CAF-Gen: A Multi-Agent System for Enriching Argumentation Structures
Pith reviewed 2026-06-28 01:35 UTC · model grok-4.3
The pith
A multi-agent Creator-Reviewer loop turns shallow argument extractions into full Carneades-compliant models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
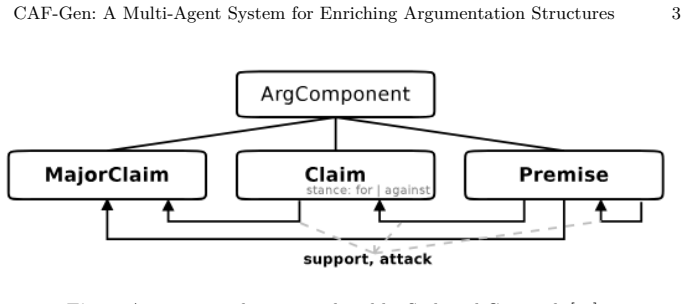
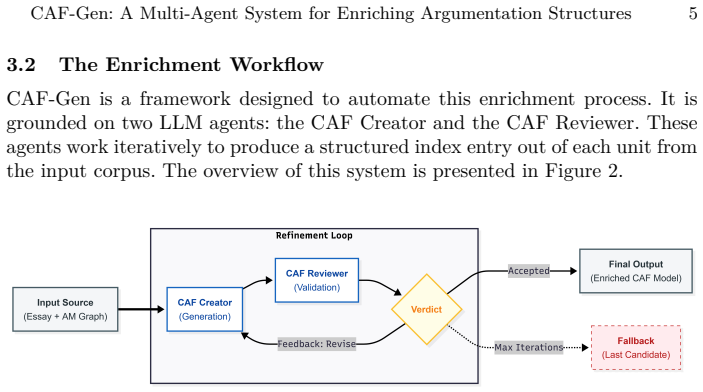
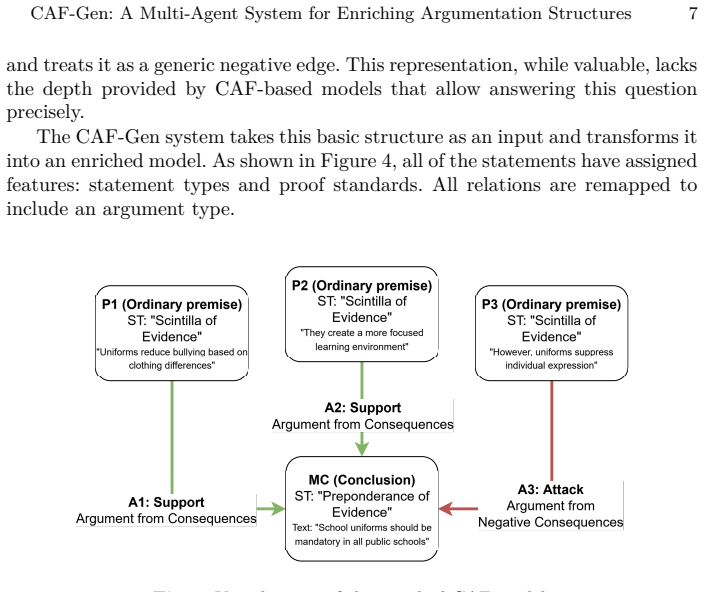
CAF-Gen is an automated multi-agent framework that enriches shallow argument structures into Carneades Argumentation Framework models through an iterative Creator-Reviewer pipeline; experiments indicate the loop improves data quality, achieves strong alignment with original annotations, and yields structurally richer models than single-pass methods.
What carries the argument
The iterative Creator-Reviewer feedback loop that validates and corrects generated CAF structures for premise types, proof standards, and argument schemes.
If this is right
- Argument mining pipelines can scale beyond basic claim-premise pairs to full formal schemas.
- Generated data sets become usable for downstream tasks that require proof standards and argument schemes.
- Multi-agent collaboration becomes a general method for stabilizing generative output in structured reasoning tasks.
- Formal argumentation models can be produced directly from raw text at higher structural fidelity.
Where Pith is reading between the lines
- The same creator-reviewer pattern could be adapted to other argumentation frameworks that specify additional constraints.
- Performance may improve further if the reviewer is given explicit examples of common CAF violations rather than relying on implicit knowledge.
- The approach opens a path to iterative refinement loops for any structured output task where single-pass generation produces inconsistent schemas.
Load-bearing premise
The reviewer agent can consistently spot and fix structural errors in the creator's output without access to ground-truth labels and without introducing fresh inconsistencies.
What would settle it
A side-by-side comparison on held-out texts in which expert annotators rate the multi-agent outputs as having equal or higher rates of CAF violations and lower agreement with original labels than single-pass generation.
Figures

read the original abstract
Formalizing complex reasoning from natural text is one of the central challenges in computational linguistics. It requires systems to understand not just keywords but also the context and complex reasoning embedded in a text. Current Argument Mining (AM) techniques identify basic claims and premises, yet they often struggle to capture the richer structural information required by advanced schemas such as the Carneades Argumentation Framework (CAF), which incorporates features such as premise types, proof standards, and argument schemes. We address this limitation by introducing CAF-Gen, an automated multi-agent framework designed to enrich shallow argument structures into CAF-compliant argument models. By employing an iterative Creator-Reviewer pipeline, a creator agent's output is validated by a critical agent to ensure structural integrity. This multi-agent collaboration is crucial for mitigating the structural instability typical of single-pass generative models. Our experiments demonstrate that the iterative feedback loop improves the quality of the resulting data and achieves strong alignment with the original annotations, while producing structurally richer models. Our findings show that the multi-agent system can overcome the limitations of single-pass generation, providing a robust methodology for the automated modeling of formal argumentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CAF-Gen, a multi-agent system that uses an iterative Creator-Reviewer pipeline to enrich basic argument-mining outputs into Carneades Argumentation Framework (CAF) models incorporating premise types, proof standards, and argument schemes. The central claim is that the feedback loop mitigates single-pass instability, yielding higher-quality, better-aligned, and structurally richer argument models than single-pass generation.
Significance. If the experimental results can be substantiated with proper validation, the work would supply a concrete methodology for scaling formal argumentation modeling beyond current argument-mining techniques, with potential downstream value in domains that require explicit proof standards and scheme identification.
major comments (2)
- [Abstract] Abstract: the assertion that 'our experiments demonstrate that the iterative feedback loop improves the quality of the resulting data and achieves strong alignment with the original annotations' is unsupported by any description of datasets, metrics, baselines, sample sizes, or statistical tests, rendering the central empirical claim unevaluable.
- [Method / Experiments] Method and Experiments sections: the claim that the reviewer agent reliably corrects premise-type, proof-standard, and scheme errors rests on the untested premise that LLM-generated reviewer decisions are accurate without ground-truth CAF annotations; no external oracle, human evaluation protocol, or inter-annotator agreement for the enriched CAF features is reported, so observed improvements could reflect stylistic convergence rather than structural correctness.
minor comments (2)
- [Introduction] The introduction would benefit from an explicit table contrasting standard AM output fields with the additional CAF fields (premise types, proof standards, schemes) that CAF-Gen targets.
- [Abstract] Ensure that all acronyms (CAF, AM) are defined on first use and used consistently; the current abstract contains minor repetition of 'multi-agent collaboration'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'our experiments demonstrate that the iterative feedback loop improves the quality of the resulting data and achieves strong alignment with the original annotations' is unsupported by any description of datasets, metrics, baselines, sample sizes, or statistical tests, rendering the central empirical claim unevaluable.
Authors: We agree that the abstract states an empirical claim without sufficient supporting detail. The Experiments section provides descriptions of the datasets, alignment and quality metrics, single-pass baselines, and sample sizes. To address the concern, we will revise the abstract to include a concise summary of the evaluation protocol, key metrics, and observed improvements so that the claim is evaluable directly from the abstract. revision: yes
-
Referee: [Method / Experiments] Method and Experiments sections: the claim that the reviewer agent reliably corrects premise-type, proof-standard, and scheme errors rests on the untested premise that LLM-generated reviewer decisions are accurate without ground-truth CAF annotations; no external oracle, human evaluation protocol, or inter-annotator agreement for the enriched CAF features is reported, so observed improvements could reflect stylistic convergence rather than structural correctness.
Authors: We acknowledge the validity of this point. Our evaluation currently relies on alignment with the original shallow annotations and internal consistency after iteration, without independent ground-truth labels or human validation for the added CAF features. This limitation means we cannot yet rule out stylistic convergence. We will add a human evaluation protocol, including inter-annotator agreement for premise types, proof standards, and argument schemes, to the revised Experiments section. revision: yes
Circularity Check
No circularity: system design paper with no equations or fitted-parameter reductions.
full rationale
The paper presents CAF-Gen as a new multi-agent Creator-Reviewer pipeline for enriching argument structures. No equations, parameters, or derivations appear in the provided abstract or description. The central claim rests on experimental outcomes rather than any step that reduces by construction to prior fitted quantities or self-citations. Self-citation is not load-bearing here because the work is a system proposal evaluated on alignment with original annotations, not a mathematical result justified only by prior author work. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Carneades Argumentation Framework provides a useful target schema that captures premise types, proof standards, and argument schemes missing from basic argument mining.
invented entities (1)
-
CAF-Gen
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 14 J. Bba and J. A. Chudziak
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Euge- nio, B.D., Schockaert, S
Cabessa, J., Hernault, H., Mushtaq, U.: Argument mining with fine-tuned large lan- guage models. In: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Euge- nio, B.D., Schockaert, S. (eds.) Proceedings of the 31st International Conference on Computational Linguistics. pp. 6624–6635. Association for Computational Linguis- tics, Abu Dhabi, UAE (Jan 202...
2025
-
[3]
In: Ku, L.W., Martins, A., Srikumar, V
Chen, G., Cheng, L., Luu, A.T., Bing, L.: Exploring the potential of large language models in computational argumentation. In: Ku, L.W., Martins, A., Srikumar, V. (eds.) Proceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers). pp. 2309–
-
[4]
Exploring the Potential of Large Language Models in Computational Argumentation
Association for Computational Linguistics, Bangkok, Thailand (Aug 2024). https://doi.org/10.18653/v1/2024.acl-long.126, https://aclanthology.org/ 2024.acl-long.126/
- [5]
-
[6]
Gordon, T., Walton, D.: Proof Burdens and Standards, pp. 239–258 (05 2009). https://doi.org/10.1007/978-0-387-98197-0_12
-
[7]
Artificial intelligence 171(10-15), 875–896 (2007)
Gordon, T.F., Prakken, H., Walton, D.: The carneades model of argument and burden of proof. Artificial intelligence 171(10-15), 875–896 (2007)
2007
-
[8]
Gordon, T.F., Walton, D.: The carneades argumentation framework–using pre- sumptions and exceptions to model critical questions (2006)
2006
- [9]
-
[10]
Gou, Z., Shao, Z., Gong, Y., Shen, Y., Yang, Y., Duan, N., Chen, W.: Critic: Large language models can self-correct with tool-interactive critiquing (2024), https:// arxiv.org/abs/2305.11738
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [11]
-
[12]
Harbar, Y., Chudziak, J.A.: Simulating oxford-style debates with llm- based multi-agent systems. In: Intelligent Information and Database Sys- tems: 17th Asian Conference, ACIIDS 2025, Kitakyushu, Japan, April 23- 25, 2025, Proceedings, Part I. p. 286300. Springer-Verlag, Berlin, Heidelberg (2025). https://doi.org/10.1007/978-981-96-6008-7_21, https://doi...
-
[13]
In: Computational models of argument, pp
Lawrence, J., Bex, F., Reed, C., Snaith, M.: Aifdb: Infrastructure for the argument web. In: Computational models of argument, pp. 515–516. IOS Press (2012)
2012
-
[14]
Computational Linguis- tics 45(4), 765–818 (Dec 2019)
Lawrence, J., Reed, C.: Argument mining: A survey. Computational Linguis- tics 45(4), 765–818 (Dec 2019). https://doi.org/10.1162/coli_a_00364, https: //aclanthology.org/J19-4006/
-
[15]
ACM Transactions on Internet Technology (TOIT) 16(2), 1–25 (2016)
Lippi, M., Torroni, P.: Argumentation mining: State of the art and emerging trends. ACM Transactions on Internet Technology (TOIT) 16(2), 1–25 (2016)
2016
-
[16]
In: Ajjour, Y., Bar-Haim, R., El Baff, R., Liu, Z., Skitalinskaya, G
Mancini, E., Ruggeri, F., Colamonaco, S., Zecca, A., Marro, S., Torroni, P.: MAMKit: A comprehensive multimodal argument mining toolkit. In: Ajjour, Y., Bar-Haim, R., El Baff, R., Liu, Z., Skitalinskaya, G. (eds.) Proceed- ings of the 11th Workshop on Argument Mining (ArgMining 2024). pp. 69–82. Association for Computational Linguistics, Bangkok, Thailand ...
- [17]
-
[18]
Argument & Computation 5(1), 31–62 (2014)
Modgil, S., Prakken, H.: The aspic+ framework for structured argumentation: a tutorial. Argument & Computation 5(1), 31–62 (2014)
2014
-
[19]
Data in Brief 57, 111087 (2024)
Ruiz-Dolz, R., Taverner, J., Lawrence, J., Reed, C.: Nlas-multi: A multilingual corpus of automatically generated natural language argumentation schemes. Data in Brief 57, 111087 (2024)
2024
- [20]
-
[21]
Sermpezis, P., Karamanidis, S., Paraschou, E., Dimitriadis, I., Yfantidou, S., Kouskouveli, F.I., Troboukis, T., Kiki, K., Galanopoulos, A., Vakali, A.: Ago- raspeech: A multi-annotated comprehensive dataset of political discourse through the lens of humans and ai (2025), https://arxiv.org/abs/2501.06265
-
[22]
In: Proceedings of COLING 2014, the 25th international conference on computational linguistics: Technical papers
Stab, C., Gurevych, I.: Annotating argument components and relations in persua- sive essays. In: Proceedings of COLING 2014, the 25th international conference on computational linguistics: Technical papers. pp. 1501–1510 (2014)
2014
-
[23]
Computational Linguistics 43(3), 619–659 (Sep 2017)
Stab, C., Gurevych, I.: Parsing argumentation structures in persua- sive essays. Computational Linguistics 43(3), 619–659 (Sep 2017). https://doi.org/10.1162/COLI_a_00295, https://aclanthology.org/J17-3005/
-
[24]
In: Cohn, T., He, Y., Liu, Y
Toledo-Ronen, O., Orbach, M., Bilu, Y., Spector, A., Slonim, N.: Multilin- gual argument mining: Datasets and analysis. In: Cohn, T., He, Y., Liu, Y. (eds.) Findings of the Association for Computational Linguistics: EMNLP
-
[25]
pp. 303–317. Association for Computational Linguistics, Online (Nov 2020). https://doi.org/10.18653/v1/2020.findings-emnlp.29, https://aclanthology. org/2020.findings-emnlp.29/
-
[26]
Tran, K.T., Dao, D., Nguyen, M.D., Pham, Q.V., O’Sullivan, B., Nguyen, H.D.: Multi-agent collaboration mechanisms: A survey of llms (2025), https://arxiv.org/ abs/2501.06322
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
In: Zong, C., Xia, F., Li, W., Navigli, R
Vecchi, E.M., Falk, N., Jundi, I., Lapesa, G.: Towards argument mining for social good: A survey. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 1338–1352. Associ...
-
[28]
Routledge (2013)
Walton, D.: Argumentation schemes for presumptive reasoning. Routledge (2013)
2013
- [29]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.