Skill-Guided Continuation Distillation for GUI Agents
Pith reviewed 2026-06-26 21:08 UTC · model grok-4.3
The pith
Skill-guided continuation distillation closes the supervision gap for GUI agents by generating successful trajectories from off-trajectory states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
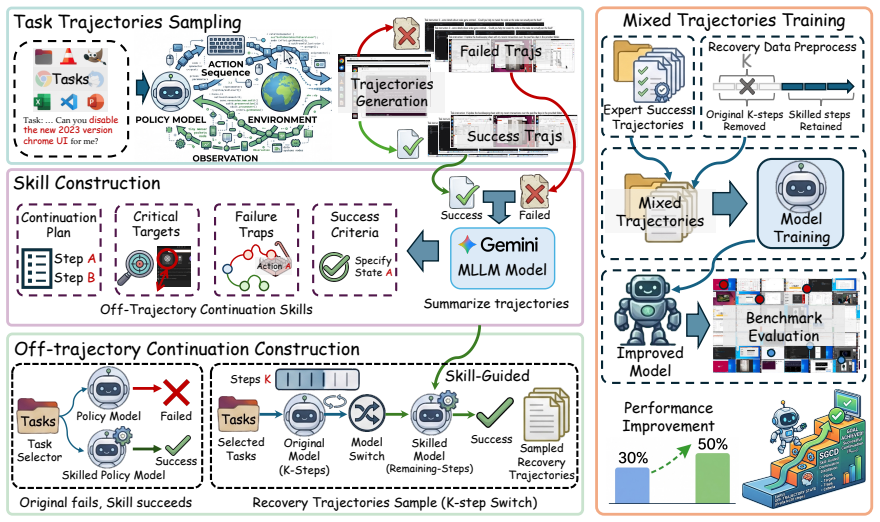
SGCD first runs the plain policy for a few steps to reach realistic policy-induced off-trajectory states. From those states a skill-guided policy then completes the task, producing successful continuations that are combined with expert trajectories to supply supervision over previously unseen states. Skills extracted from rollouts consist of Continuation Plans, Critical Targets, Failure Traps, and Success Criteria.
What carries the argument
Skill-Guided Continuation Distillation, an iterative self-improvement loop that mixes skill-guided completions from off-trajectory states with expert trajectories.
If this is right
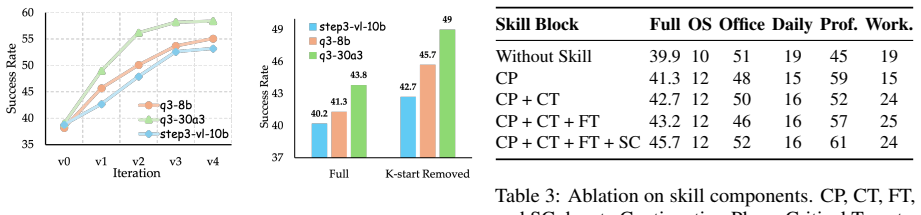
- Success rates on OSWorld-Verified rise from the low-30 percent range to over 50 percent across three base models.
- The policy receives effective supervision on states that expert trajectories alone cannot cover.
- Self-improvement occurs iteratively without requiring new expert demonstrations.
- Skills extracted from rollouts enable the policy to avoid failure traps and meet success criteria.
Where Pith is reading between the lines
- The same continuation-distillation pattern could reduce dependence on expert data in other imitation-learning domains that suffer distribution shift.
- Extracted skills might transfer across tasks or models if stored separately from the policy weights.
- The approach suggests a general recipe for turning execution failures into training signals whenever a stronger guided policy is available.
Load-bearing premise
The skill-guided policy can reliably produce successful continuations from the off-trajectory states reached by the plain policy.
What would settle it
Applying SGCD to the three base models on OSWorld-Verified and measuring no increase in success rate above the original low-30 percent range would show the method does not close the supervision gap.
Figures






read the original abstract
Improving GUI agents typically relies on behavior cloning on expert trajectories. However, as the current policy deviates from the expert policy, it inevitably encounters policy-induced off-trajectory states during closed-loop execution, i.e., states that fall outside the expert trajectories. Since expert trajectories provide no demonstrations for these unseen states, such states receive no effective supervision, leaving the policy unable to select the correct action. To close this supervision gap, we propose Skill-Guided Continuation Distillation (SGCD), an iterative self-improvement framework. SGCD first runs the plain policy without skill guidance for a few steps to reach realistic off-trajectory states. From these states, a skill-guided policy then completes the task and produces successful continuations, which are mixed with expert trajectories to supply supervision over policy-induced off-trajectory states. The skills are extracted from both successful and failed rollouts, consisting of Continuation Plans, Critical Targets, Failure Traps, and Success Criteria. On OSWorld-Verified, SGCD improves the success rate of three base models from the low-30\% range to over 50\%, demonstrating its effectiveness and generality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Skill-Guided Continuation Distillation (SGCD), an iterative self-improvement framework for GUI agents. It rolls out the current policy for a few steps to induce realistic off-trajectory states, extracts skills (Continuation Plans, Critical Targets, Failure Traps, Success Criteria) from prior successful and failed rollouts, uses a skill-guided policy to generate successful continuations from those states, and mixes the resulting trajectories with expert data to provide supervision for policy-induced states. The central empirical claim is that SGCD raises success rates on OSWorld-Verified from the low-30% range to over 50% across three base models.
Significance. If the results and ablations hold, the work addresses a practically important supervision gap in closed-loop GUI agent execution and offers a concrete mechanism for leveraging both successes and failures to generate corrective data. The explicit extraction of structured skills from rollouts is a clear methodological contribution that could generalize beyond the reported setting.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: The reported improvement (low-30% to >50% on OSWorld-Verified) is stated without any description of the base models, number of evaluation runs, statistical tests, or comparison against standard behavior-cloning or self-improvement baselines, preventing assessment of whether the gain is attributable to SGCD.
- [Method / Experiments] Method (iterative loop description) and Experiments: No quantitative results are supplied showing that the skill-guided policy achieves higher task-completion rates than the plain policy when started from the specific off-trajectory states reached by rolling out the plain policy. Without this measurement, it is impossible to confirm that the mixed trajectories supply corrective supervision rather than redundant or noisy data.
- [Experiments] Ablation studies: The manuscript provides no ablation that isolates the contribution of the skill-guided continuations versus other factors (e.g., simply increasing the amount of expert data or using random continuations), which is required to substantiate the claim that the skill-extraction mechanism is load-bearing for the observed gains.
minor comments (2)
- [Method] The four skill categories (Continuation Plans, Critical Targets, Failure Traps, Success Criteria) are introduced narratively; formalizing their extraction and representation with pseudocode or a short algorithm box would improve reproducibility.
- [Figures / Tables] Figure captions and table headers should explicitly state the evaluation metric (success rate) and the exact OSWorld-Verified split used.
Simulated Author's Rebuttal
Thank you for the constructive review and the recommendation for major revision. We appreciate the emphasis on providing clearer experimental details, direct measurements of the skill-guided policy's effectiveness on off-trajectory states, and targeted ablations. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results and evidence.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The reported improvement (low-30% to >50% on OSWorld-Verified) is stated without any description of the base models, number of evaluation runs, statistical tests, or comparison against standard behavior-cloning or self-improvement baselines, preventing assessment of whether the gain is attributable to SGCD.
Authors: We agree that additional details are required for full assessment. In the revised manuscript we will name the three base models, specify the number of evaluation runs (with error bars), report any statistical tests performed, and include direct comparisons against behavior cloning on expert trajectories as well as other self-improvement baselines such as iterative fine-tuning without skill guidance. These additions will clarify that the observed gains are attributable to SGCD. revision: yes
-
Referee: [Method / Experiments] Method (iterative loop description) and Experiments: No quantitative results are supplied showing that the skill-guided policy achieves higher task-completion rates than the plain policy when started from the specific off-trajectory states reached by rolling out the plain policy. Without this measurement, it is impossible to confirm that the mixed trajectories supply corrective supervision rather than redundant or noisy data.
Authors: This observation is correct; the current manuscript does not include a direct head-to-head evaluation of the skill-guided versus plain policy on the exact off-trajectory states induced by the plain policy. In the revision we will add a targeted experiment that collects such states, evaluates both policies from those states, and reports the resulting task-completion rates. This will provide direct evidence that the skill-guided continuations supply corrective rather than redundant supervision. revision: yes
-
Referee: [Experiments] Ablation studies: The manuscript provides no ablation that isolates the contribution of the skill-guided continuations versus other factors (e.g., simply increasing the amount of expert data or using random continuations), which is required to substantiate the claim that the skill-extraction mechanism is load-bearing for the observed gains.
Authors: We acknowledge that the manuscript lacks ablations isolating the skill-guided mechanism from volume or randomness effects. The revised version will include new ablation experiments that (i) match the volume of added trajectories using only expert data, (ii) replace skill-guided continuations with random or unguided ones, and (iii) ablate individual extracted skills. These results will demonstrate the load-bearing role of the skill-extraction and guidance components. revision: yes
Circularity Check
No circularity: empirical method with external benchmark validation
full rationale
The paper describes an iterative procedure for generating corrective trajectories via skill-guided continuation from off-trajectory states reached by the base policy, then mixing them with expert data for distillation. The central result is an empirical success-rate lift on the external OSWorld-Verified benchmark. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The derivation chain is self-contained against the benchmark and does not reduce the reported gains to a tautology by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert trajectories provide no demonstrations for policy-induced off-trajectory states
invented entities (1)
-
Continuation Plans, Critical Targets, Failure Traps, Success Criteria
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2024 , month = oct, howpublished =
Introducing Computer Use, a New Claude 3.5 Sonnet, and Claude 3.5 Haiku , author =. 2024 , month = oct, howpublished =
2024
-
[9]
2024 , howpublished =
Computer Use Tool , author =. 2024 , howpublished =
2024
-
[10]
Advances in Neural Information Processing Systems , volume=
Mind2web: Towards a generalist agent for the web , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
International Conference on Learning Representations , volume=
Webarena: A realistic web environment for building autonomous agents , author=. International Conference on Learning Representations , volume=
-
[12]
arXiv preprint arXiv:2401.01614 , year=
Gpt-4v (ision) is a generalist web agent, if grounded , author=. arXiv preprint arXiv:2401.01614 , year=
-
[13]
International Conference on Learning Representations , volume=
Androidworld: A dynamic benchmarking environment for autonomous agents , author=. International Conference on Learning Representations , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:2508.15144 , year=
Mobile-agent-v3: Fundamental agents for gui automation , author=. arXiv preprint arXiv:2508.15144 , year=
-
[16]
5: Multi-platform fundamental gui agents , author=
Mobile-agent-v3. 5: Multi-platform fundamental gui agents , author=. arXiv preprint arXiv:2602.16855 , year=
-
[17]
2025 , month = nov, howpublished =
2025
-
[18]
Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=
A reduction of imitation learning and structured prediction to no-regret online learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
2011
-
[19]
International Conference on Learning Representations , volume=
On-policy distillation of language models: Learning from self-generated mistakes , author=. International Conference on Learning Representations , volume=
-
[20]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[21]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[22]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[23]
International Conference on Learning Representations , volume=
Agent s: An open agentic framework that uses computers like a human , author=. International Conference on Learning Representations , volume=
-
[24]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Gui-reflection: Empowering multimodal gui models with self-reflection behavior , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
2025 , month = nov, howpublished =
A New Era of Intelligence with. 2025 , month = nov, howpublished =
2025
-
[27]
2026 , month = mar, howpublished =
Introducing. 2026 , month = mar, howpublished =
2026
-
[28]
arXiv preprint arXiv:2501.12326 , year=
Ui-tars: Pioneering automated gui interaction with native agents , author=. arXiv preprint arXiv:2501.12326 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Opencua: Open foundations for computer-use agents , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:2512.15431 , year=
Step-gui technical report , author=. arXiv preprint arXiv:2512.15431 , year=
-
[31]
arXiv preprint arXiv:2601.15876 , year=
Evocua: Evolving computer use agents via learning from scalable synthetic experience , author=. arXiv preprint arXiv:2601.15876 , year=
-
[32]
arXiv preprint arXiv:2605.07505 , year=
LiteGUI: Distilling Compact GUI Agents with Reinforcement Learning , author=. arXiv preprint arXiv:2605.07505 , year=
-
[33]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Screenspot-pro: Gui grounding for professional high-resolution computer use , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[34]
Advances in Neural Information Processing Systems , volume=
Scaling computer-use grounding via user interface decomposition and synthesis , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Visual test-time scaling for gui agent grounding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[36]
Advances in Neural Information Processing Systems , volume=
Gui-g1: Understanding r1-zero-like training for visual grounding in gui agents , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2507.22025 , year=
Ui-agile: Advancing gui agents with effective reinforcement learning and precise inference-time grounding , author=. arXiv preprint arXiv:2507.22025 , year=
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
GUI-G ^2 : Gaussian Reward Modeling for GUI Grounding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
2026 , month = oct, howpublished =
Introducing Claude Sonnet 4.6 , author =. 2026 , month = oct, howpublished =
2026
-
[40]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[41]
International Conference on Learning Representations , volume=
Learn-by-interact: A data-centric framework for self-adaptive agents in realistic environments , author=. International Conference on Learning Representations , volume=
-
[42]
International Conference on Learning Representations , volume=
Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials , author=. International Conference on Learning Representations , volume=
-
[43]
arXiv preprint arXiv:2508.14040 , year=
Computerrl: Scaling end-to-end online reinforcement learning for computer use agents , author=. arXiv preprint arXiv:2508.14040 , year=
-
[44]
arXiv preprint arXiv:2512.14895 , year=
Imitation Learning for Multi-turn LM Agents via On-policy Expert Corrections , author=. arXiv preprint arXiv:2512.14895 , year=
-
[45]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Seeclick: Harnessing gui grounding for advanced visual gui agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
International Conference on Learning Representations , volume=
Navigating the digital world as humans do: Universal visual grounding for gui agents , author=. International Conference on Learning Representations , volume=
-
[47]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Showui: One vision-language-action model for gui visual agent , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[48]
Advances in Neural Information Processing Systems , volume=
Look before you leap: A gui-critic-r1 model for pre-operative error diagnosis in gui automation , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
arXiv preprint arXiv:2504.08942 , year=
Agentrewardbench: Evaluating automatic evaluations of web agent trajectories , author=. arXiv preprint arXiv:2504.08942 , year=
-
[50]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[51]
arXiv preprint arXiv:2505.20023 , year=
Training LLM-Based Agents with Synthetic Self-Reflected Trajectories and Partial Masking , author=. arXiv preprint arXiv:2505.20023 , year=
-
[53]
arXiv preprint arXiv:2509.17336 , year=
Mano Technical Report , author=. arXiv preprint arXiv:2509.17336 , year=
-
[54]
arXiv preprint arXiv:2504.00906 , year=
Agent s2: A compositional generalist-specialist framework for computer use agents , author=. arXiv preprint arXiv:2504.00906 , year=
-
[55]
arXiv preprint arXiv:2510.02250 , year=
The unreasonable effectiveness of scaling agents for computer use , author=. arXiv preprint arXiv:2510.02250 , year=
-
[56]
arXiv preprint arXiv:2510.03853 , year=
Uground: Towards unified visual grounding with unrolled transformers , author=. arXiv preprint arXiv:2510.03853 , year=
-
[57]
arXiv preprint arXiv:2505.11821 , year=
Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment , author=. arXiv preprint arXiv:2505.11821 , year=
-
[58]
The Fourteenth International Conference on Learning Representations , year=
Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn Search Agents , author=. The Fourteenth International Conference on Learning Representations , year=
-
[59]
arXiv preprint arXiv:2603.24533 , year=
Ui-voyager: A self-evolving gui agent learning via failed experience , author=. arXiv preprint arXiv:2603.24533 , year=
-
[60]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Swift: a scalable lightweight infrastructure for fine-tuning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[61]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[62]
International Conference on Learning Representations , volume=
OS-ATLAS: Foundation action model for generalist GUI agents , author=. International Conference on Learning Representations , volume=
-
[63]
arXiv preprint arXiv:2503.23434 , year=
Towards trustworthy gui agents: A survey , author=. arXiv preprint arXiv:2503.23434 , year=
-
[64]
arXiv preprint arXiv:2509.23866 , year=
Efficient Multi-turn RL for GUI Agents via Decoupled Training and Adaptive Data Curation , author=. arXiv preprint arXiv:2509.23866 , year=
-
[65]
5: Visual Agentic Intelligence , author=
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
-
[66]
8 model card: Towards generalized real-world agency , author=
Seed1. 8 model card: Towards generalized real-world agency , author=. arXiv preprint arXiv:2603.20633 , year=
-
[67]
arXiv preprint arXiv:2601.09668 , year=
Step3-vl-10b technical report , author=. arXiv preprint arXiv:2601.09668 , year=
-
[68]
arXiv preprint arXiv:2505.21964 , year=
UI-Evol: Automatic Knowledge Evolving for Computer Use Agents , author=. arXiv preprint arXiv:2505.21964 , year=
-
[69]
arXiv preprint arXiv:2601.05787 , year=
From Off-Policy to On-Policy: Enhancing GUI Agents via Bi-level Expert-to-Policy Assimilation , author=. arXiv preprint arXiv:2601.05787 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.