MemoryDocDataSet: A Benchmark for Joint Conversational Memory and Long Document Reasoning
Pith reviewed 2026-06-28 06:54 UTC · model grok-4.3
The pith
A new benchmark shows retrieval systems cannot jointly handle conversational memory and long document navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
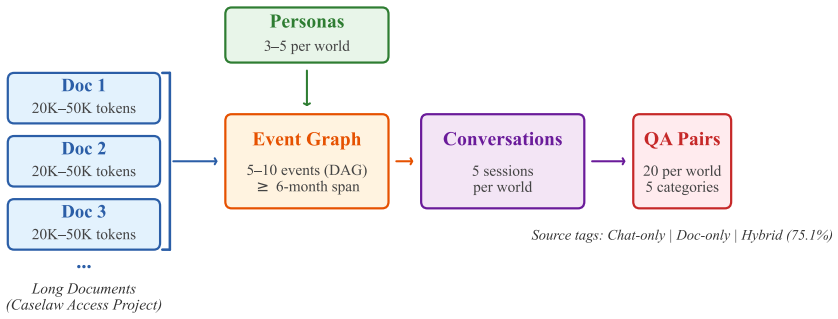
MemoryDocDataSet comprises 50 micro-worlds, each with 3-5 personas, a months-long temporal event graph, 3-5 long documents of 20,000-50,000 tokens from the Caselaw Access Project, multi-session conversations, and 20 QA pairs. Seventy-five point one percent of questions carry the Hybrid tag, meaning they require first traversing conversation history to identify the relevant document and only then reading inside that document for the answer. Six baseline configurations were run; the strongest reaches 0.358 overall F1 while document-only retrieval falls to 0.267 on Hybrid questions despite scoring 0.453 on document-only questions.
What carries the argument
The Hybrid source tag, which marks questions that demand sequential use of conversation history to select the correct long document before performing extraction inside it.
If this is right
- Systems must combine conversational memory mechanisms with document retrieval rather than running them as independent modules.
- Success on pure document retrieval tasks does not transfer to tasks where memory first selects the document.
- New model designs that unify memory navigation with long-context reading are needed to close the observed gap.
- The released generation pipeline supplies a repeatable way to create additional test instances for measuring progress on the joint task.
Where Pith is reading between the lines
- The dataset could serve as a testbed for evaluating whether simply increasing context length closes the hybrid gap or whether explicit memory structures remain necessary.
- Because the long documents come from legal case law, the benchmark may highlight limitations in current legal AI tools that handle ongoing client discussions.
- The construction method might be reused to generate similar joint-reasoning tests in other domains that pair extended records with repeated user exchanges.
Load-bearing premise
The synthetic micro-worlds, event graphs, and hybrid questions generated by the pipeline reflect the joint memory-plus-document challenge that occurs in real user interactions without introducing artificial ease or difficulty.
What would settle it
Measuring the same baselines on a collection of genuine multi-session conversations attached to long documents and checking whether hybrid-style questions still produce a comparable performance collapse relative to document-only questions.
Figures

read the original abstract
AI systems increasingly need to combine two demanding capabilities: navigating multi-session conversation history and performing deep reading comprehension within long documents. Yet no existing benchmark evaluates both simultaneously. We introduce MemoryDocDataSet, a synthetic benchmark of 50 micro-worlds and 1,000 QA pairs in which each instance comprises 3-5 personas, a temporal event graph spanning months of activity, 3-5 real long documents (20,000-50,000 tokens each sourced from the Caselaw Access Project), multi-session conversations grounded on those documents, and 20 question-answer pairs across five reasoning categories. The defining feature is the Hybrid source tag: questions requiring a system to first navigate conversation history to identify which document is relevant, then extract the answer from within that document. Hybrid questions account for 75.1% of the dataset. Dataset quality is characterised through a prompt-sensitivity self-consistency analysis using LLM-as-judge, yielding a median Cohen's $\kappa = 0.634$ across all 50 micro-worlds. We evaluate six baseline configurations spanning truncated context, long-context LLMs, retrieval-augmented generation (RAG), and memory systems. The best baseline (RAG-Both) achieves 0.358 overall F1 and 0.342 on Hybrid. Document-only retrieval (RAG-Doc) collapses to 0.267 on Hybrid despite achieving 0.453 on Doc-only questions, demonstrating a clear joint-retrieval gap that motivates architectures unifying conversational memory with long-document navigation. We release the dataset, generation pipeline, and all baseline implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemoryDocDataSet, a synthetic benchmark of 50 micro-worlds and 1,000 QA pairs designed to evaluate joint conversational memory and long-document reasoning. Each micro-world includes 3-5 personas, a temporal event graph, 3-5 long documents (20k-50k tokens from the Caselaw Access Project), multi-session conversations, and 20 QA pairs across five categories, with 75.1% labeled as Hybrid questions that require first navigating conversation history to select the relevant document before extracting the answer. Baseline evaluations across truncated context, long-context LLMs, RAG variants, and memory systems show RAG-Both achieving the highest scores (0.358 overall F1, 0.342 on Hybrid), while RAG-Doc drops from 0.453 F1 on Doc-only questions to 0.267 on Hybrid. Dataset quality is assessed via LLM-as-judge prompt-sensitivity self-consistency (median Cohen's κ=0.634), and all artifacts including the generation pipeline and baseline code are released.
Significance. If the synthetic generation process produces Hybrid questions that genuinely require joint navigation of conversation history and document content without leakage or artifacts, the benchmark would address a clear gap by providing the first dedicated resource for this combined capability. The reported performance gap supplies concrete motivation for unified architectures, and the open release of the full pipeline and implementations is a strength that enables direct extensions and reproducibility.
major comments (3)
- [Dataset construction and quality assessment] The description of Hybrid question generation (via temporal event graphs, persona-grounded conversations, and LLM-based creation) provides no audit or oracle test showing that an agent ignoring conversation history cannot solve a non-trivial fraction of these items using only the question text or event graph. This is load-bearing for the central claim, as the reported RAG-Doc collapse from 0.453 F1 (Doc-only) to 0.267 F1 (Hybrid) is only interpretable as evidence of a joint-retrieval gap if conversation history is verifiably required to identify the document.
- [Dataset construction and quality assessment] The quality characterization reports only median Cohen's κ=0.634 for LLM judge self-consistency across prompt variations; this does not address whether the generated Hybrid questions contain spurious cues or fail to demand the claimed joint reasoning, leaving the task validity unverified.
- [Experiments and baselines] Baseline implementation details are insufficient to determine whether the Hybrid performance gap arises from the intended joint challenge or from specific choices in retrieval indexing, chunking of 20k-50k token documents, or memory integration in RAG-Both vs. RAG-Doc.
minor comments (2)
- [Abstract] The abstract states there are 'five reasoning categories' but does not enumerate them; this should be listed explicitly for clarity.
- [Abstract] The source of the long documents is given as the Caselaw Access Project but lacks a citation or link in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of the Hybrid question category and more detailed baseline descriptions. We agree these points are important for establishing the benchmark's validity and will incorporate additional analyses and details in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: The description of Hybrid question generation (via temporal event graphs, persona-grounded conversations, and LLM-based creation) provides no audit or oracle test showing that an agent ignoring conversation history cannot solve a non-trivial fraction of these items using only the question text or event graph. This is load-bearing for the central claim, as the reported RAG-Doc collapse from 0.453 F1 (Doc-only) to 0.267 F1 (Hybrid) is only interpretable as evidence of a joint-retrieval gap if conversation history is verifiably required to identify the document.
Authors: We acknowledge that an explicit oracle test would provide stronger evidence that Hybrid questions require conversation history. The generation process grounds conversations in the temporal event graph such that each multi-session exchange references a specific document, and questions are constructed to necessitate identifying the relevant document from history before extraction. However, we agree this does not substitute for a direct test. In the revision we will add an oracle analysis evaluating a no-history baseline (question text plus event graph only) on the Hybrid subset to quantify any leakage, with results reported in a new validation subsection. revision: yes
-
Referee: The quality characterization reports only median Cohen's κ=0.634 for LLM judge self-consistency across prompt variations; this does not address whether the generated Hybrid questions contain spurious cues or fail to demand the claimed joint reasoning, leaving the task validity unverified.
Authors: The reported median Cohen's κ quantifies labeling consistency of the LLM judge across prompt variations for source-type assignment. We agree this metric alone does not rule out spurious cues or confirm joint-reasoning demands. To address this, the revision will include additional validation: (1) manual review of a random sample of 100 Hybrid questions with inter-annotator agreement, and (2) the no-history oracle results noted above to directly test for cues independent of conversation history. revision: yes
-
Referee: Baseline implementation details are insufficient to determine whether the Hybrid performance gap arises from the intended joint challenge or from specific choices in retrieval indexing, chunking of 20k-50k token documents, or memory integration in RAG-Both vs. RAG-Doc.
Authors: We agree that insufficient implementation details limit interpretability of the performance gap. The revision will expand the Experiments section with precise specifications: retrieval indexing method and embedding model, chunk size/overlap for the 20k-50k token documents, exact prompting and memory state management for RAG-Both versus RAG-Doc, and hyperparameter settings. We will also ensure the released code repository contains the exact configurations used for all reported baselines. revision: yes
Circularity Check
Empirical benchmark paper with no derivation chain or fitted predictions
full rationale
This is a dataset-construction and baseline-evaluation paper. The central claims consist of measured F1 scores on released artifacts (RAG-Both at 0.358 overall, RAG-Doc drop on Hybrid questions) and a prompt-sensitivity consistency check (median Cohen's κ). No equations, parameter fits, predictions, uniqueness theorems, or self-citation chains appear in the derivation of results. All reported numbers are direct empirical measurements on the synthetic micro-worlds and QA pairs; the generation pipeline is described but not invoked as a mathematical derivation that reduces to its own outputs. The paper is therefore self-contained against external benchmarks with score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval- Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval- Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020
2020
-
[2]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13851–13870, 2024
2024
-
[3]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InProceedings of the Thirteenth International Conference on Learning Representations, 2025
2025
-
[4]
L-Eval: Instituting Standardized Evaluation for Long Context Language Models
Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-Eval: Instituting Standardized Evaluation for Long Context Language Models. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 14388–14411, 2024
2024
-
[5]
ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding
Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 7977–7989, 2023
2023
-
[6]
Beyond Goldfish Memory: Long-Term Open-Domain Conversa- tion
Jing Xu, Arthur Szlam, and Jason Weston. Beyond Goldfish Memory: Long-Term Open-Domain Conversa- tion. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 5180–5197, 2022. 13
2022
-
[7]
MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19336–19352, 2025
2025
-
[8]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, 2018
2018
-
[9]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv preprint, 2025
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv preprint, 2025
2025
-
[10]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory.arXiv preprint, 2025
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A Temporal Knowledge Graph Architecture for Agent Memory.arXiv preprint, 2025
2025
-
[11]
Caselaw Access Project
Harvard Law School. Caselaw Access Project. 2018
2018
-
[12]
Datasheets for Datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for Datasets.Communications of the ACM, 64(12):86–92, 2021
2021
-
[13]
Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, 2019
2019
-
[14]
Chroma: The AI-Native Open-Source Embedding Database
Chroma. Chroma: The AI-Native Open-Source Embedding Database. 2022
2022
-
[15]
{domain}
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. Appendix A Pipeline Stage Details Stage 1 — Document Collection.Raw opinions are downloaded from the Caselaw ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.