ActiveMimic: Egocentric Video Pretraining with Active Perception
Pith reviewed 2026-06-28 01:16 UTC · model grok-4.3
The pith
Recovering synchronized camera and wrist trajectories from egocentric human video enables pretraining that matches robot-data models on manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
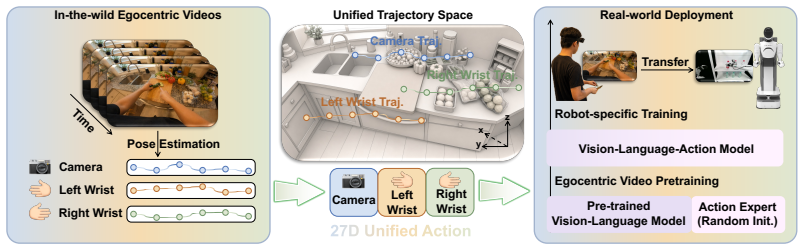
The central claim is that active perception signals latent in egocentric human videos can be recovered as synchronized camera-wrist trajectories from a single RGB camera, modeled explicitly as viewpoint actions, and used to pretrain policies that learn both perception and manipulation jointly; when adapted to robots, these policies close the gap with robot-data pretraining across tasks that vary in active-perception demands.
What carries the argument
The ActiveMimic framework that recovers synchronized camera and wrist trajectories from single RGB video and treats camera motion as an explicit viewpoint action during joint pretraining of perception and manipulation.
If this is right
- Pretraining can now draw on far larger pools of everyday human video rather than scarce robot interaction data.
- The active-perception component transfers from human-video pretraining and does not require robot-specific fine-tuning to appear in the final policy.
- Policies become effective on tasks whose success depends on deliberate viewpoint adjustment during manipulation.
- The same trajectory-recovery step can be applied to new egocentric datasets without additional instrumentation.
Where Pith is reading between the lines
- If the trajectory extraction works on internet-scale egocentric video, pretraining corpora could grow by orders of magnitude beyond current robot datasets.
- The same viewpoint-action modeling might apply to non-manipulation domains such as navigation or inspection where camera motion is also goal-directed.
- Embodiment differences between human and robot hands may still limit transfer even after active perception is aligned.
Load-bearing premise
That the performance difference between human-video and robot-data pretraining is caused by the lack of an explicit active-perception signal that can be accurately recovered from unsynchronized single-camera footage without extra sensors or viewpoint labels.
What would settle it
A controlled test in which the camera-motion modeling component is removed or replaced with random viewpoint noise yet performance still matches robot-data baselines, or in which the full method is applied to videos containing no recoverable active-perception signal yet still matches those baselines.
Figures









read the original abstract
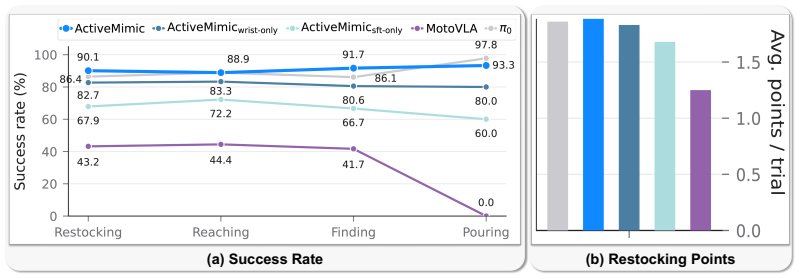
Egocentric human video offers a scalable alternative to robot data for pretraining, yet models pretrained on such video consistently underperform those pretrained on robot data. We attribute this gap to a missing signal, the active perception behavior in egocentric videos, where humans continuously reposition their viewpoint during manipulation, inducing camera motion that standard pipelines treat as noise. To address this, we present ActiveMimic, a pretraining framework that recovers synchronized camera and wrist trajectories from a single body-worn RGB camera, models camera motion as a viewpoint action, and jointly learns active perception and manipulation from in-the-wild egocentric human video before adapting to a target robot. Empirically, real-world experiments across tasks with diverse active perception demands show that ActiveMimic consistently surpasses baselines pretrained on human video and matches state-of-the-art models pretrained on robot data. Further analysis provides evidence that active perception capability originates from egocentric human video pretraining rather than robot-specific fine-tuning, confirming active perception as the key to unlocking egocentric human video for robot pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ActiveMimic, a pretraining framework that recovers synchronized camera and wrist trajectories from monocular body-worn RGB egocentric human videos, treats camera motion as explicit viewpoint actions, and jointly pretrains active perception with manipulation before robot adaptation. It claims this closes the performance gap with robot-data pretraining, with real-world experiments showing consistent superiority over human-video baselines and parity with SOTA robot-data models, plus analysis attributing the active-perception capability to the human-video stage rather than robot fine-tuning.
Significance. If the trajectory recovery is verifiably accurate and the gains are causally tied to the active-perception signal, the result would be significant for scalable robot learning: it would demonstrate how abundant in-the-wild egocentric video can substitute for scarce robot data by explicitly modeling viewpoint control, with direct implications for manipulation tasks requiring active sensing.
major comments (2)
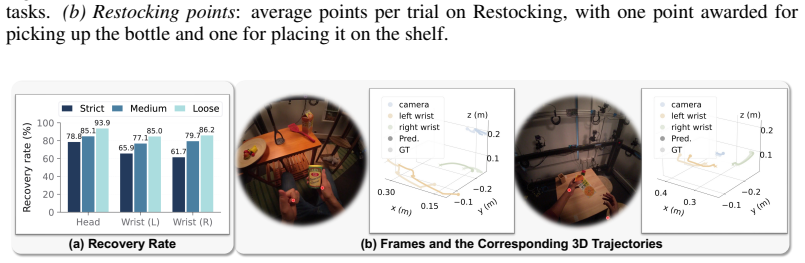
- [§3] §3 (trajectory recovery subsection): the method for extracting synchronized camera-wrist trajectories from a single monocular RGB stream is presented without any reported pose-estimation error metrics, ground-truth comparisons, or robustness analysis under manipulation blur/occlusion; this is load-bearing because the central claim attributes the human-vs-robot gap specifically to the absence of an accurate active-perception signal that is now recovered.
- [§5.2] §5.2 (origin analysis): the evidence that active-perception capability 'originates from egocentric human video pretraining rather than robot-specific fine-tuning' lacks an ablation that varies trajectory estimation noise or substitutes noisy vs. clean viewpoint actions; without it the causal attribution cannot be isolated from incidental regularization or data-filtering effects.
minor comments (2)
- [Abstract] Abstract: quantitative results, dataset sizes, task counts, and error bars are omitted, making it difficult for readers to gauge the scale of the reported improvements.
- [§3] Notation in §3: the distinction between recovered 'viewpoint action' and raw optical flow is not made explicit in the equations, risking confusion with standard video-pretraining pipelines.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (trajectory recovery subsection): the method for extracting synchronized camera-wrist trajectories from a single monocular RGB stream is presented without any reported pose-estimation error metrics, ground-truth comparisons, or robustness analysis under manipulation blur/occlusion; this is load-bearing because the central claim attributes the human-vs-robot gap specifically to the absence of an accurate active-perception signal that is now recovered.
Authors: We agree that quantitative validation of trajectory recovery would strengthen the presentation. Ground-truth comparisons are infeasible for the in-the-wild egocentric videos, which lack synchronized motion-capture data. We will add (i) accuracy metrics on synthetic sequences with known ground truth and (ii) a robustness analysis under simulated blur and occlusion in the revised manuscript. revision: yes
-
Referee: [§5.2] §5.2 (origin analysis): the evidence that active-perception capability 'originates from egocentric human video pretraining rather than robot-specific fine-tuning' lacks an ablation that varies trajectory estimation noise or substitutes noisy vs. clean viewpoint actions; without it the causal attribution cannot be isolated from incidental regularization or data-filtering effects.
Authors: The §5.2 analysis isolates the contribution of active-perception modeling via controlled pretraining ablations. We acknowledge that an explicit noise-level ablation on the recovered trajectories would provide stronger causal isolation. We will add this ablation in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external comparisons
full rationale
The paper presents an empirical pretraining framework and reports real-world robot task results comparing human-video pretraining (with recovered trajectories) against baselines. No equations, fitted parameters, or derivation steps are described that reduce by construction to the inputs (e.g., no self-definitional recovery of trajectories or predictions forced by prior fits). Attribution of gains to active perception is supported by ablation-style analysis rather than a closed mathematical loop. Self-citations, if present, are not load-bearing for the central empirical result. The method is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes that collapse to prior author work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
ThinkingVLA: Interleaved Vision and Language Reasoning for Robotic Manipulation
ThinkingVLA is a Mixture-of-Transformers VLA model that performs interleaved forward CoT for subgoal and image prediction followed by inverse CoT grounded on the predicted image to generate actions.
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In CoRL, 2023
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InCoRL, 2025
2025
-
[3]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[4]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[5]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InICLR, 2025
2025
-
[6]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[7]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[8]
Lipman, R
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[9]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. InICRA, 2024
2024
-
[10]
Y . Liu, W. C. Shin, Y . Han, Z. Chen, H. Ravichandar, and D. Xu. Immimic: Cross-domain imitation from human videos via mapping and interpolation. InCoRL, 2025
2025
- [11]
-
[12]
Spiridonov, J.-N
A. Spiridonov, J.-N. Zaech, N. Nikolov, L. Van Gool, and D. P. Paudel. Generalist robot manipulation beyond action labeled data. InCoRL, 2025
2025
-
[13]
T. Yoshida, S. Kurita, T. Nishimura, and S. Mori. Developing vision-language-action model from egocentric videos.arXiv preprint arXiv:2509.21986, 2025
arXiv 2025
-
[14]
R. Bajcsy. Active perception.Proceedings of the IEEE, 1988
1988
-
[15]
Bajcsy, Y
R. Bajcsy, Y . Aloimonos, and J. K. Tsotsos. Revisiting active perception.Autonomous Robots, 2018
2018
-
[16]
Aloimonos, I
J. Aloimonos, I. Weiss, and A. Bandyopadhyay. Active vision.IJCV, 1988
1988
-
[17]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
Pith/arXiv arXiv 2025
-
[18]
L. Y . Zhu, P. Kuppili, R. Punamiya, P. Aphiwetsa, D. Patel, S. Kareer, S. Ha, and D. Xu. Emma: Scaling mobile manipulation via egocentric human data.RAL, 2026. 9
2026
-
[19]
M. Shi, S. Peng, J. Chen, H. Jiang, Y . Li, D. Huang, P. Luo, H. Li, and L. Chen. Egohu- manoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration. arXiv preprint arXiv:2602.10106, 2026
Pith/arXiv arXiv 2026
-
[20]
R.-Z. Qiu, S. Yang, X. Cheng, C. Chawla, J. Li, T. He, G. Yan, D. J. Yoon, R. Hoque, L. Paulsen, et al. Humanoid policy∼human policy. InCoRL, 2025
2025
-
[21]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InCVPR, 2022
2022
-
[22]
H. Luo, Y . Wang, W. Zhang, S. Zheng, Z. Xi, C. Xu, H. Xu, H. Yuan, C. Zhang, Y . Wang, et al. Being-h0. 5: Scaling human-centric robot learning for cross-embodiment generalization. arXiv preprint arXiv:2601.12993, 2026
arXiv 2026
-
[23]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video. InICRA, 2025
2025
-
[24]
Bircher, M
A. Bircher, M. Kamel, K. Alexis, H. Oleynikova, and R. Siegwart. Receding horizon” next- best-view” planner for 3d exploration. InICRA, 2016
2016
-
[25]
Breyer, L
M. Breyer, L. Ott, R. Siegwart, and J. J. Chung. Closed-loop next-best-view planning for target-driven grasping. InIROS, 2022
2022
-
[26]
Connolly
C. Connolly. The determination of next best views. InICRA, 1985
1985
-
[27]
Krainin, B
M. Krainin, B. Curless, and D. Fox. Autonomous generation of complete 3d object models using next best view manipulation planning. InICRA, 2011
2011
-
[28]
Naazare, F
M. Naazare, F. G. Rosas, and D. Schulz. Online next-best-view planner for 3d-exploration and inspection with a mobile manipulator robot.RAL, 2022
2022
-
[29]
Zhang, D
X. Zhang, D. Wang, S. Han, W. Li, B. Zhao, Z. Wang, X. Duan, C. Fang, X. Li, and J. He. Affordance-driven next-best-view planning for robotic grasping. InCoRL, 2023
2023
-
[30]
J. Yu, Y . Shentu, D. Wu, P. Abbeel, K. Goldberg, and P. Wu. Egomi: Learning active vi- sion and whole-body manipulation from egocentric human demonstrations.arXiv preprint arXiv:2511.00153, 2025
arXiv 2025
-
[31]
Xiong, X
H. Xiong, X. Xu, J. Wu, Y . Hou, J. Bohg, and S. Song. Vision in action: Learning active perception from human demonstrations. InCoRL, 2025
2025
-
[32]
Q. Zeng, C. Li, J. S. John, Z. Zhou, J. Wen, G. Feng, Y . Zhu, and Y . Xu. Activeumi: Robotic manipulation with active perception from robot-free human demonstrations.arXiv preprint arXiv:2510.01607, 2025
arXiv 2025
-
[33]
Chuang, A
I. Chuang, A. Lee, D. Gao, M.-M. Naddaf-Sh, and I. Soltani. Active vision might be all you need: Exploring active vision in bimanual robotic manipulation. InICRA, 2025
2025
-
[34]
J. Kerr, K. Hari, E. Weber, C. M. Kim, B. Yi, K. Goldberg, A. Kanazawa, et al. Eye, robot: Learning to look to act with a bc-rl perception-action loop. InCoRL, 2025
2025
-
[35]
Cheng, J
X. Cheng, J. Li, S. Yang, G. Yang, and X. Wang. Open-television: Teleoperation with immer- sive active visual feedback. InCoRL, 2025
2025
-
[36]
M. Liu, E. Zhou, C. Chi, Y . Han, S. Rong, L. Chen, P. Wang, Z. Wang, and S. Zhang. Sapave: Towards active perception and manipulation in vision-language-action models for robotics. arXiv preprint arXiv:2603.12193, 2026. 10
arXiv 2026
- [37]
-
[38]
Q. Li, Y . Deng, Y . Liang, L. Luo, L. Zhou, C. Yao, L. Zeng, Z. Feng, H. Liang, S. Xu, et al. Scalable vision-language-action model pretraining for robotic manipulation with real-life hu- man activity videos.arXiv preprint arXiv:2510.21571, 2025
arXiv 2025
-
[39]
X. Yang, D. Kukreja, D. Pinkus, A. Sagar, T. Fan, J. Park, S. Shin, J. Cao, J. Liu, N. Ugrinovic, et al. Sam 3d body: Robust full-body human mesh recovery.arXiv preprint arXiv:2602.15989, 2026
arXiv 2026
-
[40]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[41]
Piccinelli, Y .-H
L. Piccinelli, Y .-H. Yang, C. Sakaridis, M. Segu, S. Li, L. Van Gool, and F. Yu. Unidepth: Universal monocular metric depth estimation. InCVPR, 2024
2024
-
[42]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InCVPR, 2019
2019
-
[43]
W. Liang, L. Yu, L. Luo, S. Iyer, N. Dong, C. Zhou, G. Ghosh, M. Lewis, W.-t. Yih, L. Zettle- moyer, et al. Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models.arXiv preprint arXiv:2411.04996, 2024
Pith/arXiv arXiv 2024
-
[44]
S. Zhao, X. Zhang, J. Guo, J. Hu, L. Duan, M. Fu, Y . X. Chng, G.-H. Wang, Q.-G. Chen, Z. Xu, et al. Unified multimodal understanding and generation models: Advances, challenges, and opportunities.arXiv preprint arXiv:2505.02567, 2025
arXiv 2025
-
[45]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[46]
H.-S. Fang, H. Fang, Z. Tang, J. Liu, C. Wang, J. Wang, H. Zhu, and C. Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot.arXiv preprint arXiv:2307.00595, 2023
arXiv 2023
-
[47]
Banerjee, S
P. Banerjee, S. Shkodrani, P. Moulon, S. Hampali, S. Han, F. Zhang, L. Zhang, J. Fountain, E. Miller, S. Basol, et al. Hot3d: Hand and object tracking in 3d from egocentric multi-view videos. InCVPR, 2025
2025
-
[48]
Y . Luo, H. Chen, Z. Wu, B. Sui, J. Liu, C. Gu, Z. Liu, Q. Feng, J. Yu, S. Gu, et al. Look before acting: Enhancing vision foundation representations for vision-language-action models.arXiv preprint arXiv:2603.15618, 2026
arXiv 2026
-
[49]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[50]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[51]
Grauman, A
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InCVPR, 2024
2024
-
[52]
S. Yin, Y . Ze, H.-X. Yu, C. K. Liu, and J. Wu. Visualmimic: Visual humanoid loco- manipulation via motion tracking and generation.arXiv preprint arXiv:2509.20322, 2025. 11
arXiv 2025
-
[53]
S. Wei, H. Jing, B. Li, Z. Zhao, J. Mao, Z. Ni, S. He, J. Liu, X. Liu, K. Kang, et al.ψ 0: An open foundation model towards universal humanoid loco-manipulation.arXiv preprint arXiv:2603.12263, 2026
arXiv 2026
- [54]
-
[55]
X. Wang, T. Kwon, M. Rad, B. Pan, I. Chakraborty, S. Andrist, D. Bohus, A. Feniello, B. Tekin, F. V . Frujeri, et al. Holoassist: an egocentric human interaction dataset for interactive ai assis- tants in the real world. InICCV, 2023
2023
-
[56]
L. Xu, C. Yang, Z. Lin, F. Xu, Y . Liu, C. Xu, Y . Zhang, J. Qin, X. Sheng, Y . Liu, et al. Perceiving and acting in first-person: A dataset and benchmark for egocentric human-object- human interactions. InICCV, 2025
2025
-
[57]
X. Lin, X. Zhu, T. Lu, S. Xie, H. Zhang, X. Qiu, Z. Wu, and Y .-G. Jiang. Ask-to-clarify: Re- solving instruction ambiguity through multi-turn dialogue.arXiv preprint arXiv:2509.15061, 2025
Pith/arXiv arXiv 2025
-
[58]
washing a dish
I. Rodin, A. Furnari, D. Mavroeidis, and G. M. Farinella. Predicting the future from first person (egocentric) vision: A survey.CVIU, 2021. 12 A From Egocentric Video to Unified Action Space A.1 Metric Scale Recovery The camera trajectory recovered by VGGT is a scale-normalized path ˜T camk cam1 whose translational component is determined only up to a glo...
2021
-
[59]
The start time (in seconds, integer only)
-
[60]
The end time (in seconds, integer only)
-
[61]
pick up",
A concise description of the specific task being performed Each description must include: - The main manipulation action (a verb like "pick up", "place", "insert", "open", etc.) - A list of one or more objects that are being manipulated - A short natural language instruction generated from the action and objects The segments may overlap in time if multipl...
-
[62]
The action involves hand-object manipulation (e.g., pick up, cut, fold, assemble, insert, tighten, wipe, pour, etc.)
-
[63]
Exclude: body parts (leg, hand, arm), people (man, woman, person), natural materials (plant, soil, mud, grass, tree)
The object(s) must be artificial, physical items (tools, containers, utensils, electronics, furniture, fabric, household goods). Exclude: body parts (leg, hand, arm), people (man, woman, person), natural materials (plant, soil, mud, grass, tree)
-
[64]
clip_uid
The scene is likely indoors. Exclude: gardening, farming, outdoor repair, digging, planting, handling mud/branches/natural terrain. Return a JSON object: {"clip_uid": "...", "status": "success", "filtered_segments": [...]} Figure 13:Prompt used for LLM-based semantic filtering.The model retains only segments involving indoor hand-object manipulation of ar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.