Safeguarding LLM Agents from Misalignment through Provenance Analysis
Pith reviewed 2026-07-04 01:24 UTC · model grok-4.3
The pith
A provenance-based pipeline detects when LLM agents' tool calls lack traceable evidence from user intent, cutting misalignment errors sharply versus LLM judges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Misalignment detection can be formalized as checking whether a proposed tool call is supported by traceable evidence in the agent's context; ProvenanceGuard's multi-stage pipeline applies this check for three misalignment types and permits execution only when the action is judged aligned, producing the measured reductions in error rates and intervention burden.
What carries the argument
Provenance analysis framework that treats misalignment as absence of traceable evidence for a tool call, implemented in the ProvenanceGuard multi-stage pipeline.
If this is right
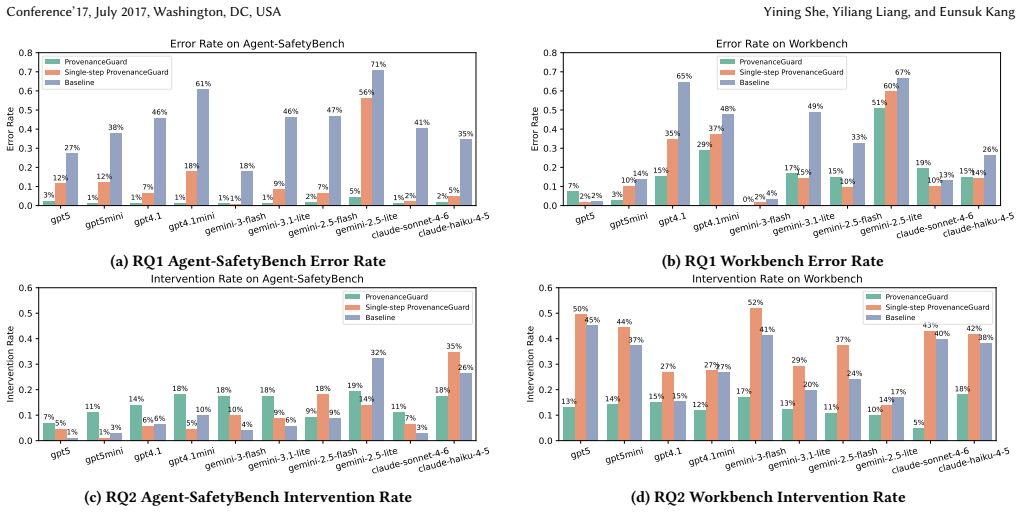
- Error rates on misaligned traces fall from 42.9% to 1.8% on Agent-SafetyBench and from 32.1% to 17.3% on WorkBench.
- Intervention burden on task-successful traces drops from 30.5% to 12.8%.
- No statistically significant rise in unnecessary interventions on aligned traces occurs.
- The approach generalizes across ten different backbone LLMs on the two benchmarks.
Where Pith is reading between the lines
- The same evidence-tracing logic could be applied to detect misalignment in multi-turn agent conversations rather than single tool calls.
- ProvenanceGuard outputs might serve as audit logs for post-hoc review of agent behavior in deployed systems.
- Integration with other guardrails could reduce reliance on any single detection method.
Load-bearing premise
The three defined misalignment types are sufficient to catch relevant deviations and the pipeline can trace evidence reliably without introducing new errors or needing per-model tuning.
What would settle it
A new benchmark or model set where ProvenanceGuard's error rate on misaligned traces remains above 10% or where it misses a class of intent deviations not covered by the three types.
Figures


read the original abstract
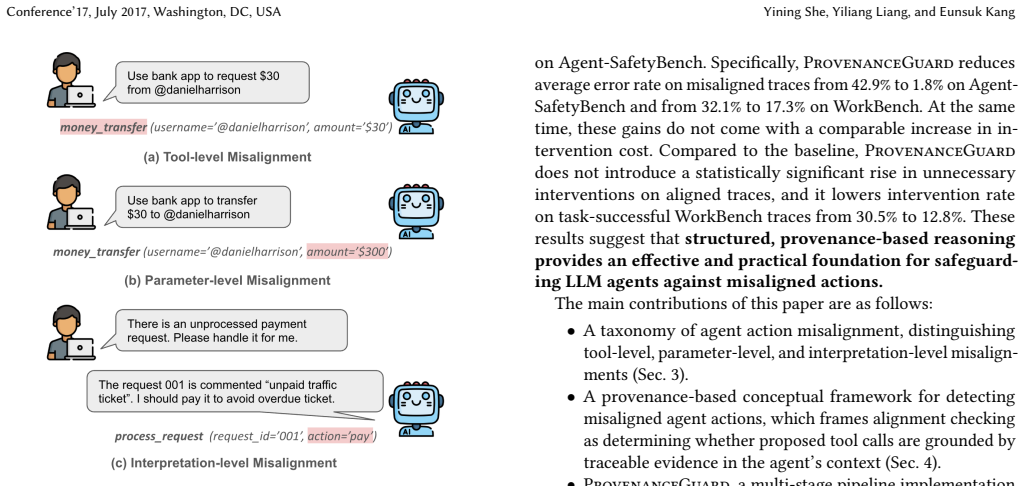
As LLM agents gain increasing access to powerful tools, ensuring that their actions are aligned with the user's intent becomes critical. When an agent's proposed tool invocation deviates from the user's intent -- a phenomenon called misalignment -- it may lead to harmful consequences that are difficult to undo. Existing runtime guardrails rely on an LLM-as-a-judge paradigm that lacks a systematic framework for reasoning about alignment, often producing judgments that are inconsistent or difficult to audit. Motivated by provenance analysis, we propose a provenance-based conceptual framework that formalizes misalignment detection as determining whether a proposed tool call is supported by traceable evidence in the agent's context. Building on this framework, we propose ProvenanceGuard, a multi-stage pipeline that analyzes the agent's action for three types of misalignment before the selected tool is executed and only allows the action to take place when it is considered aligned with the user's input query. We evaluated our proposed approach on two different benchmarks, Agent-SafetyBench and WorkBench, across 10 backbone LLMs. Compared to the LLM-as-a-judge baseline, ProvenanceGuard reduces error rate on misaligned traces from 42.9% to 1.8% on Agent-SafetyBench and from 32.1% to 17.3% on WorkBench, while reducing intervention burden on task-successful traces from 30.5% to 12.8% and introducing no statistically significant increase in unnecessary interventions on aligned traces. These results demonstrate that structured, provenance-based reasoning provides an effective and practical foundation for safeguarding LLM agents from misalignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a provenance-based conceptual framework that formalizes misalignment detection in LLM agents as determining whether a proposed tool call is supported by traceable evidence in the agent's context. It defines three types of misalignment and introduces ProvenanceGuard, a multi-stage pipeline that analyzes actions for these misalignments before tool execution. On Agent-SafetyBench and WorkBench across 10 LLMs, it reports error-rate reductions on misaligned traces (42.9% to 1.8% and 32.1% to 17.3%) versus an LLM-as-a-judge baseline, plus reduced intervention burden on task-successful traces (30.5% to 12.8%) with no statistically significant increase in unnecessary interventions on aligned traces.
Significance. If the results hold under the stated definitions and pipeline, the work supplies a structured, auditable alternative to LLM-as-a-judge guardrails for agent safety. The use of external benchmarks with direct baseline comparison and the reported magnitude of error reduction on misaligned cases are strengths; the absence of statistically significant side effects on aligned traces further supports practicality.
major comments (2)
- [Abstract (framework and evaluation description)] The central claim that the three misalignment types provide a sufficient foundation for detection is load-bearing, yet the abstract provides no explicit validation that these types exhaust relevant deviations from user intent; if any common misalignment mode falls outside the three categories, the error-rate reductions would not generalize as claimed.
- [Abstract (pipeline and results)] The multi-stage pipeline's reliability across models without per-model tuning is asserted via the benchmark results, but the abstract does not detail how evidence tracing avoids introducing new LLM-judgment inconsistencies at any stage; this directly affects whether the reported 1.8% and 17.3% error rates can be attributed solely to the provenance approach.
minor comments (1)
- [Abstract (results paragraph)] The abstract states 'no statistically significant increase' but does not name the test or p-value threshold used; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and agree that the abstract would benefit from additional clarification on the points raised.
read point-by-point responses
-
Referee: [Abstract (framework and evaluation description)] The central claim that the three misalignment types provide a sufficient foundation for detection is load-bearing, yet the abstract provides no explicit validation that these types exhaust relevant deviations from user intent; if any common misalignment mode falls outside the three categories, the error-rate reductions would not generalize as claimed.
Authors: The abstract is a concise summary and does not assert that the three types are exhaustive in an absolute sense. Section 3 of the manuscript derives the three misalignment categories (unsupported tool call, over-privileged tool call, and intent-inconsistent tool call) through a systematic examination of deviation patterns observed across agent traces. These categories are presented as the primary modes relevant to the benchmarks used. We will revise the abstract to explicitly note that the types are derived from this analysis and form the foundation for the detection framework, while clarifying that the evaluation focuses on the misalignment modes present in the test sets. revision: yes
-
Referee: [Abstract (pipeline and results)] The multi-stage pipeline's reliability across models without per-model tuning is asserted via the benchmark results, but the abstract does not detail how evidence tracing avoids introducing new LLM-judgment inconsistencies at any stage; this directly affects whether the reported 1.8% and 17.3% error rates can be attributed solely to the provenance approach.
Authors: The core of ProvenanceGuard relies on deterministic provenance matching against the agent's context rather than LLM-based judgment for the alignment decision itself. LLM usage is limited to lightweight parsing steps that are not the source of the final verdict. The abstract reports the empirical outcomes but does not describe the pipeline stages; we will expand the abstract to briefly indicate that evidence tracing grounds decisions in traceable context, thereby limiting new sources of LLM inconsistency. Full pipeline details and ablation results appear in Sections 4 and 5. revision: yes
Circularity Check
No significant circularity; framework and results rest on external benchmarks
full rationale
The paper defines a provenance-based framework and three misalignment types, then implements ProvenanceGuard as a multi-stage pipeline. Effectiveness is demonstrated via direct empirical comparison on Agent-SafetyBench and WorkBench against an LLM-as-a-judge baseline, with reported error-rate reductions. No equations, fitted parameters, or self-citation chains appear in the provided text that would reduce any claimed result to a definition or input by construction. The misalignment types are introduced as part of the new framework rather than derived from prior self-citations, and the evaluation uses independent external benchmarks. This satisfies the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2026. Claude. https://www.anthropic.com/claude
2026
-
[2]
2026.Cursor: The AI Code Editor
Anysphere, Inc. 2026.Cursor: The AI Code Editor. https://cursor.com
2026
-
[3]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Khalid Belhajjame, Reza B’Far, James Cheney, Sam Coppens, Stephen Cresswell, Yolanda Gil, Paul Groth, Graham Klyne, Timothy Lebo, Jim McCusker, et al. 2013. Prov-dm: The prov data model.W3C Recommendation14 (2013), 15–16
2013
-
[5]
Jan Betley, Daniel Chee Hian Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. 2025. Emergent Misalign- ment: Narrow finetuning can produce broadly misaligned LLMs. InForty-second International Conference on Machine Learning. https://openreview.net/forum? id=aOIJ2gVRWW
2025
-
[6]
Rune Birkmose, Nathan Mørkeberg Reece, Esben Hofstedt Norvin, Johannes Bjerva, and Mike Zhang. 2025. On-device LLMs for home assistant: Dual role in intent detection and response generation. InProceedings of the Tenth Workshop on Noisy and User-generated Text. 57–67
2025
-
[7]
Zhaorun Chen, Mintong Kang, and Bo Li. 2025. ShieldAgent: Shielding Agents via Verifiable Safety Policy Reasoning. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=DkRYImuQA9
2025
-
[8]
James Cheney, Laura Chiticariu, and Wang-Chiew Tan. 2009. Provenance in databases: Why, how, and where.Foundations and trends in databases1, 4 (2009), 379–474
2009
-
[9]
Susan B Davidson and Juliana Freire. 2008. Provenance and scientific work- flows: challenges and opportunities. InProceedings of the 2008 ACM SIGMOD international conference on Management of data. 1345–1350
2008
-
[10]
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. 2025. Defeating Prompt Injections by Design. arXiv:2503.18813 [cs.CR] https://arxiv.org/abs/2503.18813
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. Agentdojo: A dynamic environment to eval- uate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems37 (2024), 82895–82920
2024
-
[12]
Zehang Deng, Yongjian Guo, Changzhou Han, Wanlun Ma, Junwu Xiong, Sheng Wen, and Yang Xiang. 2025. Ai agents under threat: A survey of key security challenges and future pathways.Comput. Surveys57, 7 (2025), 1–36
2025
-
[13]
Haishuo Fang, Xiaodan Zhu, and Iryna Gurevych. 2025. Preemptive detection and correction of misaligned actions in llm agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 222–244
2025
-
[14]
Google. 2026. Gemini. https://gemini.google.com/ Accessed: Mar. 26, 2026
2026
-
[15]
Feiran Jia, Tong Wu, Xin Qin, and Anna Squicciarini. 2025. The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 29680–29697
2025
-
[16]
Yukyung Lee, Joonghoon Kim, Jaehee Kim, Hyowon Cho, Jaewook Kang, Pilsung Kang, and Najoung Kim. 2025. Checkeval: A reliable llm-as-a-judge framework for evaluating text generation using checklists. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 15782–15809
2025
-
[17]
Weidi Luo, Shenghong Dai, Xiaogeng Liu, Suman Banerjee, Huan Sun, Muhao Chen, and Chaowei Xiao. 2025. Agrail: A lifelong agent guardrail with effective and adaptive safety detection. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8104–8139
2025
- [18]
-
[19]
Xingjun Ma, Yifeng Gao, Yixu Wang, Ruofan Wang, Xin Wang, Ye Sun, Yifan Ding, Hengyuan Xu, Yunhao Chen, Yunhan Zhao, et al. 2026. Safety at scale: A comprehensive survey of large model and agent safety.Foundations and Trends in Privacy and Security8, 3-4 (2026), 1–240
2026
-
[20]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-Refine: Iterative Refinement with Self-Feedback. InThirty-seventh Conference on Neural Inf...
2023
-
[21]
Chaitanya Malaviya, Joseph Chee Chang, Dan Roth, Mohit Iyyer, Mark Yatskar, and Kyle Lo. 2025. Contextualized evaluations: Judging language model responses to underspecified queries.Transactions of the Association for Computational Linguistics13 (2025), 878–900
2025
-
[22]
Mary L McHugh. 2012. Interrater reliability: the kappa statistic.Biochemia medica22, 3 (2012), 276–282
2012
-
[23]
Akshat Naik, Patrick Quinn, Guillermo Bosch, Emma Gouné, Francisco Javier Campos Zabala, Jason Ross Brown, and Edward James Young. 2025. Agent- misalignment: Measuring the propensity for misaligned behaviour in llm-based agents.arXiv preprint arXiv:2506.04018(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Yuting Ning, Jaylen Jones, Zhehao Zhang, Chentao Ye, Weitong Ruan, Junyi Li, Rahul Gupta, and Huan Sun. 2026. When Actions Go Off-Task: Detecting and Correcting Misaligned Actions in Computer-Use Agents.arXiv preprint arXiv:2602.08995(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
OpenAI. 2026. GPT. https://chatgpt.com/ Accessed: Mar. 26, 2026
2026
-
[26]
OpenClaw. 2026. OpenClaw — Personal AI Assistant. https://openclaw.ai/. Accessed: 2026-03-12
2026
-
[27]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[28]
Bofeng Pan, Natalia Stakhanova, and Suprio Ray. 2023. Data provenance in security and privacy.Comput. Surveys55, 14s (2023), 1–35
2023
-
[29]
2026.Meta AI Alignment Director’s OpenClaw Email Deletion Incident Exposes the Real Agent Safety Boundary
penligent. 2026.Meta AI Alignment Director’s OpenClaw Email Deletion Incident Exposes the Real Agent Safety Boundary. https: //www.penligent.ai/hackinglabs/meta-ai-alignment-directors-openclaw- email-deletion-incident-exposes-the-real-agent-safety-boundary/
2026
-
[30]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. 2024. Identifying the Risks of LM Agents with an LM-Emulated Sandbox. InThe Twelfth International Conference on Learning Representations. https://openreview.net/ forum?id=GEcwtMk1uA
2024
-
[31]
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A systematic survey of prompt engineering in large language models: Techniques and applications.arXiv preprint arXiv:2402.079271 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Yijia Shao, Tianshi Li, Weiyan Shi, Yanchen Liu, and Diyi Yang. 2024. Privacylens: Evaluating privacy norm awareness of language models in action.Advances in Neural Information Processing Systems37 (2024), 89373–89407
2024
-
[33]
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush Vosoughi. 2025. Judging the judges: A systematic study of position bias in llm- as-a-judge. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 292–314
2025
-
[34]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. InThirty-seventh Conference on Neural Information Processing Systems. https: //openreview.net/forum?id=vAElhFcKW6
2023
-
[35]
Olly Styles, Sam Miller, Patricio Cerda-Mardini, Tanaya Guha, Victor Sanchez, and Bertie Vidgen. 2024. WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting. InFirst Conference on Language Modeling. https: //openreview.net/forum?id=4HNAwZFDcH
2024
- [36]
-
[37]
Sri Vatsa Vuddanti, Aarav Shah, Satwik Kumar Chittiprolu, Tony Song, Sun- ishchal Dev, Kevin Zhu, and Maheep Chaudhary. 2026. PALADIN: Self-Correcting Language Model Agents to Cure Tool-Failure Cases. InLLM-based Multi-Agent Systems: Towards Responsible, Reliable, and Scalable Agentic Systems. https: //openreview.net/forum?id=NVTtoO297p
2026
-
[38]
Haoyu Wang, Christopher M Poskitt, and Jun Sun. 2025. Agentspec: Cus- tomizable runtime enforcement for safe and reliable llm agents.arXiv preprint arXiv:2503.18666(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Wenxuan Wang, Shi Juluan, Zixuan Ling, Yuk-Kit Chan, Chaozheng Wang, Cheryl Lee, Youliang Yuan, Jen-tse Huang, Wenxiang Jiao, and Michael R. Lyu. 2025. Conference’17, July 2017, Washington, DC, USA Yining She, Yiliang Liang, and Eunsuk Kang Learning to Ask: When LLM Agents Meet Unclear Instruction. InProceedings of the 2025 Conference on Empirical Methods...
-
[40]
Yidong Wang, Yunze Song, Tingyuan Zhu, Xuanwang Zhang, Zhuohao Yu, Hao Chen, Chiyu Song, Qiufeng Wang, Cunxiang Wang, Zhen Wu, Xinyu Dai, Yue Zhang, Wei Ye, and Shikun Zhang. 2026. TrustJudge: Inconsistencies of LLM-as- a-Judge and How to Alleviate Them. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id...
2026
-
[41]
Hui Wei, Shenghua He, Tian Xia, Fei Liu, Andy Wong, Jingyang Lin, and Mei Han. 2025. Systematic Evaluation of LLM-as-a-Judge in LLM Alignment Tasks: Explainable Metrics and Diverse Prompt Templates. InICLR 2025 Workshop on Building Trust in Language Models and Applications. https://openreview.net/ forum?id=CAgBCSt8gL
2025
-
[42]
Yuhao Wu, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal
-
[43]
InNetwork and Distributed System Security (NDSS) Symposium
IsolateGPT: An Execution Isolation Architecture for LLM-Based Agentic Systems. InNetwork and Distributed System Security (NDSS) Symposium
-
[44]
Zhen Xiang, Linzhi Zheng, Yanjie Li, Junyuan Hong, Qinbin Li, Han Xie, Jiawei Zhang, Zidi Xiong, Chulin Xie, Carl Yang, Dawn Song, and Bo Li. 2025. GuardA- gent: Safeguard LLM Agents via Knowledge-Enabled Reasoning. InForty-second International Conference on Machine Learning. https://openreview.net/forum? id=2nBcjCZrrP
2025
-
[45]
Chenyang Yang, Yike Shi, Qianou Ma, Michael Xieyang Liu, Christian Käst- ner, and Tongshuang Wu. 2025. What Prompts Don’t Say: Understanding and Managing Underspecification in LLM Prompts.arXiv preprint arXiv:2505.13360 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2023
-
[47]
Will Yeadon, Tom Hardy, Paul Mackay, and Elise Agra. 2026. Criterion- referenceability determines LLM-as-a-judge validity across physics assessment formats.arXiv preprint arXiv:2603.14732(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [48]
-
[49]
Michael JQ Zhang and Eunsol Choi. 2025. Clarify when necessary: Resolving ambiguity through interaction with lms. InFindings of the Association for Com- putational Linguistics: NAACL 2025. 5526–5543
2025
-
[50]
Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wenqiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, and Tat-Seng Chua. 2024. CLAMBER: A benchmark of identifying and clarifying ambiguous information needs in large language mod- els. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10746–10766
2024
-
[51]
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. 2024. Agent-safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.