SPEAR: A System for Post-Quantization Error-Adaptive Recovery Enabling Efficient Low-Bit LLM Serving
Pith reviewed 2026-06-27 23:02 UTC · model grok-4.3
The pith
SPEAR recovers 56-75% of the perplexity gap from 4-bit LLM quantization by applying input-dependent error compensation only at sensitive layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
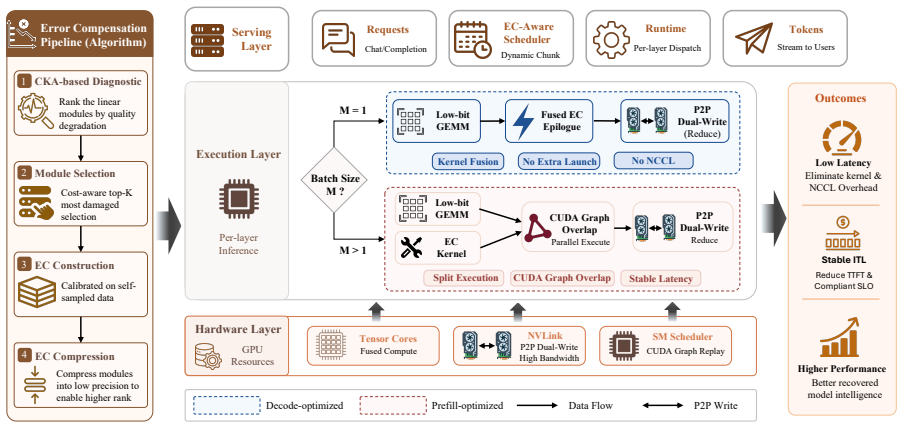
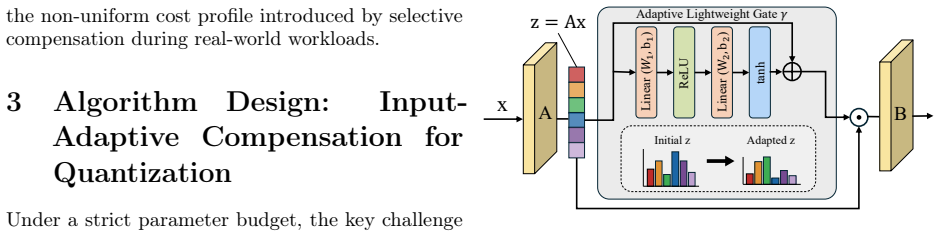
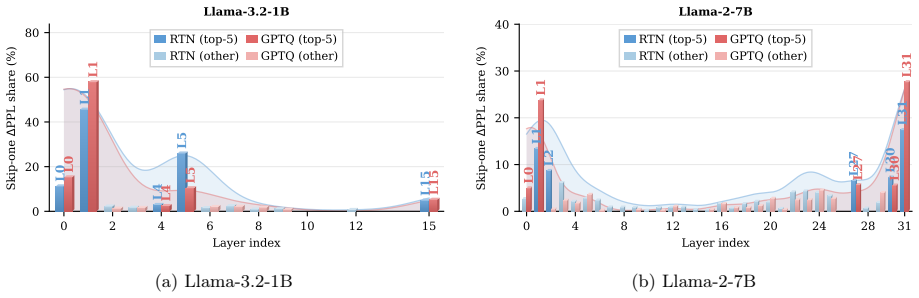
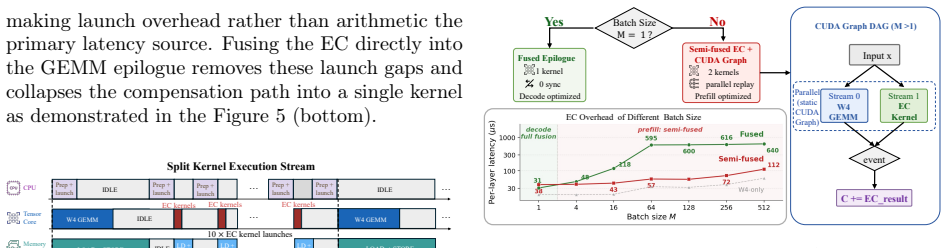
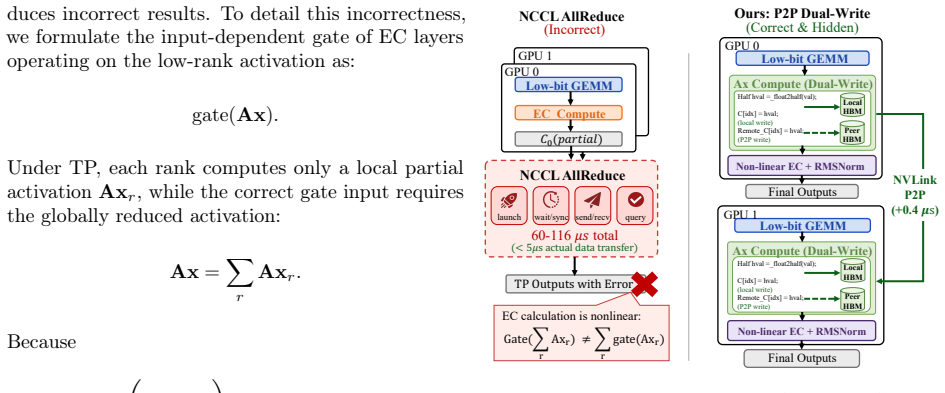
SPEAR introduces lightweight Error Compensators modulated by per-token gates and places them only at the most error-sensitive layers identified through a CKA-guided entropy-aware diagnostic. This focuses a small parameter budget where it is most effective. Efficient deployment of ECs is achieved through adaptive kernel-fusion dispatch that combines an epilogue-integrated peer-reduction kernel with P2P dual-write to fuse the post-EC computation into low-bit GEMMs, plus an SLO-constrained EC-aware scheduler. Across challenging per-channel quantization settings, SPEAR recovers 56-75% of the perplexity gap between W4 and FP16 while adding less than 1% model memory overhead and maintaining latenc
What carries the argument
Lightweight Error Compensators (ECs) modulated by per-token gates, placed via CKA-guided entropy-aware diagnostic and deployed through adaptive kernel-fusion dispatch with epilogue-integrated peer-reduction and P2P dual-write.
If this is right
- 4-bit quantized LLMs can achieve perplexity values substantially closer to FP16 without increasing model memory footprint beyond 1%.
- Serving systems can maintain the low latency of existing 4-bit deployments while reducing the quality penalty on difficult inputs.
- Compensation effort can be concentrated on a small number of layers and activated only when needed, avoiding uniform overhead across all tokens.
- The same placement and fusion strategy supports predictable performance under service-level objectives even when input difficulty varies.
Where Pith is reading between the lines
- The per-token diagnostic might be reusable to decide where to apply other forms of dynamic correction, such as speculative decoding triggers.
- Extending the same adaptive logic to 3-bit or 2-bit quantization could test whether the recovery percentage scales with the initial error magnitude.
- In multi-tenant serving, the scheduler's awareness of EC cost could be used to prioritize batches with lower expected compensation overhead.
Load-bearing premise
That the variation in quantization error across tokens is large enough for per-token gating to yield a net quality gain without introducing synchronization or latency costs that grow with model size.
What would settle it
A benchmark run on standard tensor-parallel hardware showing that the per-token gating and fused kernels increase end-to-end latency by more than a few percent relative to baseline 4-bit serving would falsify the efficiency claim.
Figures



read the original abstract
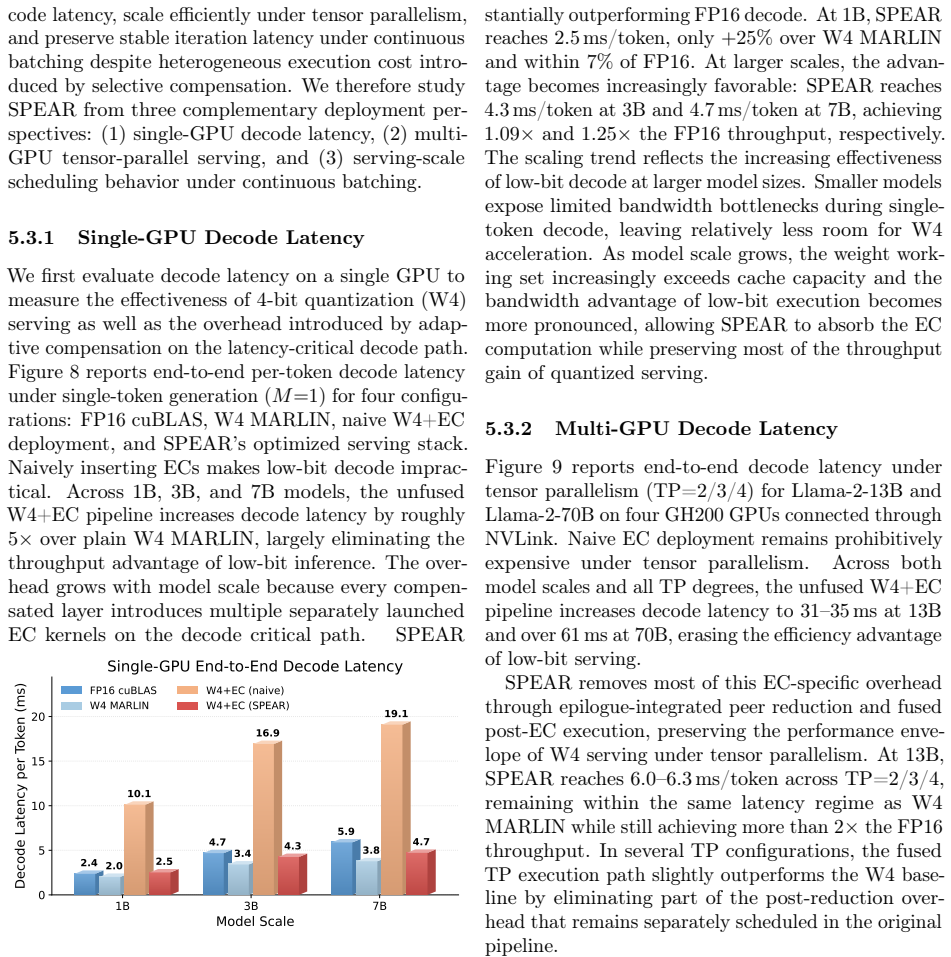
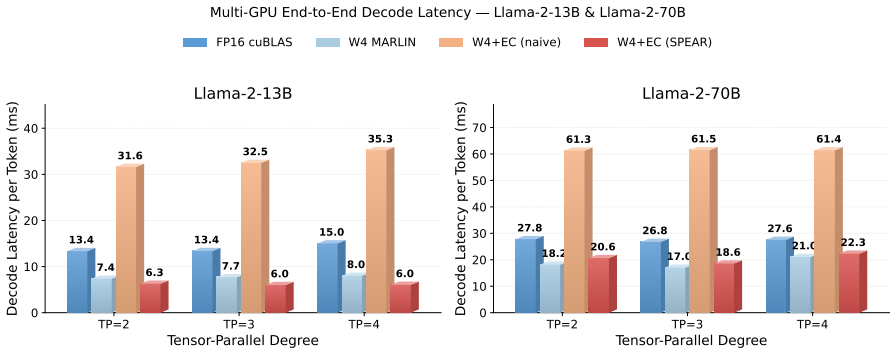
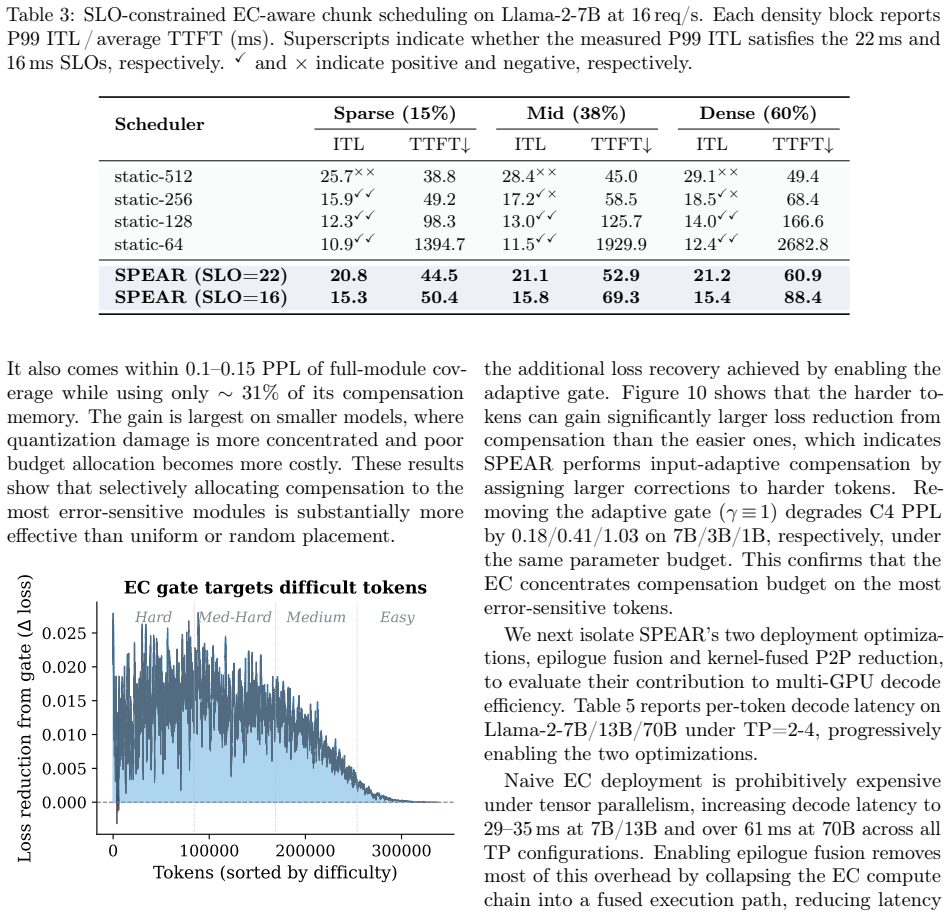
Efficient large language model (LLM) serving is increasingly constrained by deployment cost. Quantization is a key technique for reducing serving cost, yet even state-of-the-art 4-bit quantizers exhibit a noticeable quality gap from FP16, particularly for smaller models where low-bit serving is most beneficial. We identify a fundamental cause of this gap: quantization error is highly input-dependent and varies substantially across tokens, while existing post-quantization compensation methods are static and apply identical corrections to all inputs. As a result, easy tokens are over-corrected while hard tokens remain under-corrected. We present SPEAR, a system for post-quantization error-adaptive recovery that improves low-bit LLM serving. SPEAR introduces lightweight Error Compensators (ECs) modulated by per-token gates and places them only at the most error-sensitive layers identified through a CKA-guided entropy-aware diagnostic. This focuses a small parameter budget where it is most effective. Efficient deployment of ECs presents several systems challenges, including additional computation, tensor-parallel synchronization caused by input-dependent gating, and latency instability across configurations. SPEAR addresses these issues through adaptive kernel-fusion dispatch, combining an epilogue-integrated peer-reduction kernel with P2P dual-write to fuse the post-EC computation into low-bit GEMMs, and an SLO-constrained EC-aware scheduler for predictable serving performance. Across challenging per-channel quantization settings, SPEAR recovers 56-75% of the perplexity gap between W4 and FP16 while adding less than 1% model memory overhead and maintaining latency comparable to a widely used 4-bit serving deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SPEAR, a system for post-quantization error-adaptive recovery in low-bit LLM serving. It identifies input-dependent quantization error as the source of the quality gap in 4-bit models and introduces lightweight Error Compensators (ECs) modulated by per-token gates, placed only at layers selected via a CKA-guided entropy-aware diagnostic. Deployment challenges (added compute, tensor-parallel synchronization from input-dependent gating, and latency instability) are addressed via adaptive kernel-fusion dispatch that combines an epilogue-integrated peer-reduction kernel with P2P dual-write to fuse post-EC computation into low-bit GEMMs, plus an SLO-constrained EC-aware scheduler. The central claim is that, across challenging per-channel quantization settings, SPEAR recovers 56-75% of the perplexity gap to FP16 while adding <1% model memory overhead and maintaining latency comparable to a standard 4-bit serving deployment.
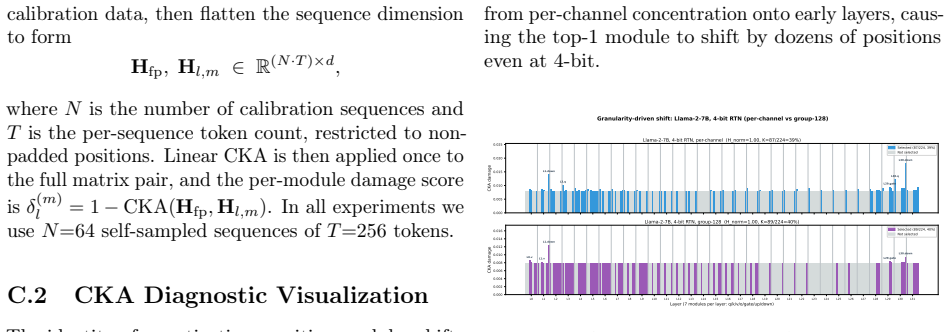
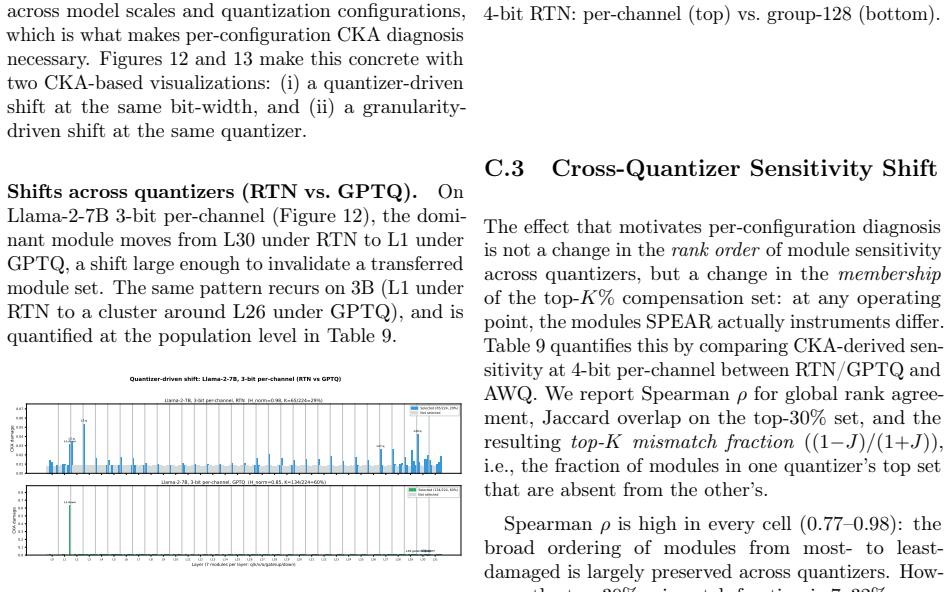
Significance. If the empirical claims hold under broader scrutiny, the work could meaningfully improve the quality-efficiency tradeoff for quantized LLM inference by shifting from static to input-adaptive compensation with negligible overhead. The explicit treatment of tensor-parallel synchronization and scheduler integration for per-token mechanisms is a practical strength; the kernel-fusion approach supplies a concrete, implementable path that other systems papers can build upon.
major comments (2)
- [Abstract] Abstract: the claim that the described mechanisms 'address tensor-parallel synchronization caused by input-dependent gating' and 'latency instability' while 'maintaining latency comparable' is load-bearing for the efficiency half of the central result, yet the kernel-fusion description supplies no quantitative bound on residual synchronization or dispatch cost when gate decisions differ across ranks or at high tensor-parallel degree.
- [Abstract] Abstract / evaluation description: the reported 56-75% recovery figures are presented as direct measurements without error bars, without enumeration of models or datasets, and without an ablation isolating the CKA-guided diagnostic from post-hoc layer selection; this weakens confidence that the gains are robust rather than configuration-specific.
minor comments (1)
- The abstract would be clearer if it named the specific quantization method (e.g., per-channel) and the baseline 4-bit serving system used for the latency comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the abstract for greater precision and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the described mechanisms 'address tensor-parallel synchronization caused by input-dependent gating' and 'latency instability' while 'maintaining latency comparable' is load-bearing for the efficiency half of the central result, yet the kernel-fusion description supplies no quantitative bound on residual synchronization or dispatch cost when gate decisions differ across ranks or at high tensor-parallel degree.
Authors: We agree the abstract would be improved by an explicit quantitative bound. The evaluation section reports latency measurements across TP degrees and gate-variation scenarios; we will revise the abstract to reference these bounds (e.g., residual dispatch overhead remains below the level that affects end-to-end comparability) and clarify the kernel-fusion limits on synchronization cost. revision: yes
-
Referee: [Abstract] Abstract / evaluation description: the reported 56-75% recovery figures are presented as direct measurements without error bars, without enumeration of models or datasets, and without an ablation isolating the CKA-guided diagnostic from post-hoc layer selection; this weakens confidence that the gains are robust rather than configuration-specific.
Authors: The 56-75% range aggregates results over the models and datasets enumerated in Section 4; error bars appear in the corresponding figures, and the CKA ablation versus post-hoc selection is shown in Section 5.2. We will revise the abstract to list the models/datasets and explicitly reference the ablation study. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper presents its central claims as empirical measurements of perplexity recovery (56-75% gap closure) against an FP16 reference under per-channel quantization, with system overheads reported as direct observations. No equations, fitted parameters renamed as predictions, or self-citation chains are invoked to derive these outcomes by construction. The CKA-guided placement, per-token gating, and kernel fusions are described as engineering choices whose effectiveness is validated externally via benchmarks rather than reduced to inputs. This matches the default case of a self-contained empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles , pages=
Aegaeon: Effective GPU pooling for concurrent LLM serving on the market , author=. Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles , pages=
-
[2]
Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 , pages=
Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-flow , author=. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 , pages=
-
[3]
Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages=
Tapas: Thermal-and Power-aware Scheduling for LLM Inference in Cloud Platforms , author=. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages=
-
[4]
Proceedings of the twentieth European conference on computer systems , pages=
Cacheblend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion , author=. Proceedings of the twentieth European conference on computer systems , pages=
-
[5]
Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles , pages=
JENGA: Effective Memory Management for Serving LLM with Heterogeneity , author=. Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles , pages=
-
[6]
Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles , pages=
Diffkv: Differentiated Memory Management for Large Language Models with Parallel KV Compaction , author=. Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles , pages=
-
[7]
Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles , pages=
Ic-cache: Efficient Large Language Model Serving via In-context Caching , author=. Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles , pages=
-
[8]
2025 USENIX Annual Technical Conference (USENIX ATC 25) , pages=
Weaver: Efficient \ Multi-LLM \ Serving with Attention Offloading , author=. 2025 USENIX Annual Technical Conference (USENIX ATC 25) , pages=
2025
-
[9]
19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25) , pages=
Mirage: A \ Multi-Level \ Superoptimizer for Tensor Programs , author=. 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25) , pages=
-
[10]
Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages=
Pim is all you need: A CXL-enabled GPU-free System for Large Language Model Inference , author=. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , pages=
-
[11]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Self-instruct: Aligning Language Models with Self-generated Instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[12]
Proceedings of Machine Learning and Systems , volume=
Qserve: W4a8kv4 Quantization and System Co-design for Efficient LLM Serving , author=. Proceedings of Machine Learning and Systems , volume=
-
[13]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
T-mac: CPU Renaissance via Table Lookup for Low-bit LLM Deployment on Edge , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[14]
2024 USENIX Annual Technical Conference (USENIX ATC 24) , pages=
\ Quant-LLM \ : Accelerating the Serving of Large Language Models via \ FP6-Centric \ \ Algorithm-System \ \ Co-Design \ on Modern \ GPUs \ , author=. 2024 USENIX Annual Technical Conference (USENIX ATC 24) , pages=
2024
-
[15]
Advances in neural information processing systems , volume=
Qlora: Efficient Finetuning of Quantized LLMs , author=. Advances in neural information processing systems , volume=
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about Physical Commonsense in Natural Language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
arXiv preprint arXiv:2009.03300 , year=
Measuring Massive Multitask Language Understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[18]
arXiv preprint arXiv:1803.05457 , year=
Think You Have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[19]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
HellaSwag: Can a Machine Really Finish your Sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[20]
Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context , author=. Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[21]
BoolQ: Exploring the Surprising Difficulty of Natural yes/no Questions , author=. Proceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers) , pages=
2019
-
[22]
Lintang Sutawika and Hailey Schoelkopf and Leo Gao and Baber Abbasi and Stella Biderman and Jonathan Tow and ben fattori and Charles Lovering and farzanehnakhaee70 and Jason Phang and Anish Thite and Fazz and Thomas Wang and Niklas and Aflah and sdtblck and nopperl and gakada and tttyuntian and researcher2 and Julen Etxaniz and Chris and James A. Michaelo...
-
[23]
Communications of the ACM , volume=
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[24]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo
-
[25]
Advances in neural information processing systems , volume=
Language Models are Few-shot Learners , author=. Advances in neural information processing systems , volume=
-
[26]
arXiv preprint arXiv:2210.17323 , year=
Gptq: Accurate Post-training Quantization for Generative Pre-trained Transformers , author=. arXiv preprint arXiv:2210.17323 , year=
-
[27]
Proceedings of machine learning and systems , volume=
Awq: Activation-aware Weight Quantization for On-device LLM Compression and Acceleration , author=. Proceedings of machine learning and systems , volume=
-
[28]
arXiv preprint arXiv:2310.08659 , year=
Loftq: Lora-fine-tuning-aware Quantization for Large Language Models , author=. arXiv preprint arXiv:2310.08659 , year=
-
[29]
arXiv preprint arXiv:2410.21271 , year=
EoRA: Fine-tuning-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation , author=. arXiv preprint arXiv:2410.21271 , year=
-
[30]
International conference on machine learning , pages=
Similarity of Neural Network Representations Revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[31]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and Fine-tuned Chat Models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Owq: Outlier-aware Weight Quantization for Efficient Fine-tuning and Inference of Large Language Models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
and Keutzer, Kurt , booktitle =
Kim, Sehoon and Hooper, Coleman Richard Charles and Gholami, Amir and Dong, Zhen and Li, Xiuyu and Shen, Sheng and Mahoney, Michael W. and Keutzer, Kurt , booktitle =. 2024 , editor =
2024
-
[34]
Advances in Neural Information Processing Systems , volume=
Quarot: Outlier-free 4-bit Inference in Rotated LLMs , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
The Thirteenth International Conference on Learning Representations , pages=
SpinQuant: LLM Quantization with Learned Rotations , author=. The Thirteenth International Conference on Learning Representations , pages=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
ASER: Activation Smoothing and Error Reconstruction for Large Language Model Quantization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
The Twelfth International Conference on Learning Representations , pages=
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models , author=. The Twelfth International Conference on Learning Representations , pages=
-
[38]
Advances in neural information processing systems , volume=
Quip: 2-bit Quantization of Large Language Models with Guarantees , author=. Advances in neural information processing systems , volume=
-
[39]
Neural Information Processing Systems , year=
The Llama 3 herd of models , author=. Neural Information Processing Systems , year=
-
[40]
Advances in Neural Information Processing Systems , volume=
Optimal Brain Compression: A Framework for Accurate Post-training Quantization and Pruning , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Advances in Neural Information Processing Systems , volume=
Duquant: Distributing Outliers via Dual Transformation Makes Stronger Quantized LLMs , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Advances in neural information processing systems , volume=
Magr: Weight Magnitude Reduction for Enhancing Post-Training Quantization , author=. Advances in neural information processing systems , volume=
-
[43]
The Twelfth International Conference on Learning Representations , pages=
AffineQuant: Affine Transformation Quantization for Large Language Models , author=. The Twelfth International Conference on Learning Representations , pages=
-
[44]
The Thirteenth International Conference on Learning Representations , year =
OSTQuant: Refining Large Language Model Quantization with Orthogonal and Scaling Transformations for Better Distribution Fitting , author=. The Thirteenth International Conference on Learning Representations , year =
-
[45]
2025 , volume =
Sun, Yuxuan and Liu, Ruikang and Bai, Haoli and Bao, Han and Zhao, Kang and Li, Yuening and Hu, Jiaxin and Yu, Xianzhi and Hou, Lu and Yuan, Chun and Jiang, Xin and Liu, Wulong and Yao, Jun , booktitle =. 2025 , volume =
2025
-
[46]
in Post-Training Quantization , author =
Qronos: Correcting the Past by Shaping the Future... in Post-Training Quantization , author =. The Fourteenth International Conference on Learning Representations , year =
-
[47]
and Zhao, Yiren , title =
Zhang, Cheng and Cheng, Jianyi and Constantinides, George A. and Zhao, Yiren , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[48]
The Thirteenth International Conference on Learning Representations , year =
QERA: an Analytical Framework for Quantization Error Reconstruction , author=. The Thirteenth International Conference on Learning Representations , year =
-
[49]
2019 IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
HAWQ: Hessian AWare Quantization of Neural Networks With Mixed-Precision , author=. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) , pages=. 2019 , organization=
2019
-
[50]
arXiv preprint arXiv:2505.22988 , year=
Model-preserving Adaptive Rounding , author=. arXiv preprint arXiv:2505.22988 , year=
-
[51]
Forty-second International Conference on Machine Learning , year =
GPTAQ: Efficient Finetuning-Free Quantization for Asymmetric Calibration , author=. Forty-second International Conference on Machine Learning , year =
-
[52]
2023 , editor =
Xiao, Guangxuan and Lin, Ji and Seznec, Mickael and Wu, Hao and Demouth, Julien and Han, Song , booktitle =. 2023 , editor =
2023
-
[53]
2024 , editor =
Tseng, Albert and Chee, Jerry and Sun, Qingyao and Kuleshov, Volodymyr and De Sa, Christopher , booktitle =. 2024 , editor =
2024
-
[54]
Proceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming , pages=
Marlin: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models , author=. Proceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming , pages=
-
[55]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[56]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , year =
Amey Agrawal and Nitin Kedia and Ashish Panwar and Jayashree Mohan and Nipun Kwatra and Bhargav Gulavani and Alexey Tumanov and Ramachandran Ramjee , title =. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , year =
-
[57]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
\ DistServe \ : Disaggregating Prefill and Decoding for Goodput-optimized Large Language model Serving , author=. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
-
[58]
Advances in neural information processing systems , volume=
Flashattention: Fast and Memory-efficient Exact Attention with IO-awareness , author=. Advances in neural information processing systems , volume=
-
[59]
Proceedings of Machine Learning and Systems , volume=
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving , author=. Proceedings of Machine Learning and Systems , volume=
-
[60]
arXiv preprint arXiv:2311.03285 , year=
S-LoRA: Serving Thousands of Concurrent LoRA Adapters , author=. arXiv preprint arXiv:2311.03285 , year=
-
[61]
Advances in Neural Information Processing Systems , volume=
Flashattention-3: Fast and Accurate Attention with Asynchrony and Low-precision , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.