VeriPort: Automated and Verified Patch Backporting at Scale
Pith reviewed 2026-06-26 09:46 UTC · model grok-4.3
The pith
VeriPort automatically backports security patches to every affected version while generating verification evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
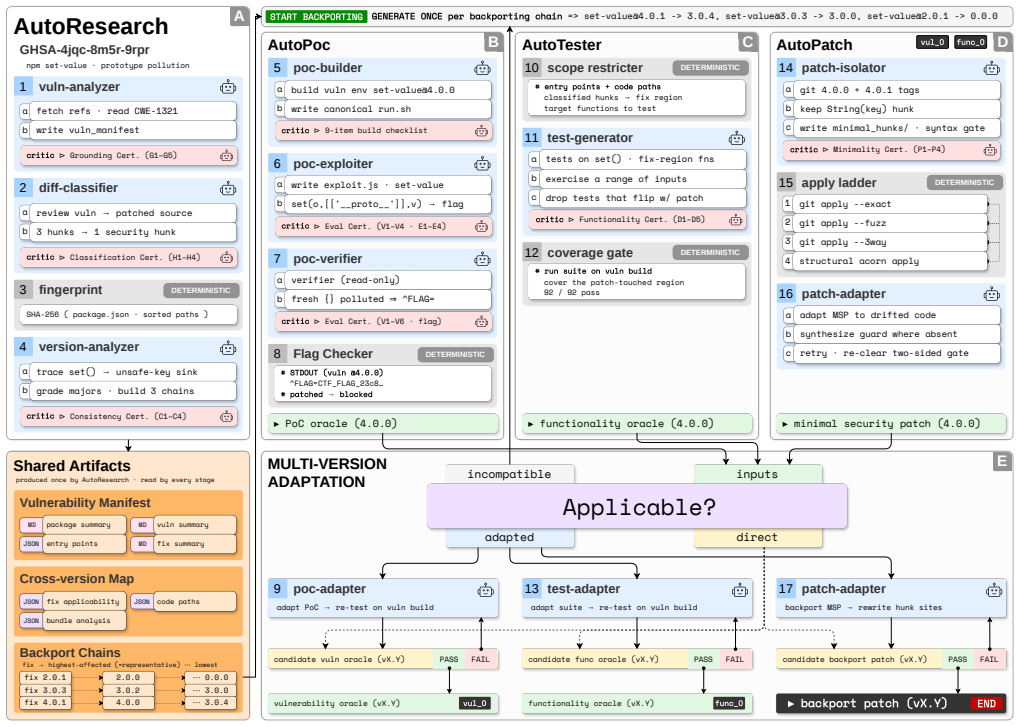
VeriPort is an end-to-end agentic system that scalably backports a patch for a given vulnerability advisory to every affected version of the package. For each backport, VeriPort builds a chain of evidence to confirm that the patch blocks exploitation and preserves intended behavior. The system resolved 95.3 percent of 128 backporting tasks in BackportBench and was deployed on 169 high- and critical-severity CVEs to generate over 5,000 verified backported patches while also correcting upstream vulnerability reports.
What carries the argument
The agentic system that produces and verifies backported patches through explicit chains of evidence for both security and functional preservation.
If this is right
- Developers obtain verified patches for older package versions without performing manual merges.
- The window during which known vulnerabilities remain exploitable in deployed software shrinks.
- Vulnerability databases receive automated corrections when backport analysis reveals mislabeled affected versions.
- Security teams can scale patch application across an entire dependency graph instead of handling each version separately.
Where Pith is reading between the lines
- The same evidence-chain approach could be applied to backporting non-security changes such as bug fixes or API updates.
- Embedding the system inside package managers or CI pipelines would allow automatic generation of verified patches at release time.
- Repeated application across many advisories could produce a large public corpus of verified backports usable for training future tools.
Load-bearing premise
The evidence chains are sufficient to guarantee that each backport blocks the exploit and preserves behavior without missing changes that would appear only in real deployments.
What would settle it
A single backport that VeriPort marks as verified yet either permits the original exploit or alters observable behavior when run against the actual application and test suite.
Figures

read the original abstract
One of the key challenges for securing the software supply chain is addressing known vulnerabilities in third-party open-source dependencies. Security patches are frequently only available for the latest version of a dependency, leaving developers with the choice of either upgrading to the latest version (risking breaking changes) or manually backporting the security fix. Prior work backports to a single version that must be specified in advance and does not produce sufficient evidence to demonstrate that their patches block exploitation and preserve functionality. In this paper, we present VeriPort, an end-to-end agentic system that scalably backports a patch for a given vulnerability advisory to every affected version of the package. For each backport, VeriPort builds a chain of evidence to confirm that the patch blocks exploitation and preserves intended behavior. VeriPort reliably resolves 95.3% of 128 backporting tasks in BackportBench, outperforming the best existing solution (Claude Code) by 22.7 percentage points. We further deployed VeriPort on 169 high- and critical-severity CVEs and have generated over 5,000 verified backported patches. Moreover, VeriPort's value extends beyond simply backporting patches. It uncovered 2,100 versions incorrectly reported as affected and 127 previously unidentified vulnerable versions across 92 advisories, and 23 advisories have since been corrected upstream by removing 387 versions and adding 81.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VeriPort, an end-to-end agentic system for scalably backporting security patches from vulnerability advisories to every affected version of an open-source package. For each backport, the system constructs a chain of evidence intended to confirm both that the patch blocks exploitation and that intended behavior is preserved. It reports resolving 95.3% of 128 tasks in BackportBench (outperforming Claude Code by 22.7 percentage points), deployment on 169 high/critical CVEs yielding over 5,000 verified patches, and discovery of 2,100 incorrectly reported affected versions plus 127 previously unidentified vulnerable versions across 92 advisories.
Significance. If the verification evidence chains are shown to be independent and reliable, the work would be significant for software supply chain security: it automates a labor-intensive task at scale while producing verifiable artifacts, and the empirical discoveries about advisory inaccuracies demonstrate immediate practical utility. The agentic approach to evidence generation is a strength if it can be shown not to reduce to self-validation.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation description: the headline 95.3% success rate and the 'verified' status of the 5,000+ patches are defined by the same agentic system both generating and accepting the evidence chains. No independent oracle, differential testing against the original vulnerable version, or external audit of the chains is described that would detect incomplete evidence or untested behavioral changes. This directly undermines the central claim that the patches are verified to block exploitation and preserve behavior.
- [Abstract / Deployment] Deployment results paragraph: the claim that VeriPort 'generated over 5,000 verified backported patches' rests on the system's internal acceptance of its own evidence chains. Without an external validation step or reported false-positive rate for the verification procedure, the scale of the deployment result cannot be taken as evidence of correctness.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of how evidence chains are constructed and what constitutes acceptance, even at high level.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The concerns about the independence of the verification evidence chains are substantive and we address them directly below. We will revise the manuscript to improve clarity on this point.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the headline 95.3% success rate and the 'verified' status of the 5,000+ patches are defined by the same agentic system both generating and accepting the evidence chains. No independent oracle, differential testing against the original vulnerable version, or external audit of the chains is described that would detect incomplete evidence or untested behavioral changes. This directly undermines the central claim that the patches are verified to block exploitation and preserve behavior.
Authors: We agree that the verification procedure is internal to the VeriPort agentic pipeline and that the manuscript does not describe an independent oracle or external audit of the evidence chains. The chains are built from objective artifacts (vulnerability reproduction on the pre-patch version, patch application, post-patch test execution, and static checks), but these steps are orchestrated and accepted by the same system. We will revise the abstract and evaluation sections to explicitly state the internal nature of the verification, report any available false-positive indicators from the BackportBench tasks, and add a limitations paragraph discussing the absence of external validation. revision: yes
-
Referee: [Abstract / Deployment] Deployment results paragraph: the claim that VeriPort 'generated over 5,000 verified backported patches' rests on the system's internal acceptance of its own evidence chains. Without an external validation step or reported false-positive rate for the verification procedure, the scale of the deployment result cannot be taken as evidence of correctness.
Authors: We accept the referee's observation. The 5,000+ figure reflects patches for which VeriPort completed an evidence chain that the system itself deemed sufficient; no separate false-positive rate for the verification procedure is reported. We will revise the deployment paragraph to qualify the term 'verified' as 'internally verified via evidence chain completion' and will include the observed rate at which chains were rejected during the 169-CVE deployment as a proxy for verification strictness. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmark.
full rationale
The paper reports an empirical success rate (95.3% on BackportBench) and real-world deployment numbers, with explicit comparison to an external baseline (Claude Code). The abstract and described evaluation structure treat BackportBench as an independent test set and measure resolution by task completion against that set, not by internal acceptance of self-generated evidence alone. No equations, definitions, or self-citations are shown that would make the reported metric equivalent to its inputs by construction. The verification chains are an output of the system, but the headline performance numbers are presented as externally measurable results rather than tautological re-statements of the system's own judgments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 CVE data review,
J. Gamblin, “2025 CVE data review,” Blog post, Jan. 2026, accessed: 2026-03-19. [Online]. Available: https://jerrygamblin.com/2026/01/ 01/2025-cve-data-review/
2025
-
[2]
2024 CVE data review,
Jerry Gamblin, “2024 CVE data review,” Blog post, Jan. 2025, analysis of NVD data. Reproducible code available at https://github.com/jgamblin/2024CVEBlog. Accessed: 2026- 03-19. [Online]. Available: https://jerrygamblin.com/2025/01/05/ 2024-cve-data-review/
2024
-
[3]
National vulnera- bility database,
National Institute of Standards and Technology, “National vulnera- bility database,” https://nvd.nist.gov/, accessed: 2026-03-19
2026
-
[4]
Claude Mythos: What does Anthropic’s new model mean for the future of cybersecurity?
C. Hicks, C. Attridge, A. Janjeva, and C. Ashurst, “Claude Mythos: What does Anthropic’s new model mean for the future of cybersecurity?” CETaS Expert Analysis, Centre for Emerging Technology and Security, The Alan Turing Institute, April 2026. [Online]. Available: https: //cetas.turing.ac.uk/publications/claude-mythos-future-cybersecurity
2026
-
[5]
Back to the past – analysing backporting practices in package dependency networks,
A. Decan, T. Mens, A. Zerouali, and C. D. Roover, “Back to the past – analysing backporting practices in package dependency networks,” IEEE Transactions on Software Engineering, vol. 48, no. 10, pp. 4087–4099, 2022
2022
-
[6]
When and how to make breaking changes: Policies and practices in 18 open source software ecosystems,
C. Bogart, C. K ¨astner, J. D. Herbsleb, and F. Thung, “When and how to make breaking changes: Policies and practices in 18 open source software ecosystems,”ACM Transactions on Software Engineering and Methodology, vol. 30, no. 4, pp. 42:1–42:56, 2021
2021
-
[7]
Compatible remediation on vulnerabilities from third-party libraries for java projects,
L. Zhang, C. Liu, Z. Xu, S. Chen, L. Fan, L. Zhao, J. Wu, and Y . Liu, “Compatible remediation on vulnerabilities from third-party libraries for java projects,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), 2023, pp. 2540–2552
2023
-
[8]
Everything you ever wanted to know about Linux -stable releases,
The kernel development community, “Everything you ever wanted to know about Linux -stable releases,”The Linux Kernel documentation, version 7.1.0-rc6. [Online]. Available: https://docs.kernel.org/process/ stable-kernel-rules.html, accessed: Jun. 2, 2026
2026
-
[9]
Automated patch backporting in Linux (experience paper),
R. Shariffdeen, X. Gao, G. J. Duck, S. H. Tan, J. Lawall, and A. Roychoudhury, “Automated patch backporting in Linux (experience paper),” inProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2021. New York, NY , USA: Association for Computing Machinery, 2021, pp. 633–645. [Online]. Available: https://d...
-
[10]
Documenting and automating collateral evolutions in Linux device drivers,
Y . Padioleau, J. Lawall, R. R. Hansen, and G. Muller, “Documenting and automating collateral evolutions in Linux device drivers,” in Proceedings of the 3rd ACM SIGOPS/EuroSys European Conference on Computer Systems (EuroSys ’08). New York, NY , USA: ACM, 2008, pp. 247–260
2008
-
[11]
Enhancing oss patch backporting with semantics,
S. Yang, Y . Xiao, Z. Xu, C. Sun, C. Ji, and Y . Zhang, “Enhancing oss patch backporting with semantics,” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 2366–2380. [Online]. Available: https://doi.org/10.1145/3576915.3623188
-
[12]
Backporting security patches of web applications: A prototype design and implementation on injection vulnerability patches,
Y . Shi, Y . Zhang, T. Luo, X. Mao, Y . Cao, Z. Wang, Y . Zhao, Z. Huang, and M. Yang, “Backporting security patches of web applications: A prototype design and implementation on injection vulnerability patches,” in31st USENIX Security Symposium (USENIX Security 22). Boston, MA: USENIX Association, 2022, pp. 1993–2010. [Online]. Available: https: //www.us...
2022
-
[13]
Vfcfinder: Pairing security advisories and patches,
T. Dunlap, E. Lin, W. Enck, and B. Reaves, “Vfcfinder: Pairing security advisories and patches,” inProceedings of the 19th ACM Asia Conference on Computer and Communications Security, ser. ASIA CCS ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 1128–1142. [Online]. Available: https://doi.org/10.1145/3634737.3657007
-
[14]
Y . Chenget al., “Fixseeker: An empirical driven graph-based approach for detecting silent vulnerability fixes in open source software,” 2025. [Online]. Available: https://arxiv.org/abs/2503.20265
arXiv 2025
-
[15]
BackportBench: A multilingual benchmark for automated backporting of patches,
Z. Zhong, J. Huang, and P. He, “BackportBench: A multilingual benchmark for automated backporting of patches,”arXiv preprint arXiv:2512.01396, 2025, under review. [Online]. Available: https: //arxiv.org/abs/2512.01396
arXiv 2025
-
[16]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://arxiv.org/abs/2405.15793
Pith/arXiv arXiv 2024
-
[17]
Mystique: Automated vulnerability patch porting with semantic and syntactic-enhanced LLM,
S. Wu, R. Wang, Y . Cao, B. Chen, Z. Zhou, Y . Huang, J. Zhao, and X. Peng, “Mystique: Automated vulnerability patch porting with semantic and syntactic-enhanced LLM,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 130–152, 2025
2025
-
[18]
Portgpt: Towards automated backporting using large language models,
Z. Li, Z. Yu, J. Song, M. Xu, Y . Luo, and D. Mu, “Portgpt: Towards automated backporting using large language models,” inProceedings of the 47th IEEE Symposium on Security and Privacy, 2026
2026
-
[19]
Siren’s song in the ai ocean: A survey on hallucination in large language models,
Y . Zhang, Y . Li, L. Cui, D. Cai, L. Liu, T. Fu, X. Huang, E. Zhao, Y . Zhang, C. Xu, Y . Chen, L. Wang, A. T. Luu, W. Bi, F. Shi, and S. Shi, “Siren’s song in the ai ocean: A survey on hallucination in large language models,” https://arxiv.org/abs/2309.01219, 2025
Pith/arXiv arXiv 2025
-
[20]
Ruler: What’s the real context size of your long-context language models?
C.-P. Hsieh, S. Sun, S. Kriman, S. Acharya, D. Rekesh, F. Jia, Y . Zhang, and B. Ginsburg, “Ruler: What’s the real context size of your long-context language models?” 2024. [Online]. Available: https://arxiv.org/abs/2404.06654
Pith/arXiv arXiv 2024
-
[21]
Claude code,
Anthropic, “Claude code,” https://code.claude.com/docs/en/overview, accessed: 2026-04-17. 14
2026
-
[22]
Multi- SWE-bench: A multilingual benchmark for issue resolving,
D. Zan, Z. Huang, W. Liu, H. Chen, S. Xin, L. Zhang, Q. Liu, A. Li, L. Chen, X. Zhong, S. Liu, Y . Xiao, L. Chen, Y . Zhang, J. Su, T. Liu, R. LONG, M. Ding, and liang xiang, “Multi- SWE-bench: A multilingual benchmark for issue resolving,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. [...
2026
-
[23]
CVEPatchBench-Public,
“CVEPatchBench-Public,” https://github.com/SocketDev/ CVEPatchBench-Public
-
[24]
Socket: Software supply chain security,
Socket, Inc., “Socket: Software supply chain security,” https://socket. dev, 2026, accessed: 2026-06-19
2026
-
[25]
Socket’s Patches Page,
“Socket’s Patches Page,” https://socket.dev/features/patches
-
[26]
Map- ping NVD records to their VFCs: How hard is it?
H. H. Nguyen, D. M. Tran, Y . Cheng, T. Le-Cong, H. J. Kang, R. Widyasari, S. L. Khin, O. E. Lieh, T. Zhang, and D. Lo, “Map- ping NVD records to their VFCs: How hard is it?”arXiv preprint arXiv:2506.09702, 2025
Pith/arXiv arXiv 2025
-
[27]
A fine-grained data set and analysis of tangling in bug fixing commits,
S. Herbold, A. Trautsch, B. Ledel, A. Aghamohammadi, T. A. Ghaleb, K. K. Chahal, T. Bossenmaier, B. Nagaria, P. Makedonski, M. N. Ahmadabadi, K. Szabados, H. Spieker, M. Madeja, N. Hoy, V . Lenarduzzi, S. Wang, G. Rodr ´ıguez-P´erez, R. Colomo-Palacios, R. Verdecchia, P. Singh, Y . Qin, D. Chakroborti, W. Davis, V . Walunj, H. Wu, D. Marcilio, O. Alam, A....
-
[28]
To- wards the detection of inconsistencies in public security vulnerability reports,
Y . Dong, W. Guo, Y . Chen, X. Xing, Y . Zhang, and G. Wang, “To- wards the detection of inconsistencies in public security vulnerability reports,” inProceedings of the 28th USENIX Security Symposium (USENIX Security 19). Santa Clara, CA: USENIX Association, 2019, pp. 869–885
2019
-
[29]
V-SZZ: Automatic identification of version ranges affected by CVE vulnerabilities,
L. Bao, X. Xia, A. E. Hassan, and X. Yang, “V-SZZ: Automatic identification of version ranges affected by CVE vulnerabilities,” inProceedings of the 44th IEEE/ACM International Conference on Software Engineering (ICSE ’22). New York, NY , USA: ACM, 2022, pp. 2352–2364
2022
-
[30]
Characterizing and modeling the GitHub security advisories review pipeline,
C. Segal, P. Segal, C. E. de Schuller Banjar, F. P. ao, H. S. Borges, P. S. Neto, E. S. de Almeida, J. C. S. Santos, A. Kocheturov, G. K. Srivastava, and D. S. Menasch ´e, “Characterizing and modeling the GitHub security advisories review pipeline,” inProceedings of the 23rd IEEE/ACM International Conference on Mining Software Repositories (MSR ’26), 2026
2026
-
[31]
H. H. Nguyen, A. T. Nguyen, T. Le-Cong, Y . Li, H. W. Ang, Y . Yin, F. Liauw, S. L. Khin, O. E. Lieh, T. Zhang, and D. Lo, “Patchseeker: Mapping nvd records to their vulnerability-fixing commits with llm generated commits and embeddings,” 2025. [Online]. Available: https://arxiv.org/abs/2509.07540
arXiv 2025
-
[32]
Diffploit: Facilitating cross-version exploit migration for open source library vulnerabilities,
Z. Chen, Z. Xue, J. Zhou, X. Hu, X. Xia, and X. Yang, “Diffploit: Facilitating cross-version exploit migration for open source library vulnerabilities,” 2025. [Online]. Available: https: //arxiv.org/abs/2511.12950
arXiv 2025
-
[33]
From cve entries to verifiable exploits: An automated multi-agent framework for reproducing cves,
S. Ullah, P. Balasubramanian, W. Guo, A. Burnett, H. Pearce, C. Kruegel, G. Vigna, and G. Stringhini, “From cve entries to verifiable exploits: An automated multi-agent framework for reproducing cves,” 2026. [Online]. Available: https://arxiv.org/abs/ 2509.01835
arXiv 2026
-
[34]
B. Ruan, J. Liu, C. Zhang, and Z. Liang, “Kernjc: Automated vulnerable environment generation for linux kernel vulnerabilities,” in The 27th International Symposium on Research in Attacks, Intrusions and Defenses, ser. RAID ’24. ACM, Sep. 2024, p. 384–402. [Online]. Available: http://dx.doi.org/10.1145/3678890.3678891
-
[35]
Pocgen: Generating proof-of-concept exploits for vulnerabilities in npm packages,
D. Simsek, A. Eghbali, and M. Pradel, “Pocgen: Generating proof-of-concept exploits for vulnerabilities in npm packages,” 2025. [Online]. Available: https://arxiv.org/abs/2506.04962
arXiv 2025
-
[36]
Automatically assessing and extending code coverage for NPM packages,
H. Sun, A. Ros `a, D. Bonetta, and W. Binder, “Automatically assessing and extending code coverage for NPM packages,” inProceedings of the 2nd IEEE/ACM International Conference on Automation of Software Test, ser. AST ’21. IEEE, 2021, pp. 40–49
2021
-
[37]
EvoSuite: Automatic test suite generation for object-oriented software,
G. Fraser and A. Arcuri, “EvoSuite: Automatic test suite generation for object-oriented software,” inProceedings of the 19th ACM SIG- SOFT Symposium and the 13th European Conference on Foundations of Software Engineering, ser. ESEC/FSE ’11. New York, NY , USA: ACM, 2011, pp. 416–419
2011
-
[38]
An empirical evaluation of using large language models for automated unit test generation,
M. Sch ¨afer, S. Nadi, A. Eghbali, and F. Tip, “An empirical evaluation of using large language models for automated unit test generation,”
-
[39]
Available: https://arxiv.org/abs/2302.06527
[Online]. Available: https://arxiv.org/abs/2302.06527
-
[40]
On the flakiness of LLM-generated tests for industrial and open- source database management systems,
A. Berndt, T. Bach, R. Gemulla, M. Kessel, and S. Baltes, “On the flakiness of LLM-generated tests for industrial and open- source database management systems,” inProceedings of the 48th IEEE/ACM International Conference on Software Engineering: Soft- ware Engineering in Practice, ser. ICSE-SEIP ’26. New York, NY , USA: ACM, 2026
2026
-
[41]
Automated unit test improvement using large language models at Meta,
N. Alshahwan, J. Chheda, A. Finogenova, B. Gokkaya, M. Harman, I. Harper, A. Marginean, S. Sengupta, and E. Wang, “Automated unit test improvement using large language models at Meta,” in Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, ser. FSE Companion ’24. New York, NY , USA: ACM, 2024, pp. 185–196
2024
-
[42]
Semantic versioning and impact of breaking changes in the Maven repository,
S. Raemaekers, A. van Deursen, and J. Visser, “Semantic versioning and impact of breaking changes in the Maven repository,”Journal of Systems and Software, vol. 129, pp. 140–158, 2017
2017
-
[43]
I depended on you and you broke me: An empirical study of manifesting breaking changes in client packages,
D. Venturini, F. R. Cogo, I. Polato, M. A. Gerosa, and I. S. Wiese, “I depended on you and you broke me: An empirical study of manifesting breaking changes in client packages,”ACM Transactions on Software Engineering and Methodology, vol. 32, no. 4, pp. 1–26, 2023
2023
-
[44]
Has my release disobeyed semantic versioning? Static detection based on semantic differencing,
L. Zhang, C. Liu, Z. Xu, S. Chen, L. Fan, B. Chen, and Y . Liu, “Has my release disobeyed semantic versioning? Static detection based on semantic differencing,” inProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE ’22). New York, NY , USA: ACM, 2022
2022
-
[45]
Plumber: Boosting the Propagation of Vulnerability Fixes in the npm Ecosystem ,
Y . Wang, P. Sun, L. Pei, Y . Yu, C. Xu, S.-C. Cheung, H. Yu, and Z. Zhu, “ Plumber: Boosting the Propagation of Vulnerability Fixes in the npm Ecosystem ,”IEEE Transactions on Software Engineering, vol. 49, no. 05, pp. 3155–3181, May 2023. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/TSE.2023.3243262
-
[46]
Introducing Claude Opus 4.7,
Anthropic, “Introducing Claude Opus 4.7,” https://www.anthropic. com/news/claude-opus-4-7, Apr. 2026, accessed: 2026-06-10
2026
-
[47]
Introducing Claude Opus 4.6,
——, “Introducing Claude Opus 4.6,” https://www.anthropic.com/ news/claude-opus-4-6, Feb. 2026, accessed: 2026-06-10
2026
-
[48]
Agentless: Demystifying llm-based software engineering agents,
C. S. Xia, Y . Deng, S. Dunn, and L. Zhang, “Agentless: Demystifying llm-based software engineering agents,” 2024. [Online]. Available: https://arxiv.org/abs/2407.01489
Pith/arXiv arXiv 2024
-
[49]
τ-bench: A benchmark for tool-agent-user interaction in real-world domains,
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan, “τ-bench: A benchmark for tool-agent-user interaction in real-world domains,”
-
[50]
Available: https://arxiv.org/abs/2406.12045 15 Appendix A
[Online]. Available: https://arxiv.org/abs/2406.12045 15 Appendix A. Additional Figures and Tables Table 2 reports BackportBench pooled across npm and PyPI. We pool because npm contributes only 18 of the 128 tasks, where a single task shifts its rate by 5.6 points, leaving the per-ecosystem npm numbers coarse. Table 5 and Table 4 isolate the with-MSP and ...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.