PACE: Phase-Aware Chunk Execution for Robot Policies with Action Chunking
Pith reviewed 2026-06-28 18:53 UTC · model grok-4.3
The pith
Robot policies achieve higher success by selecting execution horizons at low-speed points in predicted action chunks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
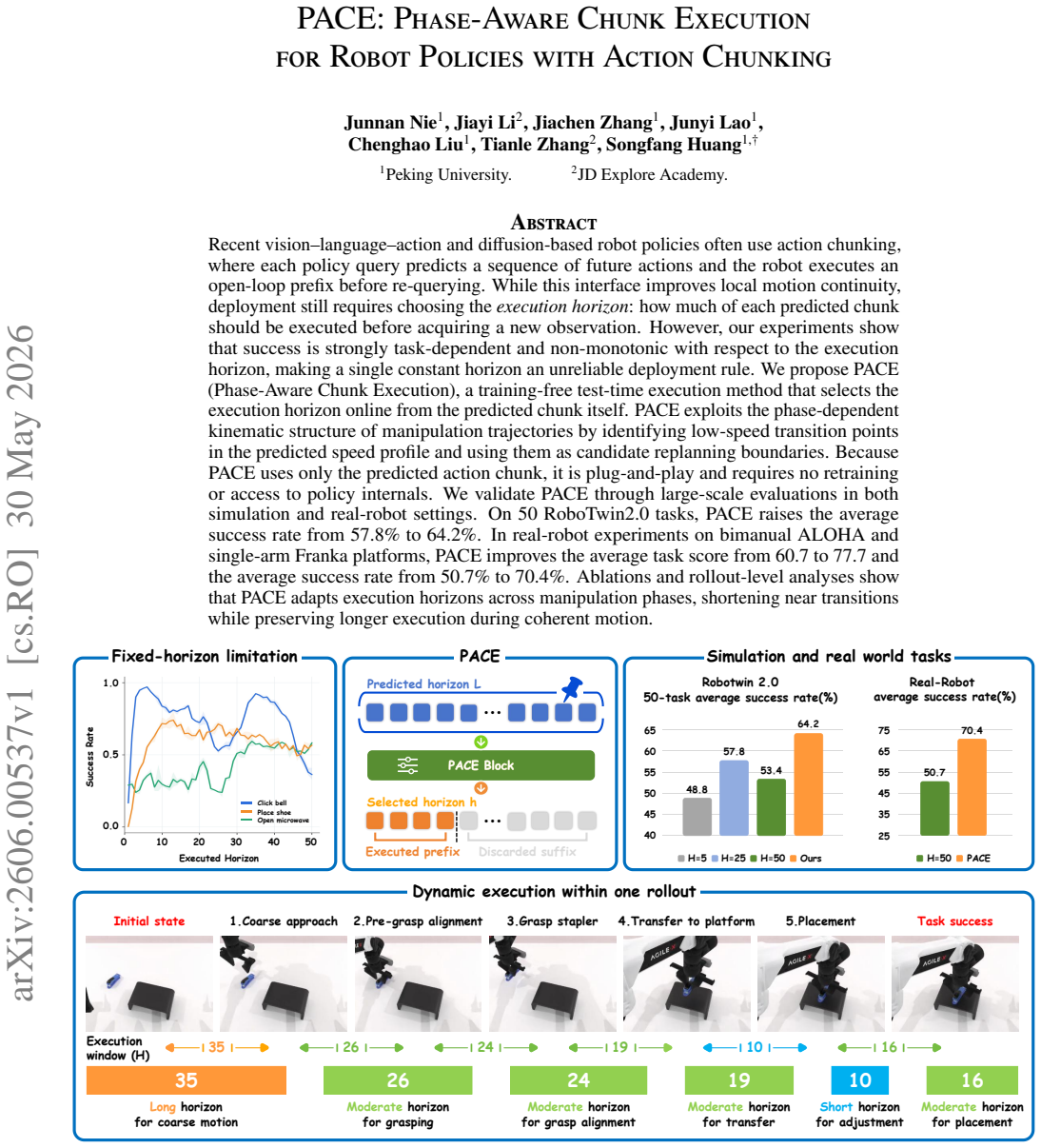
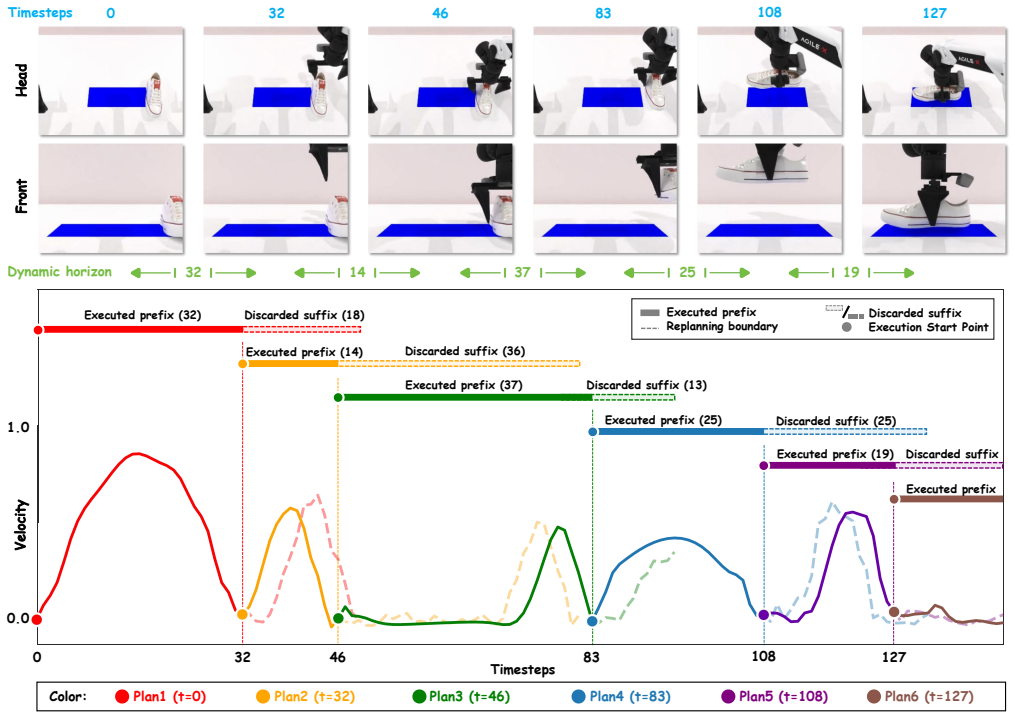
The paper claims that identifying low-speed transition points in the predicted speed profile of an action chunk and using them as execution horizons improves policy performance by adapting to the phase-dependent kinematic structure of manipulation trajectories.
What carries the argument
Low-speed transition points in the predicted speed profile, used as replanning boundaries.
If this is right
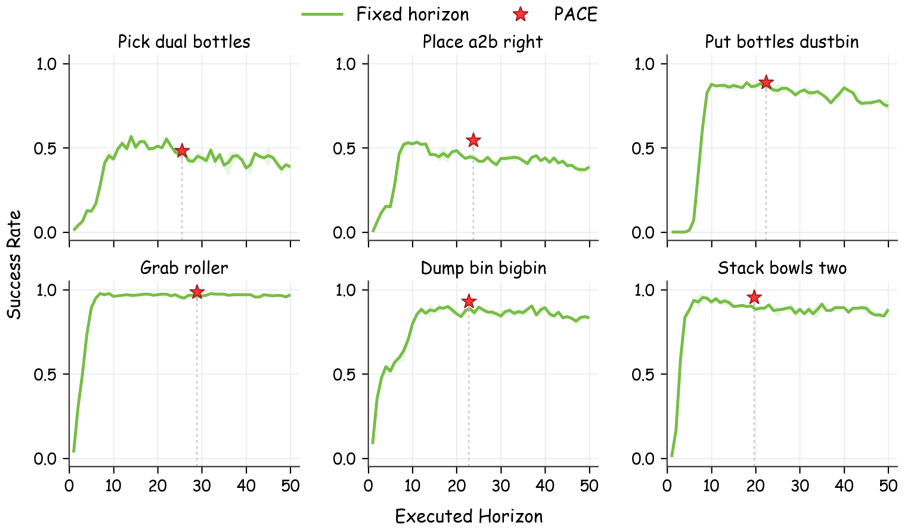
- Average success rate across 50 simulation tasks rises from 57.8 percent to 64.2 percent.
- Average real-robot success rate rises from 50.7 percent to 70.4 percent.
- Execution length shortens near detected transitions and lengthens during steady motion phases.
- The selection rule applies to any existing chunking policy without retraining or internal access.
Where Pith is reading between the lines
- Phase detection from predicted motion profiles could extend to other sequential prediction settings that contain natural pause points.
- Combining the selection rule with policy training that shapes speed profiles might produce further gains.
- The approach may show different reliability on tasks whose trajectories lack clear low-speed transitions.
Load-bearing premise
Low-speed points detected in the predicted chunk mark suitable places to stop executing and query the policy again.
What would settle it
A side-by-side test on the same tasks and policies where fixed-horizon execution matches or exceeds the success rates obtained by stopping at the detected low-speed points.
Figures








read the original abstract
Recent vision-language-action and diffusion-based robot policies often use action chunking, where each policy query predicts a sequence of future actions and the robot executes an open-loop prefix before re-querying. While this interface improves local motion continuity, deployment still requires choosing the execution horizon: how much of each predicted chunk should be executed before acquiring a new observation. However, our experiments show that success is strongly task-dependent and non-monotonic with respect to the execution horizon, making a single constant horizon an unreliable deployment rule. We propose PACE (Phase-Aware Chunk Execution), a training-free test-time execution method that selects the execution horizon online from the predicted chunk itself. PACE exploits the phase-dependent kinematic structure of manipulation trajectories by identifying low-speed transition points in the predicted speed profile and using them as candidate replanning boundaries. Because PACE uses only the predicted action chunk, it is plug-and-play and requires no retraining or access to policy internals. We validate PACE through large-scale evaluations in both simulation and real-robot settings. On 50 RoboTwin2.0 tasks, PACE raises the average success rate from 57.8% to 64.2%. In real-robot experiments on bimanual ALOHA and single-arm Franka platforms, PACE improves the average task score from 60.7 to 77.7 and the average success rate from 50.7% to 70.4%. Ablations and rollout-level analyses show that PACE adapts execution horizons across manipulation phases, shortening near transitions while preserving longer execution during coherent motion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PACE, a training-free test-time method for action-chunking robot policies that selects variable execution horizons by identifying low-speed transition points in the open-loop predicted speed profile of each chunk. It claims this exploits phase-dependent kinematic structure in manipulation trajectories, yielding average success-rate gains from 57.8% to 64.2% across 50 RoboTwin2.0 tasks and from 50.7% to 70.4% on real bimanual ALOHA and single-arm Franka platforms, with ablations showing adaptation across phases.
Significance. If the core assumption holds and is properly validated, the result would be significant for deployment of existing chunking policies: it supplies a simple, plug-and-play rule that avoids the task-dependent non-monotonicity of fixed horizons without retraining or policy internals. The scale of the evaluation (50 simulation tasks plus real-robot platforms) and the inclusion of rollout-level analyses are strengths that would support broader adoption if the phase-transition mapping is shown to be reliable rather than an artifact of prediction noise.
major comments (3)
- [Method] Method section: the exact detection rule for 'low-speed transition points' (speed threshold, local-minima criterion, derivative sign change, or smoothing parameters) is never stated. This is load-bearing for the central claim, because the reported gains are attributed specifically to these points marking appropriate replanning boundaries rather than to any variable-horizon schedule.
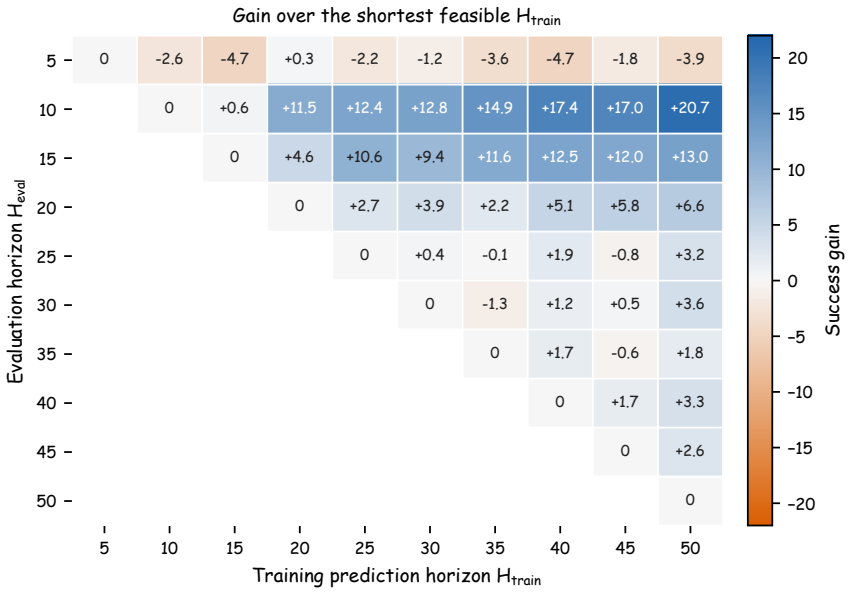
- [Experiments / Ablations] Experiments / Ablations: no control is presented that applies an alternative variable-horizon rule (e.g., random lengths within the same range, or lengths chosen by a different statistic of the chunk) and shows that the performance lift disappears. Without this, it remains possible that any non-constant horizon would produce similar gains, undermining the claim that the phase-aware speed-profile rule is responsible for the 6.4 pp and 19.7 pp improvements.
- [Results] Results: the reported averages (57.8 % → 64.2 % on 50 tasks; 50.7 % → 70.4 % real-robot) are given without per-task or aggregate error bars, trial counts, or statistical significance tests. Because the central claim is a quantitative improvement whose magnitude is task-dependent and non-monotonic, the absence of these statistics leaves the reliability of the gains unassessable.
minor comments (2)
- [Abstract / Results] The abstract and results text use both 'task score' and 'success rate' without an explicit definition or mapping between the two metrics.
- [Figures] Figure captions for rollout analyses should state the number of trajectories visualized and whether the shown speed profiles are from successful or failed rollouts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the potential significance of PACE for existing chunking policies. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Method] Method section: the exact detection rule for 'low-speed transition points' (speed threshold, local-minima criterion, derivative sign change, or smoothing parameters) is never stated. This is load-bearing for the central claim, because the reported gains are attributed specifically to these points marking appropriate replanning boundaries rather than to any variable-horizon schedule.
Authors: We agree that an explicit algorithmic description is necessary for reproducibility and to substantiate the central claim. The revised manuscript will add a dedicated subsection detailing the low-speed transition point detector, including the precise speed threshold, local-minima criterion, derivative conditions, and any smoothing or filtering parameters. revision: yes
-
Referee: [Experiments / Ablations] Experiments / Ablations: no control is presented that applies an alternative variable-horizon rule (e.g., random lengths within the same range, or lengths chosen by a different statistic of the chunk) and shows that the performance lift disappears. Without this, it remains possible that any non-constant horizon would produce similar gains, undermining the claim that the phase-aware speed-profile rule is responsible for the 6.4 pp and 19.7 pp improvements.
Authors: Our existing ablations already demonstrate that PACE produces phase-dependent horizon adaptation (shortening near transitions) that fixed horizons cannot match, and that success is non-monotonic with constant horizons. Nevertheless, we acknowledge that an explicit random or alternative-statistic variable-horizon control would more directly isolate the contribution of the speed-profile rule. We will add this comparison in the revised experiments section. revision: yes
-
Referee: [Results] Results: the reported averages (57.8 % → 64.2 % on 50 tasks; 50.7 % → 70.4 % real-robot) are given without per-task or aggregate error bars, trial counts, or statistical significance tests. Because the central claim is a quantitative improvement whose magnitude is task-dependent and non-monotonic, the absence of these statistics leaves the reliability of the gains unassessable.
Authors: We agree that error bars, trial counts, and significance testing would strengthen the quantitative claims. The revised manuscript will report per-task and aggregate standard deviations (where multiple trials per task exist), explicit trial counts, and appropriate statistical tests for the reported improvements. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes PACE as a heuristic, training-free method that selects variable execution horizons by detecting low-speed points in the open-loop predicted action chunk's speed profile. No equations, fitted parameters, self-citations, or uniqueness theorems are invoked that would reduce the reported empirical gains (e.g., 57.8% to 64.2% success) to quantities defined by the method itself. Performance is measured on external benchmarks (RoboTwin2.0 tasks and real-robot platforms) independent of the heuristic's definition, so the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manipulation trajectories exhibit phase-dependent kinematic structure identifiable via low-speed points in predicted speed profiles.
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black et al. π0: A Vision-Language-Action Flow Model for General Robot Control. 2024.doi: 10.48550/ arXiv.2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan et al.RT-1: Robotics Transformer for Real-World Control at Scale. 2022.doi: 10 . 48550 / arXiv.2212.06817
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan et al.RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. 2023.doi:10.48550/arXiv.2307.15818
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.15818 2023
-
[5]
Jun Cen et al.WorldVLA: Towards Autoregressive Ac- tion World Model. 2025.doi: 10.48550/arXiv.2506. 21539
-
[6]
Tianxing Chen et al.RoboTwin 2.0: A Scalable Data Generator and Benchmark with Strong Domain Random- ization for Robust Bimanual Robotic Manipulation. 2025. doi:10.48550/arXiv.2506.18088
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.18088 2025
-
[7]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi et al.Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. 2023.doi: 10 . 48550 / arXiv.2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Danny Driess et al.PaLM-E: An Embodied Multimodal Language Model. 2023.doi: 10.48550/arXiv.2303. 03378
-
[9]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
Zipeng Fu et al.Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleop- eration. 2024.doi:10.48550/arXiv.2401.02117
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.02117 2024
-
[10]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence et al. π0.5: A Vision-Language- Action Model with Open-World Generalization. 2025.doi: 10.48550/arXiv.2504.16054
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.16054 2025
-
[11]
Mixture of Horizons in Action Chunking
Dong Jing et al.Mixture of Horizons in Action Chunking. 2025.doi:10.48550/arXiv.2511.19433
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.19433 2025
-
[12]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky et al.DROID: A Large-Scale In- The-Wild Robot Manipulation Dataset. 2024.doi: 10 . 48550/arXiv.2403.12945
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim et al.Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success. 2025.doi: 10. 48550/arXiv.2502.19645
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Towards Learning Hierarchical Skills for Multi-Phase Manipulation Tasks
Oliver Kroemer et al. “Towards Learning Hierarchical Skills for Multi-Phase Manipulation Tasks”. In:2015 IEEE International Conference on Robotics and Automa- tion (ICRA). 2015.doi: 10.1109/ICRA.2015.7139389
-
[16]
Autonomous Framework for Segmenting Robot Trajectories of Ma- nipulation Task
Sang Hyoung Lee, Il Hong Suh, et al. “Autonomous Framework for Segmenting Robot Trajectories of Ma- nipulation Task”. In: (2015).doi: 10 . 1007 / s10514 - 014-9397-9
2015
-
[17]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu et al.RDT-1B: A Diffusion Foundation Model for Bimanual Manipulation. 2024.doi: 10.48550/ arXiv.2410.07864
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration et al.Open X- Embodiment: Robotic Learning Datasets and RT-X Mod- els. 2023.doi:10.48550/arXiv.2310.08864
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08864 2023
-
[19]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch et al.FAST: Efficient Action Tokenization for Vision-Language-Action Models. 2025.doi: 10.48550/ arXiv.2501.09747
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Mustafa Shukor et al.SmolVLA: A Vision-Language- Action Model for Affordable and Efficient Robotics. 2025. doi:10.48550/arXiv.2506.01844
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.01844 2025
-
[21]
Octo Model Team et al.Octo: An Open-Source Gener- alist Robot Policy. 2024.doi: 10.48550/arXiv.2405. 12213
-
[22]
Homer Walke et al.BridgeData V2: A Dataset for Robot Learning at Scale. 2023.doi: 10.48550/arXiv.2308. 12952
-
[23]
Haoxuan Wang et al.Real-Time Robot Execution with Masked Action Chunking. 2026.doi: 10.48550/arXiv. 2601.20130
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[24]
VLA Knows Its Limits: Adaptive Execution Horizons for Robot Policies
Haoxuan Wang et al.VLA Knows Its Limits. 2026.doi: 10.48550/arXiv.2602.21445
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.21445 2026
-
[25]
Adina Yakefu et al.RoboChallenge: Large-scale Real- robot Evaluation of Embodied Policies. 2025.doi: 10. 48550/arXiv.2510.17950
-
[26]
World Action Models are Zero-shot Policies
Seonghyeon Ye et al.World Action Models are Zero-shot Policies. 2026.doi:10.48550/arXiv.2602.15922
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.15922 2026
-
[27]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze et al.3D Diffusion Policy: Generalizable Vi- suomotor Policy Learning via Simple 3D Representations. 2024.doi:10.48550/arXiv.2403.03954
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.03954 2024
-
[28]
JoyAI-RA 0.1: A Foundation Model for Robotic Autonomy
Tianle Zhang et al.JoyAI-RA 0.1: A Foundation Model for Robotic Autonomy. 2026.doi: 10 . 48550 / arXiv . 2604.20100
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z. Zhao et al.Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. 2023.doi: 10. 48550/arXiv.2304.13705. 10 A PACE ImplementationNotes PACE is applied only at test time and does not modify or retrain the base policy. After each policy query, it analyzes the predicted action chunk and selects how many actions to execute before the next ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.