roto 2.0: The Robot Tactile Olympiad
Pith reviewed 2026-05-21 03:28 UTC · model grok-4.3
The pith
roto 2.0 provides a GPU-parallelized benchmark for blind tactile reinforcement learning across four robot morphologies, where agents reach 13 Baoding ball rotations in 10 seconds using only proprioception and touch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
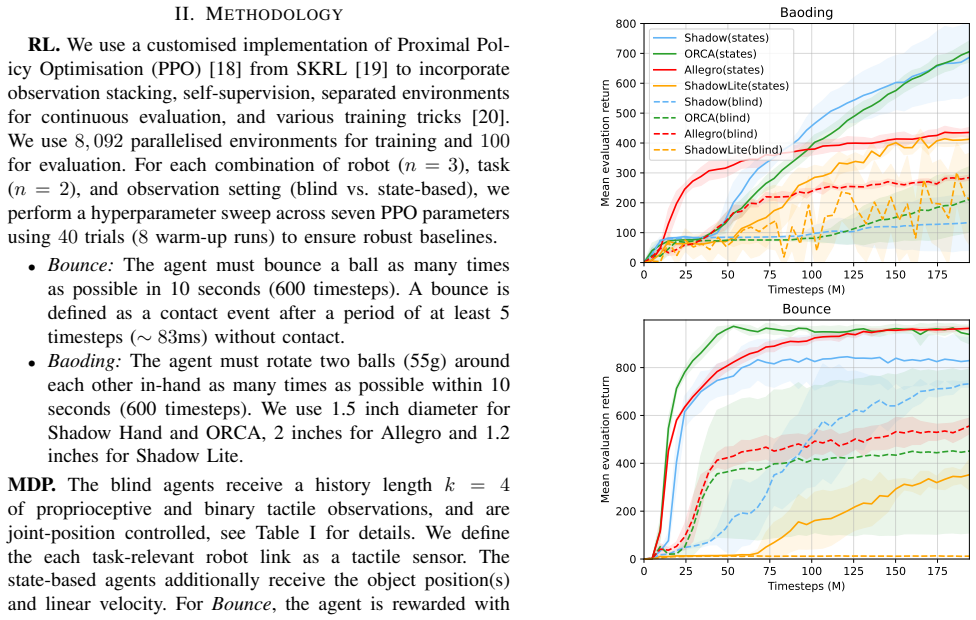
roto 2.0 is a benchmark for end-to-end blind tactile manipulation that runs in parallel on GPUs and covers four distinct robotic morphologies. It uses only proprioceptive and tactile inputs to control robots in a Baoding ball task, without providing state information or using distillation techniques. Agents trained in this setup achieve 13 rotations in 10 seconds, representing a substantial increase over previous state-of-the-art performance levels.
What carries the argument
The GPU-parallelised roto 2.0 environments supporting blind manipulation on 16-DOF to 24-DOF robot morphologies using only proprioception and tactile sensing.
If this is right
- Standardized comparison of tactile RL methods becomes possible across different robot designs.
- Researchers can prioritize algorithmic innovations over environment-specific tuning.
- Performance in blind manipulation tasks can reach significantly higher levels than before.
- Lower barrier to entry allows more researchers to work on core tactile RL problems.
Where Pith is reading between the lines
- Methods that succeed here may generalize better to varied real-world tactile challenges with uncertainty.
- The benchmark could be extended to include additional morphologies or tasks to test broader applicability.
- Similar blind setups might be adapted for other sensing modalities to explore cross-modal learning.
Load-bearing premise
The four chosen morphologies and the Baoding ball task sufficiently represent the space of real-world blind tactile manipulation challenges.
What would settle it
A demonstration that agents trained on roto 2.0 fail to improve performance or transfer to a different tactile task or robot morphology outside the benchmark would challenge the claim of standardization benefit.
Figures

read the original abstract
Tactile-based reinforcement learning (RL) is currently hindered by fragmented research and a focus on over-saturated orientation tasks. We introduce v2 of the Robot Tactile Olympiad (\texttt{roto 2.0}), a GPU-parallelised benchmark designed to standardise tactile-based RL across four distinct robotic morphologies (16-DOF to 24-DOF). Unlike prior benchmarks, roto focuses on end-to-end "blind" manipulation, utilising only proprioception and tactile sensing without state information or distillation. We demonstrate a significant performance leap, with our blind agents achieving 13 Baoding ball rotations in 10 seconds, an order of magnitude faster than current state-of-the-art speeds. By open-sourcing our environments and robustly tuned baselines, we reduce the barrier to entry and enable researchers to prioritise fundamental algorithmic challenges over tedious RL tuning. Website: https://elle-miller.github.io/roto/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces roto 2.0, a GPU-parallelized benchmark for tactile-based RL across four robotic morphologies (16-DOF to 24-DOF). It emphasizes end-to-end blind manipulation using only proprioception and tactile sensing without state information or distillation. The central empirical claim is that blind agents achieve 13 Baoding ball rotations in 10 seconds, asserted to be an order of magnitude faster than current state-of-the-art speeds, with open-sourced environments and tuned baselines provided to lower barriers for research.
Significance. If the performance claims hold under verified identical blind conditions and the chosen morphologies/tasks prove representative, the benchmark could standardize evaluation in tactile RL, shifting focus from environment tuning to algorithmic challenges. The open-sourcing of environments and baselines is a concrete strength supporting reproducibility.
major comments (2)
- [Abstract and results section] Abstract and results section: The headline claim of 13 Baoding ball rotations in 10 seconds as an order-of-magnitude improvement is load-bearing for the paper's contribution, yet the manuscript does not quote exact prior SOTA speeds, confirm identical blind observation spaces (proprioception + tactile only, no privileged information), or verify equivalent rotation-counting metrics and morphologies. If prior work used vision, distillation, or different conventions, the leap does not hold.
- [Methods/experimental setup] Methods/experimental setup: No details are supplied on training procedures, baseline implementations, statistical significance testing, or verification methods for the reported performance numbers, preventing assessment of whether the data actually supports the central performance claim.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly listed the four specific morphologies and DOF counts rather than the range alone.
- [Figures] Figure captions and axis labels in any performance plots should explicitly state the observation space and whether results are blind or privileged to aid direct comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and results section] Abstract and results section: The headline claim of 13 Baoding ball rotations in 10 seconds as an order-of-magnitude improvement is load-bearing for the paper's contribution, yet the manuscript does not quote exact prior SOTA speeds, confirm identical blind observation spaces (proprioception + tactile only, no privileged information), or verify equivalent rotation-counting metrics and morphologies. If prior work used vision, distillation, or different conventions, the leap does not hold.
Authors: We agree that explicit, side-by-side comparisons are required to support the central claim. The manuscript already cites relevant prior tactile RL works, but we will add a new comparison table in the results section that lists exact reported speeds, observation spaces (explicitly noting which use vision, privileged state, or distillation), morphologies, and rotation-counting conventions from the original papers. We will also insert a clarifying sentence in the abstract and results stating that our agents operate under strictly blind conditions using only proprioception and tactile sensing. These additions will allow direct verification of the claimed improvement. revision: yes
-
Referee: [Methods/experimental setup] Methods/experimental setup: No details are supplied on training procedures, baseline implementations, statistical significance testing, or verification methods for the reported performance numbers, preventing assessment of whether the data actually supports the central performance claim.
Authors: We accept that the current manuscript is insufficiently detailed on these points. In the revised version we will expand the experimental setup and appendix to include: (i) complete training hyperparameters and network architectures, (ii) descriptions of how each baseline was implemented and tuned, (iii) performance statistics (mean and standard deviation) across multiple random seeds, and (iv) explicit verification procedures such as automated rotation logging and episode rollout checks. Full code and configuration files are already open-sourced; we will add direct pointers and a reproducibility checklist. revision: yes
Circularity Check
No circularity: empirical benchmark without derivations
full rationale
The paper introduces roto 2.0 as a GPU-parallelised benchmark for blind tactile RL across morphologies and reports experimental results (13 Baoding ball rotations in 10 s). No equations, first-principles derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. Performance claims rest on direct simulation outcomes rather than any chain that reduces to its own inputs by construction. Self-citations, if present in the full manuscript, are not load-bearing for any derivation because none exists. The contribution is self-contained as an open benchmark with reported baselines.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use a customised implementation of Proximal Policy Optimization (PPO) ... blind agents receive a history length k=4 of proprioceptive and binary tactile observations
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
our blind agents achieving 13 Baoding ball rotations in 10 seconds
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
N. Rudin, J. He, J. Aurand, and M. Hutter, “Parkour in the wild: Learning a general and extensible agile locomotion policy using multi-expert distillation and rl fine-tuning,” 2025. [Online]. Available: https://arxiv.org/abs/2505.11164
-
[2]
Learning dexterous in-hand manipulation,
O. M. Andrychowicz, B. Baker, M. Chociej, R. Józefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba, “Learning dexterous in-hand manipulation,”The International Journal of Robotics Research, vol. 39, no. 1, Jan. 2020. [Online]. Available: https://doi.org/10.1177...
-
[3]
Learning Purely Tactile In-Hand Manipulation with a Torque-Controlled Hand,
L. Sievers, J. Pitz, and B. Bäuml, “Learning Purely Tactile In-Hand Manipulation with a Torque-Controlled Hand,” in2022 International Conference on Robotics and Automation (ICRA), May 2022, pp. 2745–
work page 2022
-
[4]
Available: https://ieeexplore.ieee.org/document/9812093
[Online]. Available: https://ieeexplore.ieee.org/document/9812093
-
[5]
A system for general in-hand object re-orientation,
T. Chen, J. Xu, and P. Agrawal, “A system for general in-hand object re-orientation,”Conference on Robot Learning, 2021
work page 2021
-
[6]
In-Hand Object Rotation via Rapid Motor Adaptation,
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik, “In-Hand Object Rotation via Rapid Motor Adaptation,” inConference on Robot Learning (CoRL), 2022
work page 2022
-
[7]
General In-hand Object Rotation with Vision and Touch,
H. Qi, B. Yi, S. Suresh, M. Lambeta, Y . Ma, R. Calandra, and J. Malik, “General In-hand Object Rotation with Vision and Touch,” inProceedings of The 7th Conference on Robot Learning. PMLR, Dec. 2023, pp. 2549–2564, iSSN: 2640-3498. [Online]. Available: https://proceedings.mlr.press/v229/qi23a.html
work page 2023
-
[8]
Estimator- Coupled Reinforcement Learning for Robust Purely Tactile In- Hand Manipulation,
L. Röstel, J. Pitz, L. Sievers, and B. Bäuml, “Estimator- Coupled Reinforcement Learning for Robust Purely Tactile In- Hand Manipulation,” in2023 IEEE-RAS 22nd International Conference on Humanoid Robots (Humanoids). Austin, TX, USA: IEEE, Dec. 2023, pp. 1–8. [Online]. Available: https://ieeexplore.ieee.org/document/10375194/
-
[9]
Anyrotate: Gravity-invariant in- hand object rotation with sim-to-real touch,
M. Yang, C. Lu, A. Church, Y . Lin, C. Ford, H. Li, E. Psomopoulou, D. A. W. Barton, and N. F. Lepora, “Anyrotate: Gravity-invariant in- hand object rotation with sim-to-real touch,” inConference on Robot Learning (CoRL), 2024
work page 2024
-
[10]
Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation,
S. Suresh, H. Qi, T. Wu, T. Fan, L. Pineda, M. Lambeta, J. Malik, M. Kalakrishnan, R. Calandra, M. Kaess, J. Ortiz, and M. Mukadam, “Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation,”Science Robotics, p. adl0628, 2024
work page 2024
-
[11]
M. T. Mason, “Toward Robotic Manipulation,”Annual Review of Con- trol, Robotics, and Autonomous Systems, no. 1, 2018
work page 2018
-
[12]
Y . Lin, J. Lloyd, A. Church, and N. F. Lepora, “Tactile gym 2.0: Sim-to- real deep reinforcement learning for comparing low-cost high-resolution robot touch,”IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 754–10 761, 2022
work page 2022
-
[13]
Q. Liu, Y . Cui, Z. Sun, G. Li, J. Chen, and Q. Ye, “Vtdexmanip: A dataset and benchmark for visual-tactile pretraining and dexterous manipulation with reinforcement learning,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=jf7C7EGw21
work page 2025
-
[14]
Orbit: A unified simulation framework for interactive robot learning environments,
M. Mittal, C. Yu, Q. Yu, J. Liu, N. Rudin, D. Hoeller, J. L. Yuan, R. Singh, Y . Guo, H. Mazhar, A. Mandlekar, B. Babich, G. State, M. Hutter, and A. Garg, “Orbit: A unified simulation framework for interactive robot learning environments,”IEEE Robotics and Automation Letters, vol. 8, no. 6, pp. 3740–3747, 2023
work page 2023
-
[15]
Enhancing tactile-based reinforcement learning for robotic control,
E. Miller, T. McInroe, D. Abel, O. Mac Aodha, and S. Vijayakumar, “Enhancing tactile-based reinforcement learning for robotic control,” in NeurIPS, 2025
work page 2025
-
[16]
Z.-H. Yin, B. Huang, Y . Qin, Q. Chen, and X. Wang, “Rotating without Seeing: Towards In-hand Dexterity through Touch,” Mar. 2023, arXiv:2303.10880 [cs]. [Online]. Available: http://arxiv.org/abs/2303. 10880
-
[17]
L. Yang, B. Huang, Q. Li, Y .-Y . Tsai, W. W. Lee, C. Song, and J. Pan, “TacGNN: Learning Tactile-Based In-Hand Manipulation With a Blind Robot Using Hierarchical Graph Neural Network,”IEEE Robotics and Automation Letters, vol. 8, no. 6, pp. 3605–3612, Jun. 2023. [Online]. Available: https://ieeexplore.ieee.org/document/10093019/
-
[18]
Robot synesthesia: In-hand manipulation with visuotactile sensing,
Y . Yuan, H. Che, Y . Qin, B. Huang, Z.-H. Yin, K.-W. Lee, Y . Wu, S.- C. Lim, and X. Wang, “Robot synesthesia: In-hand manipulation with visuotactile sensing,” inICRA, 2024
work page 2024
-
[19]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
skrl: Modular and flexible library for reinforcement learning,
A. Serrano-Muñoz, D. Chrysostomou, S. Bøgh, and N. Arana- Arexolaleiba, “skrl: Modular and flexible library for reinforcement learning,”Journal of Machine Learning Research, vol. 24, no. 254, pp. 1–9, 2023. [Online]. Available: http://jmlr.org/papers/v24/23-0112.html
work page 2023
-
[21]
The art of robot reinforcement learning,
E. Miller, “The art of robot reinforcement learning,” parallelles.substack.com, 2026. [Online]. Available: https://parallelles. substack.com/p/the-art-of-robot-reinforcement-learning
work page 2026
-
[22]
Humanoid- bench: Simulated humanoid benchmark for whole-body locomotion and manipulation,
C. Sferrazza, D.-M. Huang, X. Lin, Y . Lee, and P. Abbeel, “Humanoid- bench: Simulated humanoid benchmark for whole-body locomotion and manipulation,” 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.