Machine Unlearning for Masked Diffusion Language Models
Pith reviewed 2026-05-20 10:21 UTC · model grok-4.3
The pith
Masked diffusion unlearning removes targeted knowledge by minimizing forward KL divergence to a prompt-masked unconditional anchor at masked positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
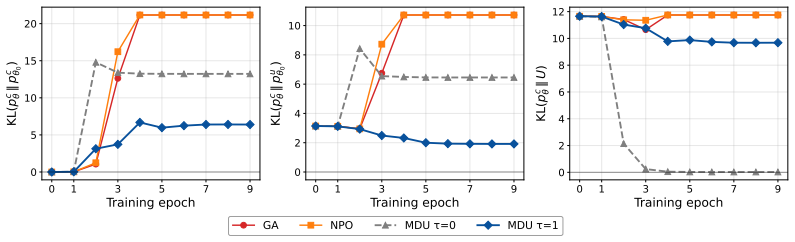
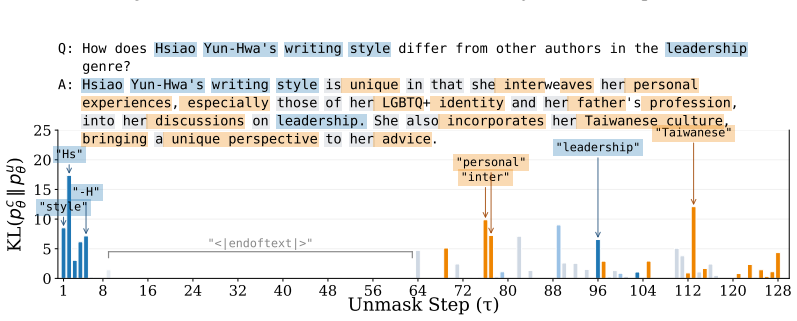
MDU minimizes a forward KL divergence from the prompt-conditional prediction to a prompt-masked unconditional anchor at every masked response position, with a temperature scaling parameter to control the privacy-utility trade-off, and empirical results on standard benchmarks and MDLM backbones show high unlearning performance compared to existing LLM unlearning methods.
What carries the argument
Minimizing forward KL divergence from prompt-conditional predictions to a prompt-masked unconditional anchor at masked response positions, with temperature scaling to adjust the privacy-utility trade-off.
If this is right
- MDU achieves higher unlearning performance than existing LLM unlearning methods on standard benchmarks.
- The framework applies directly to MDLM backbones such as LLaDA and Dream.
- Temperature scaling provides explicit control over the trade-off between forgetting targeted data and retaining overall model performance.
- Unlearning occurs by reversing the diffusion fine-tuning shift at masked positions without requiring changes to the core generative process.
Where Pith is reading between the lines
- The same divergence-minimization idea could be tested on diffusion models used for non-language data such as images or audio sequences.
- Repeated unlearning sessions on the same model might accumulate effects that gradually reduce overall generation quality, which could be checked in follow-up experiments.
- This mechanism might connect to unlearning needs in other parallel generative architectures where conditioning shifts predictions away from an unconditional baseline.
Load-bearing premise
That minimizing the forward KL divergence to the prompt-masked unconditional anchor at masked positions will remove targeted knowledge without substantially harming the model's general capabilities or introducing new unintended behaviors.
What would settle it
Measuring whether the model still generates the specific unlearned content when given the original prompts after MDU is applied.
Figures





read the original abstract
Recent masked diffusion language models (MDLMs), such as LLaDA and Dream, have achieved performance comparable to autoregressive large language models. Unlike autoregressive models, which generate text sequentially, MDLMs generate text by iteratively denoising masked positions in parallel. During fine-tuning, MDLMs learn to recover responses from masked response states conditioned on a prompt, thereby shifting their predictions from a prompt-masked unconditional distribution toward a prompt-conditional distribution. Despite this distinct generative and fine-tuning mechanism, machine unlearning for MDLMs remains largely unexplored. In this paper, we propose Masked Diffusion Unlearning (MDU), the first unlearning framework for MDLMs, by revisiting the process of learning specific knowledge in terms of diffusion. Specifically, MDU minimizes a forward KL divergence from the prompt-conditional prediction to a prompt-masked unconditional anchor at every masked response position, with a temperature scaling parameter to control the privacy-utility trade-off. Our empirical results on standard benchmarks and MDLM backbones show that MDU achieves high unlearning performance compared to existing LLM unlearning methods. Code is available at https://github.com/leegeoru/MDU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Masked Diffusion Unlearning (MDU) as the first unlearning method for masked diffusion language models (MDLMs). It reverses the fine-tuning shift by minimizing forward KL divergence from the prompt-conditional distribution to a prompt-masked unconditional anchor at masked response positions, controlled by a temperature scaling parameter. Experiments on standard benchmarks with MDLM backbones (e.g., LLaDA, Dream) report that MDU achieves higher unlearning performance than adapted existing LLM unlearning baselines.
Significance. If the empirical results hold under rigorous controls, this work is significant for addressing machine unlearning in non-autoregressive diffusion-based LLMs, a gap left by prior methods focused on autoregressive models. The mechanistic grounding in the diffusion denoising process and the public code release are strengths that support reproducibility and potential adoption.
major comments (2)
- [§4 Experiments] §4 Experiments: the central claim of superior unlearning performance relative to LLM baselines is only partially supported because the manuscript provides no details on exact metrics (e.g., forget rate, retain accuracy), statistical significance testing, number of runs, or how autoregressive unlearning methods were adapted to the parallel denoising setting of MDLMs.
- [§3.2 Method] §3.2 Method: the assumption that the prompt-masked unconditional anchor serves as a faithful forgetting target without residual leakage through the iterative denoising steps is load-bearing for the efficacy claim, yet the paper does not provide ablation or analysis showing that the KL minimization fully propagates the unlearning signal across denoising timesteps.
minor comments (2)
- [Abstract] The abstract and introduction refer to 'standard benchmarks' without naming them (e.g., TOXICITY, TRUTHFULQA, or specific unlearning suites); explicit listing would improve clarity.
- [§3.2] The temperature scaling parameter is described as controlling the privacy-utility trade-off, but no sensitivity analysis or default selection procedure is reported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate additional details and analysis where appropriate.
read point-by-point responses
-
Referee: [§4 Experiments] §4 Experiments: the central claim of superior unlearning performance relative to LLM baselines is only partially supported because the manuscript provides no details on exact metrics (e.g., forget rate, retain accuracy), statistical significance testing, number of runs, or how autoregressive unlearning methods were adapted to the parallel denoising setting of MDLMs.
Authors: We agree that these experimental details should be explicit. In the revised manuscript we will add: precise metric definitions (forget rate as the drop in accuracy on the forget set relative to the original model; retain accuracy as performance on the retain set); results reported as means and standard deviations over 5 independent runs with paired t-test p-values for significance; and a new paragraph in §4.1 explaining the adaptation procedure, in which autoregressive baselines are applied independently at each denoising timestep while respecting the parallel mask prediction structure of MDLMs. revision: yes
-
Referee: [§3.2 Method] §3.2 Method: the assumption that the prompt-masked unconditional anchor serves as a faithful forgetting target without residual leakage through the iterative denoising steps is load-bearing for the efficacy claim, yet the paper does not provide ablation or analysis showing that the KL minimization fully propagates the unlearning signal across denoising timesteps.
Authors: The concern is well-taken. Because the forward KL term is minimized at every masked position and every timestep, the unlearning signal is enforced throughout the chain of denoising steps; changes at early timesteps necessarily influence later conditional predictions. Nevertheless, we will add a targeted ablation in the revision that varies the timesteps at which MDU is applied and reports the resulting forget/retain metrics, thereby providing direct evidence that the effect propagates without substantial residual leakage. revision: partial
Circularity Check
No significant circularity
full rationale
The paper defines Masked Diffusion Unlearning (MDU) directly as minimization of forward KL divergence from the prompt-conditional distribution to the prompt-masked unconditional anchor at masked positions, with an explicit temperature scaling parameter. This construction is a mechanistic reversal of the described MDLM fine-tuning shift and is evaluated on external standard benchmarks against adapted LLM baselines. No equations reduce the claimed unlearning performance to a fitted quantity by construction, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is smuggled in. The derivation chain is therefore self-contained against the stated inputs and external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature scaling parameter
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MDU minimizes a forward KL divergence from the prompt-conditional prediction to a prompt-masked unconditional anchor at every masked response position, with a temperature scaling parameter
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
work page 2024
-
[2]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Towards making systems forget with machine unlearning
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In 2015 IEEE symposium on security and privacy, pages 463–480. IEEE, 2015
work page 2015
-
[5]
Eternal sunshine of the spotless net: Selective forgetting in deep networks
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9304–9312, 2020
work page 2020
-
[6]
Yuanshun Yao and Xiaojun Xu. Large language model unlearning.Advances in Neural Information Processing Systems, 37:105425–105475, 2024
work page 2024
-
[7]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning.arXiv preprint arXiv:2404.05868, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Yuanhe Zhang, Fangzhou Xie, Zhenhong Zhou, Zherui Li, Hao Chen, Kun Wang, and Yufei Guo. Jailbreaking large language diffusion models: Revealing hidden safety flaws in diffusion-based text generation.arXiv preprint arXiv:2507.19227, 2025
-
[9]
Zherui Li, Zheng Nie, Zhenhong Zhou, Yue Liu, Yitong Zhang, Yu Cheng, Qingsong Wen, Kun Wang, Yufei Guo, and Jiaheng Zhang. Diffuguard: How intrinsic safety is lost and found in diffusion large language models.arXiv preprint arXiv:2509.24296, 2025
-
[10]
Wonje Jeung, Sangyeon Yoon, Yoonjun Cho, Dongjae Jeon, Sangwoo Shin, Hyesoo Hong, and Albert No. A2d: Any-order, any-step safety alignment for diffusion language models.arXiv preprint arXiv:2509.23286, 2025
-
[11]
TOFU: A Task of Fictitious Unlearning for LLMs
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, Jun Zhao, et al. Rwku: Benchmarking real-world knowledge unlearning for large language models.Advances in Neural Information Processing Systems, 37:98213–98263, 2024
work page 2024
-
[13]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
work page 2015
-
[14]
Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions.Advances in neural infor- mation processing systems, 34:12454–12465, 2021
work page 2021
-
[15]
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
work page 2021
-
[16]
Andrew Campbell, Joe Benton, Valentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models.Advances in Neural Information Processing Systems, 35:28266–28279, 2022
work page 2022
-
[17]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
work page 2024
-
[19]
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the worst, plan for the best: Understanding token ordering in masked diffusions.arXiv preprint arXiv:2502.06768, 2025
-
[20]
Learning fair representa- tions
Rich Zemel, Yu Wu, Kevin Swersky, Toni Pitassi, and Cynthia Dwork. Learning fair representa- tions. InInternational conference on machine learning, pages 325–333. PMLR, 2013
work page 2013
-
[21]
Learning to unlearn: Instance-wise unlearning for pre-trained classifiers
Sungmin Cha, Sungjun Cho, Dasol Hwang, Honglak Lee, Taesup Moon, and Moontae Lee. Learning to unlearn: Instance-wise unlearning for pre-trained classifiers. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 11186–11194, 2024
work page 2024
-
[22]
Meghdad Kurmanji, Peter Triantafillou, Jamie Hayes, and Eleni Triantafillou. Towards un- bounded machine unlearning.Advances in neural information processing systems, 36:1957– 1987, 2023
work page 1957
-
[23]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation.arXiv preprint arXiv:2310.12508, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
The wmdp benchmark: measuring and reducing malicious use with unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, et al. The wmdp benchmark: measuring and reducing malicious use with unlearning. InProceedings of the 41st International Conference on Machine Learning, pages 28525–28550, 2024
work page 2024
-
[25]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2426–2436, 2023
work page 2023
-
[26]
Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, and Sijia Liu. Defensive unlearning with adversarial training for robust concept erasure in diffusion models.Advances in neural information processing systems, 37: 36748–36776, 2024
work page 2024
-
[27]
Koushik Srivatsan, Fahad Shamshad, Muzammal Naseer, Vishal M Patel, and Karthik Nandaku- mar. Stereo: A two-stage framework for adversarially robust concept erasing from text-to-image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23765–23774, 2025
work page 2025
-
[28]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023
work page 2023
-
[29]
Ddat: Diffusion policies enforcing dynamically admissible robot trajectories
Jean-Baptiste Bouvier, Kanghyun Ryu, Kartik Nagpal, Qiayuan Liao, Koushil Sreenath, and Negar Mehr. Ddat: Diffusion policies enforcing dynamically admissible robot trajectories. arXiv preprint arXiv:2502.15043, 2025
-
[30]
George Stoica, Vivek Ramanujan, Xiang Fan, Ali Farhadi, Ranjay Krishna, and Judy Hoffman. Contrastive flow matching. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1185–1194, 2025
work page 2025
-
[31]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[32]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Scaling up masked diffusion models on text
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. Scaling up masked diffusion models on text. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=WNvvwK0tut. 11
work page 2025
-
[34]
Detecting, explaining, and mitigating memorization in diffusion models
Yuxin Wen, Yuchen Liu, Chen Chen, and Lingjuan Lyu. Detecting, explaining, and mitigating memorization in diffusion models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[35]
Dongjae Jeon, Dueun Kim, and Albert No. Understanding and mitigating memorization in generative models via sharpness of probability landscapes.Proceedings of Machine Learning Research, 267:27091–27112, 2025
work page 2025
-
[36]
Classifier-free guidance inside the attraction basin may cause memorization
Anubhav Jain, Yuya Kobayashi, Takashi Shibuya, Yuhta Takida, Nasir Memon, Julian Togelius, and Yuki Mitsufuji. Classifier-free guidance inside the attraction basin may cause memorization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12871–12879, 2025
work page 2025
-
[37]
A closer look at machine unlearning for large language models.arXiv preprint arXiv:2410.08109, 2024
Xiaojian Yuan, Tianyu Pang, Chao Du, Kejiang Chen, Weiming Zhang, and Min Lin. A closer look at machine unlearning for large language models.arXiv preprint arXiv:2410.08109, 2024
-
[38]
Diffusion language model knows the answer before it decodes
Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Yi Liang, Soroush V osoughi, and Shiwei Liu. Diffusion language model knows the answer before it decodes. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=g88nt4ieTG
work page 2026
-
[39]
Knowledge unlearning for mitigating privacy risks in language models
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14389–14408, 2023
work page 2023
-
[40]
Chongyu Fan, Jiancheng Liu, Licong Lin, Jinghan Jia, Ruiqi Zhang, Song Mei, and Sijia Liu. Simplicity prevails: Rethinking negative preference optimization for llm unlearning.arXiv preprint arXiv:2410.07163, 2024
-
[41]
P., Zhou, Z., Shin, S., Han, B., and Weinberger, K
Qizhou Wang, Jin Peng Zhou, Zhanke Zhou, Saebyeol Shin, Bo Han, and Kilian Q Weinberger. Rethinking llm unlearning objectives: A gradient perspective and go beyond.arXiv preprint arXiv:2502.19301, 2025
-
[42]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023. 12 A MDU Algorithm Algorithm 1MDU optimization step Require: Trainable MDLM θ with init parameters θ0...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.