Learning the Error Patterns of Language Models
Pith reviewed 2026-06-29 13:53 UTC · model grok-4.3
The pith
Prefix filters learned by Palla capture LLM error patterns and raise validity rates via constrained sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prefix filters are per-domain-and-LLM symbolic functions that represent the focused error patterns LLMs exhibit on validity-constrained tasks. Palla learns these filters efficiently in practice. Once obtained, the filters both quantify the dominant failure modes of a model and serve as the basis for constrained sampling algorithms that improve the fraction of valid outputs without retraining.
What carries the argument
Prefix filters: per-domain-and-LLM symbolic functions that encode common error patterns, learned by the Palla algorithm and applied during constrained sampling.
If this is right
- Prefix filters supply a quantitative breakdown of which error types dominate for a given model and domain.
- Constrained sampling that avoids the learned prefixes raises the rate of valid outputs on tasks such as program generation.
- Smaller models equipped with the filters reach validity performance comparable to much larger unconstrained models.
- The same machinery applies to any domain where validity is checkable and errors cluster into few repeatable forms.
Where Pith is reading between the lines
- The method could be applied to other structured-output tasks such as generating valid JSON schemas or mathematical derivations where validity is mechanically verifiable.
- If prefix filters prove stable across model scales, they might serve as a lightweight post-training correction layer rather than requiring full retraining.
- Integration of the learned constraints back into the training objective could reduce the emergence of the captured error patterns in the first place.
Load-bearing premise
Error patterns of LLMs in domains with validity constraints can be represented using a small number of constraints that can be learned in practice.
What would settle it
A test across several domains and models in which no small collection of prefix filters can be learned that both covers most observed errors and produces a substantial lift in validity rate under constrained sampling.
Figures


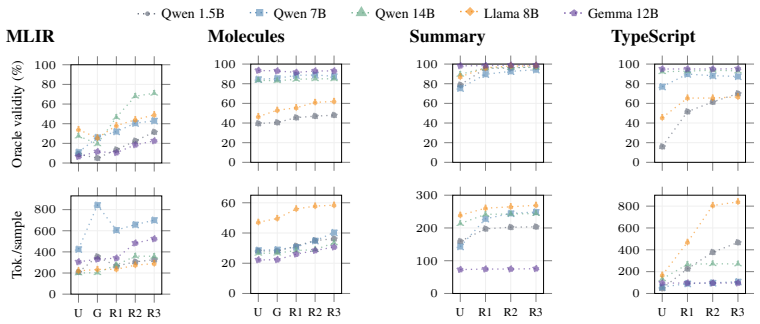
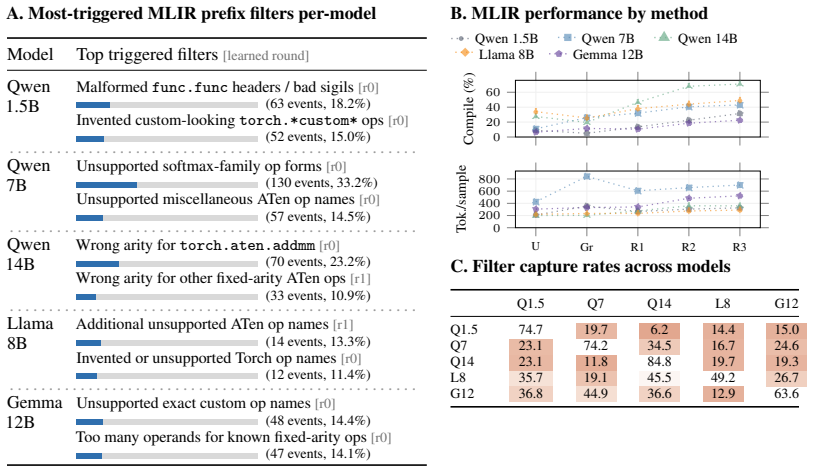
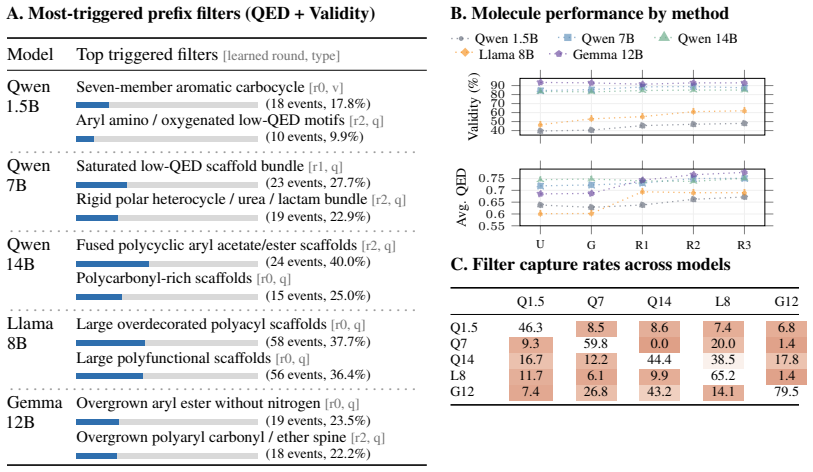

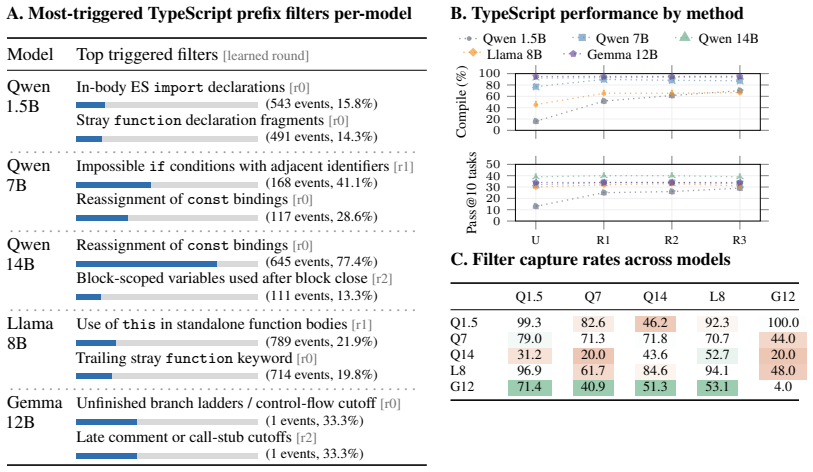

read the original abstract
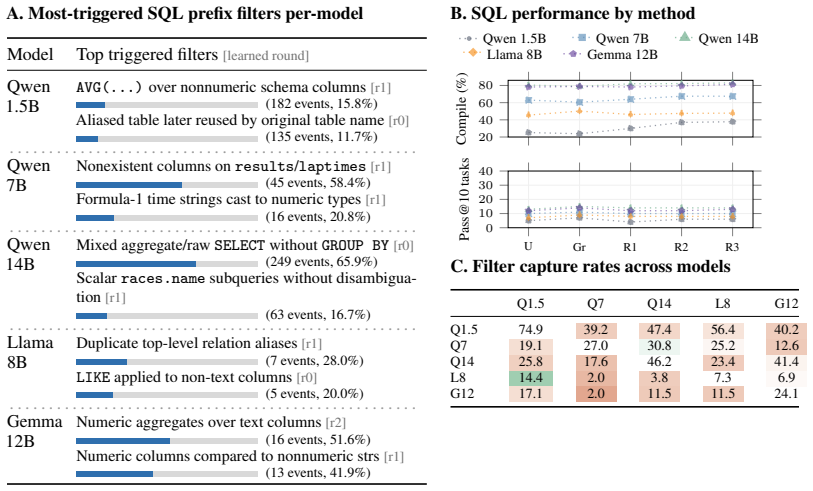
When generating outputs for domains with specific validity constraints (e.g., a program should compile), LLMs often fail in a small number of focused ways: for example, by using Python function names when generating TypeScript. We observe that these error patterns can be represented using a small number of constraints that can be learned in practice. We propose \emph{prefix filters}, which are per-domain-and-LLM symbolic functions, as objects to capture the error patterns, Palla as an algorithm to learn prefix filters efficiently in practice, and implement Palla. Prefix filters learned by Palla i) help us quantitatively analyze the error patterns of LLMs, and ii) can be used to constrain the outputs of a model via constrained sampling algorithms. For example, Palla boosts compile rates for Qwen2.5-1.5B on TypeScript generation, by over 60%, allowing Qwen2.5-1.5B to achieve similar performance to Llama3.1-8B unconstrained.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that error patterns of LLMs in validity-constrained domains (e.g., program compilation) can be represented by a small number of learnable symbolic constraints. It introduces prefix filters as per-domain-and-LLM symbolic functions to capture these patterns, proposes the Palla algorithm to learn them efficiently, and shows their dual use for quantitative error analysis and for constrained sampling to improve validity. The central empirical example is that Palla boosts compile rates for Qwen2.5-1.5B on TypeScript generation by over 60%, allowing it to match the performance of unconstrained Llama3.1-8B.
Significance. If the empirical claims hold, the work offers a practical, symbolic approach to diagnosing and mitigating focused error modes in LLMs without scaling model size. The ability to learn a compact set of constraints that both explain errors and enable constrained decoding could be useful for reliability-critical generation tasks such as code synthesis. The framing of prefix filters as analyzable objects also provides a new lens for studying LLM failure modes.
major comments (2)
- [Abstract] Abstract: the central claim of a >60% compile-rate improvement is presented with no information on how the prefix filters are learned, what data or supervision is used, how baselines are constructed, or whether the gain holds under different sampling temperatures, model sizes, or domains. This absence leaves the primary empirical support for the representability and utility claims without visible controls or derivation.
- [Abstract] Abstract: the assertion that error patterns 'can be represented using a small number of constraints that can be learned in practice' is load-bearing for both the analysis and constrained-sampling contributions, yet no section, equation, or experimental detail is supplied to show how the number of filters is chosen, what symbolic form they take, or any ablation confirming sufficiency.
minor comments (1)
- The abstract would be clearer if it briefly indicated the range of domains or tasks beyond the TypeScript example on which prefix filters were evaluated.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments on the abstract. We address each point below and will revise the abstract to incorporate additional methodological context while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a >60% compile-rate improvement is presented with no information on how the prefix filters are learned, what data or supervision is used, how baselines are constructed, or whether the gain holds under different sampling temperatures, model sizes, or domains. This absence leaves the primary empirical support for the representability and utility claims without visible controls or derivation.
Authors: We agree the abstract omits these specifics. Prefix filters are learned by the Palla algorithm from a supervised dataset of LLM outputs labeled by a validity oracle (e.g., TypeScript compiler), as described in Section 3. Baselines consist of the unconstrained target model plus larger reference models. Section 5 reports results across sampling temperatures 0.2–1.0, multiple model sizes, and an additional Python domain. We will revise the abstract to briefly note the supervised learning procedure and the robustness checks. revision: yes
-
Referee: [Abstract] Abstract: the assertion that error patterns 'can be represented using a small number of constraints that can be learned in practice' is load-bearing for both the analysis and constrained-sampling contributions, yet no section, equation, or experimental detail is supplied to show how the number of filters is chosen, what symbolic form they take, or any ablation confirming sufficiency.
Authors: The symbolic form (prefix rejection functions over token sequences) is formalized in Section 2. Palla selects the number of filters via an iterative coverage criterion detailed with pseudocode in Section 3; sufficiency is confirmed by ablations in Section 5.2 showing that a small set (typically <20) captures the bulk of errors. We will add one sentence to the abstract summarizing the learning procedure and empirical validation of compactness. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claim is an empirical observation that LLM error patterns in constrained domains are representable by a small number of learnable symbolic prefix filters, discovered via the Palla algorithm, with downstream use for analysis and constrained sampling. The abstract and high-level description present this as a direct empirical finding supported by a concrete improvement example (TypeScript compile rates), without any derivation that reduces a prediction to a fitted input by construction, without load-bearing self-citations, and without renaming or ansatz smuggling. The method is described as learning from observed errors rather than tautologically fitting the measured quantity, so the reported gains are not forced by the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Error patterns of LLMs can be represented using a small number of constraints that can be learned in practice.
invented entities (2)
-
prefix filters
no independent evidence
-
Palla algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://github.com/large-loris-models/germinator/blob/ main/src/germinator/grammar/grammars/mlir.g4
Mlir grammar. URL https://github.com/large-loris-models/germinator/blob/ main/src/germinator/grammar/grammars/mlir.g4
-
[2]
URL https://github.com/genlm/genlm-eval/blob/main/assets/ molecular_synthesis/smiles.lark
Smiles grammar. URL https://github.com/genlm/genlm-eval/blob/main/assets/ molecular_synthesis/smiles.lark
-
[3]
https://github.com/tree-sitter/tree-sitter-typescript
tree-sitter-typescript. https://github.com/tree-sitter/tree-sitter-typescript . Accessed 2026-05-06
2026
-
[4]
URLhttps://github.com/microsoft/TypeScript/blob/main/ src/compiler/diagnosticMessages.json
Typescript error codes. URLhttps://github.com/microsoft/TypeScript/blob/main/ src/compiler/diagnosticMessages.json
-
[5]
https://github.com/lark-parser/lark, 2025
Lark - a parsing toolkit for python. https://github.com/lark-parser/lark, 2025. Ac- cessed 2026-05-06
2025
-
[6]
llguidance: Super-fast structured outputs, 2025
Guidance AI. llguidance: Super-fast structured outputs, 2025. URL https://github.com/ guidance-ai/llguidance. Accessed: 2025-09-23
2025
-
[7]
Syntax- guided synthesis
Rajeev Alur, Rastislav Bodik, Garvit Juniwal, Milo MK Martin, Mukund Raghothaman, Sanjit A Seshia, Rishabh Singh, Armando Solar-Lezama, Emina Torlak, and Abhishek Udupa. Syntax- guided synthesis. In2013 Formal Methods in Computer-Aided Design, pages 1–8. IEEE, 2013
2013
-
[8]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
An empirical investigation of statistical significance in nlp
Taylor Berg-Kirkpatrick, David Burkett, and Dan Klein. An empirical investigation of statistical significance in nlp. InProceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning, pages 995–1005, 2012
2012
-
[10]
Richard Bickerton, Gaia V
G. Richard Bickerton, Gaia V . Paolini, Jérémy Besnard, Sorel Muresan, and Andrew L. Hopkins. Quantifying the chemical beauty of drugs.Nature Chemistry, 4(2):90–98, 2012. doi: 10.1038/ nchem.1243
2012
-
[11]
Multipl- e: A scalable and polyglot approach to benchmarking neural code generation.IEEE Transactions on Software Engineering, 49(7):3675–3691, 2023
Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q Feldman, et al. Multipl- e: A scalable and polyglot approach to benchmarking neural code generation.IEEE Transactions on Software Engineering, 49(7):3675–3691, 2023
2023
-
[12]
Deep reinforcement learning from human preferences
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.arXiv preprint arXiv:1706.03741, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Quentin Carbonneaux, Taco Cohen, and Gabriel Synnaeve. Rlef: Grounding code llms in execution feedback with reinforcement learning.arXiv preprint arXiv:2410.02089, 2024
-
[14]
Grammar- constrained decoding for structured NLP tasks without finetuning,
Saibo Geng, Martin Josifoski, Maxime Peyrard, and Robert West. Grammar-constrained decoding for structured nlp tasks without finetuning.arXiv preprint arXiv:2305.13971, 2023
-
[15]
GenLM: Language model probabilistic programming
GenLM Consortium. GenLM: Language model probabilistic programming. https://genlm. org/, 2026. Accessed 2026-05-06
2026
-
[16]
The Llama 3 herd of models, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, and Abhishek Ka- dianand others. The Llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407. 21783
2024
-
[17]
Semantics-guided synthesis
Jinwoo Kim, Qinheping Hu, Loris D’Antoni, and Thomas Reps. Semantics-guided synthesis. Proceedings of the ACM on Programming Languages, 5(POPL):1–32, 2021
2021
-
[18]
MLIR: Scaling compiler infrastructure for domain specific computation
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Oleksandr Zinenko. MLIR: Scaling compiler infrastructure for domain specific computation. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 2–14, 2021. doi: 10.1109/ CGO51591...
-
[19]
Coderl: Mastering code generation through pretrained models and deep reinforcement learning
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. Advances in Neural Information Processing Systems, 35:21314–21328, 2022. 10
2022
-
[20]
Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls.Advances in Neural Information Processing Systems, 36:42330–42357, 2023
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls.Advances in Neural Information Processing Systems, 36:42330–42357, 2023
2023
-
[21]
Type- constrained code generation with language models.Proceedings of the ACM on Programming Languages, 9(PLDI):601–626, 2025
Niels Mündler, Jingxuan He, Hao Wang, Koushik Sen, Dawn Song, and Martin Vechev. Type- constrained code generation with language models.Proceedings of the ACM on Programming Languages, 9(PLDI):601–626, 2025
2025
-
[22]
Shaan Nagy, Timothy Zhou, Nadia Polikarpova, and Loris D’Antoni. Chopchop: A pro- grammable framework for semantically constraining the output of language models.Proc. ACM Program. Lang., 10(POPL), January 2026. doi: 10.1145/3776708. URL https: //doi.org/10.1145/3776708
-
[23]
Introducing gpt -5.4 mini and nano
OpenAI. Introducing gpt -5.4 mini and nano. URL https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/
-
[24]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[25]
Loud: Synthesizing strongest and weakest specifications.Proceedings of the ACM on Programming Languages, 9(OOPSLA1):956–983, 2025
Kanghee Park, Xuanyu Peng, and Loris D’Antoni. Loud: Synthesizing strongest and weakest specifications.Proceedings of the ACM on Programming Languages, 9(OOPSLA1):956–983, 2025
2025
-
[26]
Flexible and efficient grammar-constrained decoding
Kanghee Park, Timothy Zhou, and Loris D’Antoni. Flexible and efficient grammar-constrained decoding. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=L6CYAzpO1k
2025
-
[27]
Constrained Adaptive Rejection Sampling
Paweł Parys, Sairam Vaidya, Taylor Berg-Kirkpatrick, and Loris D’Antoni. Constrained adaptive rejection sampling, 2025. URLhttps://arxiv.org/abs/2510.01902
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Daniil Polykovskiy, Alexander Zhebrak, Benjamin Sanchez-Lengeling, Sergey Golovanov, Oktai Tatanov, Stanislav Belyaev, Rauf Kurbanov, Aleksey Artamonov, Vladimir Aladinskiy, Mark Veselov, Artur Kadurin, Simon Johansson, Hongming Chen, Sergey Nikolenko, Al ’an Aspuru-Guzik, and Alex Zhavoronkov. Molecular sets (MOSES): A benchmarking platform for molecular...
-
[29]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[30]
RDKit: Open-source cheminformatics
RDKit. RDKit: Open-source cheminformatics. http://www.rdkit.org. Accessed: 2025- 09-20
2025
-
[31]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[34]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[35]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
On computable numbers, with an application to the entschei- dungsproblem.J
Alan Mathison Turing et al. On computable numbers, with an application to the entschei- dungsproblem.J. of Math, 58(345-363):5, 1936
1936
-
[37]
Sairam Vaidya, Marcel Böhme, and Loris D’Antoni. Bootstrapping fuzzers for compilers of low-resource language dialects using language models.arXiv preprint arXiv:2512.05887, 2025
-
[38]
Anjiang Wei, Tarun Suresh, Huanmi Tan, Yinglun Xu, Gagandeep Singh, Ke Wang, and Alex Aiken. Supercoder: Assembly program superoptimization with large language models.arXiv preprint arXiv:2505.11480, 2025
-
[39]
SMILES, a chemical language and information system
David Weininger. SMILES, a chemical language and information system. 1. introduction to methodology and encoding rules.Journal of Chemical Information and Computer Sciences, 28 (1):31–36, 1988. doi: 10.1021/ci00057a005
-
[40]
Efficient Guided Generation for Large Language Models
Brandon T Willard and Rémi Louf. Efficient guided generation for large language models. arXiv preprint arXiv:2307.09702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
HR-MultiWOZ: A task oriented dialogue (TOD) dataset for HR LLM agent
Weijie Xu, Zicheng Huang, Wenxiang Hu, Xi Fang, Rajesh Cherukuri, Naumaan Nayyar, Lorenzo Malandri, and Srinivasan Sengamedu. HR-MultiWOZ: A task oriented dialogue (TOD) dataset for HR LLM agent. InProceedings of the First Workshop on Natural Language Processing for Human Resources (NLP4HR 2024), pages 59–72, St. Julian’s, Malta, March
2024
-
[42]
doi: 10.18653/v1/2024.nlp4hr-1.5
Association for Computational Linguistics. doi: 10.18653/v1/2024.nlp4hr-1.5. URL https://aclanthology.org/2024.nlp4hr-1.5/
-
[43]
Qwen2.5 technical report,
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
-
[44]
URLhttps://arxiv.org/abs/2412.15115. 12 A Model Checkpoints We used the following models in our evaluation: Model URL Commit Qwen 1.5Bhttps://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct 989aa7 Qwen 7Bhttps://huggingface.co/Qwen/Qwen2.5-7B-Instruct a09a35 Qwen 14Bhttps://huggingface.co/Qwen/Qwen2.5-14B-Instruct cf98f3 Llama 8Bhttps://huggingface.co/meta-llam...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.