Multi-Modal Learning meets Genetic Programming: Analyzing Alignment in Latent Space Optimization
Pith reviewed 2026-05-10 17:24 UTC · model grok-4.3
The pith
SNIP's cross-modal alignment does not improve during optimization even as fitness rises, and stays too coarse for effective symbolic search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
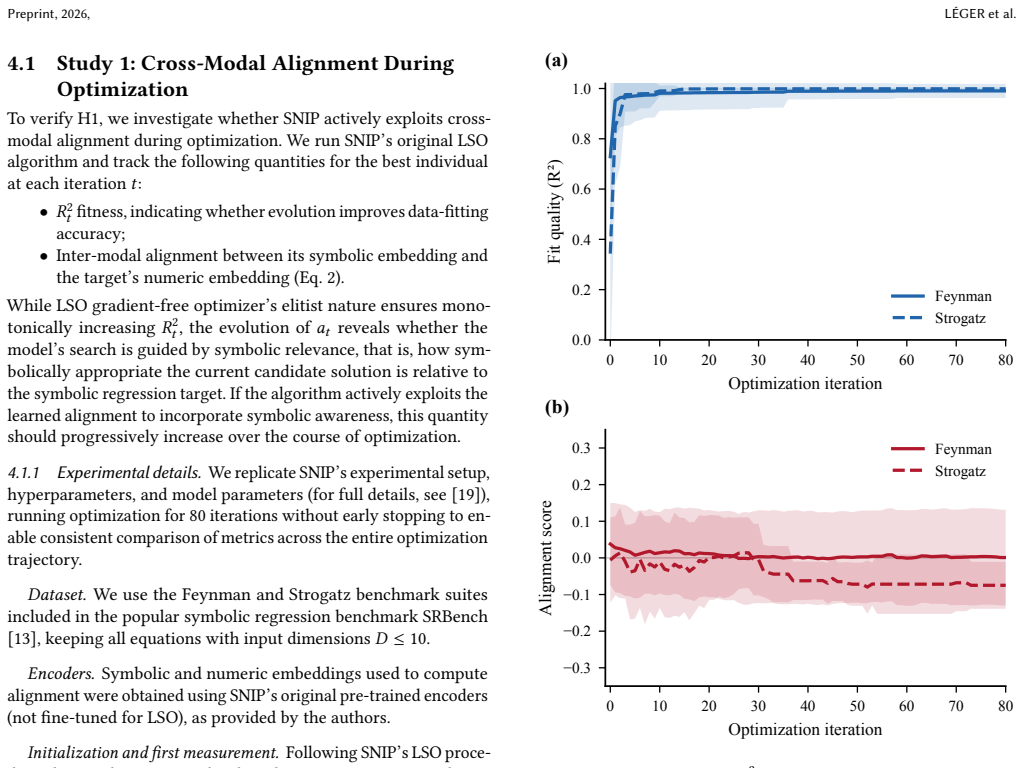
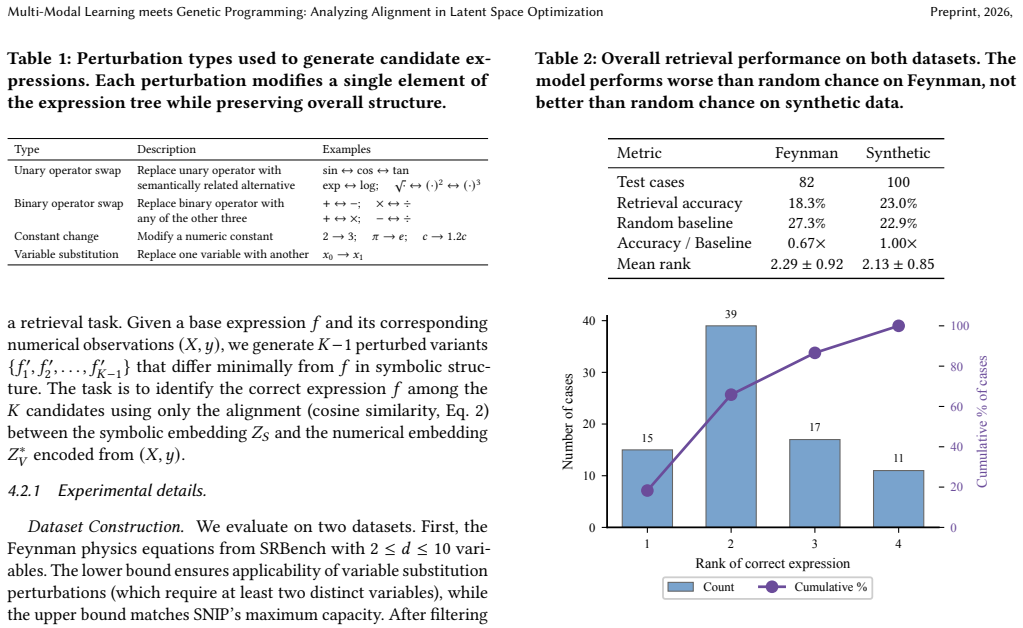
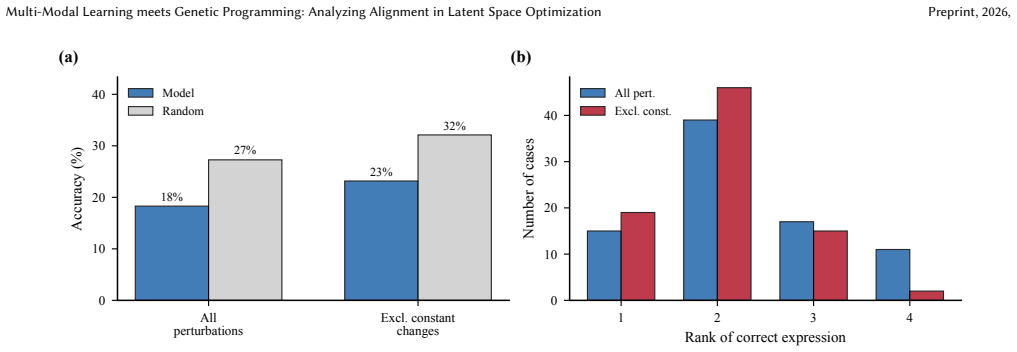
The paper claims that cross-modal alignment does not improve during optimization, even as fitness increases, and that the alignment learned by SNIP is too coarse to efficiently conduct principled search in the symbolic space. While multi-modal latent space optimization holds potential for symbolic regression, effective alignment-guided optimization remains unrealized in practice, and fine-grained alignment is identified as a critical direction for future work.
What carries the argument
SNIP, a contrastive pre-training model that aligns symbolic and numeric encoders in a shared latent space to learn the phenotype-genotype mapping for latent space optimization.
If this is right
- Multi-modal latent space optimization for symbolic regression requires advances in fine-grained alignment to achieve effective bi-modal search.
- Coarse alignment limits the ability to use numeric-space improvements to guide precise symbolic changes.
- The potential of combining multi-modal learning with genetic programming for symbolic tasks depends on realizing better modality alignment.
- Future methods must address the gap between current contrastive pre-training and the precision needed for principled symbolic optimization.
Where Pith is reading between the lines
- Similar coarse-alignment problems could appear in other contrastive models applied to structured combinatorial domains such as programs or circuits.
- Alternative training objectives or auxiliary losses that enforce finer semantic matching might overcome the current limitations.
- Hybrid approaches that retain some direct symbolic operations alongside latent optimization could mitigate reliance on perfect alignment.
Load-bearing premise
The chosen metrics for cross-modal alignment and the optimization process accurately capture whether the alignment enables effective bi-modal search without confounding factors from the experimental setup or SNIP hyperparameters.
What would settle it
A measurement showing that cross-modal alignment scores rise in step with fitness improvements during optimization, or that latent-space distances permit finer symbolic manipulations than currently observed, would challenge the central claim.
Figures

read the original abstract
Symbolic regression (SR) aims to discover mathematical expressions from data, a task traditionally tackled using Genetic Programming (GP) through combinatorial search over symbolic structures. Latent Space Optimization (LSO) methods use neural encoders to map symbolic expressions into continuous spaces, transforming the combinatorial search into continuous optimization. SNIP (Meidani et al., 2024), a contrastive pre-training model inspired by CLIP, advances LSO by introducing a multi-modal approach: aligning symbolic and numeric encoders in a shared latent space to learn the phenotype-genotype mapping, enabling optimization in the numeric space to implicitly guide symbolic search. However, this relies on fine-grained cross-modal alignment, whereas literature on similar models like CLIP reveals that such an alignment is typically coarse-grained. In this paper, we investigate whether SNIP delivers on its promise of effective bi-modal optimization for SR. Our experiments show that: (1) cross-modal alignment does not improve during optimization, even as fitness increases, and (2) the alignment learned by SNIP is too coarse to efficiently conduct principled search in the symbolic space. These findings reveal that while multi-modal LSO holds significant potential for SR, effective alignment-guided optimization remains unrealized in practice, highlighting fine-grained alignment as a critical direction for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether the multi-modal latent space optimization approach SNIP, which aligns symbolic and numeric encoders via contrastive learning, enables effective bi-modal search for symbolic regression. The central claims, supported by experiments, are that cross-modal alignment fails to improve during optimization despite rising fitness values, and that the learned alignment remains too coarse-grained to facilitate efficient, principled exploration in the symbolic expression space.
Significance. Should the empirical findings prove robust, this paper offers a significant contribution to the intersection of genetic programming and multi-modal machine learning by delivering a critical analysis that tempers enthusiasm for direct application of CLIP-like models to LSO in symbolic regression. It provides concrete evidence of limitations in current alignment quality and identifies fine-grained alignment as an open challenge, which could steer future work toward more sophisticated contrastive objectives or hybrid search strategies. The analysis is strengthened by its focus on falsifiable predictions about alignment dynamics during optimization.
major comments (1)
- [Section 4] Section 4 (Experiments): While the full manuscript provides details on the alignment metric, optimization loop, SNIP hyperparameters, and benchmark suite (addressing the abstract's brevity), the lack of reported variance across multiple random seeds or statistical tests for the no-improvement claim in alignment vs. fitness makes it difficult to rule out sampling artifacts as a confounder for finding (1).
minor comments (3)
- [Abstract] Abstract: The two main experimental findings could be enumerated more explicitly to improve scannability for readers.
- [Section 2] Section 2: A brief expansion on how the chosen latent-space similarity metric relates to symbolic equivalence measures (e.g., tree edit distance) would clarify why it is expected to capture 'coarseness' relevant to search efficiency.
- [Figures] Figure captions: Including the exact SNIP training hyperparameters and dataset sizes used for each plot would aid reproducibility without requiring cross-reference to the text.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recommending minor revision. We appreciate the recognition of our paper's contribution in highlighting limitations of current multi-modal alignment approaches for latent space optimization in symbolic regression. We address the major comment below.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Experiments): While the full manuscript provides details on the alignment metric, optimization loop, SNIP hyperparameters, and benchmark suite (addressing the abstract's brevity), the lack of reported variance across multiple random seeds or statistical tests for the no-improvement claim in alignment vs. fitness makes it difficult to rule out sampling artifacts as a confounder for finding (1).
Authors: We agree that reporting variance across multiple random seeds and including statistical tests would strengthen the evidence for our claim that cross-modal alignment does not improve with increasing fitness. In the revised manuscript, we will rerun the key experiments with at least five independent random seeds and report means with standard deviations for the alignment metrics plotted against fitness. We will also add Pearson or Spearman correlation coefficients (with p-values) between alignment quality and fitness to quantify the lack of positive relationship and rule out sampling artifacts as a potential confounder. revision: yes
Circularity Check
No significant circularity; empirical claims are self-contained
full rationale
The paper reports new experimental observations on cross-modal alignment in SNIP for symbolic regression, showing that alignment does not improve with fitness and remains too coarse. These findings rest on direct measurements from the optimization loop, latent-space metrics, and benchmark runs rather than any derivation, fitted parameter renamed as prediction, or self-referential equation. The citation to prior SNIP work (Meidani et al., 2024) merely describes the baseline method under test; the central claims are independent empirical results that can be inspected against the stated metrics, hyperparameters, and data. No load-bearing step reduces to a self-definition or self-citation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The contrastive pre-training in SNIP learns a meaningful phenotype-genotype mapping.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.