OBLIQ-Bench: Exposing Overlooked Bottlenecks in Modern Retrievers with Latent and Implicit Queries
Pith reviewed 2026-06-30 23:22 UTC · model grok-4.3
The pith
Modern retrievers miss most documents that match latent patterns, even when LLMs can spot the match once shown.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
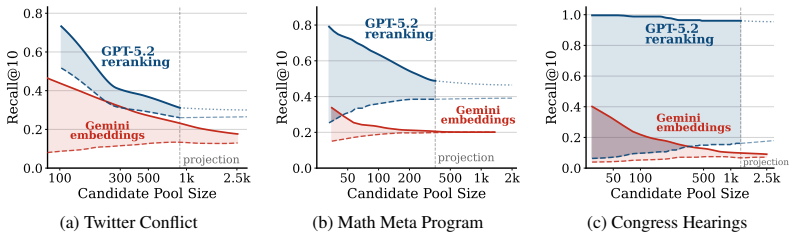
OBLIQ-Bench exposes an overlooked asymmetry between retrieval and verification, where reasoning LLMs reliably recognize latent relevance whenever relevant documents are surfaced, but even sophisticated retrieval pipelines fail to surface most relevant documents in the first place.
What carries the argument
OBLIQ-Bench, a suite of five oblique search problems over real long-tail corpora that studies three mechanisms through which obliqueness arises.
If this is right
- Retrieval architectures must be redesigned to capture latent patterns and implicit signals instead of surface-level matches.
- Existing saturated benchmarks do not reflect the performance gap on queries involving obliqueness.
- Verification models can serve as oracles for evaluating retrieval on latent relevance once documents are retrieved.
- New training objectives or indexing methods are needed to surface documents that instantiate abstract scenarios.
Where Pith is reading between the lines
- Hybrid pipelines that let a verification LLM rerank or guide an initial retriever could close part of the observed gap.
- The same asymmetry may appear in domains such as legal discovery or scientific literature search where relevance is often implicit.
- If the gap persists across larger models and corpora, entirely new retrieval paradigms beyond current dense and sparse methods will be required.
Load-bearing premise
The five oblique search problems and three mechanisms of obliqueness represent real-world latent and implicit query needs that current retrievers systematically miss.
What would settle it
A fresh collection of oblique queries drawn from the same long-tail corpora where top retrievers achieve recall rates comparable to the verification accuracy of reasoning LLMs.
Figures



read the original abstract
Retrieval benchmarks are increasingly saturating, but we argue that efficient search is far from a solved problem. We identify a class of queries we call oblique, which seek documents that instantiate a latent pattern, like finding all tweets that express an implicit stance, chat logs that demonstrate a particular failure mode, or transcripts that match an abstract scenario. We study three mechanisms through which obliqueness may arise and introduce OBLIQ-Bench, a suite of five oblique search problems over real long-tail corpora. OBLIQ-Bench exposes an overlooked asymmetry between retrieval and verification, where reasoning LLMs reliably recognize latent relevance whenever relevant documents are surfaced, but even sophisticated retrieval pipelines fail to surface most relevant documents in the first place. We hope that OBLIQ-Bench will drive research into retrieval architectures that efficiently capture latent patterns and implicit signals in large corpora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that retrieval benchmarks are saturating while efficient search remains unsolved. It defines 'oblique' queries as those seeking documents that instantiate latent patterns or implicit signals (e.g., stance in tweets, failure modes in chat logs). It identifies three mechanisms of obliqueness, constructs OBLIQ-Bench as five concrete search problems over real long-tail corpora, and reports an asymmetry: reasoning LLMs reliably verify latent relevance once documents are surfaced, yet even advanced retrieval pipelines fail to surface most relevant documents.
Significance. If the constructed problems prove representative of a non-trivial class of real-world queries, the work would usefully highlight a gap between verification and surfacing capabilities, potentially motivating new retrieval architectures that better capture implicit signals. The choice of long-tail corpora and the empirical demonstration of LLM verification success versus retriever failure are concrete strengths that could be built upon.
major comments (1)
- [§3–4] Section describing the five oblique problems and three mechanisms (likely §3–4): the central claim that OBLIQ-Bench exposes an 'overlooked bottleneck' in modern retrievers requires that these problems instantiate a class of queries that current systems systematically miss in practice. No quantitative comparison to real query logs, deployed-system failure analyses, or user studies is provided to establish that the observed asymmetry accounts for a meaningful fraction of missed relevant documents rather than edge cases of the construction process.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the clear identification of the need to better substantiate the practical relevance of the oblique query class. We respond to the single major comment below.
read point-by-point responses
-
Referee: [§3–4] Section describing the five oblique problems and three mechanisms (likely §3–4): the central claim that OBLIQ-Bench exposes an 'overlooked bottleneck' in modern retrievers requires that these problems instantiate a class of queries that current systems systematically miss in practice. No quantitative comparison to real query logs, deployed-system failure analyses, or user studies is provided to establish that the observed asymmetry accounts for a meaningful fraction of missed relevant documents rather than edge cases of the construction process.
Authors: We agree that a direct quantitative comparison against large-scale query logs or user studies would strengthen claims about prevalence. Our manuscript instead demonstrates a consistent retrieval-verification asymmetry across five tasks constructed from real long-tail corpora and motivated by three general mechanisms of obliqueness (latent patterns, implicit signals, and abstract scenario matching). These tasks reflect documented practical challenges (e.g., stance detection in social media, failure-mode identification in conversational data) that appear in the IR and NLP literature. The empirical results show that even strong retrievers surface only a small fraction of relevant documents while reasoning LLMs verify relevance reliably once documents are provided. We maintain that this constitutes evidence of an overlooked bottleneck for the defined class, even without prevalence statistics. In revision we will add an explicit limitations subsection discussing construction rationale, scope, and the absence of log-based frequency analysis, while softening language around the term 'bottleneck' to 'demonstrated challenge for this query class.' revision: partial
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential reductions.
full rationale
The paper constructs five oblique search problems over long-tail corpora and reports empirical retrieval vs. LLM verification results. No equations, fitted parameters, predictions from inputs, or self-citation chains are present in the provided text. The asymmetry claim is an observation on the newly defined benchmark rather than a derivation that reduces to its own inputs by construction. The representativeness concern is a validity issue, not circularity per the enumerated patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Can Language Models Actually Retrieve In-Context? Drowning in Documents at Million Token Scale
A 0.6B LM with length-aware attention adjustments performs competitive in-context retrieval at million-token scale on MS MARCO, NQ, and LIMIT benchmarks.
Reference graph
Works this paper leans on
-
[1]
Tip of the Tongue Known-Item Retrieval: A Case Study in Movie Identification. In Proceedings of the 2021 Conference on Human Information Interaction and Retrieval(Canberra ACT, Australia)(CHIIR ’21). Association for Computing Machinery, New York, NY , USA, 5–14. doi:10.1145/3406522.3446021 Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, ...
-
[2]
HoVer: A Dataset for Many-Hop Fact Extraction And Claim Verification. InFindings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. InProceedings of ...
-
[3]
5521–5533. Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023a. Query Rewriting in Retrieval-Augmented Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 5303–5315. doi: 10.186...
-
[4]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR). Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 Embed- ding: Advancing Text Embedding and Reranking Through Foundati...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Write ONE retrieval query (10-15 words) that a researcher would use to find tweets expressing this stance
-
[6]
The query must capture the ABSTRACT stance, not surface content
-
[7]
The query must NOT use words from the tweets verbatim
-
[8]
The query must NOT use named entities (people, places, organizations)
-
[9]
id": "<id>
Grade each tweet’s relevance: 2 = directly expresses this stance, 1 = tangentially related User:Theme: [canonical theme] Member tweets: [all tweets in cluster with implicit meanings] D.1.4 Stage 5: Pool and Expand Top results from each retriever are judged to expand relevance annotations. Pooled Relevance Judgment (Twitter) System:You are judging relevanc...
-
[10]
Find conversations where the AI
Write one NEW retrieval query a researcher might use to find these conversations • Natural phrasing: “Find conversations where the AI...” • Must capture the ABSTRACT failure pattern, not surface content • Must NOT use words from the descriptions verbatim • Must be discriminative: specific enough to exclude unrelated failures • Must NOT overlap with any ex...
-
[11]
Dropping a near-duplicate is correct
If you produced a query, grade each conversation’s relevance (2 = central, 1 = tangential) If you cannot write a query that is clearly distinct from all existing queries, set query to null. Dropping a near-duplicate is correct. User:FAILURE TYPE: [canonical label] CONVERSATIONS: [member conversations with descriptions] EXISTING QUERIES: [current benchmark...
-
[12]
The user’s instruction matches the type of constraint described in the query
-
[13]
The AI’s response violates that constraint in the specific way the query describes
-
[14]
aha moment
A reasonable person would agree the failure is the same, not merely analogous Additional guidelines: • A candidate can be relevant even if the deviation appears unintentional or minor—what matters is whether the output differs from the exact specification • When instructions contain errors, judge against what the user actually specified A candidate is NOT...
-
[15]
Focus on distinctive stylistic features, vocabulary patterns, or thematic preferences
-
[16]
Capture the author’s unique voice and writing mannerisms
-
[17]
For later hops, refine based on patterns you’ve discovered
Be different from previous search angles to maximize coverage If this is the first hop, focus on the most distinctive stylistic markers. For later hops, refine based on patterns you’ve discovered. User:ORIGINAL TEXT: [query snippet] NOTES FROM PREVIOUS HOPS: [accumulated observations] HOP NUMBER: [N] of [total] Multi-Hop Note Extraction (Authorship) Syste...
-
[18]
Select text snippets that appear to be written by the SAME AUTHOR as the query
-
[19]
candidate_ids
Write brief notes about the stylistic patterns you observed Look for: vocabulary choices, sentence structure, punctuation habits, thematic preferences, tone, rhetorical devices, and other authorial fingerprints. User:QUERY TEXT: [snippet] PREVIOUS NOTES: [observations] CANDIDATES: [retrieved snippets] Return:{"candidate_ids": [...], "notes": "...", "summa...
-
[20]
RATE the passage’s memorability (1-5): • 1 = boring procedural, nobody would remember • 2 = mildly interesting but generic • 3 = somewhat memorable, has a specific detail worth recalling • 4 = very memorable, a distinct confrontation or revelation • 5 = iconic, widely reported moment
-
[21]
I’m not sure
If memorability ≥ 3, write a ToT POST( ∼200 words, written as someone posting on Reddit trying to recall this moment): MUST FOLLOW: • Do NOT include names of any person, company, platform, committee, or legislation • Do NOT include dates, years, or exact identifiers • Reflect imperfect memory: mix up minor details, be uncertain about specifics, conflate w...
-
[22]
This has been driving me crazy
Frustrated question (“This has been driving me crazy...”)
-
[23]
Ok so there was this hearing where
Mid-thought, no preamble (“Ok so there was this hearing where...”)
-
[24]
I was at my desk / on the couch
Setting a scene (“I was at my desk / on the couch...”)
-
[25]
It was kind of like that other time when
A comparison (“It was kind of like that other time when...”)
-
[26]
Does anyone else remember
Challenge to the reader (“Does anyone else remember...”)
-
[27]
The thing that always stuck with me was
Stating what stuck (“The thing that always stuck with me was...”)
-
[28]
There’s this clip where
Diving straight in (“There’s this clip where...”)
-
[29]
A couple years back, maybe around election season
Temporal anchoring (“A couple years back, maybe around election season...”)
-
[30]
My coworker mentioned something today
Explaining why you’re posting (“My coworker mentioned something today...”)
-
[31]
I still get secondhand embarrassment
Emotional reaction first (“I still get secondhand embarrassment...”)
-
[32]
I might be mixing up two different things here but
A disclaimer (“I might be mixing up two different things here but...”)
-
[33]
Someone sent me a clip once of
Referring to how you saw it (“Someone sent me a clip once of...”)
-
[34]
Honestly one of the wildest moments
Strong opinion opener (“Honestly one of the wildest moments...”)
-
[35]
Why can I never find this clip again?
A question to yourself (“Why can I never find this clip again?”)
-
[36]
So right around the time that scandal
Anchoring to another memory (“So right around the time that scandal...”) D.5.3 Evaluation: Query Rewriting ToT Query Rewriting for Transcript Matching System:You are an advanced retrieval system. You will be given a tip of tongue query describing a user’s hazy memory of a specific moment from a US congressional hearing. They wrote a vague description of w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.