Multisensory Continual Learning: Adapting Pretrained Visuomotor Policies to Force
Pith reviewed 2026-07-01 01:00 UTC · model grok-4.3
The pith
Pretrained vision-only robot policies can adapt to force-torque sensing with limited new data while preserving performance on original tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
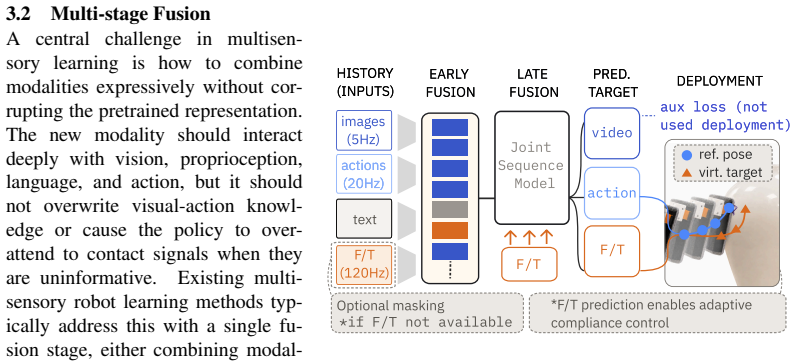
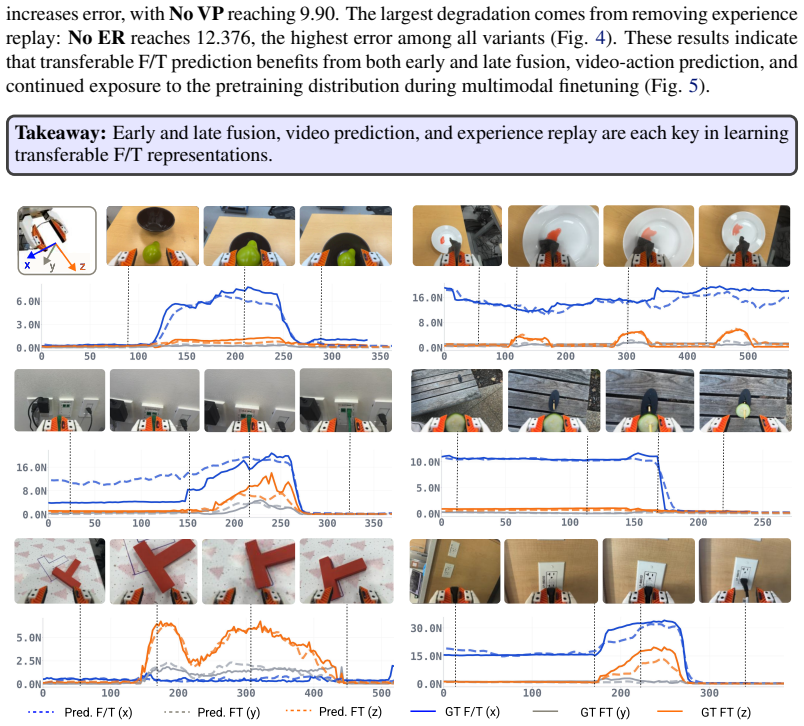
MuSe adapts pretrained vision-only policies to force-torque sensing through multi-stage fusion, multisensory future prediction, and experience replay over pretraining data. This enables strong performance on contact-rich finetuning tasks while preserving, and in some cases improving, performance on the original pretraining tasks.
What carries the argument
MuSe, which combines multi-stage fusion of new and old sensor streams, multisensory future prediction, and replay of pretraining experiences to add force-torque input without overwriting vision skills.
If this is right
- MuSe achieves strong results on contact-rich finetuning tasks.
- Performance on the original pretraining tasks is preserved.
- Performance on some original tasks improves after the update.
- A modest multisensory dataset improves general robot capabilities beyond the finetuning distribution.
Where Pith is reading between the lines
- The same replay-plus-fusion pattern could be tried when adding audio or tactile sensing instead of force.
- Policies updated this way might handle a wider range of real-world contact conditions without needing separate training runs for each sensor set.
- The approach might let a single policy base serve multiple hardware configurations by swapping in new sensor streams as needed.
- Testing the method on longer task sequences could reveal whether replay continues to protect old skills as the number of added modalities grows.
Load-bearing premise
Experience replay over the original vision data together with multi-stage fusion is enough to stop catastrophic forgetting when force-torque sensing is added using only a modest amount of new data.
What would settle it
A controlled test in which the same policy is updated with force data but without experience replay, then evaluated on the original vision-only tasks to check for a clear drop in success rate.
Figures





read the original abstract
Robot manipulation often relies on sensory feedback beyond vision, particularly in contact-rich settings where force, tactile, or audio signals reveal interaction states that are not directly observable from images. However, these modalities are often hardware- and task-specific, and large-scale multisensory robot datasets remain scarce. As a result, it is impractical to pretrain policies with every sensor they may encounter. We study multisensory continual learning: adapting a pretrained robot policy to new tasks with newly introduced modalities while preserving performance under the original sensor suite. We propose MuSe, which incorporates limited multisensory data into pretrained vision-only policies through multi-stage fusion, multisensory future prediction, and experience replay over pretraining data. We instantiate MuSe by augmenting a pretrained vision-only policy with force-torque sensing and evaluate it on real-world manipulation tasks. Our experiments show that MuSe performs strongly on contact-rich finetuning tasks while preserving, and in some cases improving, performance on the original pretraining tasks. These results suggest that a modest multisensory dataset can improve general robot capabilities beyond the finetuning distribution. Project website: https://jadenvc.github.io/multisensory-continual-learning/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MuSe for multisensory continual learning: it adapts a pretrained vision-only visuomotor policy to new force-torque sensing via multi-stage fusion, multisensory future prediction, and experience replay over the original pretraining data. Real-world experiments on contact-rich manipulation tasks are reported to show strong finetuning performance while preserving (and sometimes improving) performance on the original vision-only tasks, implying that modest multisensory data can enhance general robot capabilities beyond the finetuning distribution.
Significance. If the central empirical claims hold after the replay mechanism is fully specified and experimental details are supplied, the result would be significant for practical robot learning: it offers a route to incorporate task-specific sensors without full retraining or catastrophic forgetting, using only limited new data. The real-world evaluation on contact-rich tasks and the emphasis on preserving original-task performance are concrete strengths that would support broader claims about improved general capabilities.
major comments (3)
- [Method (experience replay component)] The description of experience replay (method section) does not specify the rule used to supply force-torque vectors to replayed vision-only pretraining transitions. Whether these vectors are zero-padded, drawn from a learned prior, or masked is unstated; any choice alters the input distribution to the multi-stage fusion layers on the original tasks and directly affects whether replay can be claimed to prevent catastrophic forgetting.
- [Experiments / abstract] The abstract states that experiments support the claims on real-world tasks, yet supplies no information on dataset sizes, number of evaluation trials per task, baselines, or statistical significance. Without these quantities the evidence that MuSe preserves or improves original-task performance cannot be assessed, undermining the load-bearing claim that replay plus fusion suffices for continual learning.
- [Results / abstract] The claim that performance on original pretraining tasks is 'in some cases improving' is presented as evidence that multisensory data can improve general capabilities. No control experiments or ablation isolating the contribution of the new force modality versus replay alone are described, leaving open the possibility that observed gains are artifacts of the fusion architecture rather than a general benefit.
minor comments (2)
- [Method] Notation for the multi-stage fusion and future-prediction losses is introduced without an explicit equation reference or diagram clarifying how the vision and force encoders are combined at each stage.
- [Abstract] The project website is cited but no additional implementation details, code, or dataset links are referenced in the text, which would aid reproducibility of the real-world setup.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Method (experience replay component)] The description of experience replay (method section) does not specify the rule used to supply force-torque vectors to replayed vision-only pretraining transitions. Whether these vectors are zero-padded, drawn from a learned prior, or masked is unstated; any choice alters the input distribution to the multi-stage fusion layers on the original tasks and directly affects whether replay can be claimed to prevent catastrophic forgetting.
Authors: We agree that the experience replay implementation requires explicit specification. The revised manuscript will state that force-torque vectors for replayed vision-only transitions are zero-padded. This maintains the original input distribution to the multi-stage fusion layers on pretraining data and thereby supports the claim that replay prevents catastrophic forgetting. revision: yes
-
Referee: [Experiments / abstract] The abstract states that experiments support the claims on real-world tasks, yet supplies no information on dataset sizes, number of evaluation trials per task, baselines, or statistical significance. Without these quantities the evidence that MuSe preserves or improves original-task performance cannot be assessed, undermining the load-bearing claim that replay plus fusion suffices for continual learning.
Authors: We acknowledge the abstract is too concise on these quantities. We will revise the abstract to report the multisensory dataset size, number of evaluation trials per task, baselines used, and note that statistical significance was assessed. Full details already appear in the experiments section; adding them to the abstract will make the supporting evidence immediately assessable. revision: yes
-
Referee: [Results / abstract] The claim that performance on original pretraining tasks is 'in some cases improving' is presented as evidence that multisensory data can improve general capabilities. No control experiments or ablation isolating the contribution of the new force modality versus replay alone are described, leaving open the possibility that observed gains are artifacts of the fusion architecture rather than a general benefit.
Authors: Existing baselines compare MuSe against vision-only finetuning and replay variants, providing partial isolation. However, we agree that dedicated ablations separating the force modality from replay alone would strengthen the interpretation. We will add such ablations in the revision to directly address whether gains arise from multisensory fusion rather than architecture or replay effects. revision: partial
Circularity Check
No significant circularity; empirical method with independent experimental validation
full rationale
The paper describes an empirical method (MuSe) for multisensory continual learning via multi-stage fusion, future prediction, and experience replay, evaluated on real-world contact-rich tasks. No equations, derivations, or parameter-fitting steps are presented that reduce any claimed result to its own inputs by construction. Central performance claims rest on external benchmarks (pretraining task retention and finetuning success) rather than self-referential definitions or self-citation chains. The approach is self-contained against those benchmarks, yielding a normal non-finding of circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Hou, Z. Liu, C. Chi, E. Cousineau, N. Kuppuswamy, S. Feng, B. Burchfiel, and S. Song. Adaptive compliance policy: Learning approximate compliance for diffusion guided control. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4829–
- [2]
-
[3]
L. Heng, H. Geng, K. Zhang, P. Abbeel, and J. Malik. Vitacformer: Learning cross-modal rep- resentation for visuo-tactile dexterous manipulation.arXiv preprint arXiv:2506.15953, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
Zhang, C
X. Zhang, C. Wang, L. Sun, Z. Wu, X. Zhu, and M. Tomizuka. Efficient sim-to-real transfer of contact-rich manipulation skills with online admittance residual learning. InConference on Robot Learning, pages 1621–1639. PMLR, 2023
2023
- [6]
-
[7]
J. Yin, H. Qi, Y . Wi, S. Kundu, M. Lambeta, W. Yang, C. Wang, T. Wu, J. Malik, and T. Helle- brekers. Osmo: Open-source tactile glove for human-to-robot skill transfer.IEEE Robotics and Automation Letters, 2026
2026
-
[8]
Jones, O
J. Jones, O. Mees, C. Sferrazza, K. Stachowicz, P. Abbeel, and S. Levine. Beyond sight: Finetuning generalist robot policies with heterogeneous sensors via language grounding. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5961–5968. IEEE, 2025
2025
- [9]
- [10]
-
[11]
Thrun and T
S. Thrun and T. M. Mitchell. Lifelong robot learning.Robotics and autonomous systems, 15 (1-2):25–46, 1995
1995
-
[12]
Lesort, V
T. Lesort, V . Lomonaco, A. Stoian, D. Maltoni, D. Filliat, and N. D ´ıaz-Rodr´ıguez. Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges. Information fusion, 58:52–68, 2020. 9
2020
-
[13]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
- [14]
-
[15]
Breaking Lock-In: Preserving Steerability under Low-Data VLA Post-Training
S. Huang, J. Shao, K. Wang, Q. Chen, J. Sun, Y . Guo, M. Schwager, and J. Bohg. Break- ing lock-in: Preserving steerability under low-data VLA post-training.arXiv preprint arXiv:2604.23121, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In Proceedings of The 7th Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[17]
Driess, J
D. Driess, J. T. Springenberg, B. Ichter, L. Yu, A. Li-Bell, K. Pertsch, A. Z. Ren, H. Walke, Q. Vuong, L. X. Shi, and S. Levine. Knowledge insulating vision-language-action models. In Advances in Neural Information Processing Systems, 2025
2025
-
[18]
A. J. Hancock, X. Wu, L. Zha, O. Russakovsky, and A. Majumdar. Actions as language: Fine-tuning VLMs into VLAs without catastrophic forgetting. InInternational Conference on Learning Representations, 2026
2026
- [19]
- [20]
-
[21]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
T. Li, Y . Tian, H. Li, M. Deng, and K. He. Autoregressive image generation without vector quantization.Advances in Neural Information Processing Systems, 37:56424–56445, 2024. 10 6 Appendix Project website: MultisensoryLearning 6.1 Performance with Fixed Compliance MuSe uses force–torque (F/T) information in two ways during deployment: the policy conditi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.