.11571, 2025
-
[16]
MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
Yu Chen, Runkai Chen, Sheng Yi, Xinda Zhao, Xiaohong Li, Jianjin Zhang, Jun Sun, Chuanrui Hu, Yunyun Han, Lidong Bing, et al. Msa: Memory sparse attention for efficient end-to-end memory model scaling to 100m tokens.arXiv preprint arXiv:2603.23516, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Block sparse flash attention.arXiv preprint arXiv:2512.07011, 2025
Daniel Ohayon, Itay Lamprecht, Itay Hubara, Israel Cohen, Daniel Soudry, and Noam Elata. Block sparse flash attention.arXiv preprint arXiv:2512.07011, 2025
-
[18]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Transformer memory as a differentiable search index.Advances in neural information processing systems, 35:21831–21843, 2022
Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. Transformer memory as a differentiable search index.Advances in neural information processing systems, 35:21831–21843, 2022
2022
-
[21]
A neural corpus indexer for document retrieval
Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, et al. A neural corpus indexer for document retrieval. Advances in Neural Information Processing Systems, 35:25600–25614, 2022
2022
-
[22]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems, 36:10299–10315, 2023
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al. Recommender systems with generative retrieval.Advances in Neural Information Processing Systems, 36:10299–10315, 2023
2023
-
[23]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Tokenselect: Efficient long-context inference and length extrapolation for llms via dynamic token-level kv cache selection
Wei Wu, Zhuoshi Pan, Kun Fu, Chao Wang, Liyi Chen, Yunchu Bai, Tianfu Wang, Zheng Wang, and Hui Xiong. Tokenselect: Efficient long-context inference and length extrapolation for llms via dynamic token-level kv cache selection. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21275–21292, 2025
2025
-
[25]
Xiang Hu, Zhihao Teng, Jun Zhao, Wei Wu, and Kewei Tu. Efficient length-generalizable atten- tion via causal retrieval for long-context language modeling.arXiv preprint arXiv:2410.01651, 2024
-
[26]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Mathew Jacob, Erik Lindgren, Matei Zaharia, Michael Carbin, Omar Khattab, and Andrew Drozdov. Drowning in documents: consequences of scaling reranker inference.arXiv preprint arXiv:2411.11767, 2024
-
[29]
Block-attention for efficient prefilling.arXiv preprint arXiv:2409.15355, 2024
Dongyang Ma, Yan Wang, and Lan Tian. Block-attention for efficient prefilling.arXiv preprint arXiv:2409.15355, 2024
-
[30]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[31]
Flex Attention: A Programming Model for Generating Optimized Attention Kernels
Juechu Dong, Boyuan Feng, Driss Guessous, Yanbo Liang, and Horace He. Flex attention: A pro- gramming model for generating optimized attention kernels.arXiv preprint arXiv:2412.05496, 2(3):4, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Nandan Thakur, Crystina Zhang, Xueguang Ma, and Jimmy Lin. Hard negatives, hard lessons: Revisiting training data quality for robust information retrieval with llms.arXiv preprint arXiv:2505.16967, 2025
-
[33]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. Ms marco: A human generated machine reading comprehension dataset.arXiv preprint arXiv:1611.09268, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Rocketqa: An optimized training approach to dense passage retrieval for open-domain question answering
Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. Rocketqa: An optimized training approach to dense passage retrieval for open-domain question answering. InProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technolog...
2021
-
[36]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[38]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 30–45, 2022
2022
-
[39]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. Retrieval head mecha- nistically explains long-context factuality.arXiv preprint arXiv:2404.15574, 2024
-
[41]
Query-focused retrieval heads improve long-context reasoning and re-ranking
Wuwei Zhang, Fangcong Yin, Howard Yen, Danqi Chen, and Xi Ye. Query-focused retrieval heads improve long-context reasoning and re-ranking. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 23802–23816, 2025
2025
-
[42]
Colbert: Efficient and effective passage search via contextual- ized late interaction over bert
Omar Khattab and Matei Zaharia. Colbert: Efficient and effective passage search via contextual- ized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48, 2020
2020
-
[43]
interpreting GPT: the logit lens
nostalgebraist. interpreting GPT: the logit lens. LessWrong, 2020
2020
-
[44]
On vanishing variance in transformer length generalization
Ruining Li, Gabrijel Boduljak, et al. On vanishing variance in transformer length generalization. arXiv preprint arXiv:2504.02827, 2025. 13
-
[45]
Long-context general- ization with sparse attention.arXiv preprint arXiv:2506.16640, 2025
Pavlo Vasylenko, Hugo Pitorro, André FT Martins, and Marcos Treviso. Long-context general- ization with sparse attention.arXiv preprint arXiv:2506.16640, 2025
-
[46]
OBLIQ-Bench: Exposing Overlooked Bottlenecks in Modern Retrievers with Latent and Implicit Queries
Diane Tchuindjo, Devavrat Shah, and Omar Khattab. Obliq-bench: Exposing overlooked bottle- necks in modern retrievers with latent and implicit queries.arXiv preprint arXiv:2605.06235, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth interna- tional conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011. 14 A Prompt Format To make the input format used by ...
2011
-
[48]
drop queries with fewer than16candidates or fewer than15negatives
-
[49]
max score(pos)≤ max score(neg)
drop queries where the highest-scoring candidate is a negative, i.e. max score(pos)≤ max score(neg)
-
[50]
Given a web search query, retrieve relevant passages that answer the query
retain the single best-scoring positive plus the top-15 highest-scoring negatives, giving exactly 16documents per query. The resulting post-filter, post-trim dataset has 522,487 training samples drawn from 7 source corpora (table 5); each sample is one query paired with its 16 documents. Optimization steps are stratified per source: each batch contains qu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.