EEG-FM-Audit: A Systematic Evaluation and Analysis Pipeline for EEG Foundation Models
Pith reviewed 2026-06-29 19:45 UTC · model grok-4.3
The pith
Properly tuned supervised baselines match or outperform EEG foundation models while using far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
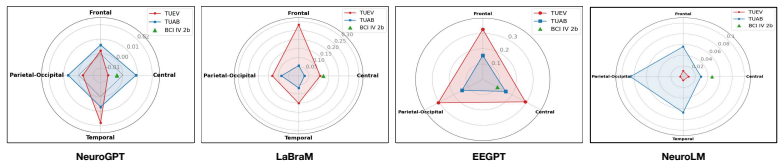
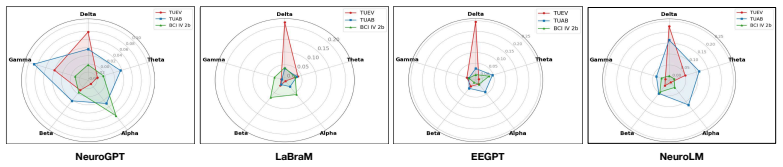
When supervised baselines receive equivalent hyperparameter optimization via an ASHA protocol, they match or exceed the accuracy of current EEG foundation models across tested tasks while requiring orders of magnitude fewer parameters; the value of complex pretraining paradigms further varies with dataset size and architecture, and a neurophysiological probing step shows that foundation models selectively rely on temporal, spatial, and spectral EEG features.
What carries the argument
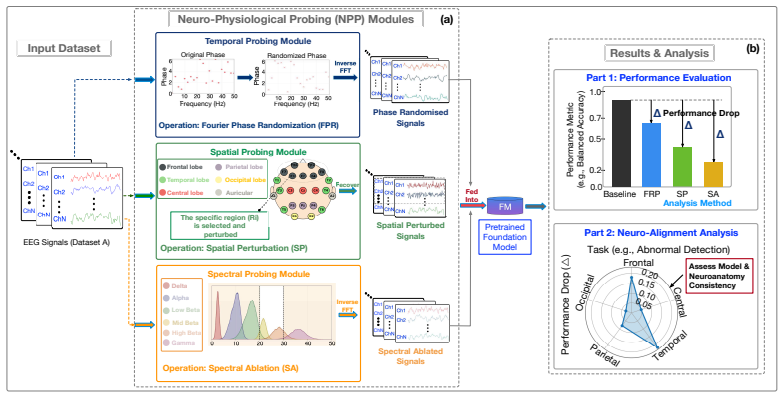
EEG-FM-Audit pipeline: an ASHA-driven benchmarking protocol for fair baseline tuning, paradigm-level ablation studies, and a neurophysiological probing (NPP) framework that checks use of valid temporal, spatial, and spectral EEG properties.
If this is right
- Many EEG decoding applications can achieve current state-of-the-art results with compact supervised models rather than large pretrained networks.
- The benefit of foundation-model pretraining and self-supervision is conditional on dataset scale and backbone architecture.
- Neurophysiological probing supplies an interpretable check that can be applied during model development to confirm physiological grounding.
Where Pith is reading between the lines
- If the pattern holds, research effort may shift from scaling foundation models to systematic tuning and architecture search for lighter supervised networks.
- The conditional effectiveness of learning paradigms suggests that future EEG foundation models should be evaluated first on small-to-medium datasets before claiming broad superiority.
- NPP-style probes could be extended to quantify which specific frequency bands or electrode montages drive predictions in any given model.
Load-bearing premise
The neurophysiological probing framework correctly identifies whether models are using genuine EEG signal properties instead of dataset artifacts or shortcuts.
What would settle it
Re-running the ASHA-tuned comparisons on a new large EEG dataset where foundation models still outperform every properly optimized supervised baseline by a clear margin.
Figures



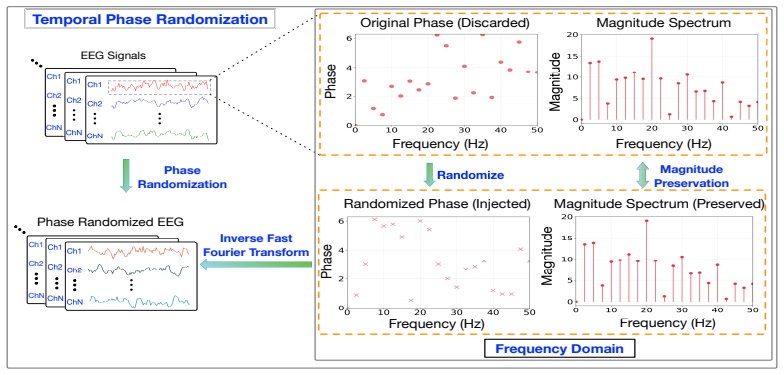






read the original abstract
Large EEG Foundation Models (FMs) have shown great potential for decoding EEG signals across diverse cognitive tasks. However, existing EEG-FM studies exhibit three critical limitations: opaque supervised baseline tuning, unverified contributions of complex learning paradigms, and a lack of transparency in model decision-making. To address these, we propose EEG-FM-Audit, a comprehensive evaluation and analysis pipeline designed to systematize the assessment of EEG-FMs. EEG-FM-Audit consists of three primary components: (1) an ASHA-driven benchmarking protocol that ensures fair comparisons by transparently optimizing supervised baselines; (2) paradigm-level ablation studies to evaluate the effectiveness of learning paradigms in FMs; and (3) a neurophysiological probing (NPP) framework, which explores whether FMs leverage valid temporal, spatial, and spectral EEG properties. We apply EEG-FM-Audit to four state-of-the-art EEG-FMs and five representative supervised models across three public datasets. Our results reveal that properly tuned supervised baselines can match or outperform advanced FMs, despite requiring significantly fewer parameters. Furthermore, we find that the effectiveness of learning paradigms of FMs is highly dependent on dataset scale and architecture. Finally, NPP analysis demonstrates how FMs rely on specific physiological features, establishing a framework for more interpretable neural decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EEG-FM-Audit, a three-component pipeline for evaluating EEG foundation models (FMs): (1) an ASHA-driven benchmarking protocol for transparent optimization of supervised baselines, (2) paradigm-level ablation studies, and (3) a neurophysiological probing (NPP) framework to check whether FMs use valid temporal/spatial/spectral EEG properties. When applied to four state-of-the-art FMs and five supervised models across three public datasets, the central empirical claim is that properly tuned supervised baselines can match or outperform the FMs despite using far fewer parameters; secondary claims are that learning-paradigm effectiveness depends on dataset scale/architecture and that NPP reveals FMs' reliance on specific physiological features.
Significance. If the results are robust, the work would be significant for the EEG decoding community by providing a reproducible audit framework that questions the necessity of large FMs and emphasizes fair baseline tuning. The explicit use of ASHA for optimization transparency and the NPP interpretability component are positive contributions that could improve evaluation standards.
major comments (3)
- [Benchmarking Protocol] Benchmarking protocol (component 1): the manuscript provides no quantitative details on the hyperparameter search space cardinality, number of ASHA trials, early-stopping thresholds, or any post-hoc validation that increasing the compute budget would not improve supervised baseline performance. This directly undermines the load-bearing claim that the baselines are 'properly tuned' and can therefore be said to match or exceed FMs.
- [Experimental Results] Results across the three datasets: no information is given on train/validation/test splits, number of random seeds, or any statistical tests (e.g., paired significance tests or confidence intervals) for the performance comparisons. Without these, the assertion that baselines 'match or outperform' FMs cannot be evaluated for reliability.
- [Neurophysiological Probing Framework] NPP framework (component 3): the claim that NPP 'explores whether FMs leverage valid' EEG properties rests on an unverified assumption that the probing tasks isolate physiologically meaningful features rather than dataset artifacts; no control experiments or alignment with established EEG literature (e.g., known ERP or spectral signatures) are described to support this.
minor comments (2)
- [Abstract] The abstract refers to 'three public datasets' without naming them; adding the dataset identifiers (e.g., BCI Competition IV, etc.) would improve immediate clarity.
- [Abstract] Acronyms FM and NPP are introduced in the abstract without parenthetical expansion on first use.
Simulated Author's Rebuttal
Thank you for the thorough review and valuable feedback on our manuscript. We appreciate the opportunity to clarify and strengthen our work. Below, we provide point-by-point responses to the major comments. We will incorporate the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [Benchmarking Protocol] Benchmarking protocol (component 1): the manuscript provides no quantitative details on the hyperparameter search space cardinality, number of ASHA trials, early-stopping thresholds, or any post-hoc validation that increasing the compute budget would not improve supervised baseline performance. This directly undermines the load-bearing claim that the baselines are 'properly tuned' and can therefore be said to match or exceed FMs.
Authors: We agree that providing these quantitative details is necessary to fully support the claim of proper tuning. In the revised manuscript, we will expand the methods section to include the cardinality of the hyperparameter search space, the number of ASHA trials performed, the early-stopping criteria, and a discussion or analysis showing that additional compute budget is unlikely to alter the relative performance conclusions based on convergence observations during our experiments. revision: yes
-
Referee: [Experimental Results] Results across the three datasets: no information is given on train/validation/test splits, number of random seeds, or any statistical tests (e.g., paired significance tests or confidence intervals) for the performance comparisons. Without these, the assertion that baselines 'match or outperform' FMs cannot be evaluated for reliability.
Authors: We acknowledge this omission and will revise the experimental setup and results sections to explicitly detail the train/validation/test splits used for each dataset, the number of random seeds employed, and include statistical analyses such as paired t-tests with p-values and confidence intervals to demonstrate the reliability of the performance comparisons. revision: yes
-
Referee: [Neurophysiological Probing Framework] NPP framework (component 3): the claim that NPP 'explores whether FMs leverage valid' EEG properties rests on an unverified assumption that the probing tasks isolate physiologically meaningful features rather than dataset artifacts; no control experiments or alignment with established EEG literature (e.g., known ERP or spectral signatures) are described to support this.
Authors: The NPP framework is intended to probe reliance on temporal, spatial, and spectral properties known to be relevant in EEG. To address the concern, the revised version will include control experiments, such as probing on shuffled or artifact-contaminated data, and will align the probing tasks with established EEG literature by referencing specific ERP components and spectral bands documented in prior studies. This will strengthen the validation that the probes capture physiologically meaningful features. revision: yes
Circularity Check
No circularity: empirical evaluation pipeline with no derivation chain
full rationale
The paper proposes an empirical benchmarking and analysis pipeline (ASHA tuning, ablations, NPP framework) and reports results from applying it to existing models on public datasets. No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-citation chains are present in the described work. The central claim rests on comparative performance numbers rather than any reduction of a result to its own inputs by construction. This matches the default expectation for non-circular empirical studies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Classifying single trial EEG: Towards brain computer interfacing
Benjamin Blankertz, Gabriel Curio, and Klaus-Robert Mü ller. Classifying single trial EEG: Towards brain computer interfacing. In Advances in Neural Information Processing Systems , volume 14, pages 157–164. MIT Press, 2001
2001
-
[2]
Lawhern, Amelia J
V ernon J. Lawhern, Amelia J. Solon, Nicholas R. Waytowic h, Stephen M. Gordon, Chou P . Hung, and Brent J. Lance. Eegnet: A compact convolutional ne ural network for eeg-based brain–computer interfaces. Journal of Neural Engineering , 15(5):056013, 2018
2018
-
[3]
A temporal-spectral-based squeeze-and-excitation feature fusion network for motor i magery eeg decoding
Y ang Li, Lianghui Guo, Y u Liu, Jingyu Liu, and Fangang Men g. A temporal-spectral-based squeeze-and-excitation feature fusion network for motor i magery eeg decoding. IEEE Trans- actions on Neural Systems and Rehabilitation Engineering , 29:1534–1545, 2021
2021
-
[4]
An in-depth survey on deep learning-based motor imagery electroenceph alogram (EEG) classification
Xianheng Wang, V eronica Liesaputra, Zhaobin Liu, Yi Wan g, and Zhiyi Huang. An in-depth survey on deep learning-based motor imagery electroenceph alogram (EEG) classification. Ar- tificial Intelligence in Medicine , 147:102738, 2024
2024
-
[5]
Wenhui Cui, Woojae Jeong, Philipp Thölke, Takfarinas Me dani, Karim Jerbi, Anand A. Joshi, and Richard M. Leahy. Neuro-gpt: Towards a foundation model for eeg. arXiv preprint arXiv:2311.03764, 2024
-
[6]
Large br ain model for learning generic representations with tremendous eeg data in bci
Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu. Large br ain model for learning generic representations with tremendous eeg data in bci. In International Conference on Learning Representations (ICLR), 2024
2024
-
[7]
Eegpt: Pre- trained transformer for universal and reliable representa tion of eeg signals
Guangyu Wang, Wenchao Liu, Y uhong He, Cong Xu, Lin Ma, and Haifeng Li. Eegpt: Pre- trained transformer for universal and reliable representa tion of eeg signals. In Advances in Neural Information Processing Systems (NeurIPS) , 2024. 10
2024
-
[8]
Neurolm: A universal multi- task foundation model for bridging the gap between language and eeg signals
Wei-Bang Jiang, Y ansen Wang, Bao-Liang Lu, and Dongsheng Li. Neurolm: A universal multi- task foundation model for bridging the gap between language and eeg signals. In International Conference on Learning Representations (ICLR) , 2025
2025
-
[9]
Are large brainwave foundation models capable yet? insights from fine- tuning
Na Lee, Konstantinos Barmpas, Y annis Panagakis, Dimitr ios Adamos, Nikolaos Laskaris, and Stefanos Zafeiriou. Are large brainwave foundation models capable yet? insights from fine- tuning. In Proceedings of the 42nd International Conference on Machin e Learning (ICML) , 2025
2025
-
[10]
Dingkun Liu, Y uheng Chen, Zhu Chen, Zhenyao Cui, Y aozhiWen, Jiayu An, Jingwei Luo, and Dongrui Wu. EEG foundation models: Progresses, benchmarki ng, and open problems. arXiv preprint arXiv:2601.17883, 2026
-
[11]
Eeg-fm-bench: A comprehensive benchmark for the systematic evaluation of eeg foundation models,
Wei Xiong, Jiangtong Li, Jie Li, Kun Zhu, and Changjun Ji ang. EEG-FM-bench: A compre- hensive benchmark for the systematic evaluation of EEG foun dation models. arXiv preprint arXiv:2508.17742, 2026
-
[12]
Eeg foundation models: A critical review of current progress and future directions,
Gayal Kuruppu, Neeraj Wagh, V aclav Kremen, Sandipan Pa ti, Gregory Worrell, and Y ogath- eesan V aratharajah. EEG foundation models: A critical revi ew of current progress and future directions. arXiv preprint arXiv:2507.11783 , 2025
-
[13]
A system for massively parallel hyperparameter tuning
Liam Li, Kevin Jamieson, Afshin Rostamizadeh, Ekateri na Gonina, Jonathan Ben-tzur, Moritz Hardt, Benjamin Recht, and Ameet Talwalkar. A system for massively parallel hyperparameter tuning. In Proceedings of Machine Learning and Systems (MLSys) , volume 2, pages 230–246, 2020
2020
-
[14]
Learning Representations from EEG with Deep Recurrent-Convolutional Neural Networks
Pouya Bashivan, Irina Rish, Mohammed Y easin, and Noel C odella. Learning repre- sentations from EEG with deep recurrent-convolutional neu ral networks. arXiv preprint arXiv:1511.06448, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
REVE: A foundatio n model for EEG: Adapting to any setup with large-scale pretraining on 25,000 subjects
Y assine El Ouahidi, Jonathan Lys, Philipp Thölke, Nico las Farrugia, Bastien Pasdeloup, Vin- cent Gripon, Karim Jerbi, and Giulia Lioi. REVE: A foundatio n model for EEG: Adapting to any setup with large-scale pretraining on 25,000 subjects. In Advances in Neural Information Processing Systems, 2025
2025
-
[16]
EEG-TCNet: An accurate temporal convoluti onal network for embedded motor-imagery brain–machine interfaces
Thorir Mar Ingolfsson, Michael Hersche, Xiaying Wang, Nobuaki Kobayashi, Lukas Cavigelli, and Luca Benini. EEG-TCNet: An accurate temporal convoluti onal network for embedded motor-imagery brain–machine interfaces. In 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC) , pages 2958–2965, 2020
2020
-
[17]
Foundation models for EEG decoding: Current progress and prospective research
Y uxuan Y ao, Hongbo Wang, Li Chen, Yiheng Peng, and Jingjing Luo. Foundation models for EEG decoding: Current progress and prospective research. Journal of Neural Engineering , 22(6):061002, 2025
2025
-
[18]
Foundation models for cross-domain EEG analysis application: A survey
Hongqi Li, Yitong Chen, Y ujuan Wang, Weihang Ni, and Haodong Zhang. Foundation models for cross-domain EEG analysis application: A survey. arXiv preprint arXiv:2508.15716 , 2025
-
[19]
CroCo: Self- supervised pre-training for 3D vision tasks by cross-view c ompletion
Philippe Weinzaepfel, Vincent Leroy, Thomas Lucas, Romain Brégier, Y ohann Cabon, V aibhav Arora, Leonid Antsfeld, Boris Chidlovskii, Gabriela Csurk a, and Jerome Revaud. CroCo: Self- supervised pre-training for 3D vision tasks by cross-view c ompletion. In Advances in Neural Information Processing Systems, volume 35, pages 3529–3541, 2022
2022
-
[20]
Lan- guage models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Am odei, and Ilya Sutskever. Lan- guage models are unsupervised multitask learners. Technic al report, OpenAI, 2019
2019
-
[21]
Large Language Models: A Survey
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam C henaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey. arXiv preprint arXiv:2402.06196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Test- ing for nonlinearity in time series: the method of surrogate data
James Theiler, Stephen Eubank, André Longtin, Bryan Ga ldrikian, and J Doyne Farmer. Test- ing for nonlinearity in time series: the method of surrogate data. Physica D: Nonlinear Phe- nomena, 58(1):77–94, 1992. 11
1992
-
[23]
Csp-net: Common spatial pattern empowered neural networks for eeg-based motor imag ery classification
Xue Jiang, Lubin Meng, Xinru Chen, Yifan Xu, and Dongrui Wu. Csp-net: Common spatial pattern empowered neural networks for eeg-based motor imag ery classification. Knowledge- Based Systems, 305:112668, 2024
2024
-
[24]
Multi- scale convolutional transformer network for motor imagery brain–computer interface
Wei Zhao, Baocan Zhang, Haifeng Zhou, Dezhi Wei, Chenxi Huang, and Quan Lan. Multi- scale convolutional transformer network for motor imagery brain–computer interface. Scien- tific Reports , 15(1):12935, 2025
2025
-
[25]
Ctnet: A convo- lutional transformer network for eeg-based motor imagery c lassification
Wei Zhao, Xiaolu Jiang, Baocan Zhang, Shixiao Xiao, and Sujun Weng. Ctnet: A convo- lutional transformer network for eeg-based motor imagery c lassification. Scientific Reports , 14(1):20237, 2024
2024
-
[26]
Vismer, Patrick A
Marta S. Vismer, Patrick A. Forcelli, Mark D. Skopin, Ka ren Gale, and Mohamad Z. Koubeissi. The piriform, perirhinal, and entorhinal cortex in seizure generation. Frontiers in Neural Cir- cuits, 9, 2015
2015
-
[27]
J. L. Noebels, M. Avoli, M. A. Rogawski, et al., editors. Jasper’s Basic Mechanisms of the Epilepsies. Oxford University Press, New Y ork, 5th edition, 2024
2024
-
[28]
Exploring EEG signal proces sing for effective filtering and classification of epileptic seizures
Aruna Pant and Adesh Kumar. Exploring EEG signal proces sing for effective filtering and classification of epileptic seizures. Discover Electronics, 3(1):20, 2026
2026
-
[29]
Pfurtscheller, C
G. Pfurtscheller, C. Neuper, and W . Mohl. Event-relate d desynchronization (ERD) during visual processing. International Journal of Psychophysiology , 16(2):147–153, 1994
1994
-
[30]
Biot: Biosigna l transformer for cross-data learn- ing in the wild
Chaoqi Y ang, M Westover, and Jimeng Sun. Biot: Biosigna l transformer for cross-data learn- ing in the wild. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems , volume 36, pages 78240–78260. Curran Associates, Inc., 2023
2023
-
[31]
Generating surrogate data for time series with several simul- taneously measured variables
Dean Prichard and James Theiler. Generating surrogate data for time series with several simul- taneously measured variables. Physical Review Letters, 73(7):951–954, 1994
1994
-
[32]
Electric Fields of the Brain: The Neurophysics of EEG
Paul L Nunez and Ramesh Srinivasan. Electric Fields of the Brain: The Neurophysics of EEG . Oxford University Press, New Y ork, NY , 2nd edition, 2006
2006
-
[33]
signal-aware
Robin Tibor Schirrmeister, Jost Tobias Springenberg, Lukas Dominique Josef Fiederer, Martin Glasstetter, Katharina Eggensperger, Michael Tangermann , Frank Hutter, Wolfram Burgard, and Tonio Ball. Deep learning with convolutional neural net works for EEG decoding and visualization. Human Brain Mapping , 38(11):5391–5420, 2017. Appendix A Pseudocode for th...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.