Training a Predictive Coding Network on ImageNet using Equilibrium Propagation
Pith reviewed 2026-06-28 11:00 UTC · model grok-4.3
The pith
Equilibrium propagation trains a 10-layer predictive coding network on full ImageNet to 13.23% top-5 error, close to backpropagation's 12.2%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By pairing the centered variant of equilibrium propagation with a novel equilibration scheme for predictive coding networks, the authors train a 10-layer convolutional PCN on full-size ImageNet and obtain 13.23% top-5 classification error, close to the 12.2% achieved by backpropagation; this constitutes the first demonstration of both PCNs and EP-based training at ImageNet scale.
What carries the argument
The novel equilibration scheme for predictive coding networks, which enables stable fixed-point convergence when used with centered equilibrium propagation.
If this is right
- Predictive coding networks become trainable at ImageNet scale using equilibrium propagation.
- Equilibrium propagation achieves performance comparable to backpropagation on large-scale image classification.
- The primary scaling challenges for equilibrium propagation in other physical systems stem from computational properties of those systems rather than inherent limits of the framework.
- Both predictive coding networks and equilibrium propagation extend to ImageNet-scale problems.
Where Pith is reading between the lines
- The same equilibration approach could be tested on other energy-based models to check whether it generalizes beyond PCNs.
- Physical hardware implementations of predictive coding networks might use the reported scheme to realize equilibrium-based training at scale.
- The near-parity with backpropagation raises the question of whether hybrid models could combine elements of both methods for further gains.
Load-bearing premise
The novel equilibration scheme produces stable fixed-point convergence at ImageNet scale without introducing instabilities or computational costs that would invalidate the direct comparison to backpropagation.
What would settle it
Observing that the 10-layer PCN diverges or fails to reach a stable fixed point during training on ImageNet with this scheme, or that its error rate substantially exceeds the reported value relative to backpropagation.
Figures


read the original abstract
Equilibrium Propagation (EP) is a physics-based training framework that has primarily been employed in energy-based models, including continuous Hopfield networks, nonlinear resistive networks and coupled phase oscillators. However, EP's practical applications have so far remained limited to relatively small-scale problems. Predictive coding networks (PCNs), another class of energy-based models rooted in computational neuroscience, are typically trained with a specialized algorithm and have likewise not yet been demonstrated at large scale. In this work, we develop an EP-based training method for PCNs which combines the centered variant of EP with a novel equilibration scheme for PCNs. Using this approach, we train a 10-layer convolutional PCN (VGG10) on full-size ImageNet, achieving 13.23\% test error rate on the top-5 classification task, close to the 12.2\% backpropagation baseline. To our knowledge, this is the first demonstration of both PCNs and EP-based training at ImageNet scale. These results significantly extend the scalability of both approaches and suggest that the primary challenges in scaling EP in other physical systems may come more from the computational properties of these systems than from inherent limitations of the EP framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an EP-based training method for predictive coding networks that combines centered equilibrium propagation with a novel equilibration scheme. It reports training a 10-layer convolutional PCN (VGG10) on full-size ImageNet to achieve 13.23% top-5 test error, close to a 12.2% backpropagation baseline, and claims this as the first demonstration of both PCNs and EP at ImageNet scale.
Significance. If the central empirical result holds, the work substantially extends the demonstrated scalability of equilibrium propagation and predictive coding networks to large-scale supervised classification, providing a direct performance comparison against backpropagation on a standard benchmark. This supplies concrete evidence that scaling limitations for EP may be more tied to the computational properties of the underlying physical systems than to the framework itself.
major comments (1)
- [Abstract] Abstract (method paragraph): the central claim that the novel equilibration scheme enables stable fixed-point convergence at ImageNet scale without instabilities or extra costs that would invalidate the direct comparison to the 12.2% BP baseline is not supported by any reported convergence criteria, iteration counts, ablation studies on scheme variants, or evidence that the scheme leaves the effective optimization landscape unchanged relative to standard EP.
minor comments (1)
- [Abstract] The abstract states performance numbers but supplies no details on hyperparameter search, statistical variance across runs, exact baseline architecture, or data preprocessing steps.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and will revise the manuscript accordingly to strengthen the presentation of the equilibration scheme.
read point-by-point responses
-
Referee: [Abstract] Abstract (method paragraph): the central claim that the novel equilibration scheme enables stable fixed-point convergence at ImageNet scale without instabilities or extra costs that would invalidate the direct comparison to the 12.2% BP baseline is not supported by any reported convergence criteria, iteration counts, ablation studies on scheme variants, or evidence that the scheme leaves the effective optimization landscape unchanged relative to standard EP.
Authors: We agree that the abstract's claim regarding the equilibration scheme would be better supported by explicit evidence. The current manuscript reports the final top-5 error but does not include convergence plots, per-layer iteration counts, or ablations on scheme variants. In the revised manuscript we will add these details in a new subsection of the methods (including average equilibration iterations on ImageNet, a stability metric such as residual norm at termination, and a brief ablation comparing the novel scheme to standard EP). We will also clarify that the scheme is intended to preserve the fixed-point equations of centered EP while improving numerical stability; the direct performance comparison to the BP baseline remains valid because both methods optimize the same network architecture to the same task, but we will note that the effective loss landscape may differ slightly due to the equilibration procedure. revision: yes
Circularity Check
No circularity: empirical training result stands on its own
full rationale
The paper's central claim is an empirical measurement: a 10-layer convolutional PCN trained on full-size ImageNet via a described EP-based procedure reaches 13.23% top-5 error. This quantity is obtained by running the training algorithm on external data and comparing to a backpropagation baseline; it does not reduce by any equation in the paper to a fitted parameter, self-defined quantity, or prior self-citation. No derivation chain exists that could be circular. The novel equilibration scheme is presented as an engineering choice whose validity is tested by the reported convergence and accuracy, not presupposed by the result itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1145/3620665.3640366. URLhttps://docs.pytorch.org/assets/pytorch2-2.pdf. Pierre Baldi and Fernando Pineda. Contrastive learning and neural oscillations.Neural Computation, 3(4):526–545,
-
[2]
Cédric Goemaere, Gaspard Oliviers, Rafal Bogacz, and Thomas Demeester. Error optimiza- tion: Overcoming exponential signal decay in deep predictive coding networks.arXiv preprint arXiv:2505.20137,
-
[3]
Training a convergent energy transformer with equilibrium propagation
Rasmus Høier, Tugdual Kerjan, and Benjamin Scellier. Training a convergent energy transformer with equilibrium propagation. InNew Frontiers in Associative Memories-Workshop at ICLR 2026,
2026
-
[4]
A gradient estimator for time-varying electrical networks with non-linear dissipation
Jack Kendall. A gradient estimator for time-varying electrical networks with non-linear dissipation. arXiv preprint arXiv:2103.05636,
-
[5]
Jack Kendall, Ross Pantone, Kalpana Manickavasagam, Yoshua Bengio, and Benjamin Scellier. Training end-to-end analog neural networks with equilibrium propagation.arXiv preprint arXiv:2006.01981,
arXiv 2006
-
[6]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton
URLhttps://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf. Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolu- tional neural networks.Advances in neural information processing systems, 25,
2009
-
[7]
Predictive coding: a theoretical and experi- mental review.arXiv preprint arXiv:2107.12979,
Beren Millidge, Anil Seth, and Christopher L Buckley. Predictive coding: a theoretical and experi- mental review.arXiv preprint arXiv:2107.12979,
-
[8]
Guillaume Pourcel, Debabrota Basu, Maxence Ernoult, and Aditya Gilra. Lagrangian-based equilib- rium propagation: generalisation to arbitrary boundary conditions & equivalence with hamiltonian echo learning.arXiv preprint arXiv:2506.06248,
-
[9]
Towards the training of deeper predictive coding neural networks.arXiv preprint arXiv:2506.23800,
Chang Qi, Matteo Forasassi, Thomas Lukasiewicz, and Tommaso Salvatori. Towards the training of deeper predictive coding neural networks.arXiv preprint arXiv:2506.23800,
-
[10]
Near-equilibrium propagation training in nonlinear wave systems.arXiv preprint arXiv:2510.16084,
Karol Sajnok and Michał Matuszewski. Near-equilibrium propagation training in nonlinear wave systems.arXiv preprint arXiv:2510.16084,
-
[11]
A fast algorithm to simulate nonlinear resistive networks
Benjamin Scellier. A fast algorithm to simulate nonlinear resistive networks. InInternational Conference on Machine Learning, pages 43477–43503. PMLR, 2024a. Benjamin Scellier. Quantum equilibrium propagation: gradient-descent training of quantum systems. InNeurIPS 2024’s Workshop on Machine Learning with New Compute Paradigms, 2024b. Benjamin Scellier an...
2024
-
[12]
Agnostic physics-driven deep learning.arXiv preprint arXiv:2205.15021,
Benjamin Scellier, Siddhartha Mishra, Yoshua Bengio, and Yann Ollivier. Agnostic physics-driven deep learning.arXiv preprint arXiv:2205.15021,
-
[13]
Christopher Zach. Bilevel programs meet deep learning: A unifying view on inference learning methods.arXiv preprint arXiv:2105.07231,
-
[14]
Predictive coding as a neuromorphic alternative to backpropagation: a critical evaluation.Neural Computation, 35(12):1881–1909,
Umais Zahid, Qinghai Guo, and Zafeirios Fountas. Predictive coding as a neuromorphic alternative to backpropagation: a critical evaluation.Neural Computation, 35(12):1881–1909,
1909
-
[15]
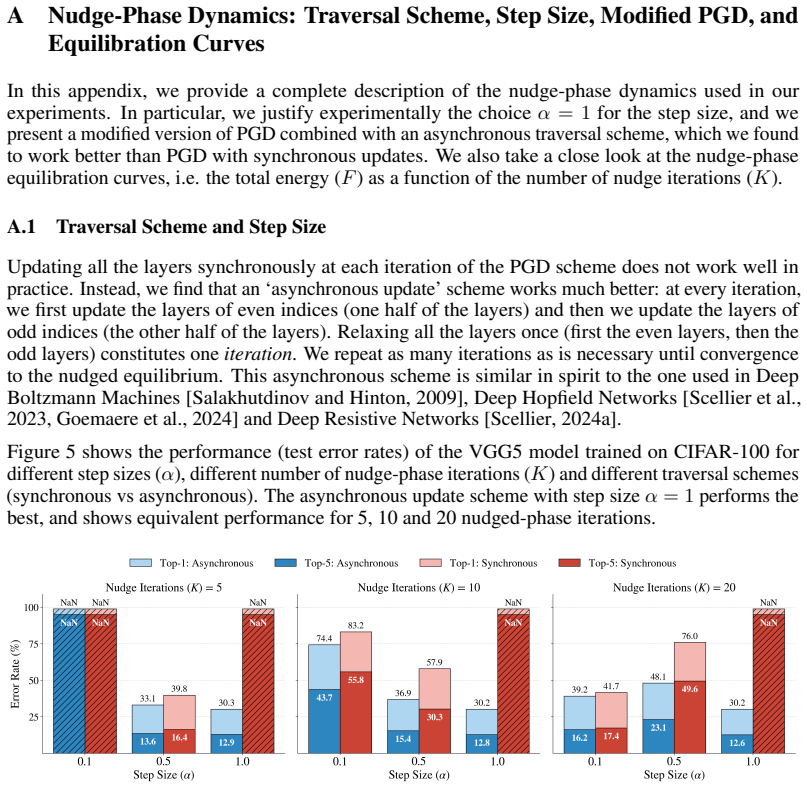
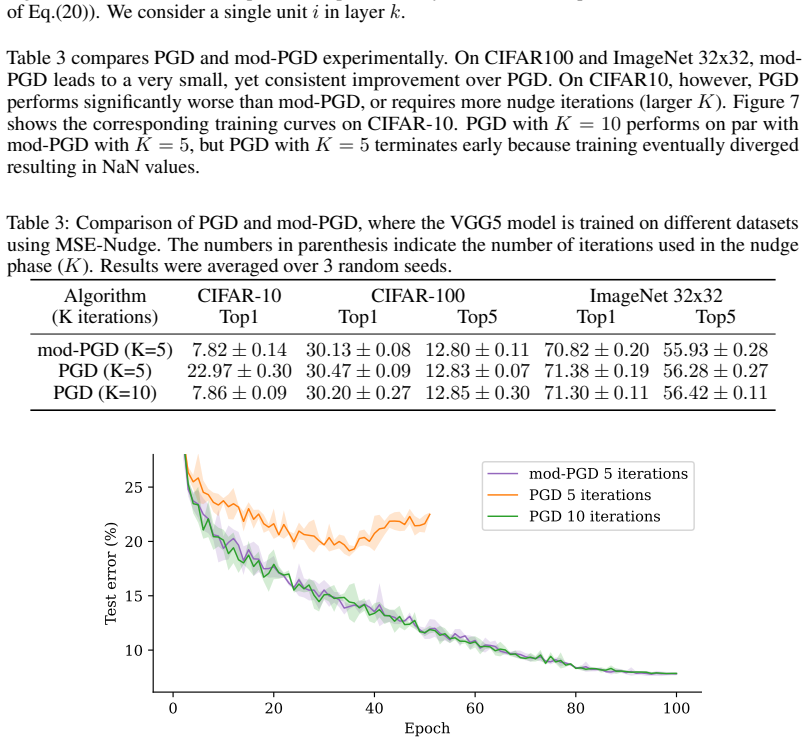
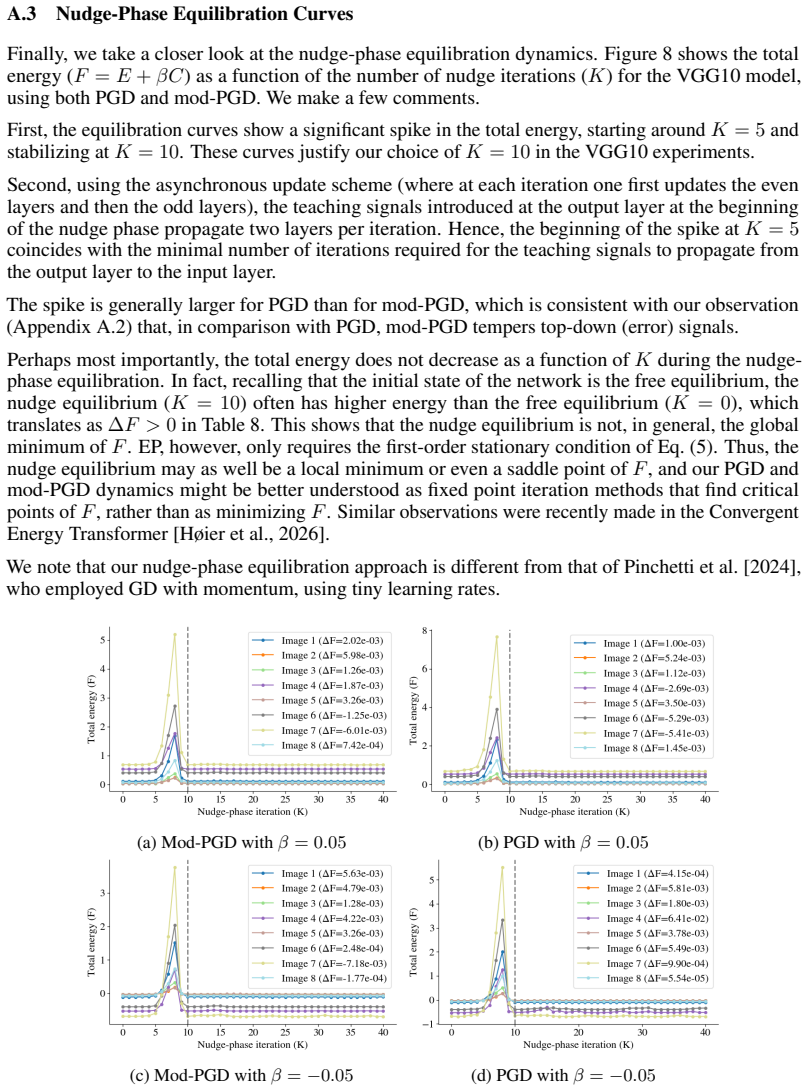
13 A Nudge-Phase Dynamics: Traversal Scheme, Step Size, Modified PGD, and Equilibration Curves In this appendix, we provide a complete description of the nudge-phase dynamics used in our experiments. In particular, we justify experimentally the choice α= 1 for the step size, and we present a modified version of PGD combined with an asynchronous traversal ...
2009
-
[16]
EP, however, only requires the first-order stationary condition of Eq.(5)
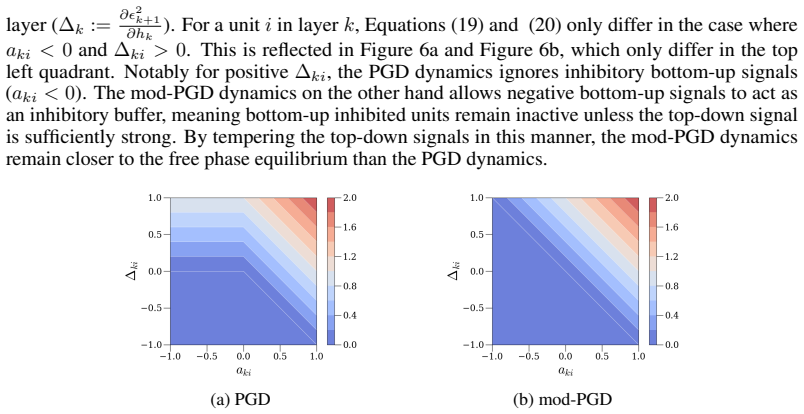
This shows that the nudge equilibrium is not, in general, the global minimum of F . EP, however, only requires the first-order stationary condition of Eq.(5). Thus, the nudge equilibrium may as well be a local minimum or even a saddle point of F , and our PGD and mod-PGD dynamics might be better understood as fixed point iteration methods that find critic...
2026
-
[17]
We normalize the input images using the recommended mean (µ) and std (σ) values for each dataset
Table 4: Data normalization. We normalize the input images using the recommended mean (µ) and std (σ) values for each dataset. The MNIST images are gray-scale, i.e. they have a unique channel. The CIFAR-10, CIFAR-100 and ImageNet images are color images, i.e. they have three channels. mean (µ) std (σ) MNIST 0.1307 0.3081 CIFAR-10 (0.4914, 0.4822, 0.4465) ...
2023
-
[18]
num_inputs is 1 for MNIST, and 3 for other datasets (CIFAR10, CIFAR100 and ImageNet variants)
17 Table 5: VGG5 architecture. num_inputs is 1 for MNIST, and 3 for other datasets (CIFAR10, CIFAR100 and ImageNet variants). num_outputs is 10 for MNIST and CIFAR10, 100 for CIFAR100, and 1000 for ImageNet and ImageNet32. Operation Channels in Channels out Kernels Conv2d num_inputs128 3×3 Conv2d128 256 3×3 MaxPool – –2×2 Conv2d256 512 3×3 MaxPool – –2×2 ...
2048
-
[19]
Training using BP is done the usual way
B.3 Hyperparameters related to training We train our VGG networks with both equilibrium propagation (EP) and backpropagation (BP). Training using BP is done the usual way. As for EP, at each training step, we proceed as follows. First we pick a mini-batch of samples in the training set, x, and their corresponding labels, y. Then we perform a forward pass ...
2024
-
[20]
This recovers the standard predictive coding update rule: neural activities are first relaxed toward a minimum of the energy function, after which synaptic parameters are updated locally using prediction errors and presynaptic activities. C.3 EP’s Contrastive Function in PCNs Unlike traditional PCN learning, EP does not require approximating an intractabl...
2023
-
[21]
As in Eq. (34), EP-based learning in PCNs proceeds in two stages: first, the network state is relaxed toward a stationary state of the total energy, and second, the parameters are updated using local derivatives evaluated at equilibrium. Figure 10: Illustration of the nudging-based perturbation approach of EP in a PCN. In contrast to the clamping-based ap...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.