Meltdown: Circuits and Bifurcations in Point-Cloud-Conditioned 3D Diffusion Transformers
Pith reviewed 2026-05-21 13:19 UTC · model grok-4.3
The pith
Tiny point cloud perturbations fracture 3D diffusion transformer outputs by committing early to directional cross-attention drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
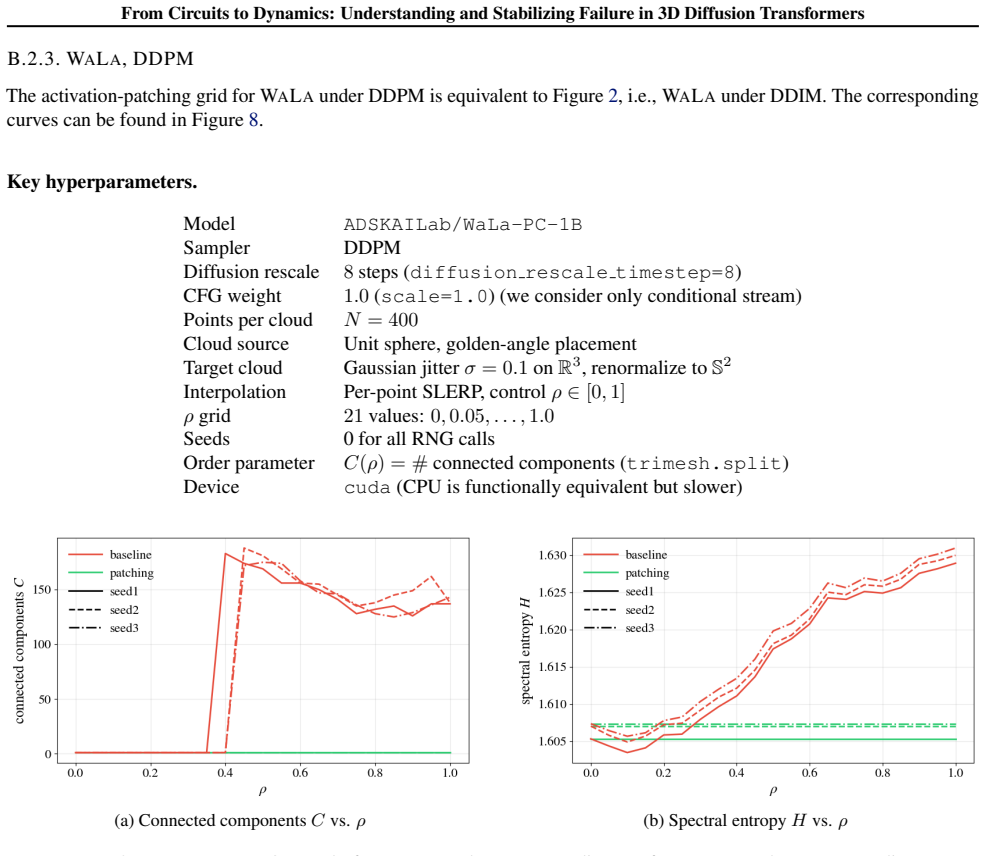
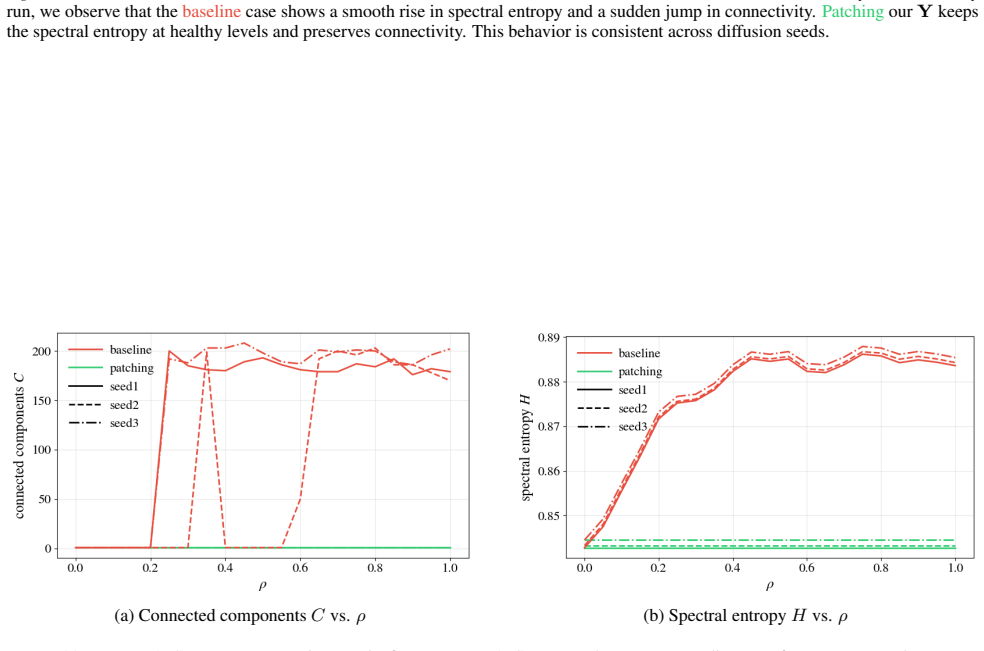
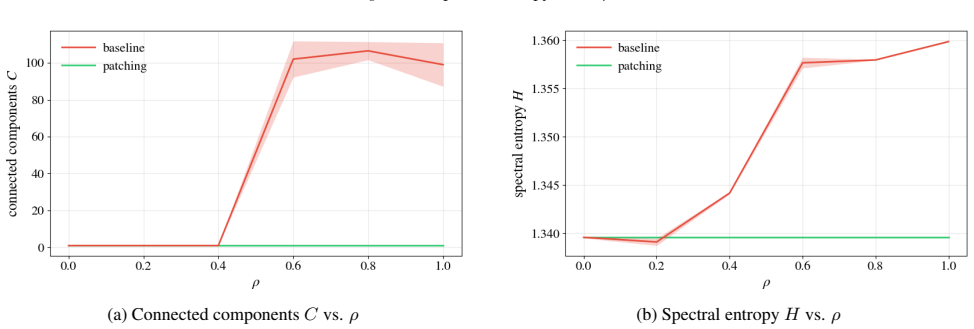
Meltdown is governed by how uniformly the points are distributed on the surface, faithfully transduced through the point-cloud encoder, and committed by a single early-denoising cross-attention write in the diffusion backbone. Diffusion-trajectory ensembles exhibit symmetry-breaking near this commit step, consistent with a bifurcation of the reverse process. Through matched-magnitude controls the variable on which the model commits is shown to be directional and concentrated in a low-rank subspace of the write's perturbation drift. PowerRemap reshapes the singular spectrum of the localized write to suppress this drift.
What carries the argument
The early-denoising cross-attention write that commits the reconstruction trajectory to a low-rank directional drift subspace determined by input point uniformity.
If this is right
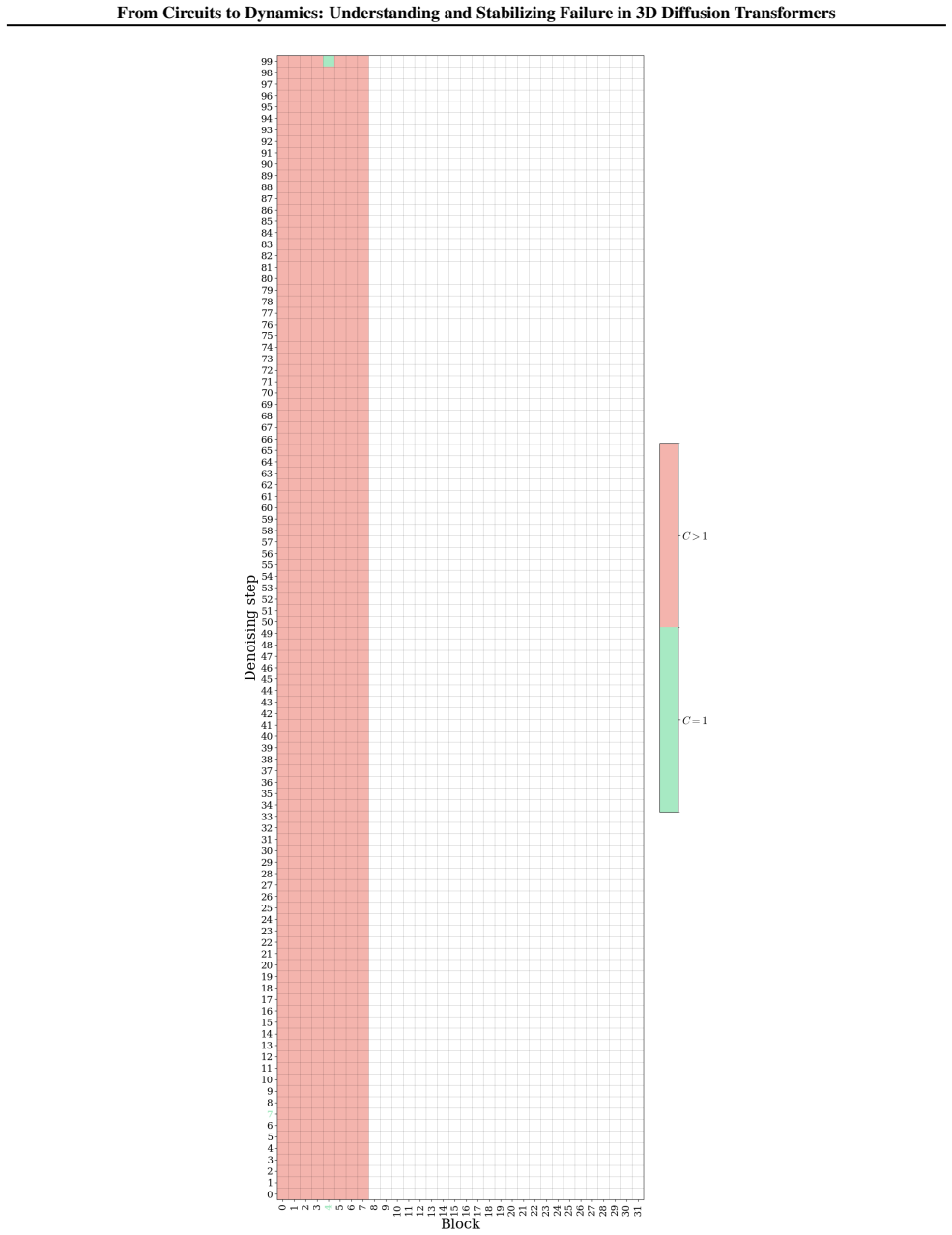
- Adversarial search recovers Meltdown in 89.9-100% of shapes across WaLa and Make-a-Shape on GSO and SimJEB under both DDPM and DDIM sampling.
- PowerRemap achieves rescue rates of 98.3% on WaLa and 84.6% on Make-a-Shape by suppressing the identified drift.
- The model commits to the failure variable at a single early step rather than gradually across the full trajectory.
- The commit variable is directional and low-rank, not explained by perturbation magnitude alone.
Where Pith is reading between the lines
- Similar early-commit bifurcations in cross-attention could appear in other conditional diffusion models for images or video when inputs contain small structured noise.
- Targeted spectrum reshaping at inference time may offer a general lightweight way to improve robustness in transformer-based generative models without retraining.
- Further work could test whether encoder modifications that better preserve surface uniformity reduce the need for test-time corrections.
Load-bearing premise
The observed symmetry-breaking and low-rank drift in the cross-attention write are causal for Meltdown rather than merely correlated with the fracturing.
What would settle it
Running the same perturbed point clouds through the model while reshaping the singular spectrum of the early cross-attention write during the first denoising steps and checking whether fracturing is prevented.
Figures












read the original abstract
Sparse point clouds are a common input modality for 3D surface reconstruction, including in safety-critical settings such as surgical navigation and autonomous perception. Recent point-cloud-conditioned 3D diffusion transformers achieve state-of-the-art results in this regime by leveraging learned priors. We show that these models can fail catastrophically under realistic input variation, and present a mechanistic case study of why. We identify a failure mode we call Meltdown: tiny on-surface perturbations to a sparse input point cloud can fracture the reconstructed output into hundreds of disconnected pieces. Adversarial search recovers Meltdown in 89.9-100% of shapes across the two open-weight state-of-the-art architectures we study (WaLa, Make-a-Shape) on real-world datasets (GSO, SimJEB) and under both DDPM and DDIM sampling. We trace Meltdown along the forward pass: it is governed by how uniformly the points are distributed on the surface, faithfully transduced through the point-cloud encoder, and committed by a single early-denoising cross-attention write in the diffusion backbone. Diffusion-trajectory ensembles exhibit symmetry-breaking near this commit step, consistent with a bifurcation of the reverse process. Through a suite of matched-magnitude controls, we show that the variable on which the model commits is directional, concentrated in a low-rank subspace of the write's perturbation drift. Motivated by this finding, we introduce PowerRemap, a test-time control that reshapes the singular spectrum of the localized write to suppress this drift, with rescue rates of 98.3% on WaLa and 84.6% on Make-a-Shape. Together, these results link a circuit-level cross-attention mechanism to a trajectory-level account of the failure, demonstrating how mechanistic analysis can explain and guide behavior in conditional diffusion transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a mechanistic analysis of a catastrophic failure mode, termed 'Meltdown', in point-cloud-conditioned 3D diffusion transformers. Small on-surface perturbations to sparse point clouds cause the model to produce fractured, disconnected surface reconstructions. The authors trace this to non-uniform point distributions being encoded and committed through a low-rank directional drift in a single early-denoising cross-attention write, leading to symmetry-breaking bifurcations in the reverse diffusion process. They validate this with high adversarial recovery rates across datasets and samplers, and propose PowerRemap, a test-time intervention that reshapes the singular spectrum of the attention write to suppress the drift, achieving rescue rates of 98.3% and 84.6% on the two models studied.
Significance. This work provides a detailed circuit-level and trajectory-level account of failure in conditional generative models for 3D reconstruction. By linking input geometry statistics to specific internal mechanisms and demonstrating a targeted fix, it contributes to understanding robustness in diffusion transformers. The empirical results on real-world datasets and multiple architectures strengthen the case for the proposed mechanism, potentially informing safer deployment in critical applications such as surgical navigation.
major comments (2)
- The matched-magnitude controls (described in the experiments tracing the commit step) are presented as isolating a directional low-rank variable in the early-denoising cross-attention write. However, these controls do not conclusively rule out confounding effects on attention patterns, noise conditioning, or downstream denoising steps, leaving open whether the observed symmetry-breaking is causal for Meltdown or a correlational downstream effect of encoder layers or global trajectory statistics.
- §3 (or equivalent section defining the perturbation and tracing): the claim that Meltdown is 'committed by a single early-denoising cross-attention write' relies on the assumption that the on-surface perturbation is faithfully transduced without earlier confounding; the precise operational definition of the perturbation and the singular-spectrum reshaping in PowerRemap needs explicit equations or pseudocode to verify that the intervention targets only the identified drift without altering reconstruction fidelity.
minor comments (2)
- The abstract and introduction mention 'WaLa' and 'Make-a-Shape' without immediate expansion or citation; add parenthetical definitions or references at first use for reader clarity.
- Trajectory ensemble visualizations would benefit from explicit axis labels or legends indicating the time step of the commit and the metric used to quantify symmetry-breaking.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address the major comments point by point below, providing clarifications and outlining planned revisions where appropriate.
read point-by-point responses
-
Referee: The matched-magnitude controls (described in the experiments tracing the commit step) are presented as isolating a directional low-rank variable in the early-denoising cross-attention write. However, these controls do not conclusively rule out confounding effects on attention patterns, noise conditioning, or downstream denoising steps, leaving open whether the observed symmetry-breaking is causal for Meltdown or a correlational downstream effect of encoder layers or global trajectory statistics.
Authors: We acknowledge the referee's point that additional controls could further strengthen the causal argument. Our matched-magnitude controls were constructed by applying perturbations of equivalent L2 norm to the cross-attention write but in orthogonal directions within the low-rank subspace, demonstrating that only the specific directional drift correlates with the bifurcation. To address potential confounders in downstream steps, we will add new experiments in the revised manuscript that apply similar interventions at later timesteps and show that they do not induce Meltdown. This will help isolate the early commit step as the critical point. revision: partial
-
Referee: §3 (or equivalent section defining the perturbation and tracing): the claim that Meltdown is 'committed by a single early-denoising cross-attention write' relies on the assumption that the on-surface perturbation is faithfully transduced without earlier confounding; the precise operational definition of the perturbation and the singular-spectrum reshaping in PowerRemap needs explicit equations or pseudocode to verify that the intervention targets only the identified drift without altering reconstruction fidelity.
Authors: We agree that providing explicit definitions will improve clarity and verifiability. In the revised version, we will expand §3 to include the formal definition of the on-surface perturbation as a small additive displacement δ applied to a subset of points on the surface, with ||δ|| controlled to be below a threshold. Additionally, we will include pseudocode for PowerRemap, which computes the SVD of the attention output matrix W, identifies the top singular vectors corresponding to the drift, and rescales their singular values by a factor α < 1 while renormalizing to preserve the Frobenius norm, ensuring minimal impact on overall reconstruction quality as validated in our experiments. revision: yes
Circularity Check
No significant circularity; empirical tracing and controls are self-contained
full rationale
The paper's central account traces Meltdown via adversarial recovery rates, forward-pass observations of point uniformity and encoder transduction, symmetry-breaking in diffusion ensembles, and matched-magnitude controls isolating directional low-rank drift in an early cross-attention write. These steps rely on direct measurement and intervention rather than any equation or parameter that reduces to its own inputs by construction. PowerRemap is motivated by the observed singular-spectrum drift and evaluated on rescue rates without tautological re-use of fitted quantities or load-bearing self-citations. The analysis remains observational and interventional, with no self-definitional loops or renamed known results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify a failure mode we call Meltdown: tiny on-surface perturbations... committed by a single early-denoising cross-attention write... spectral entropy... PowerRemap... reshapes the singular spectrum
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
symmetry-breaking bifurcation of the reverse process... spontaneous symmetry breaking
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
cc/paper_files/paper/2021/file/ 4f5c422f4d49a5a807eda27434231040-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ 4f5c422f4d49a5a807eda27434231040-Paper. pdf. Golovanevsky, M., Rudman, W., Palit, V ., Singh, R., and Eickhoff, C. What do vlms notice? a mechanistic inter- pretability pipeline for gaussian-noise-free text-image cor- ruption and evaluation, 2025. URL https://arxiv. org/abs/2406.16320. Gorto...
-
[2]
doi: 10.48550/ARXIV .2502.03930. URL https: //doi.org/10.48550/arXiv.2502.03930. Karras, T., Aittala, M., Aila, T., and Laine, S. Elucidat- ing the design space of diffusion-based generative mod- els. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neural In- formation Processing Systems, volume 35, pp. 26565–...
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[3]
Locating and Editing Factual Associations in GPT
URL https://openreview.net/forum? id=xXs2GKXPnH. Lu, H., Yang, G., Fei, N., Huo, Y ., Lu, Z., Luo, P., and Ding, M. VDT: general-purpose video diffusion trans- formers via mask modeling. InThe Twelfth Interna- tional Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024a. URL https://openreview.net/forum?...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1088/0305-4470/12/11/017 2024
-
[4]
High-Resolution Image Synthesis with Latent Diffusion Models
URL https://openreview.net/forum? id=lxGFGMMSVl. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models, 2022. URL https://arxiv.org/ abs/2112.10752. Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolu- tional networks for biomedical image segmentation, 2015. URLhttps://arxiv.org...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-4135 2022
-
[5]
OpenReview.net, 2025. Wang, K. R., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J. Interpretability in the wild: a circuit for indi- rect object identification in GPT-2 small. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenRe- view.net, 2023a. URL https://openreview.net/ foru...
-
[6]
WALA first compresses the full wavelet tree with a convolutional VQ-V AE (stage 1), mapping the diffusible wavelet tree to a latent grid. The latent grid is then modeled by a 32-layer U-ViT (stage 2), where each transformer layer runs self-attention and cross-attention, totaling 32 cross-attention calls
-
[7]
The U-ViT backbone then downsamples this tensor to a bottleneck volume
MAKE-A-SHAPEskips the auto -encoder and instead packs selected wavelet coefficients into a compact grid. The U-ViT backbone then downsamples this tensor to a bottleneck volume. The bottleneck is traversed by a 16-layer U-ViT core—8 self-attention layers immediately followed by 8 cross-attention layers— before up-sampling restores the packed grid. A.2.2. C...
work page 2017
-
[8]
Datasets(B.3): This section details our experiments on GSO (Downs et al., 2022) and SimJEB (Whalen et al., 2021)
work page 2022
-
[9]
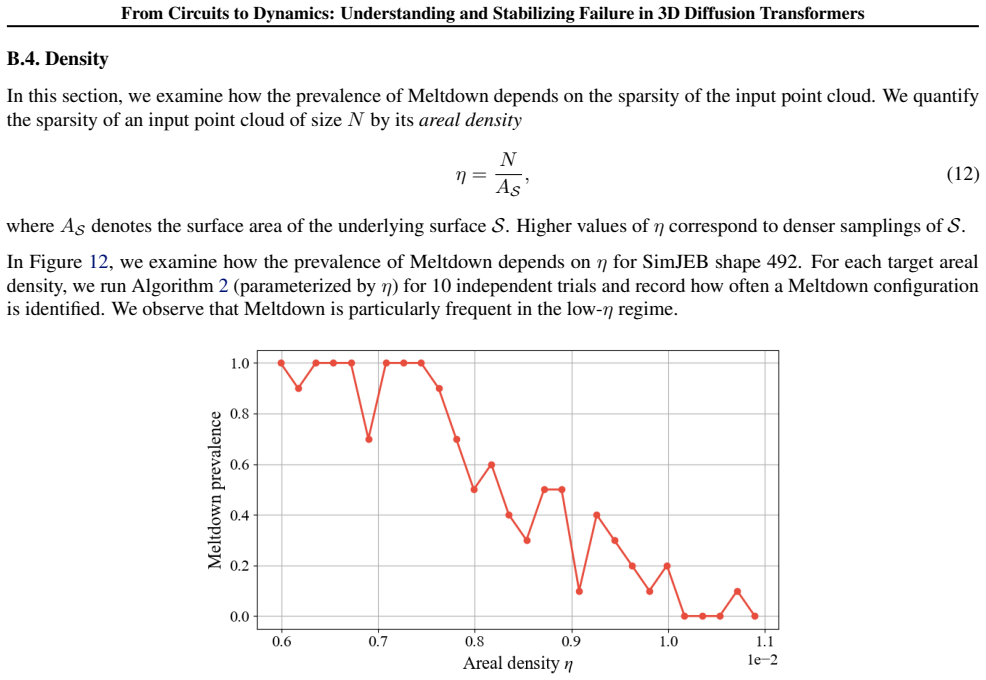
Density Study(B.4): This section examines how the prevalence of Meltdown depends on the sparsity of the input point cloud
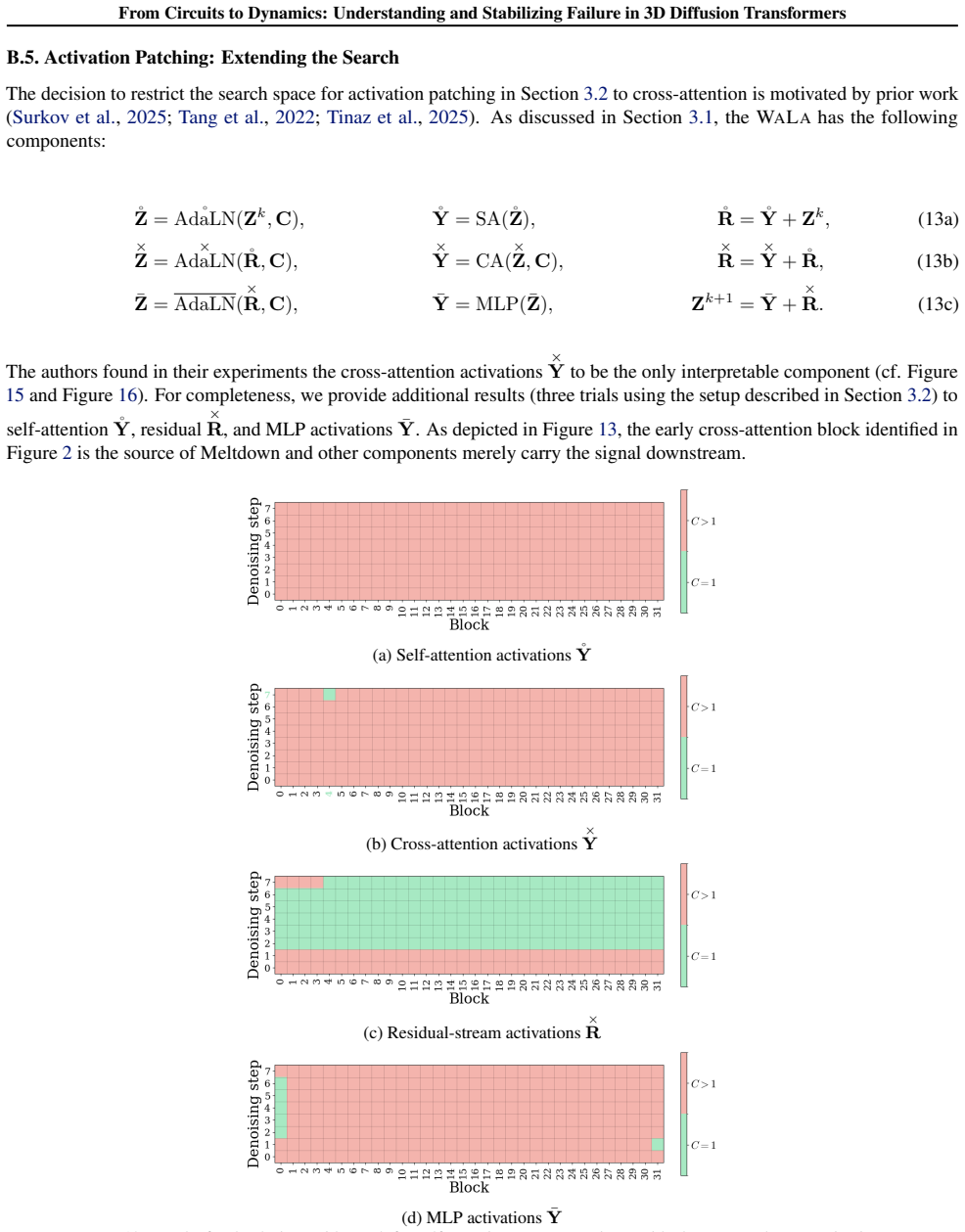
-
[10]
Extended Activation Patching(B.5): This section provides activation-patching results on additional components beyond cross-attention
-
[11]
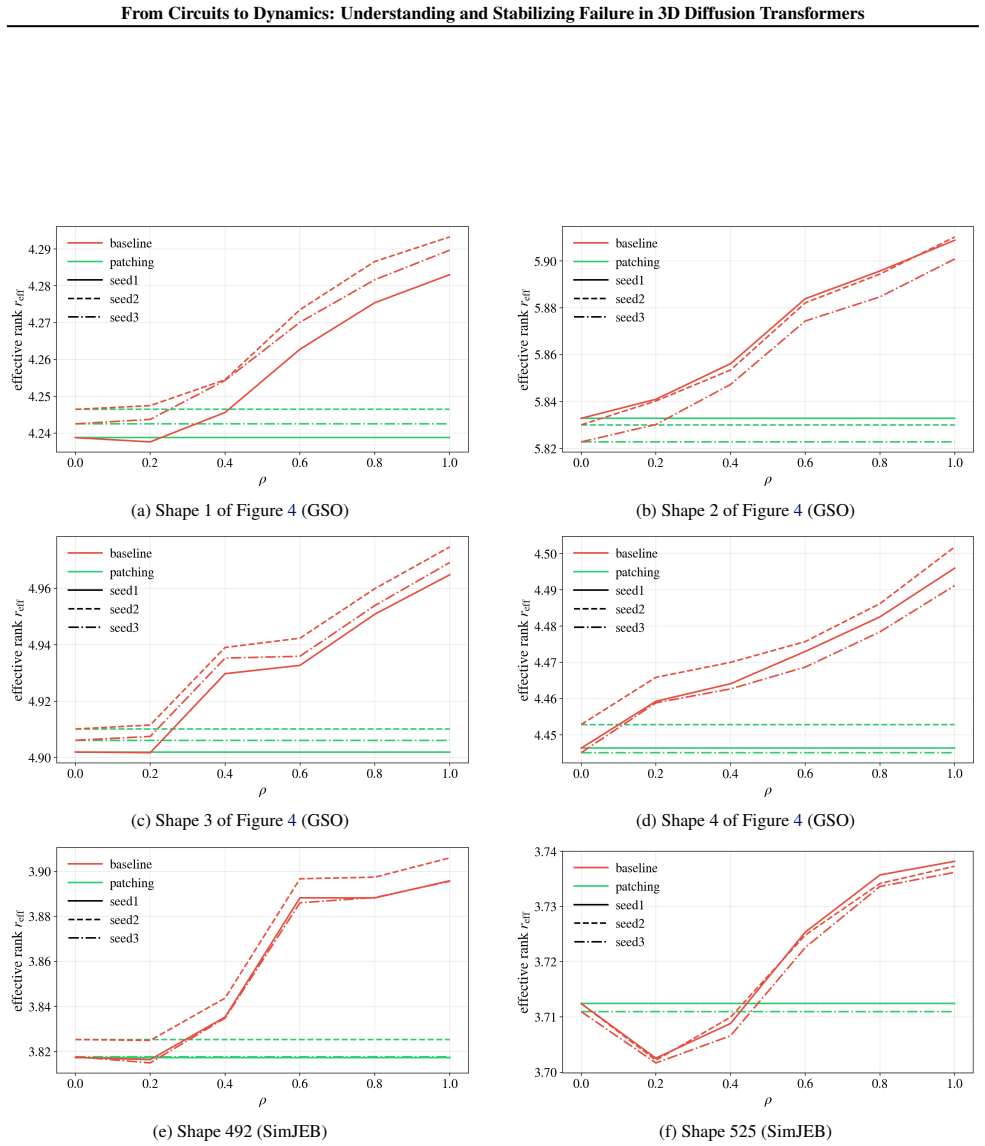
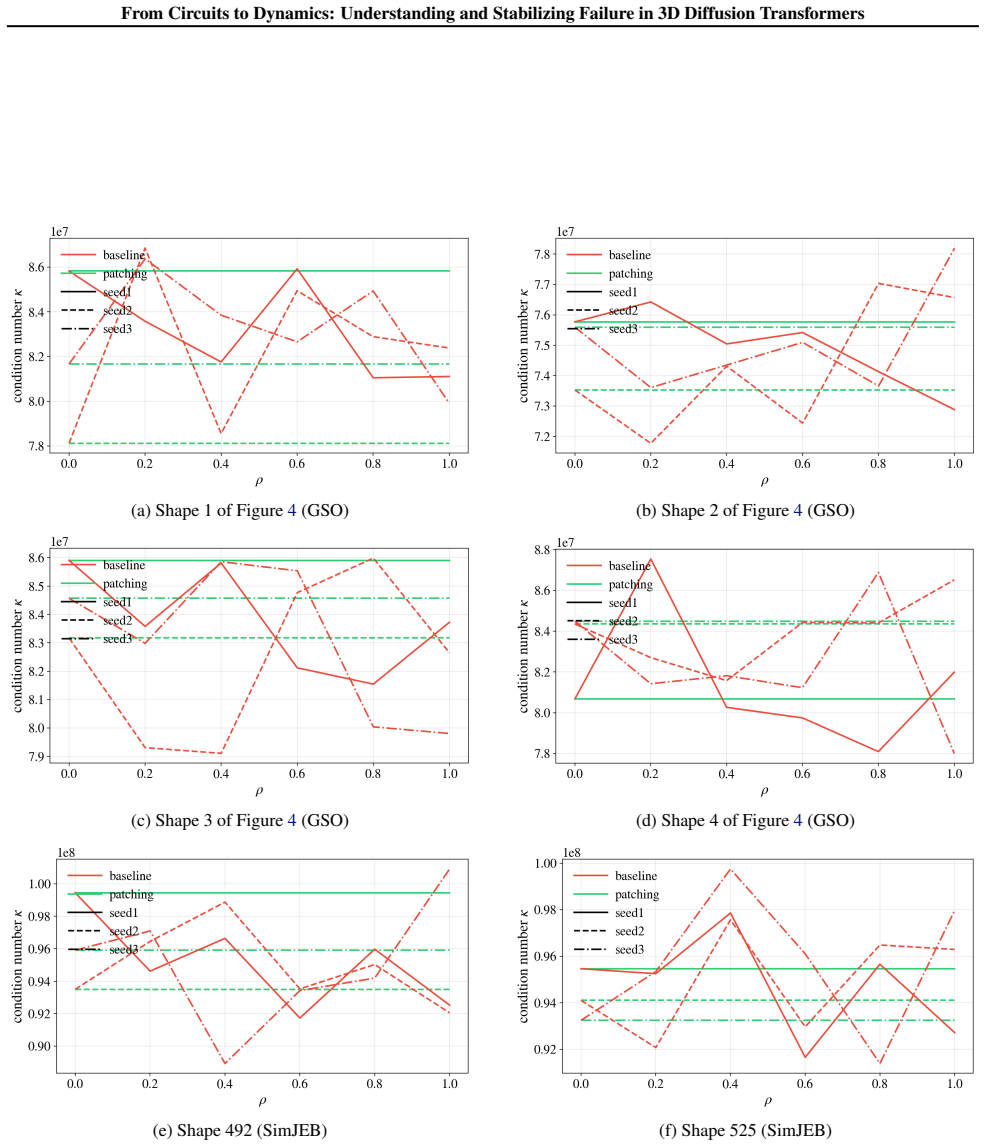
More Datapoints(B.6): This section provides further evidence that the patterns observed in Section 3.2-3.3 generalize when evaluated on more data points and random seeds
-
[12]
Additional Spectral Metrics(B.7): This section assesses additional spectral metrics as potential indicators of Meltdown
-
[13]
Multiple Objects(B.8): This section examines whether the Meltdown phenomenon and the effectiveness of PowerRemapextend beyond single-object inputs
-
[14]
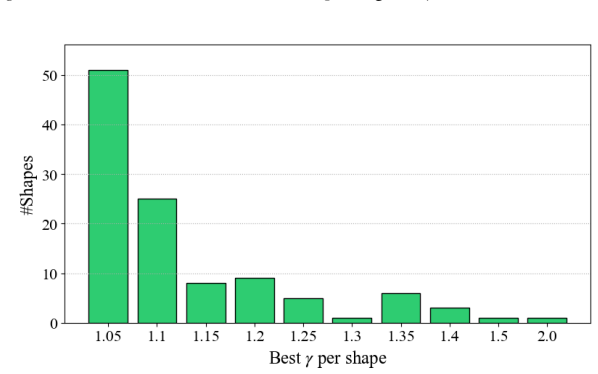
Examining PowerRemap strength(B.9): This section empirically investigates the influence of the PowerRemap Strengthγon reconstruction connectivity. 10.PowerRemap on Non-Meltdown Cases(B.10): This section empirically verifies that PowerRemap does not interfere with non-Meltdown cases. B.1. General This section provides a general overview on the experimental...
work page 2022
-
[15]
and assesses the effectiveness of PowerRemap as a mitigation strategy. SimJEB is a curated benchmark of 381 3D jet-engine bracket CAD models that wasnotincluded in the training data of either WALAor MAKE-A-SHAPE. All results in this section are obtained by applying the protocol described in Appendix B.3 to the SimJEB dataset. Evaluate PowerRemap For WALA,...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.