NightSight: Passive Computation for Navigation in Dark Using Events
Pith reviewed 2026-06-29 21:11 UTC · model grok-4.3
The pith
Monocular event camera with coded aperture and IR projector recovers accurate depth in darkness after training solely on synthetic planar data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that the depth-dependent blur signatures from an IR dot pattern imaged through a coded aperture can be decoded by a CNN trained only on synthetic planar wall data to yield dense depth maps that generalize zero-shot to real-world scenes, providing 7.0 cm L1 error up to 2.5 m range for navigation in total darkness.
What carries the argument
The depth-dependent blur signatures produced by the coded aperture lens and infrared dot projector, which are decoded into depth by the convolutional neural network.
If this is right
- The system runs in real time at 20 Hz on a NVIDIA Jetson Orin Nano, suitable for small robots.
- High accuracy of 7.0 cm L1 error (2.80% at 2.5 m) is achieved in real scenes despite minimal training.
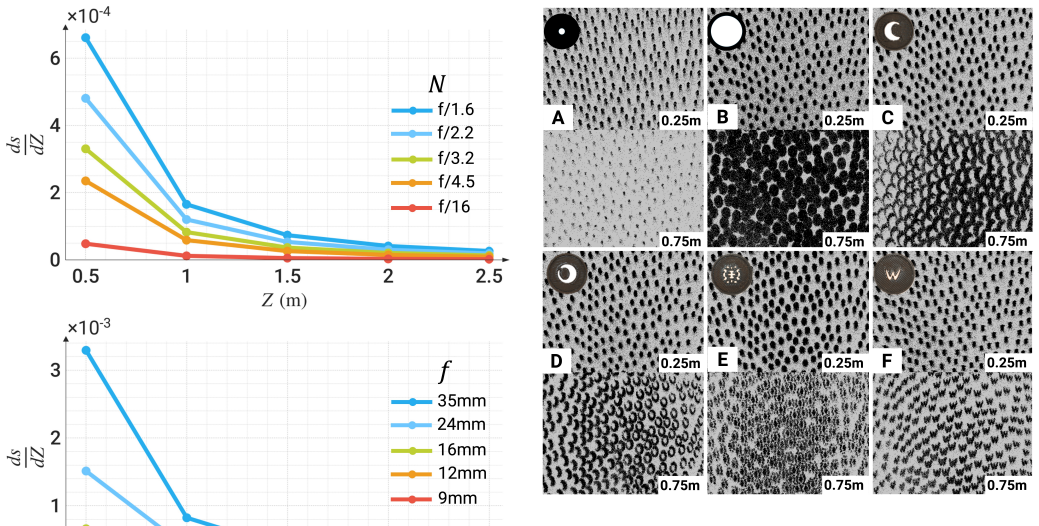
- Different coded aperture designs can be analyzed for their impact on depth estimation performance.
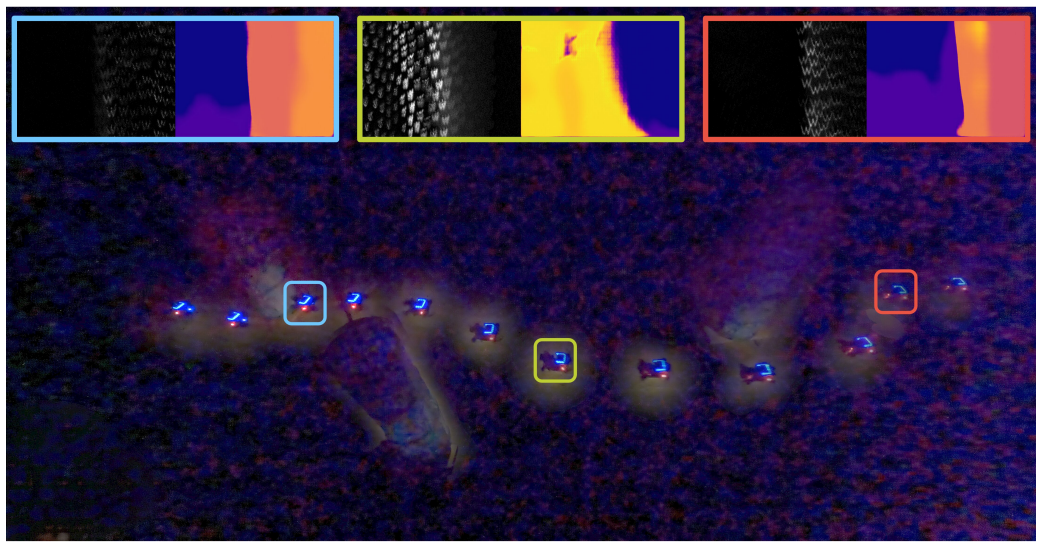
- The approach enables perception in complete darkness without substantial payload or power demands.
Where Pith is reading between the lines
- The zero-shot performance indicates that the encoded blur may capture intrinsic depth cues independent of scene content.
- This method could lower barriers for deploying autonomous systems in low-light hazardous areas by minimizing hardware requirements.
- Extensions to dynamic environments might leverage the event camera's high temporal resolution for moving objects.
Load-bearing premise
The assumption that a neural network trained exclusively on synthetic data from a planar wall will decode the blur signatures accurately in complex real-world scenes without significant domain shift or failure modes.
What would settle it
Measuring the depth estimation error on real-world scenes with multiple objects at varying distances and textures, checking if the L1 error stays at or below 7 cm up to 2.5 m.
Figures



read the original abstract
Small aerial robots are particularly well-suited for search and rescue in confined and hazardous environments due to their agility, low cost, and ability to traverse through cluttered spaces that are inaccessible to larger platforms. However, enabling autonomous navigation in complete darkness remains a significant challenge, because small aerial robots cannot easily accommodate perception systems that demand substantial payload, power, or computation. In this work, we present a lightweight perception approach that combines a monocular event camera, a coded aperture lens, and an infrared dot projector to enable navigation in such conditions. The projected pattern, when imaged through the coded aperture, produces depth dependent blur signatures that implicitly encode scene geometry. We train a convolutional neural network to decode these signatures into dense depth maps using only synthetic data generated from a simple planar wall setup. Despite this minimal training regime, the model generalizes zero-shot to complex real-world scenes. Our system operates in real time at 20 Hz on a NVIDIA Jetson Orin Nano, demonstrating suitability for resource-constrained platforms. We further analyze the impact of different coded aperture designs on depth estimation performance. Our approach gives high accuracy (l1 error 7.0cm) upto 2.5m range (2.80% error). These results highlight the potential of combining structured illumination, coded optics, and event-based sensing for enabling robust perception and navigation in complete darkness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NightSight, a lightweight perception system for small aerial robots navigating in complete darkness. It combines a monocular event camera with a coded aperture lens and an infrared dot projector. The projected IR pattern creates depth-dependent blur signatures through the coded aperture, which a CNN, trained exclusively on synthetic data from a simple planar wall, decodes into dense depth maps. The system is claimed to generalize zero-shot to complex real-world scenes, achieving an L1 error of 7.0 cm up to 2.5 m range (2.80% error), operating in real time at 20 Hz on an NVIDIA Jetson Orin Nano. The paper also examines the impact of different coded aperture designs on performance.
Significance. If the zero-shot generalization holds, this work could enable robust, low-power, passive depth sensing for resource-constrained platforms in dark, cluttered environments, which is significant for search and rescue applications with small aerial robots. The integration of event-based sensing, coded optics, and structured illumination is a promising direction, and the real-time embedded performance is a practical strength. The analysis of aperture designs provides additional insight into the approach.
major comments (1)
- [Abstract] Abstract: The central performance claim of 7.0 cm L1 error up to 2.5 m with zero-shot generalization from synthetic planar wall training to complex real scenes is load-bearing but rests on the unverified assumption that depth-dependent point-spread functions remain invariant to non-planar surfaces, varying albedo, partial occlusions, and event noise. The abstract provides no details on mechanisms to ensure this invariance or on the validation experiments in complex environments, making it impossible to assess if the reported accuracy is reliable.
minor comments (2)
- [Abstract] The phrase 'upto 2.5m range' should be 'up to 2.5 m range' for standard English usage.
- [Abstract] The notation 'l1 error' should be capitalized as 'L1 error' for consistency with standard mathematical notation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential significance. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim of 7.0 cm L1 error up to 2.5 m with zero-shot generalization from synthetic planar wall training to complex real scenes is load-bearing but rests on the unverified assumption that depth-dependent point-spread functions remain invariant to non-planar surfaces, varying albedo, partial occlusions, and event noise. The abstract provides no details on mechanisms to ensure this invariance or on the validation experiments in complex environments, making it impossible to assess if the reported accuracy is reliable.
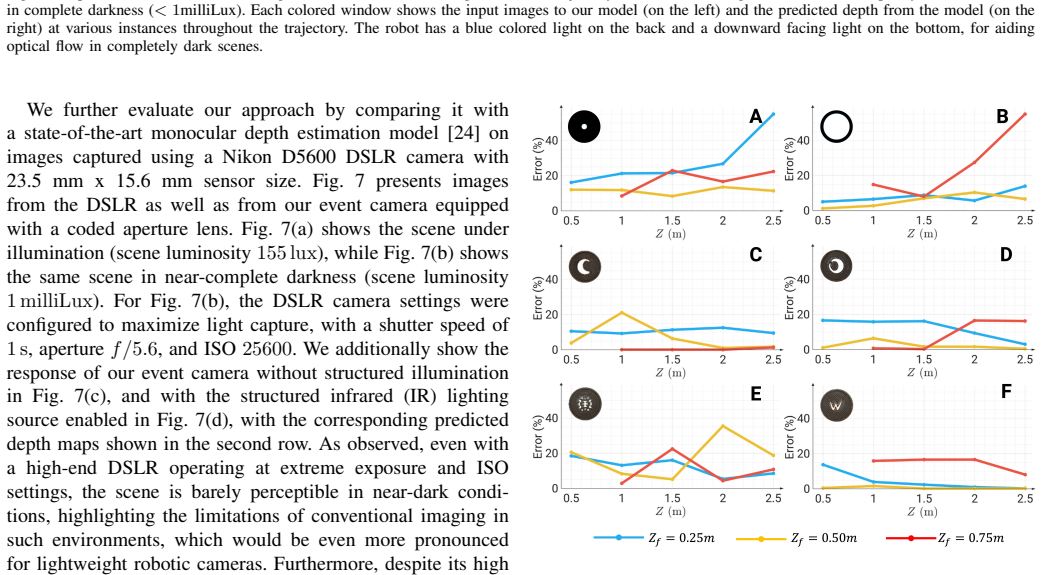
Authors: We agree the abstract is concise and omits key details on validation and invariance. The manuscript body (Section 4) reports quantitative L1 results and qualitative examples on real complex scenes containing non-planar geometry, varying albedos, partial occlusions, and actual event noise, confirming zero-shot transfer from the planar synthetic training data. The underlying mechanism is that the IR dot pattern through the coded aperture produces primarily geometric, depth-dependent blur that the network decodes; the event camera's change detection and active illumination reduce sensitivity to albedo. We will revise the abstract to briefly reference the real-world validation on complex scenes. revision: yes
Circularity Check
No circularity; empirical ML claim with no derivation chain
full rationale
The paper presents a standard supervised CNN training pipeline on synthetic planar-wall data followed by empirical testing on real scenes. No mathematical derivations, equations, fitted parameters renamed as predictions, self-citations for uniqueness theorems, or ansatzes are described. The central performance numbers (7 cm L1 error) are reported as measured outcomes of this training-and-test procedure, which is externally falsifiable and does not reduce to its inputs by construction. This matches the default expectation of no circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- CNN weights and training details
axioms (1)
- domain assumption Blur signatures from the coded aperture and IR projector encode sufficient depth information for scene geometry recovery
Reference graph
Works this paper leans on
-
[1]
T. D. Barfootet al.,Into Darkness: Visual Navigation Based on a Lidar- Intensity-Image Pipeline. Cham: Springer International Publishing, 2016, pp. 487–504
2016
-
[2]
Redformer: Radar enlightens the darkness of camera per- ception with transformers,
C. Cuiet al., “Redformer: Radar enlightens the darkness of camera per- ception with transformers,”IEEE Transactions on Intelligent Vehicles, vol. 9, no. 1, pp. 1358–1368, 2024
2024
-
[3]
Present and Future of SLAM in Extreme Environments: The DARPA SubT Challenge,
K. Ebadiet al., “Present and Future of SLAM in Extreme Environments: The DARPA SubT Challenge,”IEEE Transactions on Robotics, vol. 40, pp. 936–959, 2024
2024
-
[4]
Thermal-inertial odometry for autonomous flight throughout the night,
J. Delaune, R. Hewitt, L. Lytle, C. Sorice, R. Thakker, and L. Matthies, “Thermal-inertial odometry for autonomous flight throughout the night,” in2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 1122–1128
2019
-
[5]
Prgflow: Benchmarking swap-aware unified deep visual inertial odometry,
N. J. Sanket, C. D. Singh, C. Ferm ¨uller, and Y . Aloimonos, “Prgflow: Benchmarking swap-aware unified deep visual inertial odometry,” 2020. [Online]. Available: https://arxiv.org/abs/2006.06753
-
[6]
Asternav: Autonomous aerial robot navigation in darkness using passive computation,
D. Singh, S. Khobragade, and N. J. Sanket, “Asternav: Autonomous aerial robot navigation in darkness using passive computation,”IEEE Robotics and Automation Letters, vol. 11, no. 3, pp. 3907–3914, 2026
2026
-
[7]
Land and D.-E
M. Land and D.-E. Nilsson,Animal Eyes. United Kingdom: Oxford University Press, 2002
2002
-
[8]
Ajna: Generalized deep uncertainty for minimal perception on parsimonious robots,
N. J. Sanket, C. D. Singh, C. Ferm ¨uller, and Y . Aloimonos, “Ajna: Generalized deep uncertainty for minimal perception on parsimonious robots,”Science Robotics, vol. 8, no. 81, p. eadd5139, 2023. [Online]. Available: https://www.science.org/doi/abs/10.1126/scirobotics.add5139
-
[9]
Chameleons use accommodation cues to judge distance,
L. Harkness, “Chameleons use accommodation cues to judge distance,” Nature, vol. 267, no. 5609, pp. 346–349, 1977. [Online]. Available: https://doi.org/10.1038/267346a0
-
[10]
Visual neuroscience: How do moths see to fly at night?
P. Ala-Laurila, “Visual neuroscience: How do moths see to fly at night?”Current Biology, vol. 26, no. 6, pp. R231–R233, 2016. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0960982216000701
2016
-
[11]
Blurring for clarity: Passive com- putation for defocus-driven parsimonious navigation using a monocular event camera,
H. Pawar, D. Singh, and N. J. Sanket, “Blurring for clarity: Passive com- putation for defocus-driven parsimonious navigation using a monocular event camera,” inProceedings of the Winter Conference on Applications of Computer Vision (WACV) Workshops, February 2025, pp. 912–916
2025
-
[12]
A 128×128 120 db 15µs latency asynchronous temporal contrast vision sensor,
P. Lichtsteiner, C. Posch, and T. Delbruck, “A 128×128 120 db 15µs latency asynchronous temporal contrast vision sensor,”IEEE Journal of Solid-State Circuits, vol. 43, no. 2, pp. 566–576, 2008
2008
-
[13]
A spiking neu- ral network model of depth from defocus for event-based neuromorphic vision,
G. Haessig, X. Berthelon, S.-H. Ieng, and R. Benosman, “A spiking neu- ral network model of depth from defocus for event-based neuromorphic vision,”Scientific Reports, vol. 9, no. 1, p. 3744, Mar. 2019
2019
-
[14]
Autofocus for event cameras,
S. Lin, Y . Zhang, L. Yu, B. Zhou, X. Luo, and J. Pan, “Autofocus for event cameras,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022, pp. 16 323–16 332
2022
-
[15]
Learning depth from focus with event focal stack,
C. Jiang, M. Lin, C. Zhang, Z. Wang, and L. Yu, “Learning depth from focus with event focal stack,”IEEE Sensors Journal, vol. PP, pp. 1–1, 01 2024
2024
-
[16]
W. Xue and L. Shang, “Event-based depth from focus,” inPro- ceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 7874–7881, doi: 10.1109/IROS60139.2025.11246028
-
[17]
A new sense for depth of field,
A. P. Pentland, “A new sense for depth of field,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 9, no. 4, pp. 523–531, Apr. 1987
1987
-
[18]
Depth from defocus: A spatial domain approach,
M. Subbarao and G. Surya, “Depth from defocus: A spatial domain approach,”International Journal of Computer Vision, vol. 13, no. 3, pp. 271–294, Dec. 1994
1994
-
[19]
Image and depth from a conventional camera with a coded aperture,
A. Levin, R. Fergus, F. Durand, and W. T. Freeman, “Image and depth from a conventional camera with a coded aperture,”ACM Trans. Graph., vol. 26, no. 3, p. 70–es, Jul. 2007. [Online]. Available: https://doi.org/10.1145/1276377.1276464
-
[20]
Coded aperture pairs for depth from defocus and defocus deblurring,
C. Zhou, S. Lin, and S. K. Nayar, “Coded aperture pairs for depth from defocus and defocus deblurring,”International Journal of Computer Vision, vol. 93, no. 1, pp. 53–72, May 2011
2011
-
[21]
Low-latency automotive vision with event cameras,
D. Gehrig and D. Scaramuzza, “Low-latency automotive vision with event cameras,”Nature, vol. 629, no. 8014, pp. 1034–1040, May 2024
2024
-
[22]
Evdodgenet: Deep dynamic obstacle dodging with event cameras,
N. J. Sanket, C. M. Parameshwara, C. D. Singh, A. V . Kuruttukulam, C. Ferm ¨uller, D. Scaramuzza, and Y . Aloimonos, “Evdodgenet: Deep dynamic obstacle dodging with event cameras,” in2020 IEEE Inter- national Conference on Robotics and Automation (ICRA), 2020, pp. 10 651–10 657
2020
-
[23]
M. Kim, S. Chang, M. Kim, J.-E. Yeo, M. S. Kim, G. J. Lee, D.-H. Kim, and Y . M. Song, “Cuttlefish eye–inspired artificial vision for high-quality imaging under uneven illumination conditions,”Science Robotics, vol. 8, no. 75, p. eade4698, 2023. [Online]. Available: https://www.science.org/doi/10.1126/scirobotics.ade4698
-
[24]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
A. Bochkovskii, A. Delaunoy, H. Germain, M. Santos, Y . Zhou, S. R. Richter, and V . Koltun, “Depth pro: Sharp monocular metric depth in less than a second,” 2024. [Online]. Available: https://arxiv.org/abs/2410.02073 Accepted to the Challenges and Opportunities of Neuromorphic Field Robotics and Automation IEEE ICRA Workshop - 2026
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.