Approximate Machine Unlearning through Manifold Representation Forgetting Guided by Self Mode Connectivity
Pith reviewed 2026-05-25 06:20 UTC · model grok-4.3
The pith
Machine unlearning is recast as pushing erased samples away from their original representation centroids toward semantic neighbors in retained data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Approximate unlearning reduces to manifold representation forgetting: each erased sample is driven away from its original centroid toward the nearest semantic neighbors among the retained data, with the required margins supplied by a self-mode-connectivity reconstruction of the local manifold.
What carries the argument
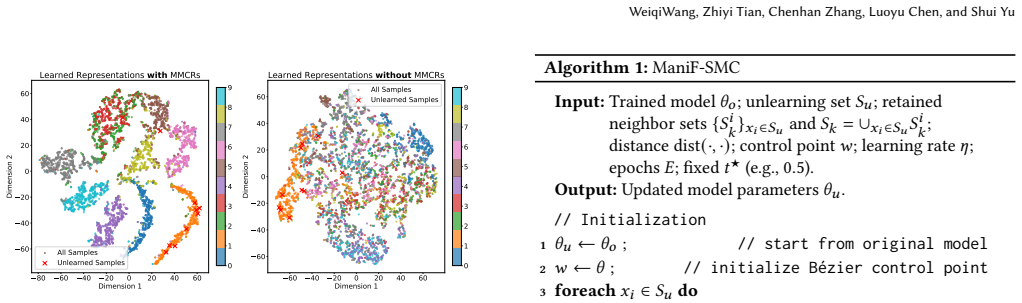
ManiF-SMC, a margin-based triplet loss whose adaptive margins are generated by a self-mode-connectivity module that reconstructs the local manifold around each unlearning request.
If this is right
- Unlearning no longer requires label flips or reversal of task-specific gradients.
- All operations stay inside the representation space, preserving the original learning objective.
- Adaptive margins derived from local manifold reconstruction replace hand-tuned thresholds.
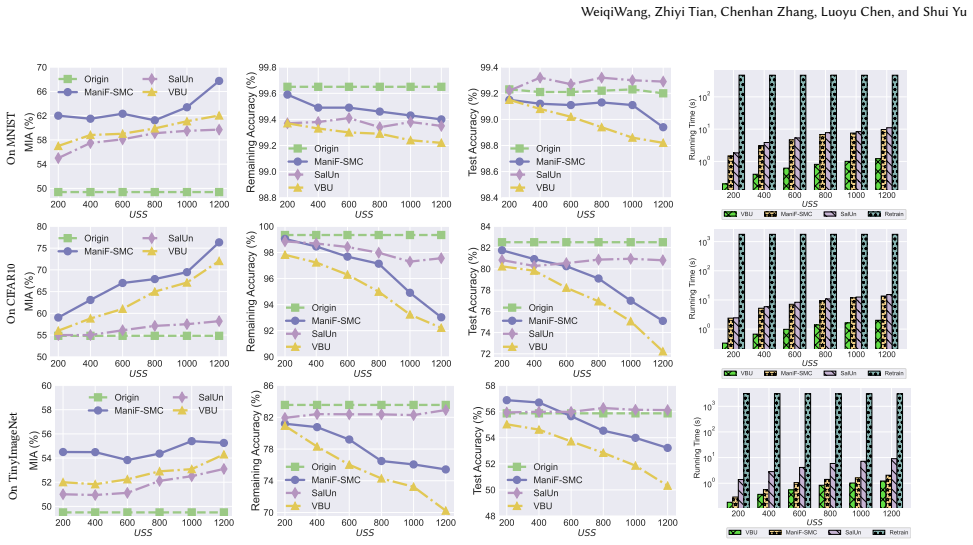
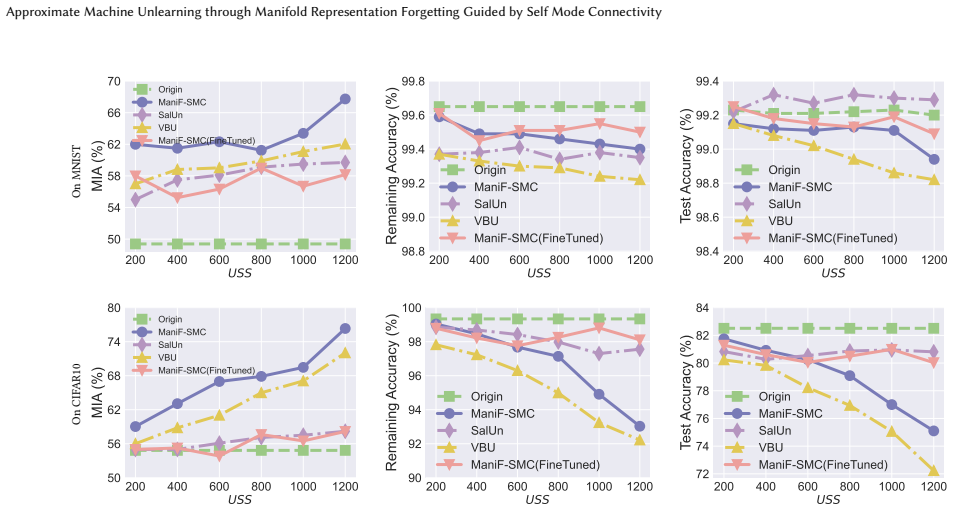
- Unlearning effectiveness on four standard datasets reaches parity with current approximate methods.
Where Pith is reading between the lines
- The same representation-space shift could be tested on sequential unlearning requests to see whether cumulative drift remains bounded.
- If the manifold reconstruction step scales linearly with the number of erased points, the method may become practical for large-scale data-deletion workloads.
- The triplet formulation naturally suggests extensions to multi-class or structured-output settings where semantic neighborhoods are defined by embedding proximity rather than class identity.
Load-bearing premise
A model retrained on the remaining data tends to classify erased samples according to their semantic similarity to the retained data.
What would settle it
A controlled retraining experiment in which erased samples are systematically assigned labels that do not match their nearest retained neighbors would falsify the central motivation.
Figures






read the original abstract
Machine unlearning is a fundamental mechanism that enforces the right to be forgotten. Existing unlearning studies that rely on label manipulation or task-gradient reversal often deliver limited unlearning effectiveness. Moreover, they can undermine the original learning objective and typically do not guarantee equivalence to standard unlearning by retraining. In this paper, we propose \textbf{ManiF-SMC} (\textbf{Mani}fold \textbf{F}orgetting with \textbf{S}elf \textbf{M}ode \textbf{C}onnectivity), motivated by the observation that a model retrained on the remaining data tends to classify erased samples by their semantic similarity to the retained data. We begin with systematically recasting the approximate unlearning as pushing each erased sample away from its original learned manifold representation centroid toward its nearest semantic neighbors in the retained data. This reformulation aligns unlearning with retraining behavior and operates purely in representation space, reducing reliance on labels and task-specific gradients. To tackle the manifold representation-based unlearning problem, ManiF-SMC encapsulates the unlearning and representation preservation goals in a margin-based triplet loss. Because finding a suitable margin for unlearning is challenging, we propose a self-mode-connectivity module that rapidly reconstructs the local manifold to guide the adaptive margins generation for each unlearning case. Extensive experiments on four representative datasets show that ManiF-SMC achieves unlearning effectiveness comparable to state-of-the-art approximate methods while operating solely within the model's representation space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ManiF-SMC for approximate machine unlearning. Motivated by the claim that a retrained model classifies erased samples according to semantic similarity with retained data, it recasts unlearning as pushing each erased sample away from its original manifold centroid toward nearest semantic neighbors in the retained set. This is implemented via a margin-based triplet loss in representation space, with a self-mode-connectivity module that reconstructs local manifolds to generate adaptive margins. Experiments on four datasets are reported to show unlearning effectiveness comparable to existing approximate methods while avoiding label manipulation and task gradients.
Significance. If the core observation and equivalence hold, the work would be significant for providing a purely representation-space unlearning procedure that reduces dependence on labels and gradients, potentially preserving utility better than reversal-based baselines. The self-mode-connectivity mechanism for adaptive margins is a concrete technical idea worth exploring. No machine-checked proofs or parameter-free derivations are present, but the label-free formulation is a clear strength if substantiated.
major comments (2)
- [Abstract / Motivation] Abstract and motivation section: the reformulation begins from the unverified observation that 'a model retrained on the remaining data tends to classify erased samples by their semantic similarity to the retained data.' No experiment, figure, or analysis in the manuscript validates this behavior on the four datasets (or in general). Because this assumption directly justifies the triplet-loss construction and the claimed alignment with retraining, its absence is load-bearing for the central claim of equivalence to standard unlearning.
- [Experiments] § on experimental validation (implied by 'extensive experiments'): the manuscript asserts comparability to SOTA approximate methods but provides no quantitative tables, metrics (e.g., unlearning effectiveness, accuracy on retained data), or ablation on the self-mode-connectivity module. Without these, the empirical support for the representation-space claim cannot be assessed.
minor comments (2)
- [Abstract] Abstract: the phrase 'four representative datasets' is used without naming them or reporting any numerical results, reducing clarity.
- [Abstract] Notation: 'manifold representation centroid' and 'self-mode-connectivity margin' are introduced without explicit definitions or equations in the provided abstract, making the technical description harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for empirical support of the core motivation and for detailed experimental reporting. We agree with both points and will revise the manuscript accordingly to strengthen the submission.
read point-by-point responses
-
Referee: [Abstract / Motivation] Abstract and motivation section: the reformulation begins from the unverified observation that 'a model retrained on the remaining data tends to classify erased samples by their semantic similarity to the retained data.' No experiment, figure, or analysis in the manuscript validates this behavior on the four datasets (or in general). Because this assumption directly justifies the triplet-loss construction and the claimed alignment with retraining, its absence is load-bearing for the central claim of equivalence to standard unlearning.
Authors: We agree that the motivating observation is presented without direct validation in the current manuscript and that this weakens the justification for the reformulation. In the revised version we will add a dedicated analysis subsection (with a supporting figure) that evaluates the classification behavior of a model retrained from scratch on the retained data when presented with erased samples, across all four datasets. This will explicitly test and report the semantic-similarity tendency, thereby grounding the triplet-loss construction. revision: yes
-
Referee: [Experiments] § on experimental validation (implied by 'extensive experiments'): the manuscript asserts comparability to SOTA approximate methods but provides no quantitative tables, metrics (e.g., unlearning effectiveness, accuracy on retained data), or ablation on the self-mode-connectivity module. Without these, the empirical support for the representation-space claim cannot be assessed.
Authors: We acknowledge that the current manuscript does not contain the quantitative tables, specific metrics, or ablations referenced by the referee. The revised manuscript will expand the experimental section to include (i) tables reporting unlearning effectiveness (e.g., membership inference attack success rates) and retained-set accuracy for all methods, (ii) direct numerical comparisons against the cited SOTA approximate unlearning baselines, and (iii) an ablation study isolating the contribution of the self-mode-connectivity module. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper proposes ManiF-SMC as a reformulation of approximate unlearning into a representation-space manifold forgetting task, motivated by an empirical observation about retrained model behavior on erased samples. No equations, derivations, or parameter-fitting steps are exhibited in the provided text that reduce by construction to the method's own inputs or prior self-citations. The central construction is presented as a new ansatz aligning with (but not derived from) retraining, and the self-mode-connectivity module is introduced as an additional component without load-bearing reduction to fitted values or renamed known results. This is a standard case of a self-contained methodological proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A model retrained on the remaining data tends to classify erased samples by their semantic similarity to the retained data
Reference graph
Works this paper leans on
-
[1]
Theo Bertram, Elie Bursztein, Stephanie Caro, Hubert Chao, Rutledge Chin Fe- man, Peter Fleischer, Albin Gustafsson, Jess Hemerly, Chris Hibbert, Luca In- vernizzi, et al. 2019. Five years of the right to be forgotten. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security . 959–972
work page 2019
-
[2]
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hen- grui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. Machine unlearning. In 2021 IEEE Symposium on Security and Privacy (SP) . IEEE, 141–159
work page 2021
-
[3]
Yinzhi Cao and Junfeng Yang. 2015. Towards making systems forget with machine unlearning. In 2015 IEEE Symposium on Security and Privacy . IEEE, 463–480
work page 2015
-
[4]
Min Chen, Weizhuo Gao, Gaoyang Liu, Kai Peng, and Chen Wang. 2023. Bound- ary unlearning: Rapid forgetting of deep networks via shifting the decision boundary. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7766–7775
work page 2023
-
[5]
Min Chen, Zhikun Zhang, Tianhao Wang, Michael Backes, Mathias Humbert, and Yang Zhang. 2021. When machine unlearning jeopardizes privacy. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security . 896–911
work page 2021
-
[6]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. In Inter- national conference on machine learning . PmLR, 1597–1607
work page 2020
-
[7]
Vikram S Chundawat, Ayush K Tarun, Murari Mandal, and Mohan Kankanhalli
-
[8]
In Proceedings of the AAAI Conference on Artificial Intelligence, Vol
Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 7210–7217
-
[9]
SueYeon Chung, Daniel D Lee, and Haim Sompolinsky. 2018. Classification and geometry of general perceptual manifolds. Physical Review X 8, 3 (2018), 031003
work page 2018
-
[10]
Li Deng. 2012. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE signal processing magazine 29, 6 (2012), 141–142
work page 2012
-
[11]
Ali Ebrahimpour-Boroojeny, Hari Sundaram, and Varun Chandrasekaran. 2025. Not All Wrong is Bad: Using Adversarial Examples for Unlearning. In Forty- second International Conference on Machine Learning
work page 2025
-
[12]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. 2024. SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation. InThe Twelfth International Conference on Learning Representations
work page 2024
-
[13]
Shaopeng Fu, Fengxiang He, and Dacheng Tao. 2022. Knowledge Removal in Sampling-based Bayesian Inference. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenRe- view.net
work page 2022
-
[14]
Elizabeth Gardner. 1988. The space of interactions in neural network models. Journal of physics A: Mathematical and general 21, 1 (1988), 257
work page 1988
-
[15]
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and An- drew G Wilson. 2018. Loss surfaces, mode connectivity, and fast ensembling of dnns. Advances in neural information processing systems 31 (2018)
work page 2018
-
[16]
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. 2020. Eternal sunshine of the spotless net: Selective forgetting in deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 9304–9312
work page 2020
-
[17]
Laura Graves, Vineel Nagisetty, and Vijay Ganesh. 2021. Amnesiac machine learning. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 35. 11516–11524
work page 2021
-
[18]
Hannun, and Laurens van der Maaten
Chuan Guo, Tom Goldstein, Awni Y. Hannun, and Laurens van der Maaten. 2020. Certified Data Removal from Machine Learning Models. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research, Vol. 119) . PMLR, 3832–3842
work page 2020
-
[19]
Danlan Huang, Feifei Gao, Xiaoming Tao, Qiyuan Du, and Jianhua Lu. 2022. Toward semantic communications: Deep learning-based image semantic coding. IEEE Journal on Selected Areas in Communications 41, 1 (2022), 55–71
work page 2022
-
[20]
Zachary Izzo, Mary Anne Smart, Kamalika Chaudhuri, and James Zou. 2021. Approximate data deletion from machine learning models. In International Con- ference on Artificial Intelligence and Statistics . PMLR, 2008–2016
work page 2021
-
[21]
Diederik P Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. stat 1050 (2014), 1
work page 2014
-
[22]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
work page 2009
-
[23]
Yann Le and Xuan Yang. 2015. Tiny imagenet visual recognition challenge. CS 231N 7, 7 (2015), 3
work page 2015
-
[24]
Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. 2020. Federated learning: Challenges, methods, and future directions. IEEE signal processing magazine 37, 3 (2020), 50–60
work page 2020
-
[25]
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2018. Large-scale celebfaces attributes (celeba) dataset. Retrieved August 15, 2018 (2018), 11
work page 2018
-
[26]
Alessandro Mantelero. 2013. The EU Proposal for a General Data Protection Regulation and the roots of the ‘right to be forgotten’.Comput. Law Secur. Rev. 29, 3 (2013), 229–235
work page 2013
-
[27]
Seth Neel, Aaron Roth, and Saeed Sharifi-Malvajerdi. 2021. Descent-to-delete: Gradient-based methods for machine unlearning. InAlgorithmic Learning Theory. PMLR, 931–962
work page 2021
-
[28]
Quoc Phong Nguyen, Bryan Kian Hsiang Low, and Patrick Jaillet. 2020. Varia- tional bayesian unlearning. Advances in Neural Information Processing Systems 33 (2020), 16025–16036
work page 2020
-
[29]
Quoc Phong Nguyen, Ryutaro Oikawa, Dinil Mon Divakaran, Mun Choon Chan, and Bryan Kian Hsiang Low. 2022. Markov Chain Monte Carlo-Based Machine Unlearning: Unlearning What Needs to be Forgotten. In ASIA CCS ’22: ACM Asia Conference on Computer and Communications Security, Nagasaki, Japan, 30 May 2022 - 3 June 2022 . ACM, 351–363
work page 2022
-
[30]
Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition . 815–823
work page 2015
-
[31]
Ayush Sekhari, Jayadev Acharya, Gautam Kamath, and Ananda Theertha Suresh
-
[32]
Advances in Neural Information Processing Systems 34 (2021)
Remember what you want to forget: Algorithms for machine unlearning. Advances in Neural Information Processing Systems 34 (2021)
work page 2021
-
[33]
Vedant Shah, Frederik Träuble, Ashish Malik, Hugo Larochelle, Michael Curtis Mozer, Sanjeev Arora, Yoshua Bengio, and Anirudh Goyal. 2025. Low Com- pute Unlearning via Sparse Representations. Transactions on Machine Learning Research (2025)
work page 2025
-
[34]
Shaofei Shen, Chenhao Zhang, Yawen Zhao, Alina Bialkowski, Weitong Tony Chen, and Miao Xu. 2024. Label-Agnostic Forgetting: A Supervision-Free Un- learning in Deep Models. In The Twelfth International Conference on Learning Representations
work page 2024
-
[35]
Liwei Song, Reza Shokri, and Prateek Mittal. 2019. Privacy risks of securing machine learning models against adversarial examples. In Proceedings of the 2019 ACM SIGSAC conference on computer and communications security . 241–257
work page 2019
-
[36]
Anvith Thudi, Gabriel Deza, Varun Chandrasekaran, and Nicolas Papernot. 2022. Unrolling sgd: Understanding factors influencing machine unlearning. In 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P) . IEEE, 303–319
work page 2022
-
[37]
Anvith Thudi, Hengrui Jia, Ilia Shumailov, and Nicolas Papernot. 2022. On the necessity of auditable algorithmic definitions for machine unlearning. In 31st USENIX Security Symposium (USENIX Security 22) . 4007–4022
work page 2022
-
[38]
Yuandong Tian, Xinlei Chen, and Surya Ganguli. 2021. Understanding self- supervised learning dynamics without contrastive pairs. In International Confer- ence on Machine Learning . PMLR, 10268–10278
work page 2021
-
[39]
Zhiyi Tian, Chenhan Zhang, Weiqi Wang, Hanna Bogucka, and Shui Yu. 2024. ROSE: A Receiver-Oriented Semantic Communication Framework. IEEE Network (2024)
work page 2024
-
[40]
Frederik Träuble, Anirudh Goyal, Nasim Rahaman, Michael Curtis Mozer, Kenji Kawaguchi, Yoshua Bengio, and Bernhard Schölkopf. 2023. Discrete key-value bottleneck. In International conference on machine learning . PMLR, 34431–34455
work page 2023
-
[41]
Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representa- tion learning through alignment and uniformity on the hypersphere. In Interna- tional conference on machine learning . PMLR, 9929–9939
work page 2020
-
[42]
Weiqi Wang, Chenhan Zhang, Zhiyi Tian, and Shui Yu. 2024. Machine Unlearning via Representation Forgetting With Parameter Self-Sharing. IEEE Transactions on Information Forensics and Security 19 (2024), 1099–1111
work page 2024
-
[43]
Alexander Warnecke, Lukas Pirch, Christian Wressnegger, and Konrad Rieck
-
[44]
31th Annual Network and Distributed System Security Symposium, NDSS 2024 (2024)
Machine unlearning of features and labels. 31th Annual Network and Distributed System Security Symposium, NDSS 2024 (2024)
work page 2024
-
[45]
Kilian Q Weinberger and Lawrence K Saul. 2009. Distance metric learning for large margin nearest neighbor classification.Journal of machine learning research 10, 2 (2009)
work page 2009
-
[46]
Yinjun Wu, Edgar Dobriban, and Susan Davidson. 2020. Deltagrad: Rapid re- training of machine learning models. In International Conference on Machine Learning. PMLR, 10355–10366
work page 2020
-
[47]
Haonan Yan, Xiaoguang Li, Ziyao Guo, Hui Li, Fenghua Li, and Xiaodong Lin
-
[48]
ARCANE: An Efficient Architecture for Exact Machine Unlearning. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelli- gence, IJCAI 2022, Vienna, Austria, 23-29 July 2022 , Luc De Raedt (Ed.). ijcai.org, 4006–4013
work page 2022
-
[49]
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. 2018. Privacy risk in machine learning: Analyzing the connection to overfitting. In 2018 IEEE 31st computer security foundations symposium (CSF) . IEEE, 268–282
work page 2018
-
[50]
Thomas Yerxa, Yilun Kuang, Eero Simoncelli, and SueYeon Chung. 2023. Learning efficient coding of natural images with maximum manifold capacity representa- tions. Advances in Neural Information Processing Systems 36 (2023), 24103–24128
work page 2023
-
[51]
Pu Zhao, Pin-Yu Chen, Payel Das, Karthikeyan Natesan Ramamurthy, and Xue Lin. 2020. Bridging Mode Connectivity in Loss Landscapes and Adversarial Robustness. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 . OpenReview.net. WeiqiWang, Zhiyi Tian, Chenhan Zhang, Luoyu Chen, and Shui Yu 80 60 ...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.