Scalable and Distributed Silhouette Approximation
Pith reviewed 2026-07-03 04:09 UTC · model grok-4.3
The pith
Sampling estimates local and global silhouette of any metric k-clustering to additive error O(ε) with O(nkε^{-2}ln(nk/δ)) distance computations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For any metric k-clustering the local silhouette of each point and the global silhouette of the clustering can be estimated to within additive error O(ε) by sampling O(nkε^{-2}ln(nk/δ)) distances, with success probability at least 1-δ, for arbitrary ε,δ in (0,1). The same sampling construction yields the first rigorous, controllable approximations; earlier fast methods were heuristics without such guarantees.
What carries the argument
Sampling to estimate the intra-cluster and nearest inter-cluster average distances that enter the silhouette formula for each point.
If this is right
- Both per-point and aggregate silhouette values become computable on datasets too large for quadratic distance matrices.
- The approximation works for arbitrary metric k-clusterings and requires no extra assumptions on data geometry.
- Constant-round distributed implementations exist in MapReduce and MPC with sublinear memory per machine.
- The accuracy-efficiency trade-off is controlled directly by the user-chosen parameters ε and δ.
Where Pith is reading between the lines
- Silhouette-based model selection or validation could be inserted into clustering pipelines on web-scale or streaming data where it was previously ruled out by cost.
- The same sampling idea may apply to other quality measures that depend only on average intra- and inter-cluster distances.
- In practice the method could be combined with existing fast clustering routines to produce both a clustering and a certified quality score in near-linear total work.
Load-bearing premise
Concentration inequalities on the sampled average distances suffice to bound the error on the silhouette terms to O(ε) without further restrictions on the metric or the point distribution.
What would settle it
On any dataset small enough for exact silhouette computation, run the sampling estimator many times with chosen ε and δ and check whether the fraction of trials whose estimates deviate by more than O(ε) exceeds δ.
Figures
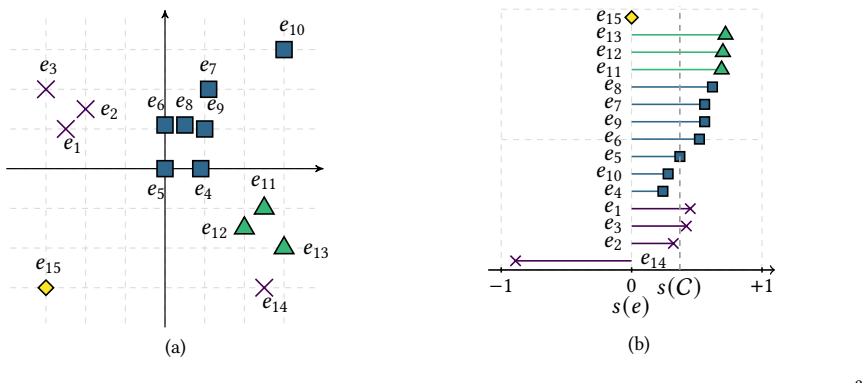
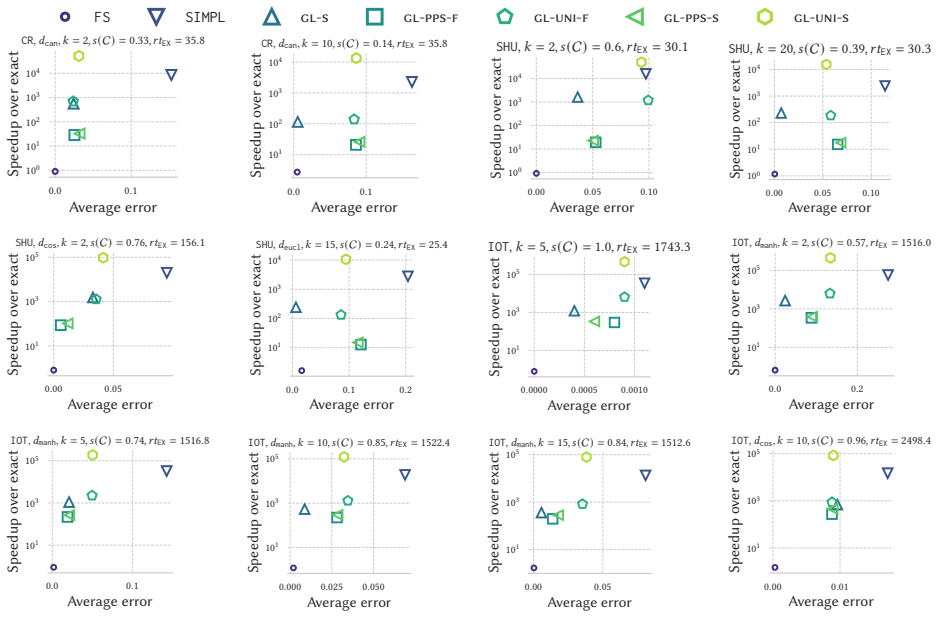
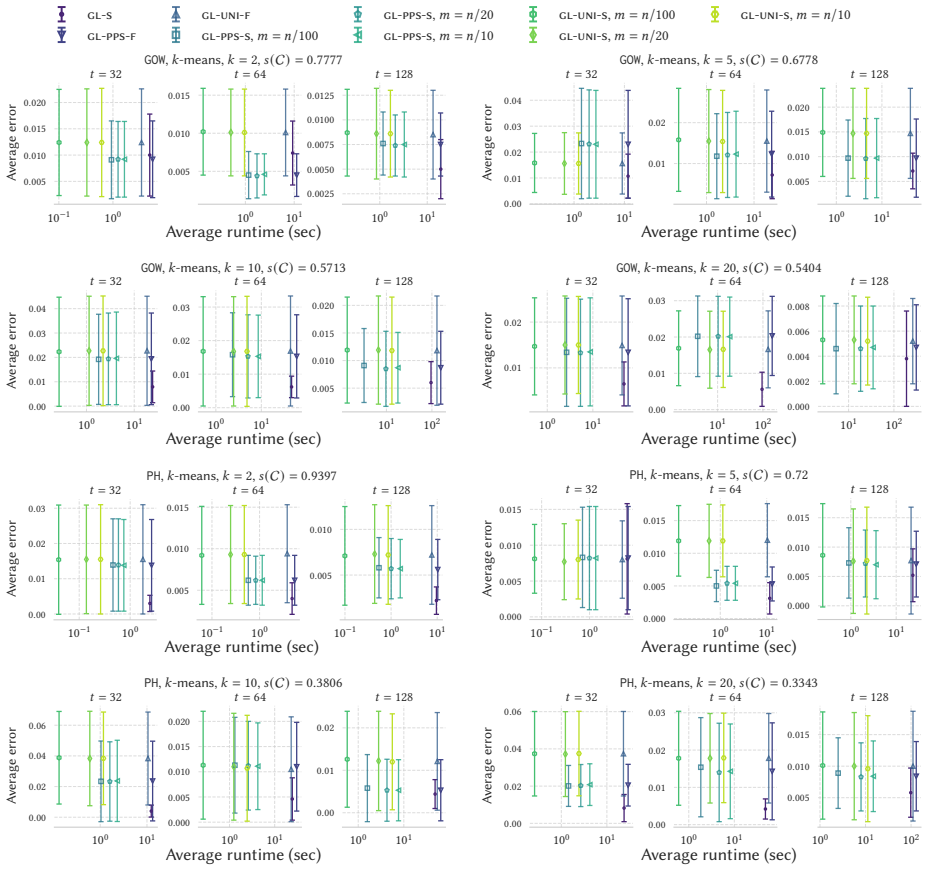
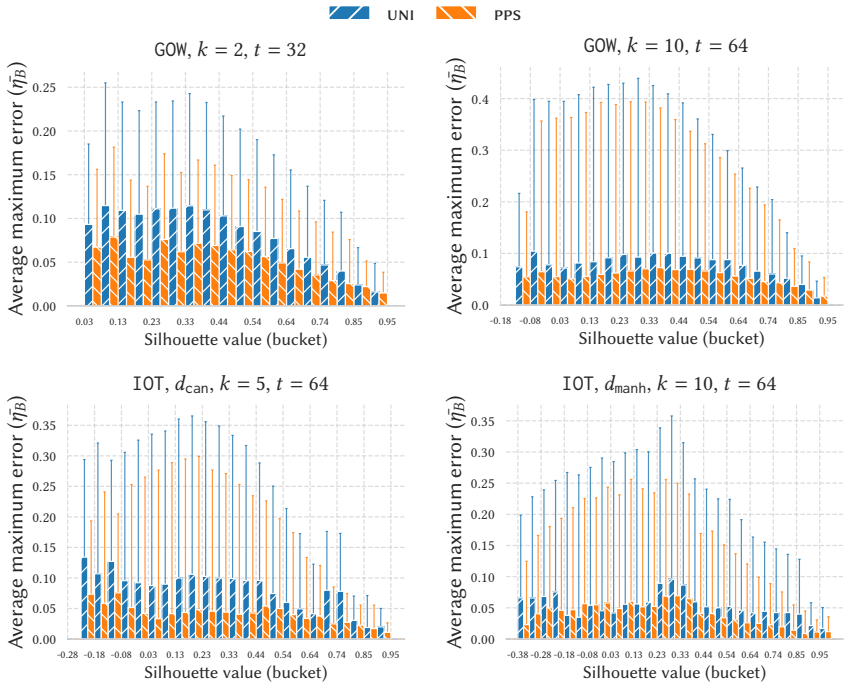
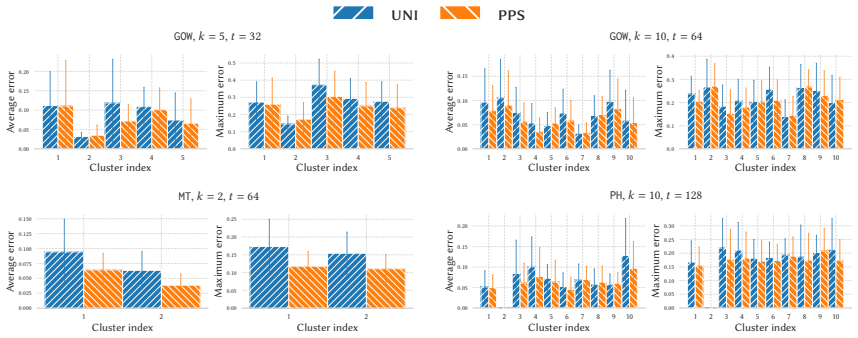
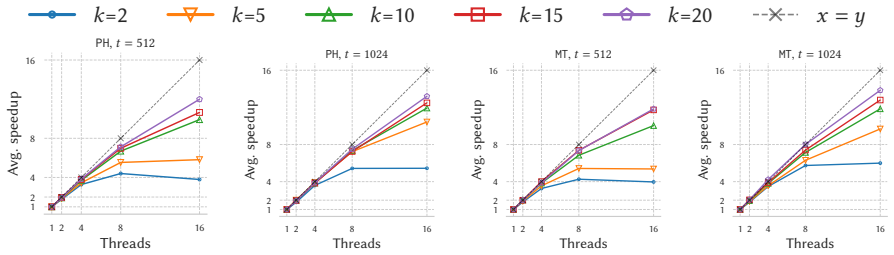
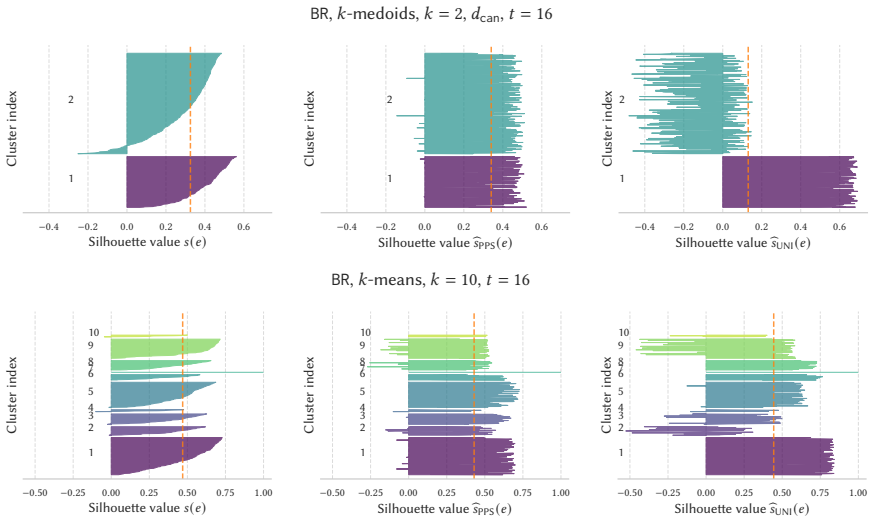
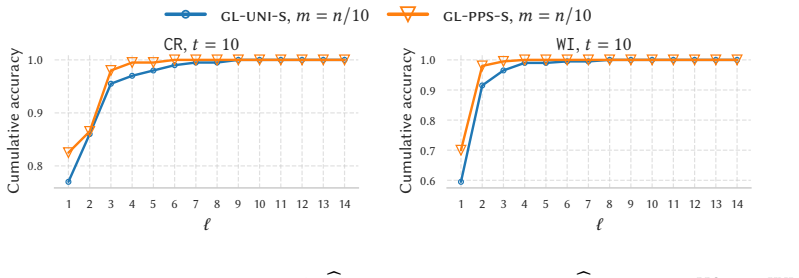
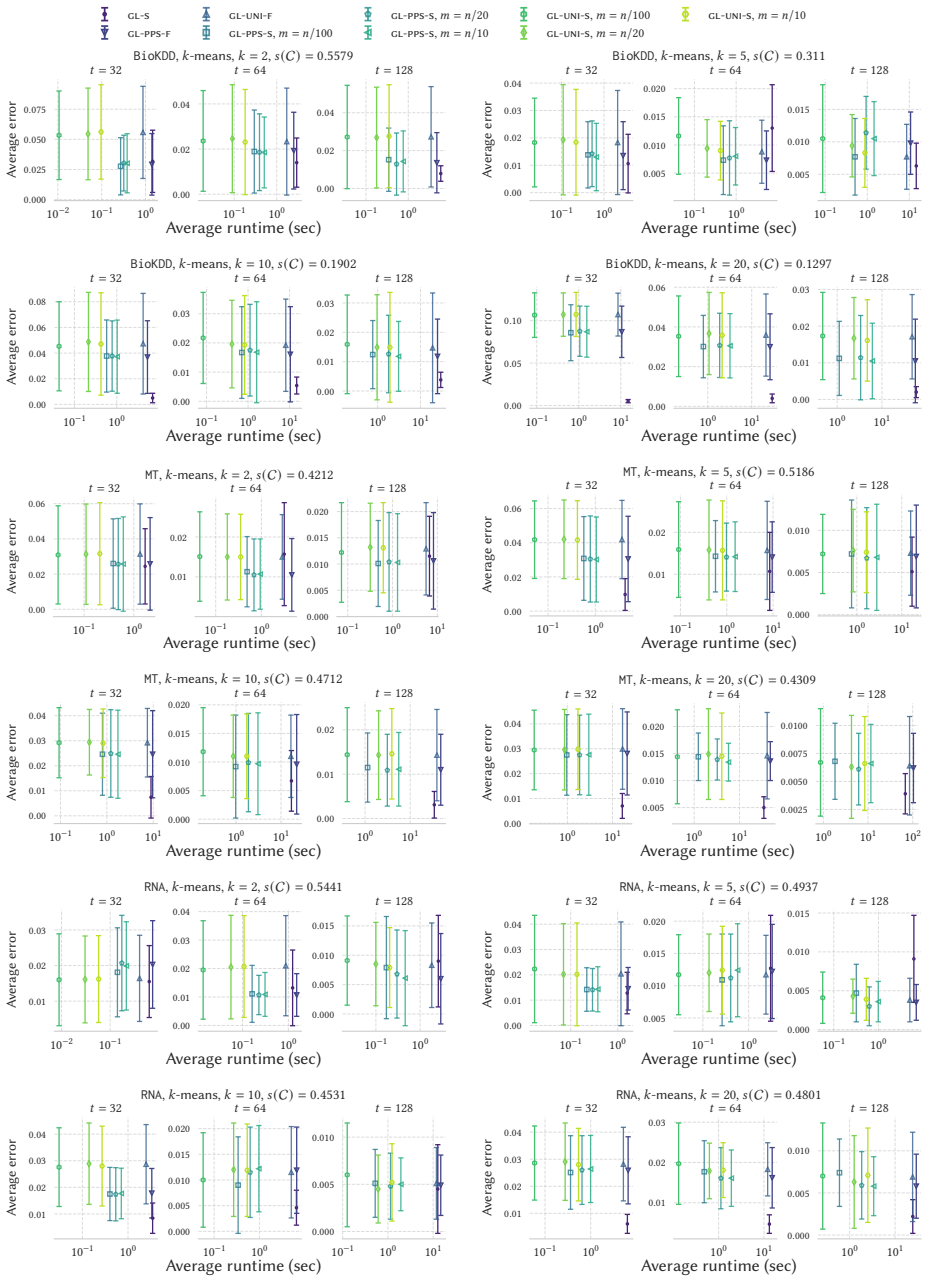
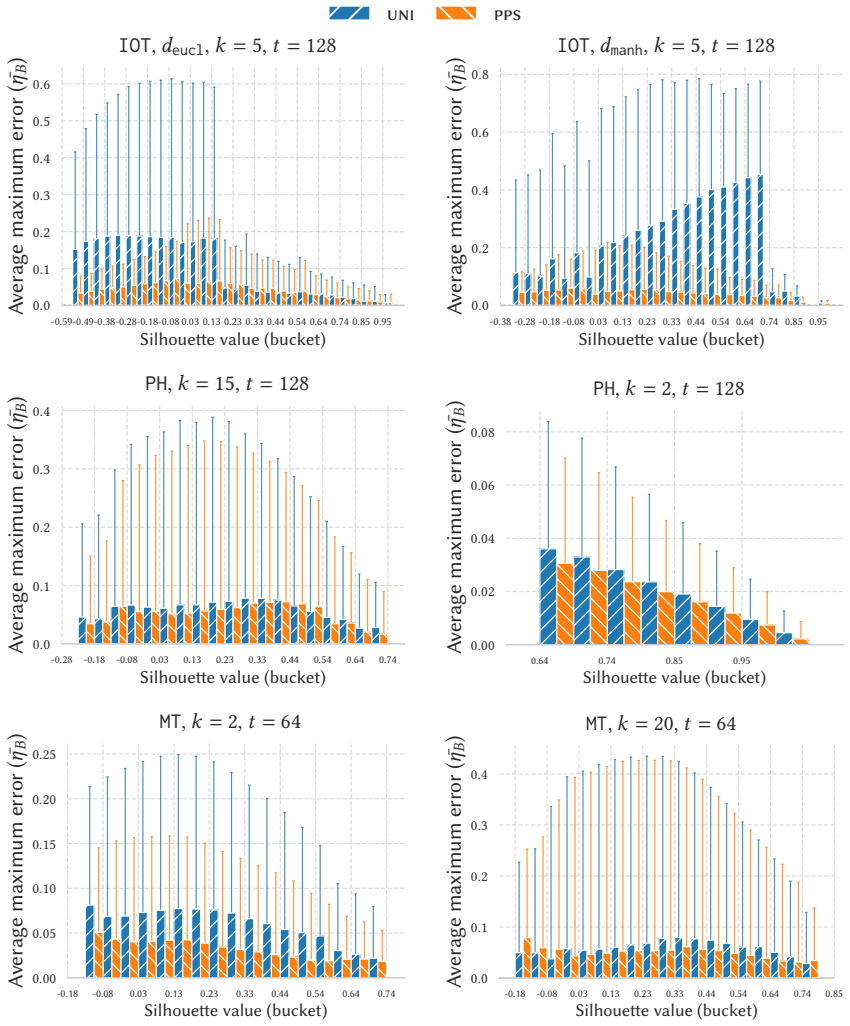
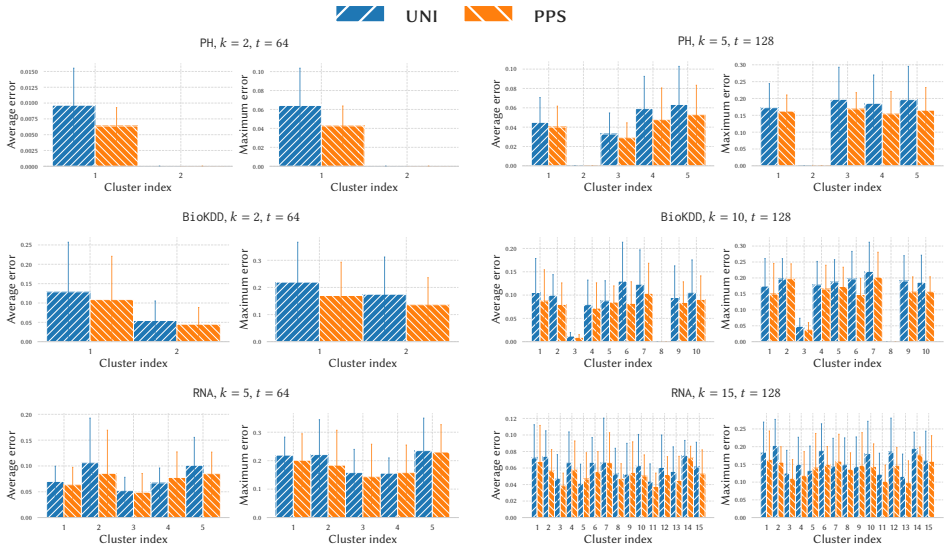
read the original abstract
The silhouette is one of the most widely used measures to assess the quality of a $k$-clustering of a dataset of $n$ elements. Its evaluation requires no information beyond the clustering assignment. In addition, the silhouette is extremely easy to interpret, providing a score to measure the quality of a clustering as a whole or for each element. The exact computation of the: (i) silhouette of each element of a dataset; and (ii) the global silhouette of the clustering; require $\Theta(n^2)$ distance calculations, under general metrics. The quadratic complexity $\Theta(n^2)$ is extremely prohibitive, especially on massive modern datasets. Surprisingly, existing approximate methods using $O(n^2)$ distance calculations are heuristics not offering provable and controllable guarantees on the quality of their results. We introduce the first rigorous and efficient algorithms to estimate: (i) the (local) silhouette of each element of a dataset; and (ii) the (global) silhouette; of any metric $k$-clustering. Our methods, based on sampling, perform $O(nk\varepsilon^{-2}\ln (nk/\delta))$ distance computations, and provide estimates with additive error $O(\varepsilon)$ with probability at least $1-\delta$. That is, parameters $\varepsilon$ and $\delta$ in $(0,1)$ control the trade-off between accuracy and efficiency. We also introduce a scalable and distributed design of our methods for the MapReduce and Massively Parallel Computing (MPC) frameworks. Our distributed algorithms use a constant number of rounds and sublinear local memory. Finally, we perform extensive experiments against state-of-the-art approaches. The results show that our new techniques yield the best trade-off between accuracy and efficiency for both local and global silhouette estimation. In addition, our methods scale efficiently to massive datasets for which an exact computation of the silhouette is not practical.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the first sampling-based algorithms for approximating the local silhouette s(i) of each point and the global silhouette of a metric k-clustering. The algorithms use O(nk ε^{-2} ln(nk/δ)) distance computations to obtain additive O(ε) error with probability ≥1-δ; they are also extended to constant-round MapReduce and MPC distributed models with sublinear local memory. Experiments demonstrate favorable accuracy-efficiency trade-offs versus prior heuristics on large datasets.
Significance. If the stated additive-error guarantees hold, the work supplies the first provably controllable approximation algorithms for silhouette computation, removing the Θ(n²) barrier that has limited its use on massive data. The explicit complexity bound, distributed implementations, and experimental validation constitute a concrete advance for scalable clustering evaluation in theoretical computer science.
major comments (1)
- [Sections presenting the local-silhouette estimator and its error analysis (abstract claim and algorithm introduction)] The central claim of additive O(ε) error on the silhouette values s(i) = (b(i)-a(i))/max(a(i),b(i)) (and on the global average) rests on additive concentration bounds for the averages a(i) and b(i). Because the map (a,b)↦s is not Lipschitz with constant independent of a and b (its gradient diverges as a,b→0), |â-a|≤O(ε) and |b̂-b|≤O(ε) can produce |ŝ-s|=Ω(1) even for arbitrarily small ε. No case analysis for small a(i),b(i), lower-bound assumption, or refined (e.g., multiplicative) analysis appears to close this gap.
Simulated Author's Rebuttal
We thank the referee for the careful and insightful review. The observation regarding error propagation through the silhouette function is a substantive technical point that we address below. We will revise the manuscript to strengthen the analysis.
read point-by-point responses
-
Referee: [Sections presenting the local-silhouette estimator and its error analysis (abstract claim and algorithm introduction)] The central claim of additive O(ε) error on the silhouette values s(i) = (b(i)-a(i))/max(a(i),b(i)) (and on the global average) rests on additive concentration bounds for the averages a(i) and b(i). Because the map (a,b)↦s is not Lipschitz with constant independent of a and b (its gradient diverges as a,b→0), |â-a|≤O(ε) and |b̂-b|≤O(ε) can produce |ŝ-s|=Ω(1) even for arbitrarily small ε. No case analysis for small a(i),b(i), lower-bound assumption, or refined (e.g., multiplicative) analysis appears to close this gap.
Authors: We acknowledge that the referee correctly identifies a gap: the map (a,b) → s(a,b) is not uniformly Lipschitz, so additive O(ε) approximations to a(i) and b(i) do not automatically imply additive O(ε) error in s(i) when a(i) or b(i) are small. The current manuscript provides concentration bounds only for the estimators of a(i) and b(i) and does not contain an explicit case analysis, lower-bound assumption on a(i),b(i), or multiplicative refinement for the silhouette values. We will revise the sections on the local-silhouette estimator and its analysis (and the corresponding global-silhouette claims) to close this gap. The revision will introduce a case distinction: when max(a(i),b(i)) ≥ cε for a suitable constant c, the local Lipschitz constant is bounded and the additive error carries through; when max(a(i),b(i)) = O(ε), we will either (i) output a conservative estimate with an explicit larger error bound or (ii) state that the additive O(ε) guarantee on s(i) holds under the additional assumption that a(i),b(i) = Ω(ε). We believe this addresses the concern without altering the sampling complexity. revision: yes
Circularity Check
No circularity; sampling-based bounds derived independently
full rationale
The paper presents sampling algorithms whose error guarantees rest on standard concentration inequalities applied directly to the definitional averages a(i) and b(i) that enter the silhouette formula. No step reduces the claimed O(ε) additive guarantee on the silhouette values to a fitted parameter, a self-citation chain, or a redefinition of the target quantity; the sampling complexity and probability bounds are obtained from first-principles tail bounds that do not presuppose the final result. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard concentration inequalities (e.g., Hoeffding) apply to the per-point intra- and nearest-cluster average distance estimators used in silhouette.
Reference graph
Works this paper leans on
-
[1]
Fully Scalable
Artur Czumaj and Guichen Gao and Mohsen Ghaffari and Shaofeng H. Fully Scalable. Proceedings of the 52nd International Colloquium on Automata, Languages, and Programming,
-
[2]
Dubhashi and Alessandro Panconesi , title =
Devdatt P. Dubhashi and Alessandro Panconesi , title =. 2009 , isbn =
2009
-
[3]
Proceedings of the Eighteenth Annual
David Arthur and Sergei Vassilvitskii , title =. Proceedings of the Eighteenth Annual
-
[4]
Journal of Open Source Software , volume=
Fast k-medoids Clustering in Rust and Python , author=. Journal of Open Source Software , volume=
-
[5]
Periodica Polytechnica Civil Engineering , volume=
Upper bound of density for packing of equal circles in special domains in the plane , author=. Periodica Polytechnica Civil Engineering , volume=
-
[6]
Java-ML: A Machine Learning Library , year =
Thomas Abeel and Yves Van de Peer and Yvan Saeys , journal =. Java-ML: A Machine Learning Library , year =
-
[7]
Data Clustering , year =
-
[8]
2013 , doi =
Awasthi Pranjal and Maria Florina Balcan , title =. 2013 , doi =
2013
-
[9]
Bahman Bahmani and Benjamin Moseley and Andrea Vattani and Ravi Kumar and Sergei Vassilvitskii , journal =. Scalable k-means++ , year =. doi:10.14778/2180912.2180915 , publisher =
-
[10]
Distributed k-Means and k-Median Clustering on General Topologies , year =
Maria Florina Balcan and Steven Ehrlich and Yingyu Liang , journal =. Distributed k-Means and k-Median Clustering on General Topologies , year =
-
[11]
k-Means for Streaming and Distributed Big Sparse Data , year =
Artem Barger and Dan Feldman , booktitle =. k-Means for Streaming and Distributed Big Sparse Data , year =
-
[12]
Paul Beame and Paraschos Koutris and Dan Suciu , title =. J
-
[13]
Clustering uncertain graphs , year =
Matteo Ceccarello and Carlo Fantozzi and Andrea Pietracaprina and Geppino Pucci and Fabio Vandin , journal =. Clustering uncertain graphs , year =. doi:10.1145/3186728.3164143 , publisher =
-
[14]
Solving k-center clustering (with outliers) in
Matteo Ceccarello and Andrea Pietracaprina and Geppino Pucci , journal =. Solving k-center clustering (with outliers) in. 2019 , month =. doi:10.14778/3317315.3317319 , publisher =
-
[15]
Average Distance Queries through Weighted Samples in Graphs and Metric Spaces: High Scalability with Tight Statistical Guarantees , year =
Shiri Chechik and Edith Cohen and Haim Kaplan , booktitle =. Average Distance Queries through Weighted Samples in Graphs and Metric Spaces: High Scalability with Tight Statistical Guarantees , year =
-
[16]
Clustering Small Samples With Quality Guarantees: Adaptivity With One2all
Edith Cohen and Shiri Chechik and Haim Kaplan , booktitle =. Clustering Small Samples With Quality Guarantees: Adaptivity With One2all. 2018 , editor =
2018
-
[17]
Jeffrey Dean and Sanjay Ghemawat , journal =. 2008 , month =. doi:10.1145/1327452.1327492 , publisher =
-
[18]
Fast clustering using
Alina Ene and Sungjin Im and Benjamin Moseley , booktitle =. Fast clustering using. 2011 , publisher =
2011
-
[19]
A unified framework for approximating and clustering data , year =
Dan Feldman and Michael Langberg , booktitle =. A unified framework for approximating and clustering data , year =
-
[20]
Gereon Frahling and Christian Sohler , journal =. A. 2008 , month =. doi:10.1142/s0218195908002787 , publisher =
-
[21]
Data mining: concepts and techniques , year =
Jiawei Han and Micheline Kamber and Jian Pei , publisher =. Data mining: concepts and techniques , year =
-
[22]
Handbook of Cluster Analysis , year =
Christian Hennig and Marina Meila and Fionn Murtagh and Roberto Rocci , publisher =. Handbook of Cluster Analysis , year =
-
[23]
Shahriar Hossain and Rafal A
M. Shahriar Hossain and Rafal A. Angryk , booktitle =. 2007 , month =
2007
-
[24]
Hruschka and L.N
E.R. Hruschka and L.N. de Castro and R.J.G.B. Campello , booktitle =. Evolutionary Algorithms for Clustering Gene-Expression Data , publisher =
-
[25]
Karloff and Siddharth Suri and Sergei Vassilvitskii , booktitle =
Howard J. Karloff and Siddharth Suri and Sergei Vassilvitskii , booktitle =. A Model of Computation for MapReduce , year =
-
[26]
Mining of Massive Datasets , year =
Jure Leskovec and Anand Rajaraman and Jeffrey David Ullman , publisher =. Mining of Massive Datasets , year =
-
[27]
S. Lloyd , journal =. Least squares quantization in. 1982 , month =. doi:10.1109/tit.1982.1056489 , publisher =
-
[28]
Kusner and Wenlin Chen and Kilian Q
Gustavo Malkomes and Matt J. Kusner and Wenlin Chen and Kilian Q. Weinberger and Benjamin Moseley , booktitle =. Fast Distributed k-Center Clustering with Outliers on Massive Data , year =
-
[29]
Accurate MapReduce Algorithms for k-Median and k-Means in General Metric Spaces , year =
Alessio Mazzetto and Andrea Pietracaprina and Geppino Pucci , booktitle =. Accurate MapReduce Algorithms for k-Median and k-Means in General Metric Spaces , year =
-
[30]
Jaskowiak and Ricardo J
Davoud Moulavi and Pablo A. Jaskowiak and Ricardo J. G. B. Campello and Arthur Zimek and J. Density-Based Clustering Validation , year =. Proceedings of the 2014
2014
-
[31]
Ng and Jiawei Han , booktitle =
Raymond T. Ng and Jiawei Han , booktitle =. Efficient and Effective Clustering Methods for Spatial Data Mining , year =
-
[32]
Space-round tradeoffs for MapReduce computations , year =
Andrea Pietracaprina and Geppino Pucci and Matteo Riondato and Francesco Silvestri and Eli Upfal , booktitle =. Space-round tradeoffs for MapReduce computations , year =
-
[33]
Peter J. Rousseeuw , journal =. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis , year =. doi:10.1016/0377-0427(87)90125-7 , publisher =
-
[34]
Thibault Sellam and Robin Cijvat and Richard Koopmanschap and Martin L. Kersten , journal =. Blaeu: Mapping and Navigating Large Tables with Cluster Analysis , year =. doi:10.14778/3007263.3007288 , url =
-
[35]
2005 , address =
Pang-Ning Tan and Michael Steinbach and Vipin Kumar , publisher =. 2005 , address =
2005
-
[36]
Aggarwal and Yelong Shen , booktitle =
Lin Liu and Ruoming Jin and Charu C. Aggarwal and Yelong Shen , booktitle =. Reliable Clustering on Uncertain Graphs , year =
-
[37]
Emmendorfer and Eduardo Nunes Borges and Karina S
Caroline Tomasini and Leonardo R. Emmendorfer and Eduardo Nunes Borges and Karina S. Machado , booktitle =. A methodology for selecting the most suitable cluster validation internal indices , year =
-
[38]
Fei Wang and Hector. An Analysis of the Application of Simplified Silhouette to the Evaluation of k-means Clustering Validity , year =. Machine Learning and Data Mining in Pattern Recognition - 13th International Conference,. doi:10.1007/978-3-319-62416-7\_21 , url =
-
[39]
Comparing the performance of biomedical clustering methods , year =
Christian Wiwie and Jan Baumbach and Richard Röttger , journal =. Comparing the performance of biomedical clustering methods , year =. doi:10.1038/nmeth.3583 , publisher =
-
[40]
Clustering Validation Measures , year =
Hui Xiong and Zhongmou Li , booktitle =. Clustering Validation Measures , year =
-
[41]
2009 , month = jul, abstract =
Andreas Maurer and Massimiliano Pontil , title =. 2009 , month = jul, abstract =
2009
-
[42]
Analytica Chimica Acta , title =
Llet. Analytica Chimica Acta , title =. 2004 , issn =. doi:10.1016/j.aca.2003.12.020 , publisher =
-
[43]
Silhouette Index as Clustering Evaluation Tool , year =
Dudek, Andrzej , pages =. Silhouette Index as Clustering Evaluation Tool , year =. Classification and Data Analysis , doi =
-
[44]
Probability and Computing , year =
Michael Mitzenmacher and Eli Upfal , publisher =. Probability and Computing , year =
-
[45]
Schubert, Erich and Rousseeuw, Peter J. , journal =. Fast and eager k -medoids clustering:. 2021 , issn =. doi:10.1016/j.is.2021.101804 , publisher =
-
[46]
A new partitioning around medoids algorithm , year =
Van der Laan, Mark and Pollard, Katherine and Bryan, Jennifer , journal =. A new partitioning around medoids algorithm , year =. doi:10.1080/0094965031000136012 , publisher =
-
[47]
Medoid Silhouette clustering with automatic cluster number selection , year =
Lenssen, Lars and Schubert, Erich , journal =. Medoid Silhouette clustering with automatic cluster number selection , year =. doi:10.1016/j.is.2023.102290 , publisher =
-
[48]
Arbelaitz, Olatz and Gurrutxaga, Ibai and Muguerza, Javier and Pérez, Jesús M. and Perona, Iñigo , journal =. An extensive comparative study of cluster validity indices , year =. doi:10.1016/j.patcog.2012.07.021 , publisher =
-
[49]
Clustering by Means of Medoids , year =
Kaufmann, Leonard and Rousseeuw, Peter , journal =. Clustering by Means of Medoids , year =
-
[50]
Silhouette coefficient-based weighting k-means algorithm , year =
Lai, Huixia and Huang, Tao and Lu, BinLong and Zhang, Shi and Xiaog, Ruliang , journal =. Silhouette coefficient-based weighting k-means algorithm , year =. doi:10.1007/s00521-024-10706-0 , publisher =
-
[51]
Cluster Quality Analysis Using Silhouette Score , year =
Shahapure, Ketan Rajshekhar and Nicholas, Charles , booktitle =. Cluster Quality Analysis Using Silhouette Score , year =
-
[52]
Scalable Distributed Approximation of Internal Measures for Clustering Evaluation , year =
Altieri, Federico and Pietracaprina, Andrea and Pucci, Geppino and Vandin, Fabio , pages =. Scalable Distributed Approximation of Internal Measures for Clustering Evaluation , year =. Proceedings of the 2021 SIAM International Conference on Data Mining (SDM) , doi =
2021
-
[53]
A Comprehensive Survey of Clustering Algorithms , year =
Xu, Dongkuan and Tian, Yingjie , journal =. A Comprehensive Survey of Clustering Algorithms , year =. doi:10.1007/s40745-015-0040-1 , publisher =
-
[54]
Ikotun, Abiodun M. and Ezugwu, Absalom E. and Abualigah, Laith and Abuhaija, Belal and Heming, Jia , journal =. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data , year =. doi:10.1016/j.ins.2022.11.139 , publisher =
-
[55]
A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs , year =
Karypis, George and Kumar, Vipin , journal =. A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs , year =. doi:10.1137/s1064827595287997 , publisher =
-
[56]
Advances in neural information processing systems , volume=
An impossibility theorem for clustering , author=. Advances in neural information processing systems , volume=
-
[57]
Stop using the elbow criterion for k-means and how to choose the number of clusters instead , year =
Schubert, Erich , journal =. Stop using the elbow criterion for k-means and how to choose the number of clusters instead , year =. doi:10.1145/3606274.3606278 , publisher =
-
[58]
Understanding of Internal Clustering Validation Measures , year =
Liu, Yanchi and Li, Zhongmou and Xiong, Hui and Gao, Xuedong and Wu, Junjie , booktitle =. Understanding of Internal Clustering Validation Measures , year =
-
[59]
and Tayfor, Noor Bahjat and Hassan, Alla A
Hassan, Bryar A. and Tayfor, Noor Bahjat and Hassan, Alla A. and Ahmed, Aram M. and Rashid, Tarik A. and Abdalla, Naz N. , journal =. From A-to-Z review of clustering validation indices , year =. doi:10.1016/j.neucom.2024.128198 , publisher =
-
[60]
Silhouette scores for assessment of SNP genotype clusters , year =
Lovmar, Lovisa and Ahlford, Annika and Jonsson, Mats and Syvänen, Ann-Christine , journal =. Silhouette scores for assessment of SNP genotype clusters , year =. doi:10.1186/1471-2164-6-35 , publisher =
-
[61]
Estimating the Optimal Number of Clusters in Categorical Data Clustering by Silhouette Coefficient , year =
Dinh, Duy-Tai and Fujinami, Tsutomu and Huynh, Van-Nam , pages =. Estimating the Optimal Number of Clusters in Categorical Data Clustering by Silhouette Coefficient , year =. Knowledge and Systems Sciences , doi =
-
[62]
2023 , volume =
Im, Sungjin and Kumar, Ravi and Lattanzi, Silvio and Moseley, Benjamin and Vassilvitskii, Sergei , title =. 2023 , volume =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.