Enabling Cloud-Level Accuracy in Edge AI through IoT Data Preprocessing
Pith reviewed 2026-06-26 09:31 UTC · model grok-4.3
The pith
Enriched prompts raise local LLM accuracy on IoT queries from 51% to 82% indoors and 64% to 89% outdoors
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
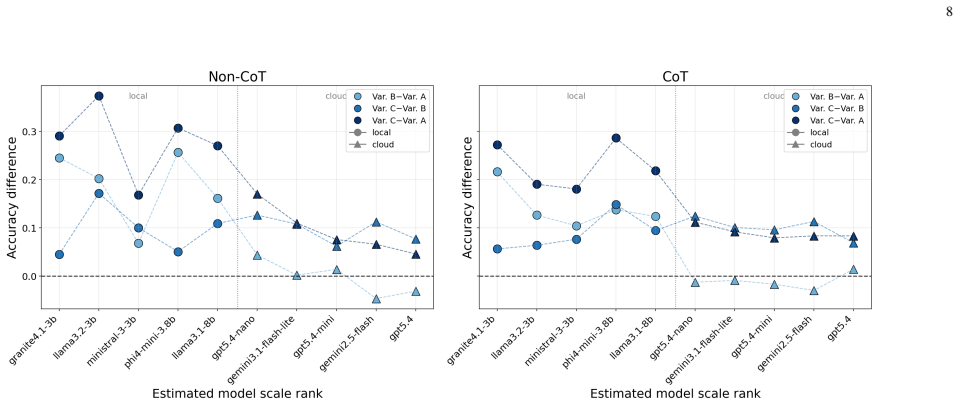
The central claim is that a structured prompt construction framework which transforms raw air-quality and thermal-comfort measurements into progressively enriched textual representations (raw values, threshold-aware descriptions, compact summary flags) substantially improves the accuracy of compact local LLMs on binary environmental queries, raising No-CoT accuracy from 50.9% to 81.7% indoors and from 63.7% to 89.3% outdoors while keeping mean latency near 0.22 seconds.
What carries the argument
The structured prompt construction framework that converts raw sensor values into threshold-aware descriptions and compact environmental summary flags
If this is right
- Local No-CoT inference with the richest prompts becomes the fastest accurate option for real-time IoT analytics.
- The accuracy gap between local and cloud models narrows enough that cloud offloading is no longer required for many monitoring tasks.
- The same enrichment pattern works on both indoor Raspberry Pi/BME680 data and outdoor data from Helsinki, Katowice, and Warsaw.
- Chain-of-thought prompting increases latency without delivering proportional accuracy gains once prompts are already enriched.
Where Pith is reading between the lines
- The preprocessing steps could be reused for other sensor streams such as occupancy or energy use without changing the overall structure.
- If the thresholds prove sensitive to the exact dataset, the method may need an automatic threshold-selection step before deployment.
- The approach might allow smaller edge hardware to suffice, since enriched prompts compensate for weaker numerical reasoning in compact models.
Load-bearing premise
The binary query dataset and chosen threshold rules fairly represent the real-world interpretation tasks that IoT systems must solve.
What would settle it
Evaluating the same local models on a fresh collection of queries whose thresholds were chosen independently of the test data, or on queries that require multi-class rather than binary answers, would show whether the accuracy gains remain.
Figures



read the original abstract
Large language models (LLMs) offer a natural-language interface for interpreting Internet of Things (IoT) sensor data in smart environments; however, cloud deployment introduces latency, privacy, and connectivity concerns. Local LLMs can reduce these limitations, but compact edge-deployable models often show weaker numerical reasoning when raw sensor readings are provided directly. This paper investigates whether prompt-side preprocessing can improve the accuracy-latency trade-off of local LLMs for environmental monitoring. We propose a structured prompt construction framework that transforms raw air-quality and thermal-comfort measurements into progressively enriched textual representations: raw sensor values, threshold-aware descriptions, and compact environmental summary flags. The approach is evaluated using indoor Raspberry Pi/BME680 datasets from Tampere University and outdoor air-quality datasets from Helsinki, Katowice, and Warsaw. We construct a binary LLM query dataset covering air quality, thermal comfort, and joint environmental conditions, and evaluate five local and five cloud LLMs across three prompt variants and two inference modes, with and without chain-of-thought prompting. Results show that prompt enrichment substantially improves local-model accuracy. In No-CoT mode, local accuracy increases from 50.9% to 81.7% indoors and from 63.7% to 89.3% outdoors from the raw to the most enriched prompt. Local No-CoT inference is the fastest configuration, with mean latency close to 0.22 s, while CoT substantially increases inference time. These findings suggest that lightweight prompt-side preprocessing can narrow the local--cloud performance gap and support low-latency IoT analytics in smart environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a structured prompt enrichment framework—transforming raw IoT sensor readings into threshold-aware descriptions and compact summary flags—substantially raises the accuracy of local LLMs on binary environmental queries (air quality, thermal comfort) while preserving low latency. On indoor (Tampere) and outdoor (Helsinki/Katowice/Warsaw) datasets, local No-CoT accuracy rises from 50.9% to 81.7% indoors and 63.7% to 89.3% outdoors when moving from raw values to the most enriched prompt; the work evaluates five local and five cloud models across three prompt variants and two inference modes.
Significance. If the reported gains reflect genuine improvements in local LLM reasoning rather than artifacts of the preprocessing pipeline, the result would be significant for edge AI in IoT settings: it offers a lightweight, low-latency alternative to cloud offloading that narrows the accuracy gap without requiring larger models or additional hardware. The multi-model, multi-dataset empirical evaluation provides a concrete starting point for follow-on work on prompt-side preprocessing.
major comments (2)
- [Abstract] Abstract: the central accuracy claims (50.9% → 81.7% indoors, 63.7% → 89.3% outdoors in No-CoT) are presented without statistical tests, confidence intervals, or error bars on the reported percentages. This omission is load-bearing because the binary query dataset construction is not described; without these diagnostics it is impossible to exclude post-hoc selection or threshold-tuning effects that could inflate the observed deltas.
- [Abstract] Abstract / evaluation description: no information is given on how the binary LLM query dataset was generated or on the provenance and selection procedure for the thresholds used to produce the enriched descriptions and flags. If the queries were derived from the same threshold rules applied in preprocessing, the enrichment step directly encodes the target labels; the measured accuracy gain would then reflect the external rule engine rather than any enhancement of the LLM’s internal numerical reasoning on raw sensor values.
minor comments (2)
- [Abstract] The abstract states that five local and five cloud models were evaluated but does not name the specific models or their parameter counts; adding this list would improve reproducibility.
- [Abstract] The latency figure (mean 0.22 s for local No-CoT) is given without variance or hardware details (Raspberry Pi model, quantization level); a small table or footnote would clarify the measurement conditions.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We address the major comments point-by-point below. We will revise the manuscript to incorporate additional details and statistical analyses as suggested.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central accuracy claims (50.9% → 81.7% indoors, 63.7% → 89.3% outdoors in No-CoT) are presented without statistical tests, confidence intervals, or error bars on the reported percentages. This omission is load-bearing because the binary query dataset construction is not described; without these diagnostics it is impossible to exclude post-hoc selection or threshold-tuning effects that could inflate the observed deltas.
Authors: We agree that statistical tests, confidence intervals, and error bars are important for substantiating the accuracy claims. In the revised manuscript, we will include these diagnostics for the reported percentages. We will also expand the description of the binary query dataset construction to address concerns about potential post-hoc selection or threshold-tuning effects. revision: yes
-
Referee: [Abstract] Abstract / evaluation description: no information is given on how the binary LLM query dataset was generated or on the provenance and selection procedure for the thresholds used to produce the enriched descriptions and flags. If the queries were derived from the same threshold rules applied in preprocessing, the enrichment step directly encodes the target labels; the measured accuracy gain would then reflect the external rule engine rather than any enhancement of the LLM’s internal numerical reasoning on raw sensor values.
Authors: We acknowledge that the manuscript does not provide sufficient information on the generation of the binary LLM query dataset or the selection of thresholds. In the revision, we will add a detailed account of the query dataset construction and the provenance of the thresholds. This will allow for an evaluation of whether the enrichment directly encodes the labels or supports improved LLM performance. revision: yes
Circularity Check
No circularity; purely empirical measurements on explicit prompt variants
full rationale
The paper reports direct accuracy measurements comparing raw sensor values against threshold-based textual enrichments fed to LLMs on a constructed binary query set. No equations, derivations, fitted parameters, or self-citations are invoked as load-bearing steps that reduce the reported accuracy gains to the inputs by construction. The evaluation uses held-out prompt variants and multi-location datasets, with preprocessing rules stated explicitly rather than learned from the test queries themselves. This is a standard experimental comparison without any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The binary query dataset and threshold rules are representative of real IoT interpretation tasks
Reference graph
Works this paper leans on
-
[1]
Smart lab: An iot-centric approach for indoor environment automation,
J. G. A. de Carvalho, A. A. da Conceic ¸˜ao, L. P. Ambr´osio, F. Fernandes, E. H. T. Ramborger, G. P. Aquino, and E. C. V . Boas, “Smart lab: An iot-centric approach for indoor environment automation,”Journal of Communication and Information Systems, vol. 39, no. 1, p. 82, 2024
2024
-
[2]
Creation of ai-driven smart spaces for enhanced indoor environments–a survey,
A. Varol, N. H. Motlagh, M. Leino, S. Tarkoma, and J. Virkki, “Creation of ai-driven smart spaces for enhanced indoor environments–a survey,” Internet of Things, p. 101876, 2026
2026
-
[3]
A general ai agent framework for smart buildings based on large language models and react strategy,
X. Yan, X. Yang, N. Jin, Y . Chen, and J. Li, “A general ai agent framework for smart buildings based on large language models and react strategy,”Smart Construction, vol. 2, no. 1, 2025. [Online]. Available: https://doi.org/10.55092/sc20250004
-
[4]
Revolutionizing indoor air quality monitoring through iot innovations: a comprehensive systematic review and bibliometric analysis,
H. Tan, M. H. D. Othman, H. Y . Kek, W. T. Chong, B. B. Nyakuma, R. A. Wahab, G. L. H. Teck, and K. Y . Wong, “Revolutionizing indoor air quality monitoring through iot innovations: a comprehensive systematic review and bibliometric analysis,”Environmental Science and Pollution Research, vol. 31, no. 32, pp. 44 463–44 488, 2024
2024
-
[5]
Digital twins for smart spaces—beyond iot analytics,
N. H. Motlagh, M. A. Zaidan, L. Lov ´en, P. L. Fung, T. H ¨anninen, R. Morabito, P. Nurmi, and S. Tarkoma, “Digital twins for smart spaces—beyond iot analytics,”IEEE internet of things journal, vol. 11, no. 1, pp. 573–583, 2023
2023
-
[6]
Performance of large language models across edge and cloud platforms in smart spaces,
A. Varol, N. H. Motlagh, M. Leino, and J. Virkki, “Performance of large language models across edge and cloud platforms in smart spaces,” in 2025 10th International Conference on Smart and Sustainable Technolo- gies (SpliTech). IEEE, 2025, pp. 1–6
2025
-
[7]
Multi- agent large language models for distributed internet of things analytics in smart environments,
A. Varol, A. Shaikh, N. H. Motlagh, M. Leino, and J. Virkki, “Multi- agent large language models for distributed internet of things analytics in smart environments,” in2026 11th International Conference on Smart and Sustainable Technologies (SpliTech). IEEE, 2026, pp. 1–6. 15
2026
-
[8]
Llm on the edge: the new frontier,
S. O. Semerikov, T. A. Vakaliuk, O. B. Kanevska, M. V . Moiseienko, I. I. Donchev, and A. O. Kolhatin, “Llm on the edge: the new frontier,” inCEUR Workshop Proceedings, 2025, pp. 137–161
2025
-
[9]
A survey of sustainability in large language models: Applications, economics, and challenges,
A. Singh, N. P. Patel, A. Ehtesham, S. Kumar, and T. T. Khoei, “A survey of sustainability in large language models: Applications, economics, and challenges,” in2025 IEEE 15th Annual Computing and Communication Workshop and Conference (CCWC). IEEE, 2025, pp. 8–14
2025
-
[10]
Llm-based edge intelligence: A comprehensive survey on architectures, applications, security and trustworthiness,
O. Friha, M. A. Ferrag, B. Kantarci, B. Cakmak, A. Ozgun, and N. Ghoualmi-Zine, “Llm-based edge intelligence: A comprehensive survey on architectures, applications, security and trustworthiness,”IEEE Open Journal of the Communications Society, 2024
2024
-
[11]
Mobile edge intelligence for large language models: A contemporary survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,”IEEE Communications Surveys & Tutorials, 2025
2025
-
[12]
A survey on network methodologies for real-time analytics of massive iot data and open research issues,
S. Verma, Y . Kawamoto, Z. M. Fadlullah, H. Nishiyama, and N. Kato, “A survey on network methodologies for real-time analytics of massive iot data and open research issues,”IEEE Communications Surveys & Tutorials, vol. 19, no. 3, pp. 1457–1477, 2017
2017
-
[13]
E. King, H. Yu, S. Lee, and C. Julien, “” get ready for a party”: Exploring smarter smart spaces with help from large language models,”arXiv preprint arXiv:2303.14143, 2023
arXiv 2023
-
[14]
Chatiot: Zero- code generation of trigger-action based iot programs,
Y . Gao, K. Xiao, F. Li, W. Xu, J. Huang, and W. Dong, “Chatiot: Zero- code generation of trigger-action based iot programs,”Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 8, no. 3, pp. 1–29, 2024
2024
-
[15]
Buildingsage: A safe and secure ai copilot for smart buildings,
V . Dedeoglu, Q. Zhang, Y . Li, J. Liu, and S. Sethuvenkatraman, “Buildingsage: A safe and secure ai copilot for smart buildings,” in Proceedings of the 11th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, 2024, pp. 369– 374
2024
-
[16]
Follow-me ai: Energy-efficient user interaction with smart environments,
A. Saleh, P. K. Donta, R. Morabito, N. H. Motlagh, S. Tarkoma, and L. Lov ´en, “Follow-me ai: Energy-efficient user interaction with smart environments,”IEEE Pervasive Computing, 2025
2025
-
[17]
Llmind: Orchestrating ai and iot with llm for complex task execution,
H. Cui, Y . Du, Q. Yang, Y . Shao, and S. C. Liew, “Llmind: Orchestrating ai and iot with llm for complex task execution,”IEEE Communications Magazine, 2024
2024
-
[18]
Penetrative ai: Making llms comprehend the physical world,
H. Xu, L. Han, Q. Yang, M. Li, and M. Srivastava, “Penetrative ai: Making llms comprehend the physical world,” inProceedings of the 25th International Workshop on Mobile Computing Systems and Applications, 2024, pp. 1–7
2024
-
[19]
Sensorllm: Aligning large language models with motion sensors for human activity recognition,
Z. Li, S. Deldari, L. Chen, H. Xue, and F. D. Salim, “Sensorllm: Aligning large language models with motion sensors for human activity recognition,”arXiv preprint arXiv:2410.10624, 2024
arXiv 2024
-
[20]
Tinyllama: An open-source small language model,
P. Zhang, G. Zeng, T. Wang, and W. Lu, “Tinyllama: An open-source small language model,”arXiv preprint arXiv:2401.02385, 2024
Pith/arXiv arXiv 2024
-
[21]
Powerinfer-2: Fast large language model inference on a smartphone,
Z. Xue, Y . Song, Z. Mi, X. Zheng, Y . Xia, and H. Chen, “Powerinfer-2: Fast large language model inference on a smartphone,”arXiv preprint arXiv:2406.06282, 2024
arXiv 2024
-
[22]
Edgeshard: Efficient llm inference via collaborative edge computing,
M. Zhang, X. Shen, J. Cao, Z. Cui, and S. Jiang, “Edgeshard: Efficient llm inference via collaborative edge computing,”IEEE Internet of Things Journal, 2024
2024
-
[23]
Splitllm: Collaborative infer- ence of llms for model placement and throughput optimization,
A. Mudvari, Y . Jiang, and L. Tassiulas, “Splitllm: Collaborative infer- ence of llms for model placement and throughput optimization,”arXiv preprint arXiv:2410.10759, 2024
arXiv 2024
-
[24]
Y . Chen, R. Li, X. Yu, Z. Zhao, and H. Zhang, “Adaptive layer splitting for wireless llm inference in edge computing: A model-based reinforcement learning approach,”arXiv preprint arXiv:2406.02616, 2024
arXiv 2024
-
[25]
Hpipe: Large language model pipeline parallelism for long context on heterogeneous cost-effective devices,
R. Ma, X. Yang, J. Wang, Q. Qi, H. Sun, J. Wang, Z. Zhuang, and J. Liao, “Hpipe: Large language model pipeline parallelism for long context on heterogeneous cost-effective devices,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), 20...
2024
-
[26]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[27]
Smart air quality monitoring iot-based in- frastructure for industrial environments,
L. Garc ´ıa, A.-J. Garcia-Sanchez, R. Asorey-Cacheda, J. Garcia-Haro, and C.-L. Z ´u˜niga-Ca˜n´on, “Smart air quality monitoring iot-based in- frastructure for industrial environments,”Sensors, vol. 22, no. 23, p. 9221, 2022
2022
-
[28]
LLMAir: Adaptive reprogramming large language model for air quality prediction,
J. Fan, H. Chu, L. Liu, and H. Ma, “LLMAir: Adaptive reprogramming large language model for air quality prediction,” in2024 IEEE 30th International Conference on Parallel and Distributed Systems (ICPADS), 2024, pp. 423–430
2024
-
[29]
Vayubuddy: an LLM-powered chatbot to democratize air quality insights,
Z. B. Patel, Y . Bachwana, N. Sharma, S. Guttikunda, and N. Batra, “Vayubuddy: an LLM-powered chatbot to democratize air quality insights,” 2024. [Online]. Available: https://arxiv.org/abs/2411.12760
arXiv 2024
-
[30]
Instructor–worker large language model system for policy recommen- dation: A case study on air quality analysis of the january 2025 los angeles wildfires,
K. Gao, D. Lu, L. Li, N. Chen, H. He, J. Du, L. Xu, and J. Li, “Instructor–worker large language model system for policy recommen- dation: A case study on air quality analysis of the january 2025 los angeles wildfires,”International Journal of Applied Earth Observation and Geoinformation, vol. 143, p. 104774, 2025
2025
-
[31]
Through the thicket: A study of number-oriented llms derived from random forest models,
M. Romaszewski, P. Sekuła, P. Głomb, M. Cholewa, and K. Kołodziej, “Through the thicket: A study of number-oriented llms derived from random forest models,”Journal of Artificial Intelligence and Soft Com- puting Research, vol. 15, no. 3, pp. 279–298, 2025
2025
-
[32]
Public data repository,
Institute of Meteorology and Water Management (IMGW), “Public data repository,” https://danepubliczne.imgw.pl/, 2025, accessed: 2025-07-23
2025
-
[33]
Air quality archives – national air quality monitoring system,
Chief Inspectorate of Environmental Protection (GIOS), “Air quality archives – national air quality monitoring system,” https://powietrze.gios. gov.pl/pjp/archives, 2025, accessed: 2025-07-23
2025
-
[34]
Download observations,
Finnish Meteorological Institute, “Download observations,” https://en. ilmatieteenlaitos.fi/download-observations, 2025, accessed: 2025-07-23
2025
-
[35]
EU Air Quality Standards,
European Commission, “EU Air Quality Standards,” 2025, accessed: 2025-03-19. [Online]. Available: https://environment.ec.europa.eu/ topics/air/air-quality/eu-air-quality-standards en
2025
-
[36]
Heat index,
National Oceanic and Atmospheric Administration (NOAA), “Heat index,” https://www.noaa.gov/jetstream/synoptic/heat-index, 2025, ac- cessed: 2025-07-23
2025
-
[37]
The heat index equation,
National Weather Service (NWS), “The heat index equation,” https://www.wpc.ncep.noaa.gov/html/heatindex equation.shtml, 2025, accessed: 2025-07-23
2025
-
[38]
Warning levels and content of meteorological messages,
Institute of Meteorology and Water Management (IMGW), “Warning levels and content of meteorological messages,” http://aplikacjameteo.imgw.pl/informacje-i-pomoc/ostrzezenia/ stopnie-ostrzezen-i-tresc-komunikatow/, 2025, accessed: 2025-07- 23
2025
-
[39]
Warnings on hot and cold weather,
Finnish Meteorological Institute (FMI), “Warnings on hot and cold weather,” https://en.ilmatieteenlaitos.fi/ warnings-on-hot-and-cold-weather, 2025, accessed: 2025-07-23
2025
-
[40]
2024, document revision 1.9, BST-BME680-DS001-
Bosch Sensortec,BME680 Datasheet: Low Power Gas, Pressure, Temperature & Humidity Sensor, Bosch Sensortec GmbH, Feb. 2024, document revision 1.9, BST-BME680-DS001-
2024
-
[41]
Available: https://www.bosch-sensortec.com/media/ boschsensortec/downloads/datasheets/bst-bme680-ds001.pdf
[Online]. Available: https://www.bosch-sensortec.com/media/ boschsensortec/downloads/datasheets/bst-bme680-ds001.pdf
-
[42]
ASHRAE Standard 62.1-2022: Ventilation for Acceptable Indoor Air Quality,
ASHRAE, “ASHRAE Standard 62.1-2022: Ventilation for Acceptable Indoor Air Quality,” 2022
2022
-
[43]
tiktoken: OpenAI Tokenizer,
OpenAI, “tiktoken: OpenAI Tokenizer,” https://github.com/openai/ tiktoken, 2024
2024
-
[44]
Beyond text compression: Evaluating tokenizers across scales,
J. F. Lotz, A. V . Lopes, S. Peitz, H. Setiawan, and L. Emili, “Beyond text compression: Evaluating tokenizers across scales,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 32 155–32 173
2025
-
[45]
OpenAI API Pricing,
OpenAI, “OpenAI API Pricing,” https://platform.openai.com/docs/ pricing/, 2026, accessed: 2026-05-29
2026
-
[46]
Google Gemini API Pricing,
Google, “Google Gemini API Pricing,” https://ai.google.dev/gemini-api/ docs/pricing, 2026, accessed: 2026-05-29
2026
-
[47]
Finland electricity prices,
GlobalPetrolPrices.com, “Finland electricity prices,” 2025, accessed: 2026-06-18. [Online]. Available: https://www.globalpetrolprices.com/ Finland/electricity prices/
2025
-
[48]
Pre- train, prompt, and predict: A systematic survey of prompting methods in natural language processing,
P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre- train, prompt, and predict: A systematic survey of prompting methods in natural language processing,”ACM computing surveys, vol. 55, no. 9, pp. 1–35, 2023
2023
-
[49]
IoT-LLM: A framework for enhancing large language model reasoning from real-world sensor data,
T. An, Y . Zhou, H. Zou, and J. Yang, “IoT-LLM: A framework for enhancing large language model reasoning from real-world sensor data,” Patterns, vol. 7, no. 1, p. 101429, 2026
2026
-
[50]
IoT-LM: Large multisensory language models for the internet of things,
S. Mo, R. Salakhutdinov, L.-P. Morency, and P. P. Liang, “IoT-LM: Large multisensory language models for the internet of things,”arXiv preprint arXiv:2407.09801, 2024
arXiv 2024
-
[51]
The role of large language models in addressing IoT challenges: A systematic literature review,
G. De Vito, F. Palomba, and F. Ferrucci, “The role of large language models in addressing IoT challenges: A systematic literature review,” Future Generation Computer Systems, vol. 171, p. 107829, 2025
2025
-
[52]
R. Liu, J. Geng, A. J. Wu, I. Sucholutsky, T. Lombrozo, and T. L. Griffiths, “Mind your step (by step): Chain-of-thought can reduce performance on tasks where thinking makes humans worse,”arXiv preprint arXiv:2410.21333, 2024
arXiv 2024
-
[53]
Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,
M. Turpin, J. Michael, E. Perez, and S. R. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,” inAdvances in Neural Information Processing Systems, 2023. 16
2023
-
[54]
Right answer, wrong score: Uncovering the inconsistencies of llm evaluation in multiple-choice question answering,
F. M. Molfese, L. Moroni, L. Gioffr `e, A. Scir`e, S. Conia, and R. Navigli, “Right answer, wrong score: Uncovering the inconsistencies of llm evaluation in multiple-choice question answering,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 18 477– 18 494
2025
-
[55]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdh- ery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inInternational Conference on Learning Repre- sentations, 2023
2023
-
[56]
Scaling laws for neural language models,
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[57]
Training compute-optimal large language models,
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. Casas, L. A. Hendricks, J. Welbl, A. Clarket al., “Training compute-optimal large language models,”arXiv preprint arXiv:2203.15556, vol. 10, 2022
Pith/arXiv arXiv 2022
-
[58]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems, S. K...
2022
-
[59]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7B,”arXiv preprint arXiv:2310.06825, 2023
Pith/arXiv arXiv 2023
-
[60]
Gpt3. int8 (): 8- bit matrix multiplication for transformers at scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “Gpt3. int8 (): 8- bit matrix multiplication for transformers at scale,” inAdvances in Neu- ral Information Processing Systems, vol. 35, 2022, pp. 30 318–30 332. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 2022/file/c3ba4962c05c49636d4c6206a97e9c8a-Paper-Conference.pdf
2022
-
[61]
Large language models empowered autonomous edge AI for connected intelligence,
Y . Shen, J. Shao, X. Zhang, Z. Lin, H. Pan, D. Li, J. Zhang, and K. B. Letaief, “Large language models empowered autonomous edge AI for connected intelligence,”IEEE Communications Magazine, vol. 62, no. 10, pp. 140–146, 2024
2024
-
[62]
Ce-collm: Efficient and adaptive large language mod- els through cloud-edge collaboration,
H. Jin and Y . Wu, “Ce-collm: Efficient and adaptive large language mod- els through cloud-edge collaboration,”arXiv preprint arXiv:2411.02829, 2024
arXiv 2024
-
[63]
Semantic sensor web,
A. P. Sheth, C. A. Henson, and S. S. Sahoo, “Semantic sensor web,” IEEE Internet Computing, vol. 12, no. 4, pp. 78–83, 2008
2008
-
[64]
Sosa: A lightweight ontology for sensors, observations, samples, and actuators,
K. Janowicz, A. Haller, S. J. D. Cox, D. Le Phuoc, and M. Lefranc ¸ois, “Sosa: A lightweight ontology for sensors, observations, samples, and actuators,”Journal of Web Semantics, vol. 56, pp. 1–10, 2019
2019
-
[65]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems, 2020
2020
-
[66]
A review on edge large language models: Design, execution, and applications,
Y . Zheng, Y . Chen, B. Qian, X. Shi, Y . Shu, and J. Chen, “A review on edge large language models: Design, execution, and applications,”ACM Computing Surveys, vol. 57, no. 8, 2025. Ayg¨un Varolreceived the M.Sc. degree in elec- trical and electronics engineering from the Isparta University of Applied Sciences, Isparta, T ¨urkiye, in 2022. He is currentl...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.