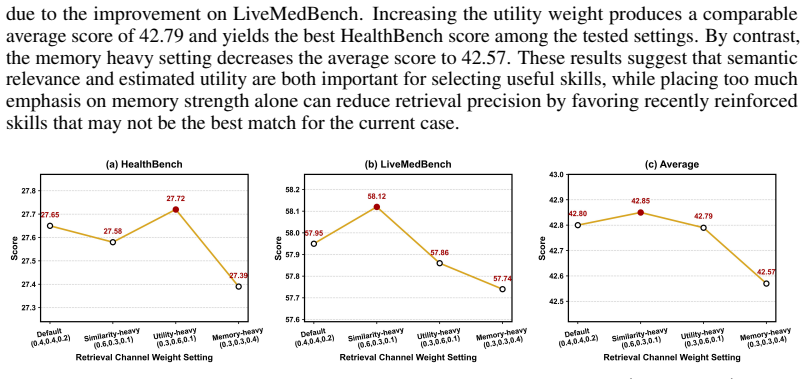
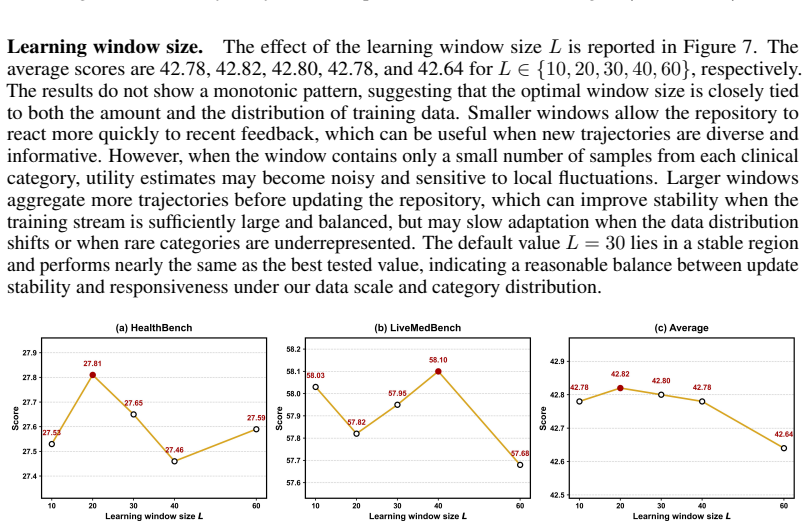
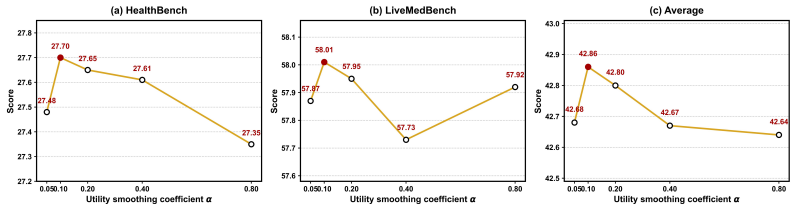
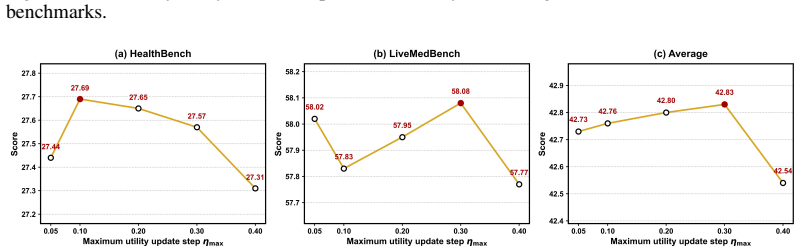
Experience Makes Skillful: Enabling Generalizable Medical Agent Reasoning via Self-Evolving Skill Memory
Pith reviewed 2026-06-27 16:43 UTC · model grok-4.3
The pith
Medical agents improve clinical reasoning by building and governing reusable skill memories from interaction feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SkeMex is a post-deployment self-evolution framework that distills informative interaction trajectories into structured skills encoding reusable procedural knowledge, organizes them into a multi-branch repository, estimates context-dependent utility from environment feedback to guide value-aware retrieval and repository governance, and uses a closed-loop Read-Write-Assess-Govern lifecycle to write new skills, update utilities, promote useful memories, and remove harmful entries, resulting in consistent outperformance of representative memory-based agents in diverse clinical tasks both offline and online, while generalizing across model backbones and supporting transferable skill memory.
What carries the argument
The multi-branch skill memory repository combined with context-dependent utility estimation from environment feedback to drive the Read-Write-Assess-Govern lifecycle.
If this is right
- Agents achieve better performance than other memory-based systems on clinical tasks in both offline and online settings.
- The skill memory supports generalization across different model backbones.
- Skill memories can be transferred between different tasks or settings.
- The governance process keeps the memory compact by removing harmful or low-utility entries.
- Procedural knowledge is reused for long-horizon reasoning without redundant raw traces.
Where Pith is reading between the lines
- Similar self-evolving memory could be applied to agent systems in other domains like legal reasoning or scientific discovery where experience accumulates over interactions.
- By focusing on skills instead of raw data, this might reduce storage and retrieval costs in long-term agent deployments.
- Accurate utility estimation could help in creating more reliable agents for real-world use by automatically discarding skills that lead to poor outcomes.
- Future work could test if the same framework works when the agent interacts with real human users rather than simulated environments.
Load-bearing premise
Environment feedback provides a reliable and unbiased signal for judging the usefulness of skills in different contexts.
What would settle it
An experiment where environment feedback is corrupted or biased, then measuring whether the skill governance still leads to performance gains or instead promotes bad skills.
Figures





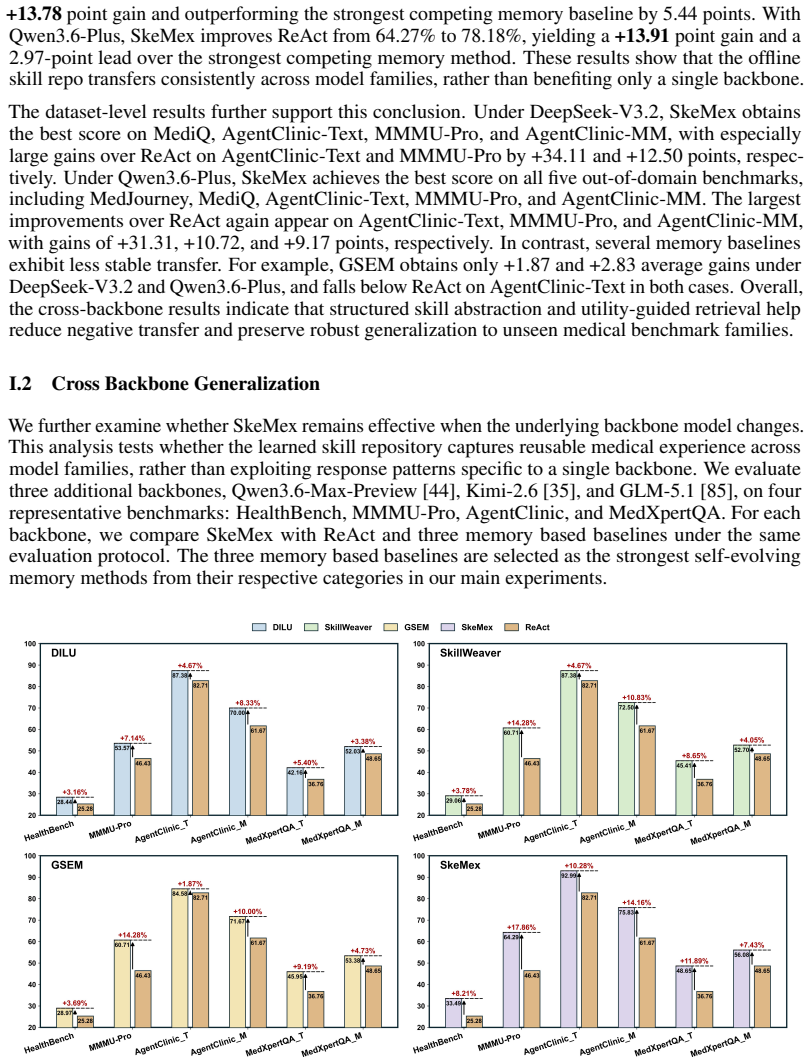





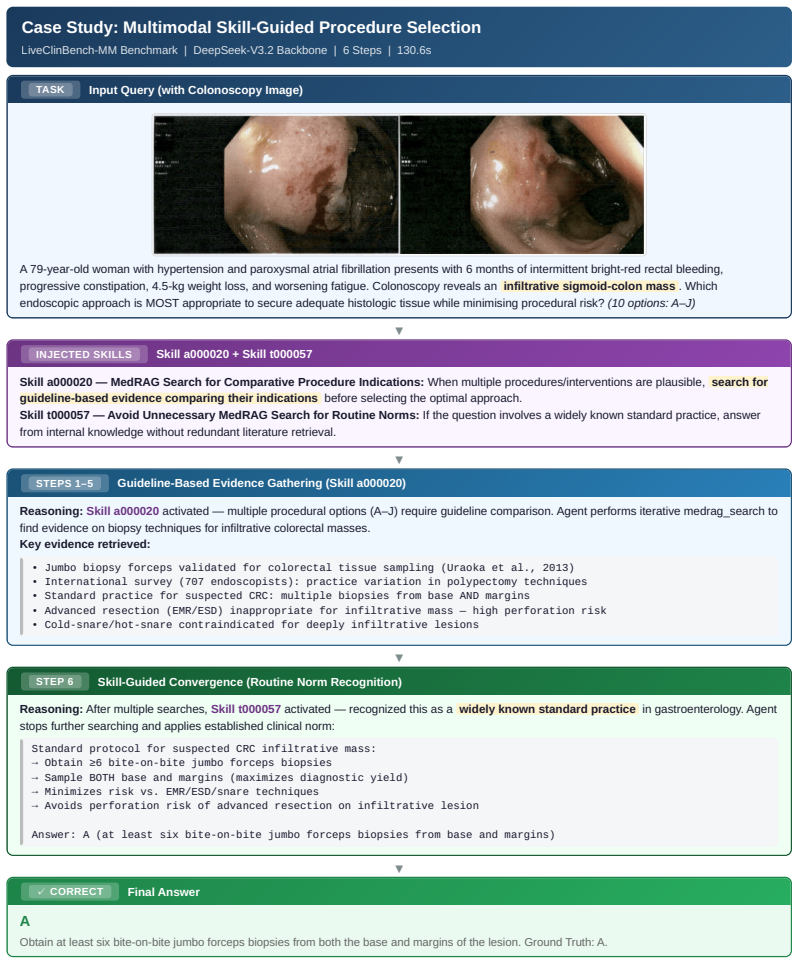














read the original abstract
Medical agent systems are increasingly expected to support interactive clinical decision making rather than only static question answering. In such settings, effective agents must reuse prior experience across evolving cases, yet existing memory mechanisms often retain raw historical traces that are redundant, noisy, and difficult to govern. More importantly, they rarely distinguish which memories are truly useful for future reasoning. This limits their ability to accumulate compact and reliable experience for long-horizon clinical reasoning. To close this gap, we propose SkeMex, a post-deployment self-evolution framework that improves medical agents through a skill-based memory without updating model weights. SkeMex distills informative interaction trajectories into structured skills that encode reusable procedural knowledge, and organizes them into a multi-branch repository spanning general, task-specific, and action-level experience. To determine which memories should be reused and retained, SkeMex estimates context-dependent utility from environment feedback and uses it to guide value-aware retrieval and repository governance. A closed-loop ``Read--Write--Assess--Govern" lifecycle further supports continual evolution by writing new skills, updating utilities, promoting useful memories, and removing harmful entries. Experiments across diverse clinical tasks show that SkeMex consistently outperforms representative memory-based agents in both offline and online settings. It also generalizes across model backbones and supports transferable skill memory. All data and code will be released publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SkeMex, a post-deployment self-evolution framework for medical agents. It distills interaction trajectories into structured skills organized in a multi-branch repository (general, task-specific, action-level), estimates context-dependent utility from environment feedback to guide retrieval and governance, and implements a closed-loop Read-Write-Assess-Govern lifecycle for continual evolution without model weight updates. Experiments across diverse clinical tasks report consistent outperformance over representative memory-based agents in offline and online settings, with generalization across model backbones and transferable skill memory.
Significance. If the results hold, the work could meaningfully advance adaptive medical AI systems by enabling compact, governable experience accumulation for long-horizon clinical reasoning. The emphasis on skill distillation over raw traces and the public release of data/code strengthen reproducibility and practical impact.
major comments (2)
- [§3 (Method), Assess/Govern stages] §3 (Method), Assess/Govern stages: The central claim that context-dependent utility estimated from environment feedback reliably drives promotion, retention, and removal decisions lacks a concrete description of the utility estimator, any debiasing procedures, or handling of noisy/delayed clinical feedback. This is load-bearing for the governance loop and the headline outperformance result; without it, observed gains could be artifacts of the simulation environments rather than robust skill evolution.
- [§5 (Experiments)] §5 (Experiments): The reported consistent outperformance across tasks and backbones requires ablations that isolate the utility-based governance from skill distillation alone, plus statistical significance testing and failure-case analysis (e.g., retention of low-value skills). These are needed to substantiate that the closed-loop mechanism, rather than other factors, drives the gains.
minor comments (2)
- [Figure 2] Figure 2 (repository diagram): The multi-branch structure and Read-Write-Assess-Govern flow would be clearer with explicit pseudocode or an expanded legend for the utility update rule.
- [§4 (Implementation)] §4 (Implementation): The description of how skills are distilled from trajectories could include more detail on the prompting templates or extraction heuristics used.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments identify areas where additional clarity and analysis will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3 (Method), Assess/Govern stages] §3 (Method), Assess/Govern stages: The central claim that context-dependent utility estimated from environment feedback reliably drives promotion, retention, and removal decisions lacks a concrete description of the utility estimator, any debiasing procedures, or handling of noisy/delayed clinical feedback. This is load-bearing for the governance loop and the headline outperformance result; without it, observed gains could be artifacts of the simulation environments rather than robust skill evolution.
Authors: We agree that the current description of the utility estimator in §3 is high-level and requires expansion to fully substantiate the governance mechanism. In the revised manuscript we will add an explicit formulation of the context-dependent utility computation (including the precise aggregation of environment feedback signals such as task success, step efficiency, and error recovery), along with a dedicated subsection on potential biases and mitigation strategies. We will also discuss the deterministic nature of feedback in the current simulation environments and outline planned extensions for handling noisy or delayed real-world clinical signals. These additions will clarify how promotion, retention, and removal decisions are driven and reduce the risk that gains are simulation-specific artifacts. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments): The reported consistent outperformance across tasks and backbones requires ablations that isolate the utility-based governance from skill distillation alone, plus statistical significance testing and failure-case analysis (e.g., retention of low-value skills). These are needed to substantiate that the closed-loop mechanism, rather than other factors, drives the gains.
Authors: We concur that isolating the contribution of the Assess/Govern stages is essential. The revision will include new ablation experiments that disable the utility-based governance while retaining skill distillation and the Read-Write components, allowing direct comparison of performance deltas. We will also report statistical significance (paired t-tests or Wilcoxon tests across repeated runs with different seeds) and add a failure-case analysis subsection that examines instances of low-value skill retention or erroneous removal. These results will be presented alongside the existing offline and online evaluations to demonstrate that the closed-loop lifecycle, rather than distillation alone, accounts for the observed improvements. revision: yes
Circularity Check
No significant circularity; framework is self-contained via external experiments
full rationale
The paper introduces SkeMex as a post-deployment framework with a Read-Write-Assess-Govern lifecycle that distills trajectories into skills and governs them via environment feedback for utility. No equations, parameter fits, derivations, or self-citations appear in the abstract or description. Outperformance claims rest on experiments across clinical tasks, model backbones, and offline/online settings rather than any reduction of outputs to inputs by construction. The central claims are empirically grounded and independent of self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Interaction trajectories contain extractable procedural knowledge that can be represented as reusable skills without critical loss of context.
Reference graph
Works this paper leans on
-
[1]
Building agents with skills: Equipping agents for specialized work, 2026
Anthropic. Building agents with skills: Equipping agents for specialized work, 2026
2026
-
[2]
Claude Sonnet 4.6.https://www.anthropic.com/claude/sonnet, 2026
Anthropic. Claude Sonnet 4.6.https://www.anthropic.com/claude/sonnet, 2026
2026
-
[3]
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, et al. Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
Pith/arXiv arXiv 2025
-
[4]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[5]
The clinical reasoning process.Medical education, 21(2):86–91, 1987
Howard S Barrows and Paul J Feltovich. The clinical reasoning process.Medical education, 21(2):86–91, 1987
1987
-
[6]
The unified medical language system (umls): integrating biomedical terminology.Nucleic acids research, 32(suppl_1):D267–D270, 2004
Olivier Bodenreider. The unified medical language system (umls): integrating biomedical terminology.Nucleic acids research, 32(suppl_1):D267–D270, 2004
2004
-
[7]
Benchmarking large language models on answering and explaining challenging medical questions
Hanjie Chen, Zhouxiang Fang, Yash Singla, and Mark Dredze. Benchmarking large language models on answering and explaining challenging medical questions. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3563–3599, 2025
2025
-
[8]
Chengfeng Dou, Chong Liu, Fan Yang, Fei Li, Jiyuan Jia, Mingyang Chen, Qiang Ju, Shuai Wang, Shunya Dang, Tianpeng Li, et al. Baichuan-m2: Scaling medical capability with large verifier system.arXiv preprint arXiv:2509.02208, 2025
arXiv 2025
-
[9]
A guide to deep learning in healthcare.Nature medicine, 25(1):24–29, 2019
Andre Esteva, Alexandre Robicquet, Bharath Ramsundar, V olodymyr Kuleshov, Mark DePristo, Katherine Chou, Claire Cui, Greg Corrado, Sebastian Thrun, and Jeff Dean. A guide to deep learning in healthcare.Nature medicine, 25(1):24–29, 2019
2019
-
[10]
Lin Fan, Pengyu Dai, Zhipeng Deng, Haolin Wang, Xun Gong, Yefeng Zheng, and Yafei Ou. Evolving medical imaging agents via experience-driven self-skill discovery.arXiv preprint arXiv:2603.05860, 2026
arXiv 2026
-
[11]
Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025
Pith/arXiv arXiv 2025
-
[12]
Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, et al. A survey of self-evolving agents: On path to artificial super intelligence.arXiv preprint arXiv:2507.21046, 1, 2025
Pith/arXiv arXiv 2025
-
[13]
A new era of intelligence with gemini 3, 2025
Google. A new era of intelligence with gemini 3, 2025
2025
-
[14]
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738, 2023
Pith/arXiv arXiv 2023
-
[15]
Ds-agent: Automated data science by empowering large language models with case-based reasoning
Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, and Jun Wang. Ds-agent: Automated data science by empowering large language models with case-based reasoning. arXiv preprint arXiv:2402.17453, 2024
arXiv 2024
-
[16]
Optimizing case-based reasoning system for functional test script generation with large language models
Siyuan Guo, Huiwu Liu, Xiaolong Chen, Yuming Xie, Liang Zhang, Tao Han, Hechang Chen, Yi Chang, and Jun Wang. Optimizing case-based reasoning system for functional test script generation with large language models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 4487–4498, 2025
2025
-
[17]
Xiao Han, Yuzheng Fan, Sendong Zhao, Haochun Wang, and Bing Qin. Gsem: Graph- based self-evolving memory for experience augmented clinical reasoning.arXiv preprint arXiv:2603.22096, 2026. 11
arXiv 2026
-
[18]
The landscape of medical agents: A survey
Xiaobin Hu, Yunhang Qian, Jiaquan Yu, Jingjing Liu, Xiaozhong Ji, Chengming Xu, Peng Tang, Chengming Xu, Peng Tang, Jiawei Liu, et al. The landscape of medical agents: A survey. 2026
2026
-
[19]
Songtao Jiang, Yuan Wang, Sibo Song, Tianxiang Hu, Chenyi Zhou, Bin Pu, Yan Zhang, Zhibo Yang, Yang Feng, Joey Tianyi Zhou, et al. Hulu-med: A transparent generalist model towards holistic medical vision-language understanding.arXiv preprint arXiv:2510.08668, 2025
arXiv 2025
-
[20]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[21]
Stella: Self-evolving llm agent for biomedical research.arXiv preprint arXiv:2507.02004, 2025
Ruofan Jin, Zaixi Zhang, Mengdi Wang, and Le Cong. Stella: Self-evolving llm agent for biomedical research.arXiv preprint arXiv:2507.02004, 2025
arXiv 2025
-
[22]
Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S Chan, Xuhai Xu, Daniel McDuff, Hyeon- hoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W Park. Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
2024
-
[23]
An introduction to case-based reasoning.Artificial intelligence review, 6(1):3–34, 1992
Janet L Kolodner. An introduction to case-based reasoning.Artificial intelligence review, 6(1):3–34, 1992
1992
-
[24]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[25]
Patient-zero: A unified framework for real-record-free patient agent generation.arXiv e-prints, pages arXiv–2509, 2025
Yunghwei Lai, Weizhi Ma, and Yang Liu. Patient-zero: A unified framework for real-record-free patient agent generation.arXiv e-prints, pages arXiv–2509, 2025
2025
-
[26]
Depression diagnosis dialogue simulation: self-improving psychiatrist with tertiary memory
Kunyao Lan, Bingrui Jin, Zichen Zhu, Siyuan Chen, Shu Zhang, Kenny Q Zhu, and Mengyue Wu. Depression diagnosis dialogue simulation: self-improving psychiatrist with tertiary memory. arXiv preprint arXiv:2409.15084, 2024
arXiv 2024
-
[27]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[28]
Mmedagent: Learning to use medical tools with multi-modal agent
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin, et al. Mmedagent: Learning to use medical tools with multi-modal agent. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8745–8760, 2024
2024
-
[29]
Junkai Li, Yunghwei Lai, Weitao Li, Jingyi Ren, Meng Zhang, Xinhui Kang, Siyu Wang, Peng Li, Ya-Qin Zhang, Weizhi Ma, et al. Agent hospital: A simulacrum of hospital with evolvable medical agents.arXiv preprint arXiv:2405.02957, 2024
arXiv 2024
-
[30]
Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning.Advances in Neural Information Processing Systems, 37:28858–28888, 2024
Shuyue S Li, Vidhisha Balachandran, Shangbin Feng, Jonathan S Ilgen, Emma Pierson, Pang W Koh, and Yulia Tsvetkov. Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning.Advances in Neural Information Processing Systems, 37:28858–28888, 2024
2024
-
[31]
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, et al. Memos: An operating system for memory-augmented generation (mag) in large language models.arXiv preprint arXiv:2505.22101, 2025
arXiv 2025
-
[32]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
Pith/arXiv arXiv 2025
-
[33]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024. 12
2024
-
[34]
Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377, 2026
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangxiang Chu. Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377, 2026
Pith/arXiv arXiv 2026
-
[35]
Kimi K2.6: Advancing Open-Source Coding
Moonshot AI. Kimi K2.6: Advancing Open-Source Coding. https://www.kimi.com/blog/ kimi-k2-6, 2026
2026
-
[36]
Replication and analysis of ebbinghaus’ forgetting curve.PloS one, 10(7):e0120644, 2015
Jaap MJ Murre and Joeri Dros. Replication and analysis of ebbinghaus’ forgetting curve.PloS one, 10(7):e0120644, 2015
2015
-
[37]
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158, 2026
Pith/arXiv arXiv 2026
-
[38]
New embedding models and api updates, 2024
OpenAI. New embedding models and api updates, 2024
2024
-
[39]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[40]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonza- lez. Memgpt: towards llms as operating systems. 2023
2023
-
[41]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InConference on health, inference, and learning, pages 248–260. PMLR, 2022
2022
-
[42]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[43]
Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026
Qwen Team. Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026
2026
-
[44]
Qwen3.6-Max-Preview: Smarter, sharper, still evolving, April 2026
Qwen Team. Qwen3.6-Max-Preview: Smarter, sharper, still evolving, April 2026
2026
-
[45]
Qwen3.6-Plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-Plus: Towards real world agents, April 2026
2026
-
[46]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[47]
Healthcare agent: eliciting the power of large language models for medical consultation.npj Artificial Intelligence, 1(1):24, 2025
Zhiyao Ren, Yibing Zhan, Baosheng Yu, Liang Ding, Pingbo Xu, and Dacheng Tao. Healthcare agent: eliciting the power of large language models for medical consultation.npj Artificial Intelligence, 1(1):24, 2025
2025
-
[48]
Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024
Pith/arXiv arXiv 2024
-
[49]
Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
Pith/arXiv arXiv 2025
-
[50]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[51]
Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records
Wenqi Shi, Ran Xu, Yuchen Zhuang, Yue Yu, Jieyu Zhang, Hang Wu, Yuanda Zhu, Joyce C Ho, Carl Yang, and May Dongmei Wang. Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22315–22339, 2024. 13
2024
-
[52]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[53]
Welcome to the era of experience.Google AI, 1:11, 2025
David Silver and Richard S Sutton. Welcome to the era of experience.Google AI, 1:11, 2025
2025
-
[54]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
2023
-
[55]
Toward expert-level medical question answering with large language models.Nature medicine, 31(3):943–950, 2025
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models.Nature medicine, 31(3):943–950, 2025
2025
-
[56]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[57]
Dynamic cheatsheet: Test-time learning with adaptive memory
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7080–7106, 2026
2026
-
[58]
Xiangru Tang, Tianrui Qin, Tianhao Peng, Ziyang Zhou, Daniel Shao, Tingting Du, Xinming Wei, Peng Xia, Fang Wu, He Zhu, et al. Agent kb: Leveraging cross-domain experience for agentic problem solving.arXiv preprint arXiv:2507.06229, 2025
arXiv 2025
-
[59]
Medagents: Large language models as collaborators for zero-shot medical reasoning
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. Medagents: Large language models as collaborators for zero-shot medical reasoning. InFindings of the Association for Computational Linguistics: ACL 2024, pages 599–621, 2024
2024
-
[60]
Tavily AI GitHub Organization.https://github.com/tavily-ai, 2026
Tavily AI. Tavily AI GitHub Organization.https://github.com/tavily-ai, 2026
2026
-
[61]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[62]
High-performance medicine: the convergence of human and artificial intelligence
Eric J Topol. High-performance medicine: the convergence of human and artificial intelligence. Nature medicine, 25(1):44–56, 2019
2019
-
[63]
Episodic and semantic memory.Organization of memory, 1(381-403):1, 1972
Endel Tulving et al. Episodic and semantic memory.Organization of memory, 1(381-403):1, 1972
1972
-
[64]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
Pith/arXiv arXiv 2023
-
[65]
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, et al. Skill-sd: Skill-conditioned self-distillation for multi-turn llm agents.arXiv preprint arXiv:2604.10674, 2026
Pith/arXiv arXiv 2026
-
[66]
Augmenting language models with long-term memory.Advances in Neural Information Processing Systems, 36:74530–74543, 2023
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory.Advances in Neural Information Processing Systems, 36:74530–74543, 2023
2023
-
[67]
Liveclin: A live clinical benchmark without leakage.arXiv preprint arXiv:2602.16747, 2026
Xidong Wang, Shuqi Guo, Yue Shen, Junying Chen, Jian Wang, Jinjie Gu, Ping Zhang, Lei Liu, and Benyou Wang. Liveclin: A live clinical benchmark without leakage.arXiv preprint arXiv:2602.16747, 2026
arXiv 2026
-
[68]
Zhenhailong Wang, Haiyang Xu, Junyang Wang, Xi Zhang, Ming Yan, Ji Zhang, Fei Huang, and Heng Ji. Mobile-agent-e: Self-evolving mobile assistant for complex tasks.arXiv preprint arXiv:2501.11733, 2025. 14
arXiv 2025
-
[69]
Medagent-pro: Towards multi- modal evidence-based medical diagnosis via reasoning agentic workflow.arXiv e-prints, pages arXiv–2503, 2025
Ziyue Wang, Junde Wu, Chang Han Low, and Yueming Jin. Medagent-pro: Towards multi- modal evidence-based medical diagnosis via reasoning agentic workflow.arXiv e-prints, pages arXiv–2503, 2025
2025
-
[70]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. arXiv preprint arXiv:2409.07429, 2024
Pith/arXiv arXiv 2024
-
[71]
Medco: Medical education copilots based on a multi-agent framework
Hao Wei, Jianing Qiu, Haibao Yu, and Wu Yuan. Medco: Medical education copilots based on a multi-agent framework. InEuropean Conference on Computer Vision, pages 119–135. Springer, 2024
2024
-
[72]
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H Chi, et al. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025
Pith/arXiv arXiv 2025
-
[73]
Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao. Dilu: A knowledge-driven approach to autonomous driving with large language models.arXiv preprint arXiv:2309.16292, 2023
arXiv 2023
-
[74]
Drugbank 5.0: a major update to the drugbank database for 2018.Nucleic acids research, 46(D1):D1074–D1082, 2018
David S Wishart, Yannick D Feunang, An C Guo, Elvis J Lo, Ana Marcu, Jason R Grant, Tanvir Sajed, Daniel Johnson, Carin Li, Zinat Sayeeda, et al. Drugbank 5.0: a major update to the drugbank database for 2018.Nucleic acids research, 46(D1):D1074–D1082, 2018
2018
-
[75]
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
Pith/arXiv arXiv 2025
-
[76]
Medjourney: Benchmark and evaluation of large language models over patient clinical journey.Advances in Neural Information Processing Systems, 37:87621–87646, 2024
Xian Wu, Yutian Zhao, Yunyan Zhang, Jiageng Wu, Zhihong Zhu, Yingying Zhang, Yi Ouyang, Ziheng Zhang, Huimin Wang, Zhenxi Lin, et al. Medjourney: Benchmark and evaluation of large language models over patient clinical journey.Advances in Neural Information Processing Systems, 37:87621–87646, 2024
2024
-
[77]
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
Pith/arXiv arXiv 2026
-
[78]
Im- proving retrieval-augmented generation in medicine with iterative follow-up questions
Guangzhi Xiong, Qiao Jin, Xiao Wang, Minjia Zhang, Zhiyong Lu, and Aidong Zhang. Im- proving retrieval-augmented generation in medicine with iterative follow-up questions. In Biocomputing 2025: Proceedings of the Pacific Symposium, pages 199–214. World Scientific, 2024
2025
-
[79]
A comprehensive survey of ai agents in healthcare.Journal of Biomedical Informatics, page 105045, 2026
Gelei Xu, Xueyang Li, Yixiong Chen, Yuying Duan, Shuqing Wu, Haoxinran Yu, Ching-Hao Chiu, Juntong Ni, Ningzhi Tang, Toby Jia-Jun Li, et al. A comprehensive survey of ai agents in healthcare.Journal of Biomedical Informatics, page 105045, 2026
2026
-
[80]
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Cheng- hao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foun- dation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.