Temporal Preference Optimization for Unsupervised Retrieval
Pith reviewed 2026-06-26 22:50 UTC · model grok-4.3
The pith
TPOUR lets unsupervised retrievers capture temporal relevance by reinterpreting preference optimization along the time axis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
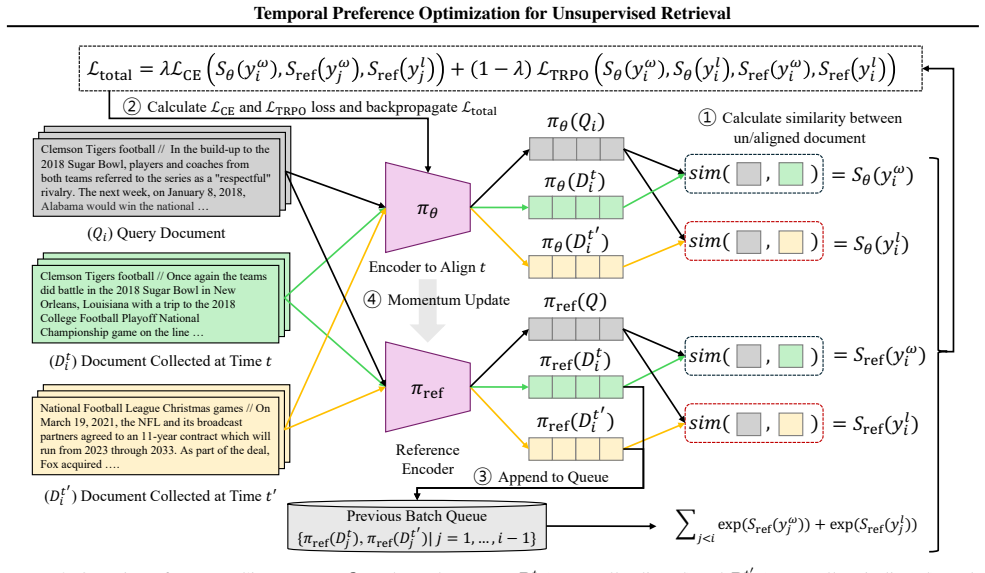
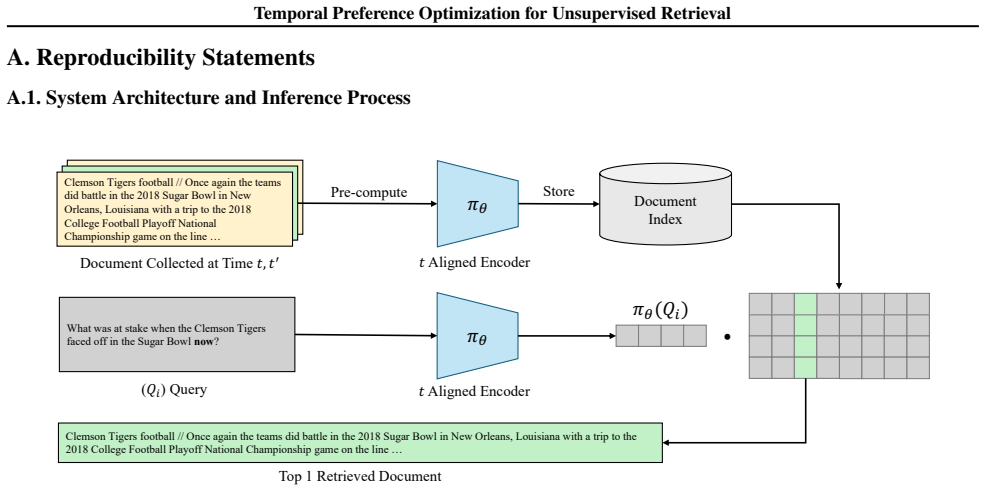
TPOUR uses Temporal Retrieval Preference Optimization (TRPO) to reinterpret preference learning in the temporal dimension, guiding the retriever to favor temporally aligned documents, and further generalizes to unseen time periods via interpolation in a learned time embedding.
What carries the argument
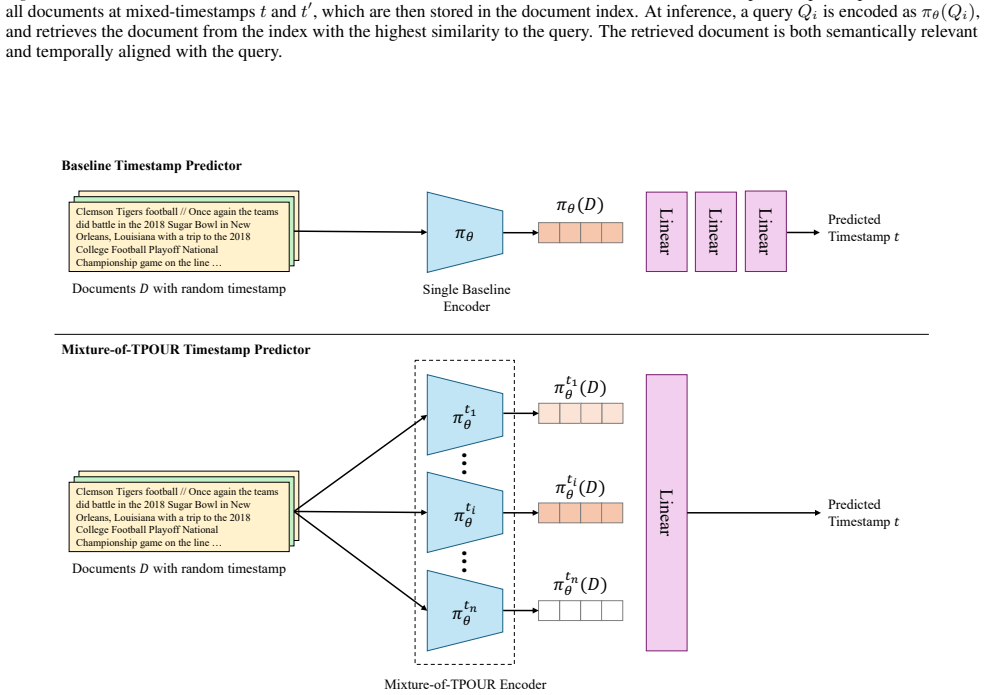
Temporal Retrieval Preference Optimization (TRPO), which reinterprets preference learning along the temporal dimension to align retrieved documents with query time periods.
If this is right
- TPOUR outperforms both unsupervised and supervised baselines on temporal information retrieval tasks.
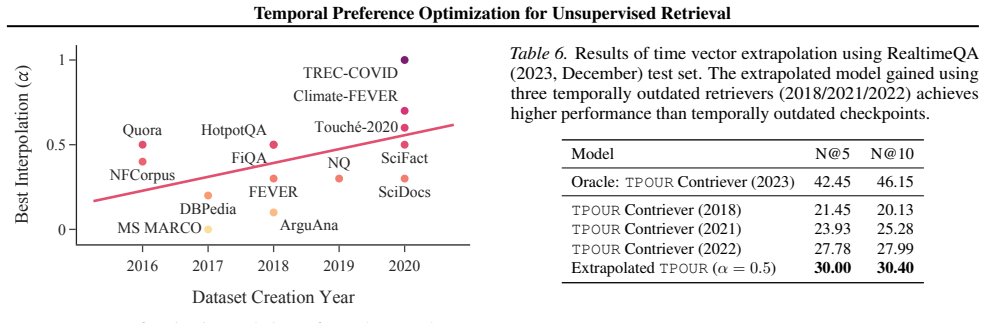
- A model roughly 72 times smaller than Qwen-Embedding-8B improves average nDCG@5 by +4.04 on explicit and +4.98 on implicit temporal queries.
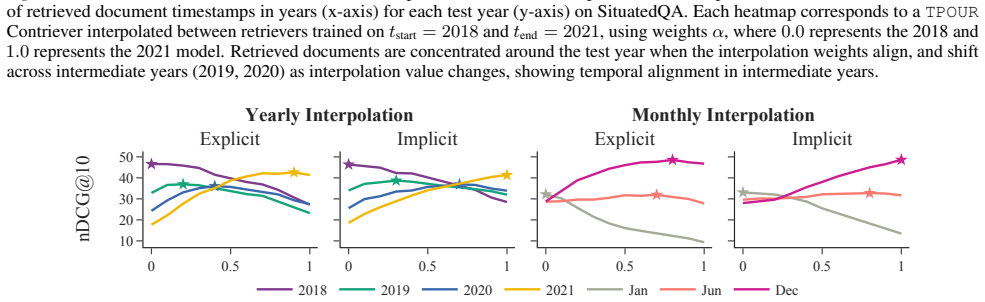
- The learned time embedding supports continuous temporal alignment for time periods absent from the training data.
- The same training procedure works without any explicit timestamp labels on the documents.
Where Pith is reading between the lines
- The same temporal reinterpretation of preferences could be applied to other contrastive objectives to improve time-aware retrieval in news archives or scientific literature.
- Measuring performance degradation as the gap between training and test time periods increases would test the limits of the interpolation mechanism.
- Extending the time embedding to handle queries that mention multiple distinct time periods would require combining several interpolated vectors.
Load-bearing premise
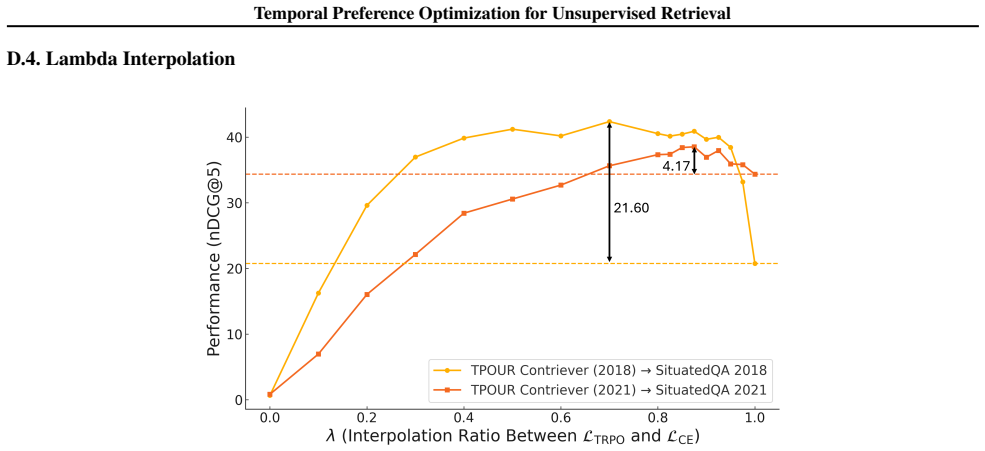
The assumption that reinterpreting preference learning along the temporal dimension can reliably guide the retriever toward temporally aligned documents and that interpolation in a learned time embedding will generalize to unseen time periods.
What would settle it
Run the trained model on a set of temporal queries whose target time periods lie outside the range of any timestamps seen during training and check whether nDCG drops sharply relative to in-distribution queries.
Figures


read the original abstract
Unsupervised dense retrievers offer scalability by learning semantic similarity from unlabeled documents via contrastive learning, but they struggle to capture the temporal relevance, retrieving semantically related but temporally misaligned documents-an important aspect when a document collection spans multiple time periods (e.g., retrieving documents from 2018-2025 for "Who is the president in 2019?" introduces temporal ambiguity). Existing methods rely on supervised training with explicit timestamps, which are not always feasible. We propose TPOUR (Temporal Preference Optimization for Unsupervised Retriever), which uses our novel training method Temporal Retrieval Preference Optimization (TRPO). TRPO reinterprets preference learning in the temporal dimension, guiding the retriever to favor temporally aligned documents. TPOUR further generalizes to unseen time periods via interpolation in a learned time embedding, enabling continuous temporal alignment. Experiments on temporal information retrieval (T-IR), TPOUR outperforms both unsupervised and supervised baselines. Compared to Qwen-Embedding-8B, despite being about 72.7x smaller, TPOUR Contriever improves average nDCG@5 by +4.04 (+12.15%) on explicit and +4.98 (+15.21%) on implicit queries. We provide our code at https://github.com/agwaBom/TPOUR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TPOUR, a method for unsupervised dense retrieval that employs Temporal Retrieval Preference Optimization (TRPO) to reinterpret preference learning along the temporal dimension, thereby guiding retrievers to favor temporally aligned documents from unlabeled data. TPOUR incorporates a learned time embedding to enable interpolation and generalization to unseen time periods. On temporal information retrieval (T-IR) tasks, the method is reported to outperform both unsupervised and supervised baselines, with TPOUR Contriever achieving average nDCG@5 gains of +4.04 (+12.15%) on explicit queries and +4.98 (+15.21%) on implicit queries relative to the much larger Qwen-Embedding-8B model.
Significance. If the central claims hold after verification, the work would be significant for advancing unsupervised retrieval in temporally dynamic collections without requiring explicit timestamps or supervision, addressing a practical limitation of standard contrastive approaches. The code release at the provided GitHub link is a positive factor for reproducibility.
major comments (3)
- [Abstract] Abstract: the description of TRPO states that it 'reinterprets preference learning in the temporal dimension' and 'generalizes to unseen time periods via interpolation' but supplies no derivation, pair-construction procedure, or example demonstrating how contrastive pairs encode temporal order (rather than semantic similarity) from document semantics alone.
- [Abstract] Abstract / Experiments section: the headline outperformance claims (+4.04 and +4.98 nDCG@5) are presented without reported variance, number of runs, statistical tests, or controls for potential metadata correlations in the unlabeled data, which is load-bearing for the assertion that the method remains unsupervised while surpassing supervised baselines.
- [Abstract] Abstract: no ablation or held-out-period validation is described to test the assumption that interpolation in the learned time embedding (rather than semantic cues alone) drives the reported gains on implicit queries, leaving the generalization claim unverified.
minor comments (2)
- [Abstract] The abstract refers to 'T-IR' tasks and 'explicit' vs. 'implicit' queries without defining these terms or citing the specific datasets and query construction process used in the experiments.
- The manuscript states that code is provided at https://github.com/agwaBom/TPOUR but does not specify the contents (e.g., training scripts, hyper-parameters, or evaluation code) in the text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and note the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description of TRPO states that it 'reinterprets preference learning in the temporal dimension' and 'generalizes to unseen time periods via interpolation' but supplies no derivation, pair-construction procedure, or example demonstrating how contrastive pairs encode temporal order (rather than semantic similarity) from document semantics alone.
Authors: The abstract summarizes the approach at a high level. Section 3 of the manuscript provides the full derivation of TRPO, the pair-construction procedure that infers temporal order from document semantics in unlabeled data, and concrete examples. We will add a brief illustrative example to the abstract to clarify how contrastive pairs capture temporal alignment rather than pure semantic similarity. revision: yes
-
Referee: [Abstract] Abstract / Experiments section: the headline outperformance claims (+4.04 and +4.98 nDCG@5) are presented without reported variance, number of runs, statistical tests, or controls for potential metadata correlations in the unlabeled data, which is load-bearing for the assertion that the method remains unsupervised while surpassing supervised baselines.
Authors: We agree these details strengthen the claims. We will revise the experiments section to report results across multiple runs with different seeds, include standard deviations and statistical significance tests. We will also add an analysis checking for potential metadata correlations in the unlabeled data to support the unsupervised nature of the gains. revision: yes
-
Referee: [Abstract] Abstract: no ablation or held-out-period validation is described to test the assumption that interpolation in the learned time embedding (rather than semantic cues alone) drives the reported gains on implicit queries, leaving the generalization claim unverified.
Authors: Section 4 contains ablations on the time embedding component. We acknowledge that explicit held-out-period validation would better isolate the contribution of interpolation. We will add such an experiment in the revision to verify that the learned time embedding drives gains on implicit queries beyond semantic cues. revision: yes
Circularity Check
No circularity: new training procedure presented without reduction to fitted inputs or self-citations
full rationale
The paper introduces TPOUR and its TRPO training method as a novel reinterpretation of preference learning along the temporal dimension for unsupervised retrievers, with generalization via interpolation in a learned time embedding. The provided abstract and description contain no equations, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. The central claims rest on the proposed method's construction rather than any self-referential reduction, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: https://doi.org/10.1016/j.knosys.2013.03
-
[2]
URL https://www.sciencedirect.com/ science/article/pii/S0950705113001044. Brin, S. and Page, L. The anatomy of a large-scale hypertextual web search engine.Computer Networks and ISDN Systems, 30(1):107–117, 1998. ISSN 0169-7552. doi: https://doi.org/10.1016/S0169-7552(98)00110-X. URL https://www.sciencedirect.com/ science/article/pii/S016975529800110X. Pr...
-
[3]
Retrieval-Augmented Generation for Large Language Models: A Survey
Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.552. URL https:// aclanthology.org/2021.emnlp-main.552. Gao, Y ., Xiong, Y ., Gao, X., Jia, K., Pan, J., Bi, Y ., Dai, Y ., Sun, J., Wang, M., and Wang, H. Retrieval-augmented 10 Temporal Preference Optimization for Unsupervised Retrieval generation for large language models: A su...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.emnlp-main.552 2021
-
[4]
He, K., Fan, H., Wu, Y ., Xie, S., and Girshick, R
URL https://proceedings.mlr.press/ v119/guu20a.html. He, K., Fan, H., Wu, Y ., Xie, S., and Girshick, R. Mo- mentum contrast for unsupervised visual representation learning. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9726–9735,
-
[5]
doi: 10.1109/CVPR42600.2020.00975. Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bo- janowski, P., Joulin, A., and Grave, E. Unsupervised dense information retrieval with contrastive learning. Trans. Mach. Learn. Res., 2022, 2022. URL https: //openreview.net/forum?id=jKN1pXi7b0. Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D. P., and Wilson, A....
-
[6]
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.550. URL https:// aclanthology.org/2020.emnlp-main.550. Kasai, J., Sakaguchi, K., takahashi, y., Le Bras, R., Asai, A., Yu, X., Radev, D., Smith, N. A., Choi, Y ., and Inui, K. Realtime qa: What's the answer right now? In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., ...
-
[7]
cc/paper_files/paper/2023/file/ 11 Temporal Preference Optimization for Unsupervised Retrieval 9941624ef7f867a502732b5154d30cb7- Paper-Datasets_and_Benchmarks.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ 11 Temporal Preference Optimization for Unsupervised Retrieval 9941624ef7f867a502732b5154d30cb7- Paper-Datasets_and_Benchmarks.pdf. Kwon, M., Bang, J., Hwang, S., Jang, J., and Lee, W. A dynamic-selection-based, retrieval-augmented genera- tion framework: Enhancing multi-document question- a...
2023
-
[8]
cc/paper_files/paper/2021/file/ f5bf0ba0a17ef18f9607774722f5698c- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ f5bf0ba0a17ef18f9607774722f5698c- Paper.pdf. Lee, K., Chang, M.-W., and Toutanova, K. Latent retrieval for weakly supervised open domain question answering. In Korhonen, A., Traum, D., and M `arquez, L. (eds.), Proceedings of the 57th Annual Meeting of the Asso- ciation for Computational Lin...
-
[9]
Towards General Text Embeddings with Multi-stage Contrastive Learning
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 6b493230205f780e1bc26945df7481e5- Paper.pdf. Li, X., Jin, J., Zhou, Y ., Zhang, Y ., Zhang, P., Zhu, Y ., and Dou, Z. From matching to generation: A survey on generative information retrieval.ACM Trans. Inf. Syst., March 2025. ISSN 1046-8188. doi: 10.1145/3722552. URLhttps://doi.org/10.1145/...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3722552 2020
-
[10]
Text and Code Embeddings by Contrastive Pre-Training
URL https://aclanthology.org/2023. emnlp-main.322/. Neelakantan, A., Xu, T., Puri, R., Radford, A., Han, J. M., Tworek, J., Yuan, Q., Tezak, N., Kim, J. W., Hallacy, C., Heidecke, J., Shyam, P., Power, B., Nekoul, T. E., Sastry, G., Krueger, G., Schnurr, D., Such, F. P., Hsu, K., Thompson, M., Khan, T., Sherbakov, T., Jang, J., Welinder, P., and Weng, L. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/ 2023
-
[11]
cc/paper_files/paper/2022/file/ b1efde53be364a73914f58805a001731- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ b1efde53be364a73914f58805a001731- Paper-Conference.pdf. Qian, X., Zhang, Y ., Zhao, Y ., Zhou, B., Sui, X., Zhang, L., and Song, K. TimeR 4 : Time-aware retrieval- augmented large language models for temporal knowl- edge graph question answering. In Al-Onaizan, Y ., Bansal, M., and Chen, Y ....
-
[12]
cc/paper_files/paper/2023/file/ a85b405ed65c6477a4fe8302b5e06ce7- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ a85b405ed65c6477a4fe8302b5e06ce7- Paper-Conference.pdf. Rame, A., Ahuja, K., Zhang, J., Cord, M., Bottou, L., and Lopez-Paz, D. Model ratatouille: Recycling di- verse models for out-of-distribution generalization. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlet...
2023
-
[13]
URL https://proceedings.mlr.press/ v202/rame23a.html. Robertson, S. and Zaragoza, H. The probabilistic relevance framework: Bm25 and beyond.Found. Trends Inf. Retr., 3(4):333–389, apr 2009. ISSN 1554-0669. doi: 10.1561/ 1500000019. URL https://doi.org/10.1561/ 1500000019. Rosin, G. D., Guy, I., and Radinsky, K. Time mask- ing for temporal language models....
-
[14]
Thakur, N., Reimers, N., R ¨uckl´e, A., Srivastava, A., and Gurevych, I
Accessed: 2026-01-27. Thakur, N., Reimers, N., R ¨uckl´e, A., Srivastava, A., and Gurevych, I. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Thirty-fifth Conference on Neural Information Process- ing Systems Datasets and Benchmarks Track (Round 2),
2026
-
[15]
Wang, C., Jiang, Y ., Yang, C., Liu, H., and Chen, Y
URL https://openreview.net/forum? id=wCu6T5xFjeJ. Wang, C., Jiang, Y ., Yang, C., Liu, H., and Chen, Y . Beyond reverse KL: generalizing direct preference optimization with diverse divergence constraints. InThe Twelfth Inter- national Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024a. URL https://ope...
-
[16]
URL https://proceedings.mlr.press/ v235/xiong24a.html. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.aiopen.2022.12 2025
-
[17]
URL https://www.sciencedirect.com/ science/article/pii/S2666651022000249. 15 Temporal Preference Optimization for Unsupervised Retrieval Zhang, M. and Choi, E. SituatedQA: Incorporating extra- linguistic contexts into QA. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.),Proceedings of the 2021 Conference on Empirical Methods in Natural Lan...
-
[18]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
doi: 10.1145/3285029. URL https://doi. org/10.1145/3285029. Zhang, Y ., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., Huang, F., and Zhou, J. Qwen3 embedding: Advancing text embedding and reranking through foundation models, 2025. URL https://arxiv.org/abs/2506.05176. Zhao, P., Zhang, H., Yu, Q., Wang, Z., Geng, Y .,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3285029 2025
-
[19]
If the actual document update with temporal change is too small relative to noise, TRPO learning could be unstable
Temporal preference margin.There must be a certain temporal preference gap (i.e., margin) between aligned and misaligned document E[S(Q, Dt)−S(Q, D t′ )]> δ when t′ ̸=t where δ is a minimum gap required. If the actual document update with temporal change is too small relative to noise, TRPO learning could be unstable. To handle this issue, we comprise a t...
-
[20]
Similar semantic across corpora.Aligned and misaligned temporal corpora should cover a similar set of topics, so semantic similarity may remain high and the only difference is the timestamp and the document content at that timestamp
-
[21]
generation quality
Model capacity.Encoder should have sufficient capacity to represent latent temporal signal as well as semantic similarity. Under these conditions, TRPO encourages the model to rank temporally aligned documents higher. The resulting scoring function Sθ is expected to approximate one that reflects temporal alignment between query and document. This mirrors ...
2024
-
[22]
They also introduced the concept of document focus time, which refers to the temporal period indicated by the document content and is distinct from its creation time
proposed a re-ranking method that utilizes archived web snapshots to prioritize documents based on content freshness and relevance. They also introduced the concept of document focus time, which refers to the temporal period indicated by the document content and is distinct from its creation time. Additionally, they proposed a method to automatically esti...
2013
-
[23]
They further proposed the first machine learning framework capable of automatically selecting the most effective temporal ranking strategy for a given query (Kanhabua et al., 2012)
developed methods for determining the time of implicit temporal queries by leveraging temporal language models trained on timestamped corpora. They further proposed the first machine learning framework capable of automatically selecting the most effective temporal ranking strategy for a given query (Kanhabua et al., 2012). C.2. Baseline Models DPR (Dense ...
2012
-
[24]
Identify the temporal intent of the query
-
[25]
Filter or downweight documents that violate the temporal constraint
-
[26]
Rank documents by both semantic relevance and temporal alignment
-
[27]
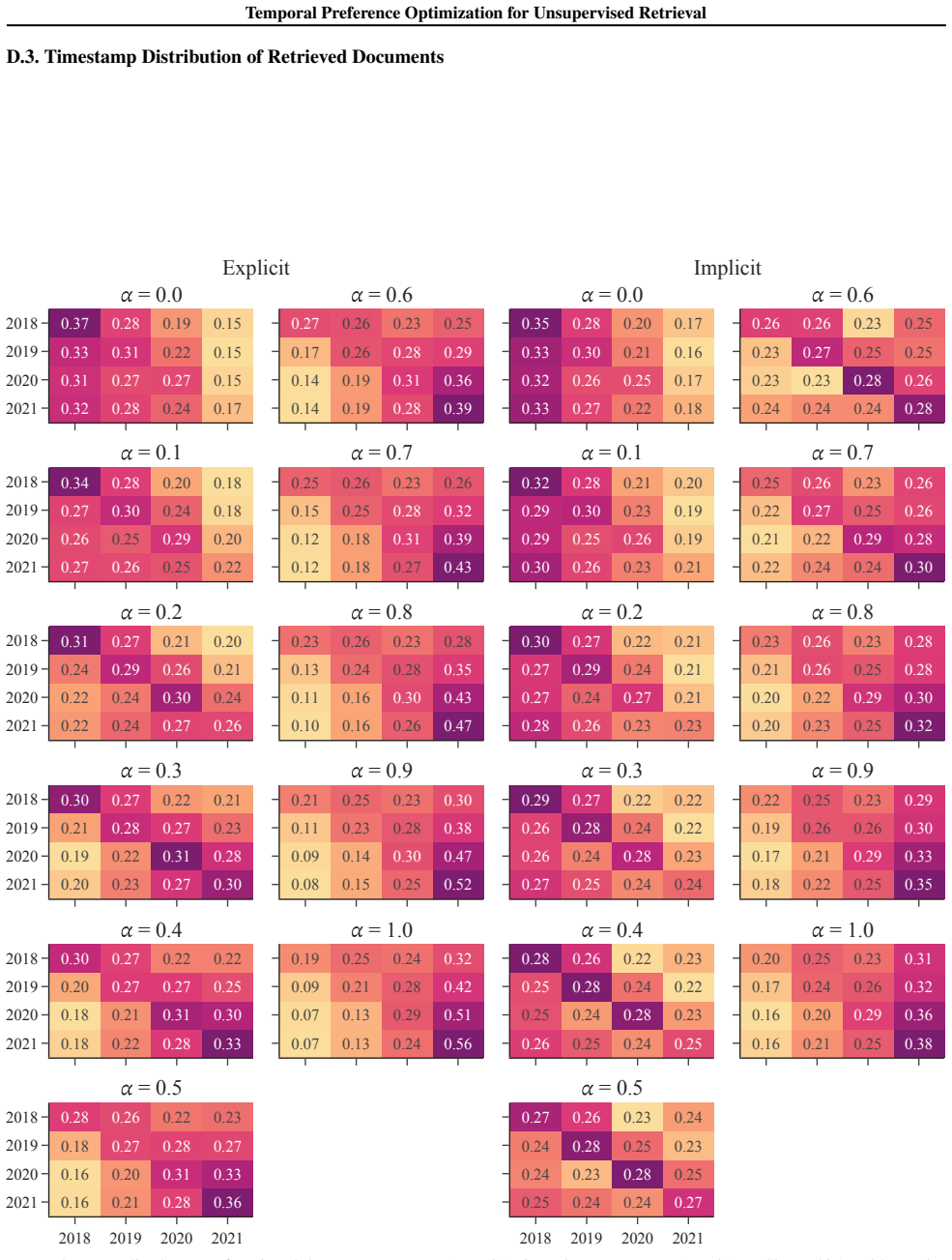
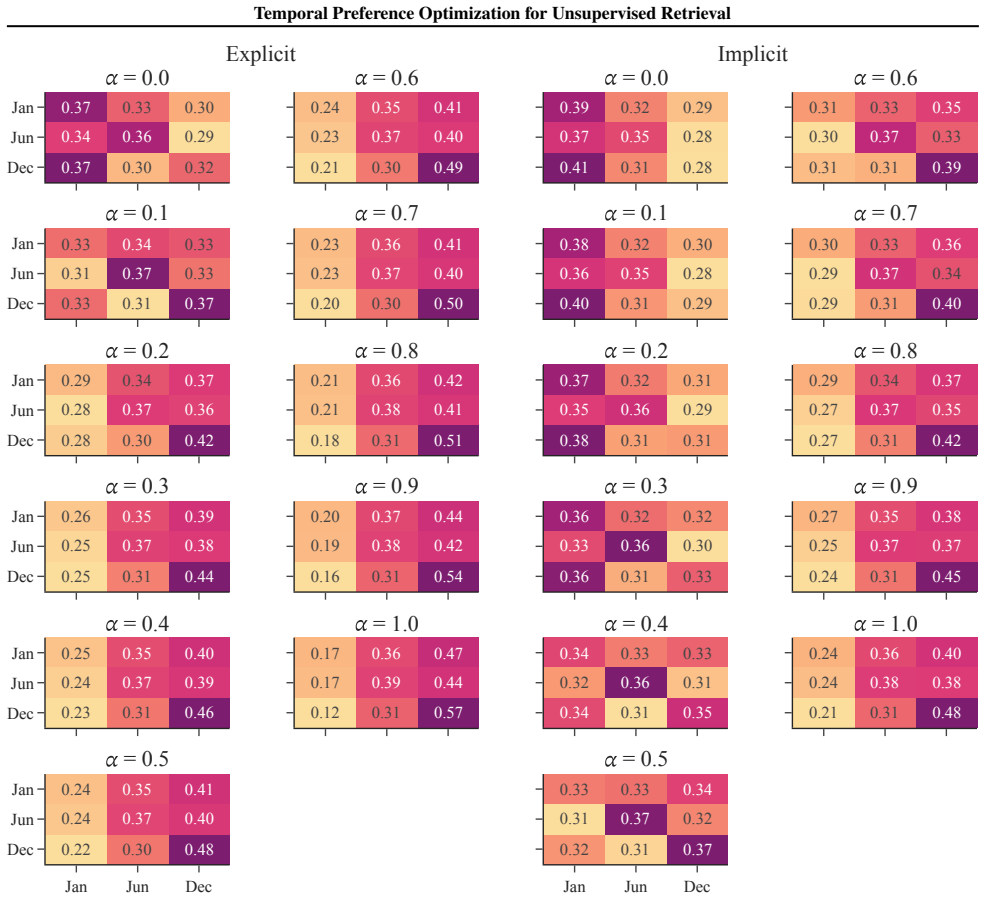
Prefer documents whose timestamps are closest to, but not exceeding, the target time. Query:{QUERY} 21 Temporal Preference Optimization for Unsupervised Retrieval D. Additional Experimental Results & Analysis D.1. Full Results on BEIR Benchmark Table 11.Retrieval performance (nDCG@10) on the BEIR benchmark, with dataset publication years shown below each ...
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.