AnySimLite: A Lightweight Few-Shot Similarity Encoder for On-Device Speech-Adjacent Classification
Pith reviewed 2026-06-26 01:09 UTC · model grok-4.3
The pith
A single lightweight similarity encoder handles multiple speech-adjacent classification tasks in few-shot settings by recasting them as text similarity problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AnySimLite, a lightweight similarity encoder that combines word-level and character-level channels together with a dataset transformation strategy, enables a single model to achieve state-of-the-art or competitive performance across multiple speech-adjacent classification tasks in few-shot settings while using less than 1/250th the size of the qLLaMA_LoRA-7B baseline and limiting the worst-case performance drop to below 7 percent.
What carries the argument
AnySimLite: a lightweight similarity encoder combining word-level and character-level channels, used with a dataset transformation that recasts classification labels as similarity pairs.
If this is right
- Multiple speech-adjacent tasks can share one model instead of requiring separate specialized models.
- On-device deployment becomes feasible for several tasks while respecting tight memory limits on phones.
- Privacy improves because inference stays local without sending data to larger cloud models.
- Few-shot performance remains usable even when the model size is reduced by more than two orders of magnitude.
Where Pith is reading between the lines
- The similarity reformulation could apply to additional classification problems that are not speech-adjacent.
- A single encoder might support rapid addition of new tasks on device without retraining from scratch.
- Memory savings could allow more headroom for other on-device features running alongside the classifier.
Load-bearing premise
The dataset transformation successfully converts each classification task into a similarity problem without discarding task-specific information that would be needed for accurate few-shot decisions.
What would settle it
A new speech-adjacent classification task where the similarity reformulation produces accuracy more than 7 percent below the large-model baseline in few-shot evaluation.
Figures


read the original abstract
To minimize privacy concerns and inference latency on edge devices like smartphones, lightweight on-device models remain important for end-user applications. Many of these applications involve natural language classification, but deploying multiple specialized models creates a memory footprint challenge. We investigate: Can a single lightweight architecture solve multiple Speech-Adjacent (SA) classification tasks through reduction to a nuanced text similarity formulation? We propose AnySimLite, a lightweight similarity encoder that combines word-level and character-level channels. Together with a dataset transformation strategy, we evaluate AnySimLite across multiple SA classification tasks and show that it consistently achieves state-of-the-art (SOTA) or SOTA-competitive performance in few-shot settings while maintaining a low memory footprint. Even in the worst case, the performance drop remains below 7% while using $<\frac{1}{250}^{\mathrm{th}}$ of the model size of the SOTA qLLaMA_LoRA-7B baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AnySimLite, a lightweight similarity encoder that combines word-level and character-level channels. Together with a dataset transformation strategy, the model reduces multiple Speech-Adjacent (SA) classification tasks to a nuanced text similarity formulation. It claims to achieve SOTA or SOTA-competitive performance in few-shot settings across these tasks while using less than 1/250th the model size of the qLLaMA_LoRA-7B baseline, with worst-case performance drop below 7%.
Significance. If the experimental claims hold with proper validation, the result would be significant for on-device NLP: a single small model could handle diverse classification tasks with low memory and latency, addressing privacy and deployment constraints on edge devices. The reduction of classification to similarity is a potentially reusable idea for few-shot regimes.
major comments (2)
- [Abstract] Abstract: The central performance claims (SOTA-competitive results, <7% drop, <1/250 model size vs. qLLaMA_LoRA-7B) are stated without any experimental protocol, baseline implementation details, number of shots, statistical significance tests, or error bars. This renders the primary empirical claim unevaluable from the manuscript text.
- [Abstract and §3] Dataset transformation strategy (Abstract and §3): The claim that the transformation converts each SA task into a similarity problem while preserving all information needed for accurate few-shot decisions is load-bearing for the <7% drop result. No mechanics, pair-construction rules, labeling procedure, or ablation on information loss are supplied, leaving open whether overlapping or context-dependent categories are collapsed.
minor comments (1)
- [Abstract] The size-comparison notation $<\frac{1}{250}^{\mathrm{th}}$ is typographically awkward and should be rewritten for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and agree that expansions are warranted for clarity and evaluability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (SOTA-competitive results, <7% drop, <1/250 model size vs. qLLaMA_LoRA-7B) are stated without any experimental protocol, baseline implementation details, number of shots, statistical significance tests, or error bars. This renders the primary empirical claim unevaluable from the manuscript text.
Authors: We agree the abstract is too terse. In revision we will add one sentence noting the 5-shot and 10-shot regimes, that all results are means over five random seeds with standard deviations, and that the qLLaMA_LoRA-7B baseline follows the standard LoRA fine-tuning protocol described in Section 4. Full protocol, significance tests, and error bars remain in Section 4 and Table 2; the abstract change will make the headline claims directly evaluable. revision: yes
-
Referee: [Abstract and §3] Dataset transformation strategy (Abstract and §3): The claim that the transformation converts each SA task into a similarity problem while preserving all information needed for accurate few-shot decisions is load-bearing for the <7% drop result. No mechanics, pair-construction rules, labeling procedure, or ablation on information loss are supplied, leaving open whether overlapping or context-dependent categories are collapsed.
Authors: We acknowledge that the current description in §3 is high-level and lacks the requested specifics. We will expand §3.2 to state the pair-construction rules (one positive pair per input with its gold label text; negatives formed by pairing with uniformly sampled incorrect labels), the labeling procedure (binary 1.0/0.0 similarity targets), and add an appendix ablation that measures accuracy drop on tasks with overlapping categories before versus after transformation. This will directly substantiate the information-preservation claim. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external evaluation
full rationale
The paper's central claim is an empirical one: a lightweight dual-channel similarity encoder plus a (described but not mathematically derived) dataset transformation reduces multiple SA classification tasks to few-shot similarity while retaining competitive accuracy at <1/250th the size of a 7B baseline. No equations, fitted parameters presented as predictions, self-definitional loops, or load-bearing self-citations appear in the provided abstract or description. The transformation strategy is presented as a methodological choice whose success is measured by downstream accuracy, which remains externally falsifiable and does not reduce to its own inputs by construction. This is the normal non-circular case for an applied modeling paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction On-device models are essential in inference pipelines on edge devices for obvious benefits in terms of network latency, data privacy, and overall low carbon footprint at data centers. These models should have low latency and low resource requirements (storage, memory, power). Modern smartphones contain mul- tiple models as part of SDK runtime...
Pith/arXiv arXiv 2026
-
[2]
Event Title Sim- ilarity
Preliminaries 2.1. Problem Formulation In text similarity problem, the aim is to model the similarity between two text documents to a quantifiable score. Mathemat- ically, the goal is to formulate a modelf, such that two text doc- uments,d 1 andd 2, are said to be more similar, compared tod 3 andd 4, if and only iff(d 1, d2)> f(d 3, d4). This implies that...
-
[3]
explored to solve the toy problem, and thereby, to act as foundation for lightweight on-device NTS
Architecture for NTS We describe configs. explored to solve the toy problem, and thereby, to act as foundation for lightweight on-device NTS. 3.1. As binary classification By concatenating the two titles together, a single string is pro- duced that can be tokenized and fed to the model architecture. Here, a training dataset for supervised learning is to b...
-
[4]
too dissimilar
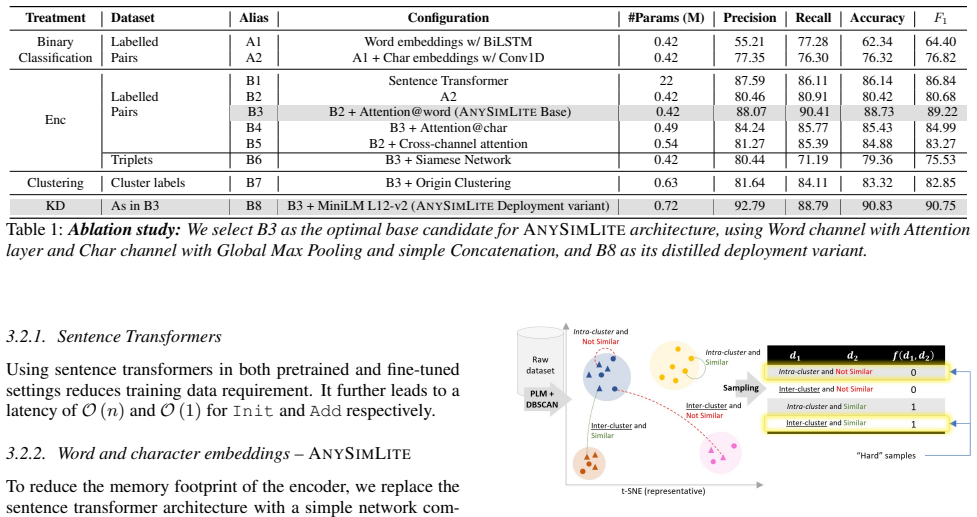
Datasets and Transformation Recall from Section 2.1 thatRdenotes a subset of tasks that are reducible to NTS. Once we have a foundation architecture for NTS in the form of ANYSIMLITE, the next step is to devise a strategy to convert one of these tasksGto its NTS-reduced form, G′. In this section, we introduce a few of such tasks inRalong with their public...
-
[5]
too dissimilar
This is to ensure that a significant portion of the dissimilar samples are not“too dissimilar”(their belonging to the same cluster implies shared factors notwithstanding the nuance spe- cific to the problem statement). For our experiments, this ratio is 8:2. 4.2. Selected problem statements∈R We select diverse NLP classification tasks and their correspond...
2019
-
[6]
Experimental Results We conduct all training and experiments on an NVIDIA RTX A6000 GPU with 48 GB memory. 5.1. Ablation Study To support the dual goal of ANYSIMLITEarchitecture to be lightweight along with being versatile, we evaluate performance metric impact due to each component. For this purpose, we use TitleSimCurated dataset. From Table 1, we note ...
-
[7]
Conclusion We explore the hypothesis that a lightweight architecture based on word+char channels can solve NLP classifications via task reduction. Our ANYSIMLITEachieves SOTA or SOTA- competitive performance, with an average accuracy degradation of only2.24%±3.23%(sample standard deviation) relative to the best reported result, on diverse problem statemen...
-
[8]
Generative AI Use Disclosure Apart from explicit description in the paper, usage of generative AI tools is limited to permitted re-formatting of tables
-
[9]
Natural language understanding with the quora question pairs dataset,
L. Sharma, L. Graesser, N. Nangia, and U. Evci, “Natural language understanding with the quora question pairs dataset,”
-
[10]
Available: https://arxiv.org/abs/1907.01041
[Online]. Available: https://arxiv.org/abs/1907.01041
Pith/arXiv arXiv 1907
-
[11]
Building siamese attention-augmented recurrent convolutional neural networks for document similarity scoring,
S. Han, L. Shi, R. Richie, and F. R. Tsui, “Building siamese attention-augmented recurrent convolutional neural networks for document similarity scoring,”IS, vol. 615, pp. 90–102, 2022
2022
-
[12]
Question pairs dataset,
“Question pairs dataset,” https://www.kaggle.com/datasets/quora/ question-pairs-dataset/, accessed: 2025-09-01
2025
-
[13]
Enhancing semantical text under- standing with fine-tuned large language models: A case study on quora question pair duplicate identification,
S. Han, L. Shi, and F. Tsui, “Enhancing semantical text under- standing with fine-tuned large language models: A case study on quora question pair duplicate identification,”PloS one, vol. 20, no. 1, p. e0317042, 2025
2025
-
[14]
Roberta-bilstm: A context-aware hybrid model for sentiment analysis,
M. M. Rahman, A. I. Shiplu, Y . Watanobe, and M. A. Alam, “Roberta-bilstm: A context-aware hybrid model for sentiment analysis,”IEEE Transactions on Emerging Topics in Computa- tional Intelligence, 2025
2025
-
[15]
Twitter sentiment classifica- tion using distant supervision,
A. Go, R. Bhayani, and L. Huang, “Twitter sentiment classifica- tion using distant supervision,”CS224N project report, Stanford, vol. 1, no. 12, p. 2009, 2009
2009
-
[16]
Sentiment analysis of cop9-related tweets: a comparative study of pre-trained models and traditional techniques,
S. Elmitwalli and J. Mehegan, “Sentiment analysis of cop9-related tweets: a comparative study of pre-trained models and traditional techniques,”Frontiers in big Data, vol. 7, p. 1357926, 2024
2024
-
[17]
Learning word vectors for sentiment analysis,
A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y . Ng, and C. Potts, “Learning word vectors for sentiment analysis,” inACL-HLT. Portland, Oregon, USA: Association for Computational Linguistics, June 2011, pp. 142–150. [Online]. Available: http://www.aclweb.org/anthology/P11-1015
2011
-
[18]
Y . Guo, Z. Xie, X. Chen, H. Chen, L. Wang, H. Du, S. Wei, Y . Zhao, Q. Li, and G. Wu, “Esie-bert: Enriching sub-words information explicitly with bert for joint intent classification and slotfilling,” 2023. [Online]. Available: https: //arxiv.org/abs/2211.14829
arXiv 2023
-
[19]
A. Coucke, A. Saade, A. Ball, T. Bluche, A. Caulier, D. Leroy, C. Doumouro, T. Gisselbrecht, F. Caltagirone, T. Lavril, M. Primet, and J. Dureau, “Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces,” 2018. [Online]. Available: https://arxiv.org/abs/1805.10190
Pith/arXiv arXiv 2018
-
[20]
Lidsnet: A lightweight on-device intent detection model using deep siamese network,
V . Agarwal, S. D. Shivnikar, S. Ghosh, H. Arora, and Y . Saini, “Lidsnet: A lightweight on-device intent detection model using deep siamese network,” in2021 20th IEEE International Confer- ence on Machine Learning and Applications (ICMLA), 2021, pp. 1112–1117
2021
-
[21]
Evaluation of spoken language systems: the ATIS domain,
P. J. Price, “Evaluation of spoken language systems: the ATIS domain,” inSpeech and Natural Language: Proceedings of a Workshop Held at Hidden Valley, Pennsylvania, June 24-27,1990,
1990
-
[22]
Available: https://aclanthology.org/H90-1020/
[Online]. Available: https://aclanthology.org/H90-1020/
-
[23]
Sms spam detection using bert and multi-graph convolutional networks,
L. Shen, Y . Wang, Z. Li, and W. Ma, “Sms spam detection using bert and multi-graph convolutional networks,”International Journal of Intelligent Networks, vol. 6, pp. 79–88, 2025. [On- line]. Available: https://www.sciencedirect.com/science/article/ pii/S2666603025000089
2025
-
[24]
T. Almeida and J. Hidalgo, “SMS Spam Collec- tion,” UCI Machine Learning Repository, 2011, DOI: https://doi.org/10.24432/C5CC84
-
[25]
A spam transformer model for sms spam detection,
X. Liu, H. Lu, and A. Nayak, “A spam transformer model for sms spam detection,”IEEE Access, vol. 9, pp. 80 253–80 263, 2021
2021
-
[26]
Performance-guided llm knowledge distillation for efficient text classification at scale,
F. D. Palo, P. Singhi, and B. Fadlallah, “Performance-guided llm knowledge distillation for efficient text classification at scale,”
-
[27]
Available: https://arxiv.org/abs/2411.05045
[Online]. Available: https://arxiv.org/abs/2411.05045
-
[28]
Character-level convolu- tional networks for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level convolu- tional networks for text classification,” inNeurIPS, C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, Eds., vol. 28. Curran Associates, Inc., 2015. [Online]. Avail- able: https://proceedings.neurips.cc/paper files/paper/2015/file/ 250cf8b51c773f3f8dc8b4be867a9a02-Paper.pdf
2015
-
[29]
Xlnet: Generalized autoregressive pretraining for language understanding,
Z. Yang, Z. Dai, Y . Yang, J. Carbonell, R. Salakhutdinov, and Q. V . Le, “Xlnet: Generalized autoregressive pretraining for language understanding,” 2019. [Online]. Available: https: //arxiv.org/abs/1906.08237v1
Pith/arXiv arXiv 2019
-
[30]
Paying atten- tion to toxic comments online,
M. Kohli, E. Kuehler, and J. Palowitch, “Paying atten- tion to toxic comments online,”Web: https://web. stanford. edu/class/archive/cs/cs224n/cs224n, vol. 1184, 2018
2018
-
[31]
Toxic comment clas- sification challenge,
cjadams, J. Sorensen, J. Elliott, L. Dixon, M. McDon- ald, nithum, and W. Cukierski, “Toxic comment clas- sification challenge,” https://kaggle.com/competitions/ jigsaw-toxic-comment-classification-challenge, 2017, kag- gle
2017
-
[32]
A machine learning approach to comment tox- icity classification,
N. Chakrabarty, “A machine learning approach to comment tox- icity classification,” inComputational Intelligence in Pattern Recognition: Proceedings of CIPR 2019. Springer, 2019, pp. 183–193
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.