PRISM: A Benchmark for Programmatic Spatial-Temporal Reasoning
Pith reviewed 2026-05-20 05:48 UTC · model grok-4.3
The pith
LLMs that generate executable code for animated visualizations often produce spatially incoherent outputs, with an average 41% performance drop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
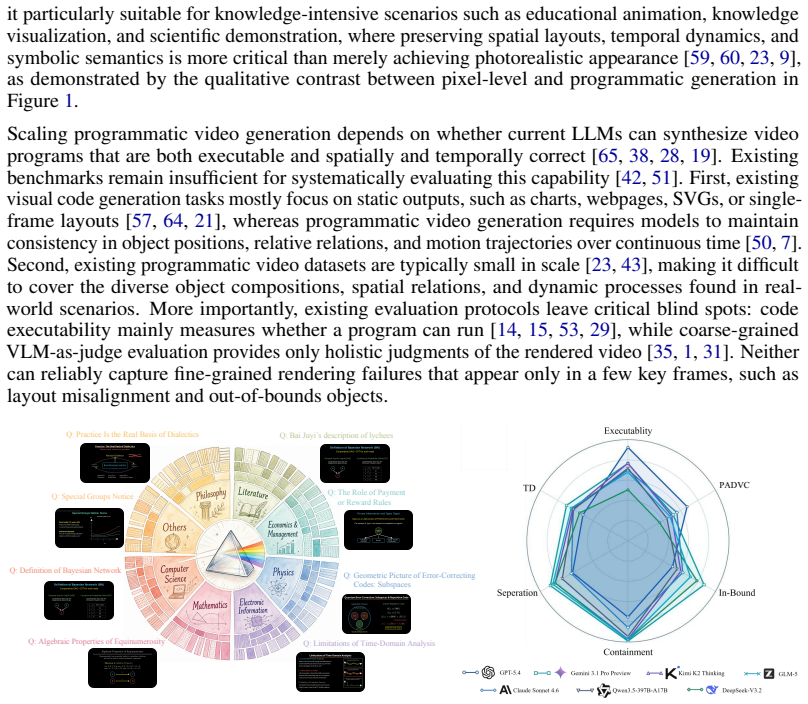
The paper establishes an Execution-Spatial Gap in which success at producing runnable code for video generation drops by approximately 41% on average when the requirement is added that the resulting animations must show correct spatial layouts over full sequences, based on evaluation across thousands of tasks in 437 subject categories.
What carries the argument
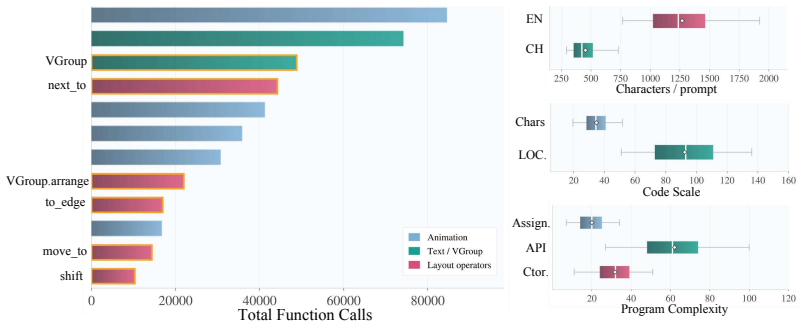
The PRISM benchmark of 10,372 human-calibrated instruction-code pairs together with its funnel-style evaluation framework that applies four metrics: Code-Level Reliability for executability, Spatial Reasoning for layout correctness, Prompt-Aware Dynamic Visual Complexity, and Temporal Density.
If this is right
- Evaluation of programmatic video generation must extend beyond code executability to include checks for spatial coherence across animation frames.
- Mainstream LLMs exhibit substantial limitations in spatial-temporal reasoning when translating instructions into code for visualizations.
- The benchmark spans English and Chinese instructions and 437 categories, indicating the gap is not limited to narrow domains.
- Future model development should target improvements in geometric and temporal understanding rather than relying solely on execution feedback.
Where Pith is reading between the lines
- Models could be trained with additional signals that enforce geometric constraints during code generation to reduce the observed gap.
- The benchmark structure might transfer to other code-based simulation tasks such as scientific plotting or interactive diagrams.
- The results point to a need for verification or planning stages that check spatial properties before final code output.
Load-bearing premise
The human-calibrated instruction-code pairs and the four metrics accurately capture spatial-temporal reasoning ability without bias from the calibration or metric design.
What would settle it
A model achieving high spatial pass rates close to its execution success rates on the PRISM tasks, or a demonstration that the spatial metric fails to match independent human judgments of visual coherence, would undermine the reported gap.
Figures







read the original abstract
Programmatic video generation through code offers geometric precision and temporal coherence beyond pixel-level diffusion models, yet rigorously evaluating whether language models can produce spatially correct animated outputs remains an open problem. We introduce PRISM, a large-scale benchmark of 10,372 human-calibrated instruction-code pairs (20 times larger than prior programmatic video generation benchmarks), grounded in real-world knowledge visualization scenarios across English and Chinese and spanning 437 subject categories. We further propose a funnel-style evaluation framework with four complementary metrics: Code-Level Reliability for executability, Spatial Reasoning for layout correctness over full animation sequences, and Prompt-Aware Dynamic Visual Complexity (PADVC) and Temporal Density (TD) for diagnosing dynamic expression and temporal activity. Systematic evaluation of seven mainstream LLMs reveals a striking Execution-Spatial Gap: the average drop from execution success rate to spatial pass rate is approximately 41%, showing that runnable code does not necessarily yield spatially coherent visual output. These findings show that programmatic video generation evaluation should go beyond executability. PRISM provides a principled benchmark for advancing spatially coherent code generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, a benchmark of 10,372 human-calibrated instruction-code pairs (20x larger than prior work) for programmatic video generation across English/Chinese and 437 categories. It defines a funnel-style evaluation using four metrics (Code-Level Reliability for executability, Spatial Reasoning for layout correctness over animation sequences, plus PADVC and TD for dynamic/temporal aspects) and evaluates seven mainstream LLMs, reporting an average ~41% Execution-Spatial Gap between execution success rate and spatial pass rate to argue that runnable code does not guarantee spatially coherent visual output.
Significance. If the gap is shown to reflect spatial deficits conditional on executable code, the work is significant for establishing a large-scale, human-grounded benchmark that pushes evaluation of code-based video generation beyond executability alone. The scale, real-world scenario grounding, and multi-metric framework are clear strengths that could support reproducible progress in spatial-temporal reasoning for LLMs.
major comments (1)
- [Evaluation framework] Evaluation framework section: the Spatial Reasoning metric and the reported 41% Execution-Spatial Gap must explicitly define the aggregation procedure. Is the spatial pass rate computed only over the subset of generations that pass Code-Level Reliability (i.e., conditional on successful execution and subsequent rendering/layout checks), or is it an unconditional percentage over all samples? The abstract's claim that 'runnable code does not necessarily yield spatially coherent visual output' requires the former; if the latter, the gap largely reproduces the execution failure rate rather than revealing additional spatial deficits.
minor comments (2)
- [Results] Results section: report per-model execution success rates, spatial pass rates, and the exact gap values with standard deviations or confidence intervals rather than only the average 41% figure, to allow readers to assess variability across the seven LLMs.
- [Benchmark construction] Benchmark construction: clarify the exact procedure and inter-annotator agreement for the human calibration of the 10,372 instruction-code pairs, including how spatial-temporal correctness was verified during dataset creation.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address the major comment on the evaluation framework below and will incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: Evaluation framework section: the Spatial Reasoning metric and the reported 41% Execution-Spatial Gap must explicitly define the aggregation procedure. Is the spatial pass rate computed only over the subset of generations that pass Code-Level Reliability (i.e., conditional on successful execution and subsequent rendering/layout checks), or is it an unconditional percentage over all samples? The abstract's claim that 'runnable code does not necessarily yield spatially coherent visual output' requires the former; if the latter, the gap largely reproduces the execution failure rate rather than revealing additional spatial deficits.
Authors: We agree that the aggregation procedure requires explicit definition to avoid ambiguity. The Spatial Reasoning metric is computed conditionally: the spatial pass rate is calculated exclusively over the subset of generations that first pass Code-Level Reliability (i.e., successful execution and rendering). This conditional evaluation isolates spatial-temporal deficits beyond mere executability and directly supports the abstract claim that runnable code does not guarantee spatially coherent output. The reported ~41% Execution-Spatial Gap is the average difference between execution success rate and this conditional spatial pass rate across models. We will revise the Evaluation framework section to state this conditional procedure explicitly, include the precise aggregation formula, and clarify how the gap is derived. revision: yes
Circularity Check
No significant circularity; empirical gap is measured outcome of independent benchmark evaluation
full rationale
The paper introduces a new benchmark of instruction-code pairs and applies four explicitly defined metrics (Code-Level Reliability, Spatial Reasoning, PADVC, TD) to LLM-generated outputs. The Execution-Spatial Gap is reported as the observed numerical difference between execution success rate and spatial pass rate across seven LLMs. No equations, fitted parameters, or self-citations appear in the derivation; the gap is not forced by redefining one metric in terms of the other or by renaming an input. The central claim rests on external LLM evaluations against the benchmark rather than reducing to the benchmark construction itself. This is a standard self-contained benchmark paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human calibration produces reliable ground-truth instruction-code pairs that reflect real-world visualization needs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
funnel-style evaluation framework with four complementary metrics: Code-Level Reliability for executability, Spatial Reasoning for layout correctness over full animation sequences
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Execution-Spatial Gap: the average drop from execution success rate to spatial pass rate is approximately 41%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jiaxin Ai, Pengfei Zhou, Zhaopan Xu, Ming Li, Fanrui Zhang, Zizhen Li, Jianwen Sun, Yukang Feng, Baojin Huang, Zhongyuan Wang, and Kaipeng Zhang. Projudge: A multi-modal multi-discipline benchmark and instruction-tuning dataset for mllm-based process judges. In IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[2]
Kimi K2: Open Agentic Intelligence
Moonshot AI. Kimi k2: Open agentic intelligence. InarXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Zhipu AI. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. InarXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
Claude opus 4 & claude sonnet 4 system card
Anthropic. Claude opus 4 & claude sonnet 4 system card. 2025
work page 2025
-
[6]
Dash: Detection and assessment of systematic hallucinations of vlms
Maximilian Augustin, Yannic Neuhaus, and Matthias Hein. Dash: Detection and assessment of systematic hallucinations of vlms. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[7]
Tikzero: Zero-shot text-guided graphics program synthesis
Jonas Belouadi, Eddy Ilg, Margret Keuper, Hideki Tanaka, Masao Utiyama, Raj Dabre, Steffen Eger, and Simone Paolo Ponzetto. Tikzero: Zero-shot text-guided graphics program synthesis. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[8]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 10
work page 2024
-
[9]
Hao Chen, Tianyu Shi, Pengran Huang, Zeyuan Li, Jiahui Pan, Qianglong Chen, and Lewei He. Visualedu: A benchmark for assessing coding and visual comprehension through educational problem-solving video generation. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2025
work page 2025
-
[10]
Code2video: A code-centric paradigm for educational video generation
Yanzhe Chen, Kevin Qinghong Lin, and Mike Zheng Shou. Code2video: A code-centric paradigm for educational video generation. InarXiv preprint arXiv:2510.01174, 2025
-
[11]
Wan-move: Motion-controllable video generation via latent trajectory guidance
Ruihang Chu, Yefei He, Zhekai Chen, Shiwei Zhang, Xiaogang Xu, Bin Xia, Dingdong Wang, Hongwei Yi, Xihui Liu, Hengshuang Zhao, Yu Liu, Yingya Zhang, and Yujiu Yang. Wan-move: Motion-controllable video generation via latent trajectory guidance. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[12]
Google DeepMind. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. InarXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models. InarXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Codescore: Evaluating code generation by learning code execution
Yihong Dong, Jiazheng Ding, Xue Jiang, Ge Li, Zhuo Li, and Zhi Jin. Codescore: Evaluating code generation by learning code execution. InACM Transactions on Software Engineering and Methodology (TOSEM), 2025
work page 2025
-
[15]
A Survey on Code Generation with LLM-based Agents
Yihong Dong, Xue Jiang, Jiaru Qian, Tian Wang, Kechi Zhang, Zhi Jin, and Ge Li. A survey on code generation with llm-based agents. InarXiv preprint arXiv:2508.00083, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InI...
work page 2025
-
[17]
Cad-coder: Text-to-cad generation with chain-of-thought and geometric reward
Yandong Guan, Xilin Wang, Ximing Xing, Jing Zhang, Dong Xu, and Qian Yu. Cad-coder: Text-to-cad generation with chain-of-thought and geometric reward. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[18]
Flaw or artifact? rethinking prompt sensitivity in evaluating llms
Andong Hua, Kenan Tang, Chenhe Gu, Jindong Gu, Eric Wong, and Yao Qin. Flaw or artifact? rethinking prompt sensitivity in evaluating llms. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2025
work page 2025
-
[19]
Scipostgen: Bridging the gap between scientific papers and poster layouts
Shun Inadumi, Shohei Tanaka, Tosho Hirasawa, Atsushi Hashimoto, Koichiro Yoshino, and Yoshitaka Ushiku. Scipostgen: Bridging the gap between scientific papers and poster layouts. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(Findings), 2026
work page 2026
-
[20]
G, Minseo Yoon, Manmohan Chan- draker, and Hyunwoo J
Dohwan Ko, Sihyeon Kim, Yumin Suh, Vijay Kumar B. G, Minseo Yoon, Manmohan Chan- draker, and Hyunwoo J. Kim. St-vlm: Kinematic instruction tuning for spatio-temporal reason- ing in vision-language models. InarXiv preprint arXiv:2503.19355, 2025
-
[21]
Woosung Koh, Jang Han Yoon, MinHyung Lee, Youngjin Song, Jaegwan Cho, Jaehyun Kang, Taehyeon Kim, Se-Young Yun, Youngjae Yu, and Bongshin Lee.c2: Scalable auto-feedback for llm-based chart generation. InAnnual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2025
work page 2025
-
[22]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Theorem- explainagent: Towards video-based multimodal explanations for llm theorem understanding
Max Ku, Thomas Chong, Jonathan Leung, Krish Shah, Alvin Yu, and Wenhu Chen. Theorem- explainagent: Towards video-based multimodal explanations for llm theorem understanding. In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[24]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[25]
Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi. A sur- vey of state of the art large vision language models: Alignment, benchmark, evaluations and challenges. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(Workshops), 2025
work page 2025
-
[26]
Jingping Liu, Ziyan Liu, Zhedong Cen, Yan Zhou, Yinan Zou, Weiyan Zhang, Haiyun Jiang, and Tong Ruan. Can multimodal large language models understand spatial relations? InAnnual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[27]
On robustness and reliability of benchmark-based evaluation of llms
Riccardo Lunardi, Vincenzo Della Mea, Stefano Mizzaro, and Kevin Roitero. On robustness and reliability of benchmark-based evaluation of llms. InarXiv preprint arXiv:2509.04013, 2025
-
[28]
Geogram- bench: Benchmarking the geometric program reasoning in modern llms
Shixian Luo, Zezhou Zhu, Yu Yuan, Yuncheng Yang, Lianlei Shan, and Yong Wu. Geogram- bench: Benchmarking the geometric program reasoning in modern llms. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[29]
Rethinking verification for llm code generation: From generation to testing
Zihan Ma, Taolin Zhang, Maosong Cao, Junnan Liu, Wenwei Zhang, Minnan Luo, Songyang Zhang, and Kai Chen. Rethinking verification for llm code generation: From generation to testing. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[30]
ivispar – an interactive visual-spatial reasoning benchmark for vlms
Julius Mayer, Mohamad Ballout, Serwan Jassim, Farbod Nosrat Nezami, and Elia Bruni. ivispar – an interactive visual-spatial reasoning benchmark for vlms. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2025
work page 2025
-
[31]
CountLoop: Training-Free High-Instance Image Generation via Iterative Agent Guidance
Anindya Mondal, Ayan Banerjee, Sauradip Nag, Josep Llados, Xiatian Zhu, and Anjan Dutta. Countloop: Training-free high-instance image generation via iterative agent guidance. InarXiv preprint arXiv:2508.16644, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Spare: Enhancing spatial reasoning in vision-language models with synthetic data
Michael Ogezi and Freda Shi. Spare: Enhancing spatial reasoning in vision-language models with synthetic data. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[33]
Nabin Oli. Manibench: A benchmark for testing visual-logic drift and syntactic hallucinations in manim code generation. InarXiv preprint arXiv:2603.13251, 2026
- [34]
-
[35]
Renjie Pi, Felix Bai, Qibin Chen, Simon Wang, Jiulong Shan, Kieran Liu, and Meng Cao. Mr. judge: Multimodal reasoner as a judge. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2025
work page 2025
-
[36]
Capture: Evaluating spatial reasoning in vision language models via occluded object counting
Atin Pothiraj, Elias Stengel-Eskin, Jaemin Cho, and Mohit Bansal. Capture: Evaluating spatial reasoning in vision language models via occluded object counting. InIEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[37]
Forest: Frame of reference evaluation in spatial rea- soning tasks
Tanawan Premsri and Parisa Kordjamshidi. Forest: Frame of reference evaluation in spatial rea- soning tasks. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2025
work page 2025
-
[38]
Zeju Qiu, Weiyang Liu, Haiwen Feng, Zhen Liu, Tim Z. Xiao, Katherine M. Collins, Joshua B. Tenenbaum, Adrian Weller, Michael J. Black, and Bernhard Schölkopf. Can large language models understand symbolic graphics programs? InInternational Conference on Learning Representations (ICLR), 2025. 12
work page 2025
-
[39]
Benchmarking spatiotemporal reasoning in llms and reasoning models: Capabilities and challenges
Pengrui Quan, Brian Wang, Kang Yang, Liying Han, and Mani Srivastava. Benchmarking spatiotemporal reasoning in llms and reasoning models: Capabilities and challenges. In Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[40]
Text2vis: A challenging and diverse benchmark for generating multimodal visualizations from text
Mizanur Rahman, Md Tahmid Rahman Laskar, Shafiq Joty, and Enamul Hoque. Text2vis: A challenging and diverse benchmark for generating multimodal visualizations from text. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
work page 2025
-
[41]
Brittlebench: Quantifying LLM robustness via prompt sensitivity
Angelika Romanou, Mark Ibrahim, Candace Ross, Chantal Shaib, Kerem Oktar, Samuel J. Bell, Anaelia Ovalle, Jesse Dodge, Antoine Bosselut, Koustuv Sinha, and Adina Williams. Brit- tlebench: Quantifying llm robustness via prompt sensitivity. InarXiv preprint arXiv:2603.13285, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Design2code: Benchmarking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: Benchmarking multimodal code generation for automated front-end engineering. InAnnual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2025
work page 2025
-
[43]
Ravidu Suien Rammuni Silva, Ahmad Lotfi, Isibor Kennedy Ihianle, Golnaz Shahtahmassebi, and Jordan J. Bird. Training and agentic inference strategies for llm-based manim animation generation. InarXiv preprint arXiv:2604.18364, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Manim - mathematical animation framework (v0.19.0)
The Manim Community Developers. Manim - mathematical animation framework (v0.19.0). In 10.5281/zenodo.14699705, 2025
-
[45]
Ode: Open-set evaluation of hallucinations in multimodal large language models
Yahan Tu, Rui Hu, and Jitao Sang. Ode: Open-set evaluation of hallucinations in multimodal large language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[46]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Fei Wang, Xingyu Fu, James Y . Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, Tianyi Lorena Yan, Wenjie Jacky Mo, Hsiang-Hui Liu, Pan Lu, Chunyuan Li, Chaowei Xiao, Kai-Wei Chang, Dan Roth, Sheng Zhang, Hoifung Poon, and Muhao Chen. Muirbench: A comprehensive benchmark for robust multi-image understanding. InInte...
work page 2025
-
[48]
Ske- layout: Spatial knowledge enhanced layout generation with llms
Junsheng Wang, Nieqing Cao, Yan Ding, Mengying Xie, Fuqiang Gu, and Chao Chen. Ske- layout: Spatial knowledge enhanced layout generation with llms. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[49]
Spatial457: A diagnostic benchmark for 6d spatial reasoning of large multimodal models
Xingrui Wang, Wufei Ma, Tiezheng Zhang, Celso M de Melo, Jieneng Chen, and Alan Yuille. Spatial457: A diagnostic benchmark for 6d spatial reasoning of large multimodal models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[50]
Jingxuan Wei, Cheng Tan, Qi Chen, Gaowei Wu, Siyuan Li, Zhangyang Gao, Linzhuang Sun, Bihui Yu, and Ruifeng Guo. From words to structured visuals: A benchmark and framework for text-to-diagram generation and editing. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[51]
Chengyue Wu, Zhixuan Liang, Yixiao Ge, Qiushan Guo, Zeyu Lu, Jiahao Wang, Ying Shan, and Ping Luo. Plot2code: A comprehensive benchmark for evaluating multi-modal large language models in code generation from scientific plots. InAnnual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)(Findings), 2024. 13
work page 2024
-
[52]
PanoWan: Lifting diffusion video generation models to 360◦ with latitude/longitude-aware mechanisms
Yifei Xia, Shuchen Weng, Siqi Yang, Jingqi Liu, Chengxuan Zhu, Minggui Teng, Zijian Jia, Han Jiang, and Boxin Shi. PanoWan: Lifting diffusion video generation models to 360◦ with latitude/longitude-aware mechanisms. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[53]
Core: Benchmarking llms code reasoning capabilities through static analysis tasks
Danning Xie, Mingwei Zheng, Xuwei Liu, Jiannan Wang, Chengpeng Wang, Lin Tan, and Xiangyu Zhang. Core: Benchmarking llms code reasoning capabilities through static analysis tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[54]
Empower- ing llms to understand and generate complex vector graphics
Ximing Xing, Juncheng Hu, Guotao Liang, Jing Zhang, Dong Xu, and Qian Yu. Empower- ing llms to understand and generate complex vector graphics. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[55]
Wenrui Xu, Dalin Lyu, Weihang Wang, Jie Feng, Chen Gao, and Yong Li. Defining and evaluating visual language models’ basic spatial abilities: A perspective from psychometrics. In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[56]
An Yang et al. Qwen3 technical report. InarXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Chart- mimic: Evaluating lmm’s cross-modal reasoning capability via chart-to-code generation
Cheng Yang, Chufan Shi, Yaxin Liu, Bo Shui, Junjie Wang, Mohan Jing, Linran Xu, Xinyu Zhu, Siheng Li, Yuxiang Zhang, Gongye Liu, Xiaomei Nie, Deng Cai, and Yujiu Yang. Chart- mimic: Evaluating lmm’s cross-modal reasoning capability via chart-to-code generation. In International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[58]
Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
work page 2025
-
[60]
Omnisvg: A unified scalable vector graphics generation model
Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Fukun Yin, Jiaxu Zhang, Liao Wang, Gang Yu, Xingjun Ma, and Yu-Gang Jiang. Omnisvg: A unified scalable vector graphics generation model. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[61]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[62]
Mitigating spatial hallucination in large language models for path planning via prompt engineering
Hongjie Zhang, Hourui Deng, Jie Ou, and Chaosheng Feng. Mitigating spatial hallucination in large language models for path planning via prompt engineering. InScientific Reports, 2025
work page 2025
-
[63]
Sphere: Unveiling spatial blind spots in vision-language models through hierarchical evaluation
Wenyu Zhang, Wei En Ng, Lixin Ma, Yuwen Wang, Junqi Zhao, Allison Koenecke, Boyang Li, and Lu Wang. Sphere: Unveiling spatial blind spots in vision-language models through hierarchical evaluation. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[64]
Chartcoder: Advancing multimodal large language model for chart-to-code generation
Xuanle Zhao, Xianzhen Luo, Qi Shi, Chi Chen, Shuo Wang, Zhiyuan Liu, and Maosong Sun. Chartcoder: Advancing multimodal large language model for chart-to-code generation. In Annual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[65]
Knowledge- enhanced large language models for automatic lesson plan generation
Ying Zheng, Shuyan Huang, Xiaoli Zeng, Yaying Huang, Zitao Liu, and Weiqi Luo. Knowledge- enhanced large language models for automatic lesson plan generation. InHumanities and Social Sciences Communications, 2025
work page 2025
-
[66]
Autofigure: Generating and refining publication-ready scientific illustrations
Minjun Zhu, Zhen Lin, Yixuan Weng, Panzhong Lu, Qiujie Xie, Yifan Wei, Sifan Liu, Qiyao Sun, and Yue Zhang. Autofigure: Generating and refining publication-ready scientific illustrations. InInternational Conference on Learning Representations (ICLR), 2026. 14
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.