Structured Visual Evidence Decomposition for Evidence-Grounded Multimodal Screening of Obstructive Sleep Apnea-Hypopnea Syndrome
Pith reviewed 2026-06-30 13:36 UTC · model grok-4.3
The pith
Decomposing each frontal facial image into seven fixed anatomical queries produces structured evidence cards that, when fused with clinical data in a final adjudication step, deliver 94.86% sensitivity and 5.14% false-negative rate for bina
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
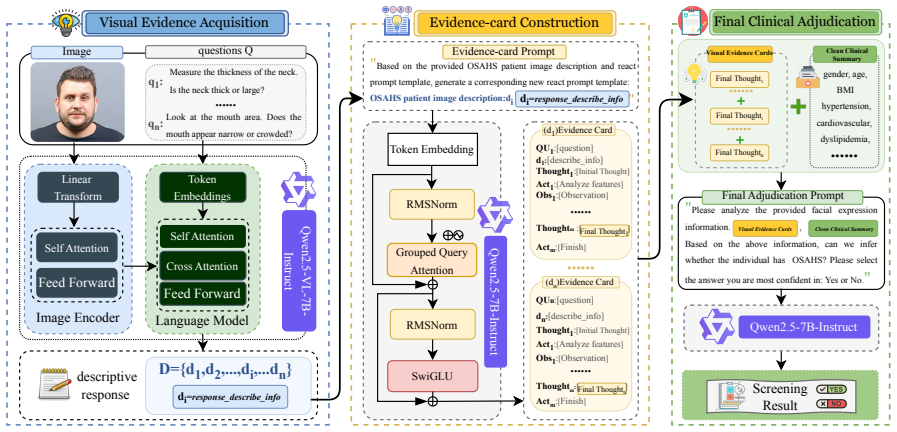
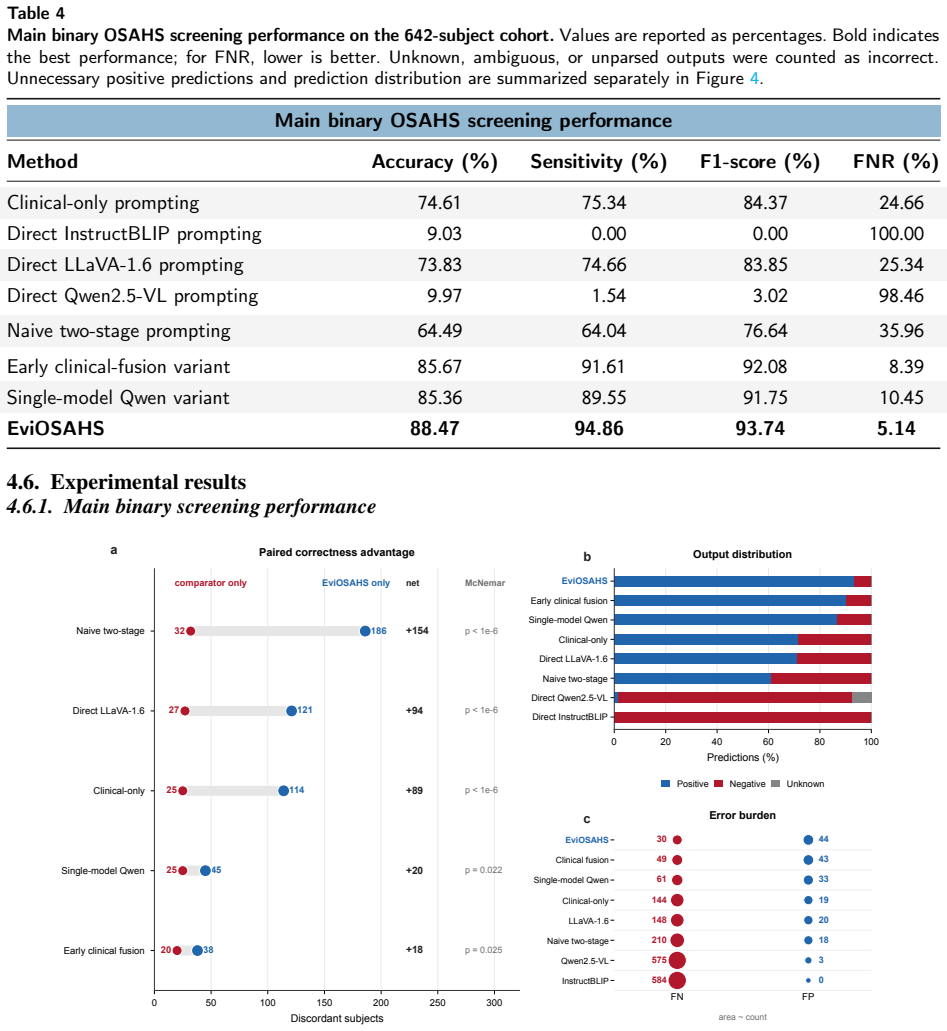
EviOSAHS separates visual evidence acquisition from final adjudication: each frontal facial image is decomposed into seven fixed anatomical queries; responses are converted into structured evidence cards listing target anatomy, visibility, risk direction, evidence strength, confidence and a concise summary; these cards are combined with a cleaned clinical profile only in the final LLM stage for balanced binary screening that maps normal subjects to negative and mild/moderate/severe OSAHS subjects to positive, yielding 88.47% accuracy, 94.86% sensitivity, 93.74% F1-score and 5.14% false-negative rate while providing full auditability of the 4,494 visual outputs.
What carries the argument
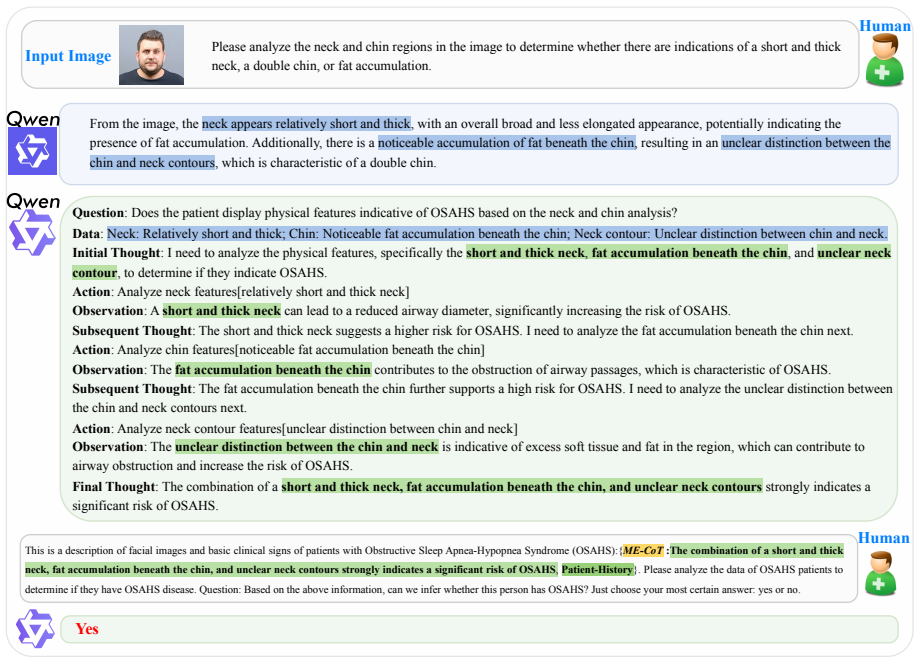
Structured evidence cards produced by seven fixed anatomical queries on frontal facial images, which isolate visual evidence collection from clinical adjudication and supply auditable inputs to the final screening LLM.
If this is right
- Seven-question visual decomposition plus balanced final adjudication are required to reach the reported high-sensitivity operating point.
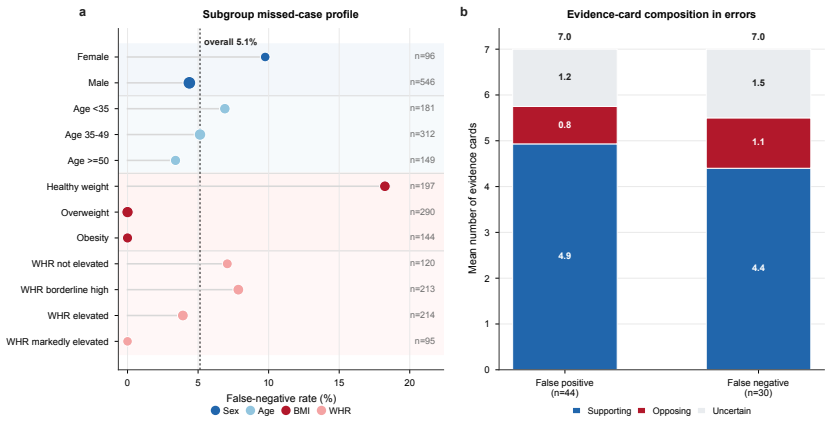
- The workflow supplies a fully auditable trace for every visual response, satisfying the 100% structured parse rate observed in the 4,494-output audit.
- The system is positioned as a triage assistant for pre-polysomnography screening rather than a standalone diagnostic.
- Performance gains over clinical-only prompting, direct multimodal prompting and naive two-stage pipelines hold under a single unified evaluation protocol.
Where Pith is reading between the lines
- The same query-to-card structure could be reused for other craniofacial screening tasks if new query sets are derived for those conditions.
- Replacing the final LLM adjudication with a lighter calibrated classifier might allow tighter control of the operating point without retraining the visual stage.
- External validation on images from different ethnic groups would test whether the fixed seven-query list remains sufficient or requires population-specific adjustments.
Load-bearing premise
The seven fixed anatomical queries on neck, chin, mouth, face/neck fat, lower jaw, midface and nose capture the clinically relevant craniofacial and neck cues needed for reliable high-sensitivity binary screening when turned into evidence cards.
What would settle it
A prospective test on an independent cohort of at least 300 new subjects in which the false-negative rate rises above 10% or the sensitivity falls below 85% when the same seven queries and evidence-card format are used.
Figures



read the original abstract
Effective pre-polysomnography screening for obstructive sleep apnea-hypopnea syndrome (OSAHS) requires combining clinical risk factors with visible craniofacial and neck cues. Directly prompting general-purpose multimodal foundation models for medical yes/no decisions can yield unstable, poorly calibrated outputs. We propose EviOSAHS, an evidence-grounded multimodal reasoning framework that separates image-only anatomical evidence acquisition from final clinical adjudication. Each frontal facial image is decomposed into seven fixed anatomical queries covering the neck, chin, mouth, face/neck fat, lower jaw, midface, and nose. Visual responses are converted into structured evidence cards recording target anatomy, visibility, risk direction, evidence strength, confidence, and a concise summary. These cards are combined with a cleaned clinical profile only in the final stage, where a large language model performs balanced binary screening adjudication. We evaluated EviOSAHS on a 642-subject cohort, mapping normal subjects to screening-negative and mild, moderate, or severe OSAHS subjects to screening-positive. EviOSAHS achieved 88.47% accuracy, 94.86% sensitivity, 93.74% F1-score, and a 5.14% false-negative rate, outperforming clinical-only prompting, direct multimodal prompting, and naive two-stage pipelines under a unified protocol. Ablations showed that seven-question visual decomposition and balanced final adjudication were critical to the high-sensitivity operating point. A question-level audit of 4,494 visual outputs showed a 100% structured parse rate and 93.88% high-visibility rate. EviOSAHS provides an auditable, high-sensitivity workflow for binary pre-polysomnography OSAHS screening, but should be viewed as a triage assistant rather than a diagnostic system. Prospective validation, external testing, and calibrated operating-point control are needed before clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EviOSAHS, an evidence-grounded multimodal framework for binary pre-polysomnography OSAHS screening. Frontal facial images are decomposed via seven fixed anatomical queries (neck, chin, mouth, face/neck fat, lower jaw, midface, nose) whose LLM responses are structured into evidence cards (target anatomy, visibility, risk direction, strength, confidence, summary). These cards are fused only at the final stage with a cleaned clinical profile for balanced LLM adjudication. On a 642-subject cohort (normal mapped to negative; mild/moderate/severe to positive), the method reports 88.47% accuracy, 94.86% sensitivity, 93.74% F1-score and 5.14% false-negative rate, outperforming clinical-only prompting, direct multimodal prompting and naive two-stage pipelines. Ablations confirm the necessity of the seven-query decomposition and balanced adjudication; a question-level audit of 4,494 outputs shows 100% structured parse rate and 93.88% high-visibility rate. The work positions the system as a triage assistant requiring prospective validation.
Significance. If the reported operating point generalizes, the structured decomposition-plus-evidence-card approach supplies an auditable, high-sensitivity alternative to unstable direct multimodal prompting for OSAHS triage. The explicit ablations, 100% parse-rate audit, and emphasis on prospective/external testing constitute concrete strengths that increase reproducibility and clinical interpretability. The result would be of interest to multimodal medical AI and sleep-medicine screening communities, though its practical significance hinges on demonstrating that the fixed seven-query set captures predictors beyond the internal cohort.
major comments (3)
- [Abstract] Abstract: the assertion that the seven fixed queries (neck, chin, mouth, face/neck fat, lower jaw, midface, nose) extract 'clinically relevant craniofacial and neck cues' is load-bearing for the 94.86% sensitivity claim, yet no derivation from AASM guidelines, expert consensus, or feature-importance analysis on the cohort is supplied; if key visible predictors (e.g., tongue base or lateral neck distribution) are systematically omitted, the high-sensitivity operating point may be cohort-specific rather than a general property of the decomposition method.
- [Evaluation] Evaluation section (implied by cohort and metric reporting): the exact cohort composition, inclusion/exclusion criteria, AHI thresholds used to map mild/moderate/severe labels to the positive class, and whether the reported operating point was selected post-hoc on the held-out set are not visible; these details are required to interpret the 5.14% false-negative rate and the unified-protocol comparisons.
- [Ablations] Ablation results (Abstract): while the paper states that 'seven-question visual decomposition and balanced final adjudication were critical,' the quantitative effect sizes of removing individual queries or altering the adjudication prompt are not tabulated, leaving unclear which components drive the sensitivity gain versus the baselines.
minor comments (1)
- [Methods] The manuscript would benefit from an explicit table listing the seven query templates and the exact JSON schema of the evidence cards to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the clarity and reproducibility of the manuscript. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the seven fixed queries (neck, chin, mouth, face/neck fat, lower jaw, midface, nose) extract 'clinically relevant craniofacial and neck cues' is load-bearing for the 94.86% sensitivity claim, yet no derivation from AASM guidelines, expert consensus, or feature-importance analysis on the cohort is supplied; if key visible predictors (e.g., tongue base or lateral neck distribution) are systematically omitted, the high-sensitivity operating point may be cohort-specific rather than a general property of the decomposition method.
Authors: We acknowledge that the manuscript does not supply an explicit derivation of the seven queries from AASM guidelines or a feature-importance analysis. The queries were selected to target externally visible craniofacial and neck features with established associations to OSAHS risk in the clinical literature (e.g., neck circumference, retrognathia, midface hypoplasia). In revision we will add a Methods subsection with supporting references to prior sleep-medicine studies that link these visible cues to AHI. Frontal images inherently limit visibility of intraoral structures such as the tongue base; this constraint is already implicit in our emphasis on prospective validation. The current ablations support the contribution of the chosen set, but we agree external cohorts are required to establish broader generalizability. revision: partial
-
Referee: [Evaluation] Evaluation section (implied by cohort and metric reporting): the exact cohort composition, inclusion/exclusion criteria, AHI thresholds used to map mild/moderate/severe labels to the positive class, and whether the reported operating point was selected post-hoc on the held-out set are not visible; these details are required to interpret the 5.14% false-negative rate and the unified-protocol comparisons.
Authors: We agree these details are essential for interpreting the reported metrics. The revised Evaluation section will explicitly state the cohort source, inclusion/exclusion criteria, the AHI mapping (normal: AHI < 5 as negative; mild 5–15, moderate 15–30, severe ≥30 as positive), and confirm that the operating point was chosen on the validation split rather than post-hoc on the test set. These additions will directly address interpretability of the false-negative rate and baseline comparisons. revision: yes
-
Referee: [Ablations] Ablation results (Abstract): while the paper states that 'seven-question visual decomposition and balanced final adjudication were critical,' the quantitative effect sizes of removing individual queries or altering the adjudication prompt are not tabulated, leaving unclear which components drive the sensitivity gain versus the baselines.
Authors: We concur that the current presentation lacks tabulated quantitative effect sizes. The revised manuscript will include a new table in the Ablations subsection reporting accuracy, sensitivity, specificity, and F1 for the full model, each single-query ablation, and variants with modified adjudication prompts (balanced vs. unbalanced). This will quantify the contribution of each component relative to the baselines. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports empirical performance metrics (88.47% accuracy, 94.86% sensitivity, etc.) measured directly on a held-out 642-subject cohort against baselines under a unified protocol. These outcomes are not derived from any internal equations, fitted parameters, or self-referential definitions that would force the reported numbers by construction. The seven fixed queries are introduced as an explicit design choice to cover craniofacial cues, with ablations confirming their contribution, but the evaluation treats them as inputs whose utility is tested rather than presupposed. No self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the derivation of the central claims. The result remains an externally falsifiable measurement on independent subjects.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visible craniofacial and neck anatomy in a frontal photo contains the cues needed for reliable OSAHS risk stratification when structured into the seven fixed queries.
Reference graph
Works this paper leans on
-
[1]
Estimation of the global prevalence and burden of obstructive sleep apnoea: a literature-based analysis.The Lancet respiratory medicine, 7(8):687–698, 2019
AdamVBenjafield,NajibTAyas,PeterREastwood,RaphaelHeinzer,MarySMIp,MaryJMorrell,CarlosMNunez,SanjayRPatel,Thomas Penzel, Jean-Louis Pépin, et al. Estimation of the global prevalence and burden of obstructive sleep apnoea: a literature-based analysis.The Lancet respiratory medicine, 7(8):687–698, 2019
2019
-
[2]
Diagnosis and management of obstructive sleep apnea: a review.Jama, 323(14):1389–1400, 2020
Daniel J Gottlieb and Naresh M Punjabi. Diagnosis and management of obstructive sleep apnea: a review.Jama, 323(14):1389–1400, 2020
2020
-
[3]
Obstructivesleepapneaandcardiovasculardisease:ascientificstatementfromtheamerican heart association.Circulation, 144(3):e56–e67, 2021
Yerem Yeghiazarians, Hani Jneid, Jeremy R Tietjens, Susan Redline, Devin L Brown, Nabil El-Sherif, Reena Mehra, Biykem Bozkurt, ChiadiEricsonNdumele,VirendKSomers,etal. Obstructivesleepapneaandcardiovasculardisease:ascientificstatementfromtheamerican heart association.Circulation, 144(3):e56–e67, 2021
2021
-
[4]
Sleepapnea:types,mechanisms,andclinicalcardiovascularconsequences.Journalofthe American College of Cardiology, 69(7):841–858, 2017
ShahrokhJavaheri,FerranBarbe,FranciscoCampos-Rodriguez,JeromeADempsey,RamiKhayat,SogolJavaheri,AtulMalhotra,MiguelA Martinez-Garcia,ReenaMehra,AllanIPack,etal. Sleepapnea:types,mechanisms,andclinicalcardiovascularconsequences.Journalofthe American College of Cardiology, 69(7):841–858, 2017
2017
-
[5]
Obstructive sleep apnea, hypertension, and cardiovascular risk: epidemiology, pathophysiology, and management.Current Cardiology Reports, 22(2):6, 2020
Liann Abu Salman, Rachel Shulman, and Jordana B Cohen. Obstructive sleep apnea, hypertension, and cardiovascular risk: epidemiology, pathophysiology, and management.Current Cardiology Reports, 22(2):6, 2020
2020
-
[6]
Stop-bang questionnaire: a practical approach to screen for obstructive sleep apnea.Chest, 149(3):631–638, 2016
Frances Chung, Hairil R Abdullah, and Pu Liao. Stop-bang questionnaire: a practical approach to screen for obstructive sleep apnea.Chest, 149(3):631–638, 2016
2016
-
[7]
Diagnosisandtreatmentofobstructivesleepapneainadults.Americanfamilyphysician, 94(5):355–360, 2016
MichaelSemelka,JonathanWilson,andRyanFloyd. Diagnosisandtreatmentofobstructivesleepapneainadults.Americanfamilyphysician, 94(5):355–360, 2016
2016
-
[8]
Claudio Vicini, Andrea De Vito, Marco Benazzo, Sabrina Frassineti, Aldo Campanini, Piercarlo Frasconi, and Eugenio Mira. The nose oropharynx hypopharynx and larynx (nohl) classification: a new system of diagnostic standardized examination for osahs patients.European Archives of Oto-Rhino-Laryngology, 269(4):1297–1300, 2012
2012
-
[9]
Facialphenotypeinobstructivesleepapnea–hypopneasyndrome:asystematicreviewandmeta-analysis.Journal of sleep research, 26(2):122–131, 2017
BahnAghaandAmaJohal. Facialphenotypeinobstructivesleepapnea–hypopneasyndrome:asystematicreviewandmeta-analysis.Journal of sleep research, 26(2):122–131, 2017
2017
-
[10]
Vishesh K Kapur, Dennis H Auckley, Susmita Chowdhuri, David C Kuhlmann, Reena Mehra, Kannan Ramar, and Christopher G Harrod. Clinical practice guideline for diagnostic testing for adult obstructive sleep apnea: an american academy of sleep medicine clinical practice guideline.Journal of clinical sleep medicine, 13(3):479–504, 2017
2017
-
[11]
Metrics of sleep apnea severity: beyond the apnea-hypopnea index.Sleep, 44(7):zsab030, 2021
AtulMalhotra,InduAyappa,NajibAyas,NancyCollop,DouglasKirsch,NigelMcardle,ReenaMehra,AllanIPack,NareshPunjabi,DavidP White, et al. Metrics of sleep apnea severity: beyond the apnea-hypopnea index.Sleep, 44(7):zsab030, 2021
2021
-
[12]
Machinelearningmethodsforadultosahsriskprediction.BMCHealth Services Research, 24(1):706, 2024
ShanshanGe,KainanWu,ShuhuiLi,RuilingLi,andCaizhengYang. Machinelearningmethodsforadultosahsriskprediction.BMCHealth Services Research, 24(1):706, 2024. et al.:Preprint submitted to ElsevierPage 18 of 19
2024
-
[13]
June-Young Park, Hye-Rim Shin, Min Hye Kim, Yunsoo Kim, Wi-Sun Ryu, Eun Young Kim, Hyeyeon Chang, Woo-Jin Lee, Jee Hyun Kim, and Tae-Joon Kim. A novel machine learning model for screening the risk of obstructive sleep apnea using craniofacial photography with questionnaires.Journal of Clinical Sleep Medicine, 21(5):843–854, 2025
2025
-
[14]
Machine learning and geometric morphometrics to predict obstructive sleep apnea from 3d craniofacial scans.Sleep Medicine, 95:76–83, 2022
Fabrice Monna, Raoua Ben Messaoud, Nicolas Navarro, Sébastien Baillieul, Lionel Sanchez, Corinne Loiodice, Renaud Tamisier, Marie Joyeux-Faure, and Jean-Louis Pépin. Machine learning and geometric morphometrics to predict obstructive sleep apnea from 3d craniofacial scans.Sleep Medicine, 95:76–83, 2022
2022
-
[15]
Screening obstructivesleepapneapatientsviadeeplearningofknowledgedistillationinthelateralcephalogram.ScientificReports,13(1):17788,2023
Min-Jung Kim, Jiheon Jeong, Jung-Wook Lee, In-Hwan Kim, Jae-Woo Park, Jae-Yon Roh, Namkug Kim, and Su-Jung Kim. Screening obstructivesleepapneapatientsviadeeplearningofknowledgedistillationinthelateralcephalogram.ScientificReports,13(1):17788,2023
2023
-
[16]
Automatic video analysis for obstructive sleep apnea diagnosis.Sleep, 39(8):1507–1515, 2016
Jorge Abad, Aida Muñoz-Ferrer, Miguel Ángel Cervantes, Cristina Esquinas, Alicia Marin, Carlos Martínez, Josep Morera, and Juan Ruiz. Automatic video analysis for obstructive sleep apnea diagnosis.Sleep, 39(8):1507–1515, 2016
2016
-
[17]
Anosahsevaluationmethodbasedonmulti-featuresacousticanalysisofsnoringsounds.Sleep Medicine, 84:317–323, 2021
YanmeiJiang,JianxinPeng,andLijuanSong. Anosahsevaluationmethodbasedonmulti-featuresacousticanalysisofsnoringsounds.Sleep Medicine, 84:317–323, 2021
2021
-
[18]
Detection of snore from osahs patients based on deep learning
Fanlin Shen, Siyi Cheng, Zhu Li, Keqiang Yue, Wenjun Li, and Lili Dai. Detection of snore from osahs patients based on deep learning. Journal of Healthcare Engineering, 2020(1):8864863, 2020
2020
-
[19]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[20]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[21]
Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250– 49267, 2023
WenliangDai,JunnanLi,DongxuLi,AnthonyTiong,JunqiZhao,WeishengWang,BoyangLi,PascaleNFung,andStevenHoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250– 49267, 2023
2023
-
[22]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[23]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, YuanzhiZhu,MingkunYang,ZhaohaiLi,JianqiangWan,PengfeiWang,WeiDing,ZherenFu,YihengXu,JiaboYe,XiZhang,TianbaoXie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
2025
-
[24]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
KaranSinghal,ShekoofehAzizi,TaoTu,SSaraMahdavi,JasonWei,HyungWonChung,NathanScales,AjayTanwani,HeatherCole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
2023
-
[26]
Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
1930
-
[27]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Large language models must be taught to know what they don’t know.Advances in Neural Information Processing Systems, 37:85932–85972, 2024
SanyamKapoor,NateGruver,ManleyRoberts,KatherineCollins,ArkaPal,UmangBhatt,AdrianWeller,SamuelDooley,MicahGoldblum, and Andrew G Wilson. Large language models must be taught to know what they don’t know.Advances in Neural Information Processing Systems, 37:85932–85972, 2024
2024
-
[29]
Capabilities of GPT-4 on Medical Challenge Problems
HarshaNori,NicholasKing,ScottMayerMcKinney,DeanCarignan,andEricHorvitz. Capabilitiesofgpt-4onmedicalchallengeproblems. arXiv preprint arXiv:2303.13375, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3876–3887, 2022
2022
-
[31]
Making the most of text semantics to improve biomedical vision–language processing
Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-Valle, et al. Making the most of text semantics to improve biomedical vision–language processing. In European conference on computer vision, pages 1–21. Springer, 2022
2022
-
[32]
Identifying facial phenotypes of genetic disorders using deep learning.Nature medicine, 25(1):60–64, 2019
Yaron Gurovich, Yair Hanani, Omri Bar, Guy Nadav, Nicole Fleischer, Dekel Gelbman, Lina Basel-Salmon, Peter M Krawitz, Susanne B Kamphausen, Martin Zenker, et al. Identifying facial phenotypes of genetic disorders using deep learning.Nature medicine, 25(1):60–64, 2019
2019
-
[33]
Gestaltmatcher facilitates rare disease matching using facial phenotype descriptors.Nature genetics, 54(3):349–357, 2022
Tzung-Chien Hsieh, Aviram Bar-Haim, Shahida Moosa, Nadja Ehmke, Karen W Gripp, Jean Tori Pantel, Magdalena Danyel, Martin Atta Mensah, Denise Horn, Stanislav Rosnev, et al. Gestaltmatcher facilitates rare disease matching using facial phenotype descriptors.Nature genetics, 54(3):349–357, 2022
2022
-
[34]
Validation of 3 computer-aidedfacialphenotypingtools(deepgestalt,gestaltmatcher,andd-score):comparativediagnosticaccuracystudy.Journalofmedical Internet research, 26:e42904, 2024
Alisa Maria Vittoria Reiter, Jean Tori Pantel, Magdalena Danyel, Denise Horn, Claus-Eric Ott, and Martin Atta Mensah. Validation of 3 computer-aidedfacialphenotypingtools(deepgestalt,gestaltmatcher,andd-score):comparativediagnosticaccuracystudy.Journalofmedical Internet research, 26:e42904, 2024
2024
-
[35]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[36]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. et al.:Preprint submitted to ElsevierPage 19 of 19
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.