Know2Guess: A Contamination-Aware Multi-Zone Benchmark for Knowledge-Boundary Evaluation in Large Language Models
Pith reviewed 2026-07-01 08:55 UTC · model grok-4.3
The pith
A contamination-aware multi-zone benchmark distinguishes supported answers from abstention in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
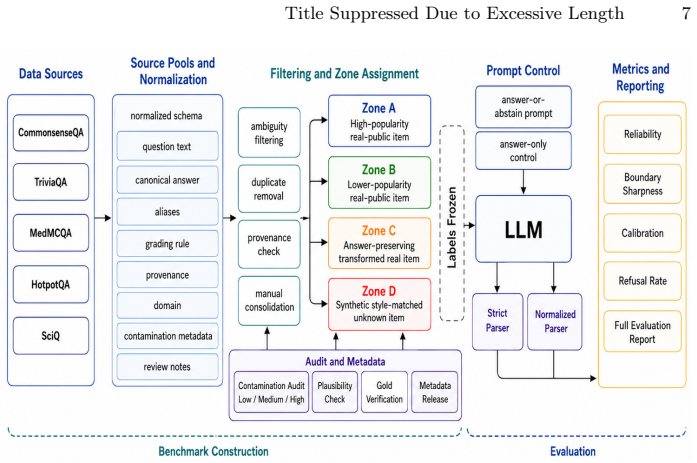
The benchmark provides a reproducible protocol for auditing answerability, abstention, refusal, and contamination as distinct but interacting dimensions of LLM reliability, achieved through multi-zone assignments, explicit abstention expectations, and contamination-risk metadata under locked prompts.
What carries the argument
The contamination-aware multi-zone benchmark with frozen build-time labels, explicit abstention expectations, and dual parsing (strict and normalized robustness parsers).
If this is right
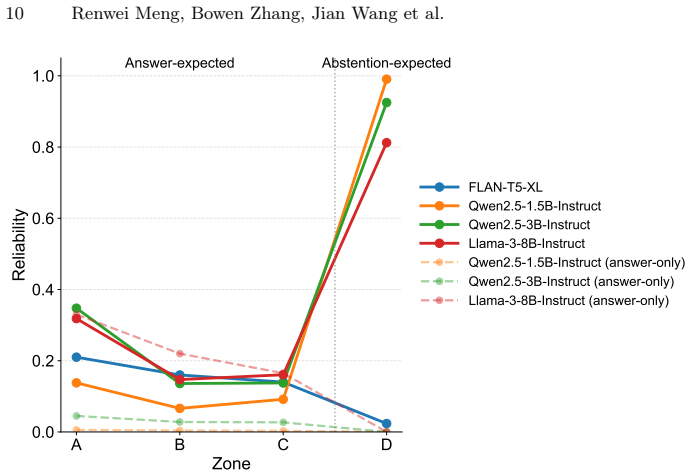
- FLAN baselines remain weak on productive abstention while stronger models show selective but incomplete transition to abstaining.
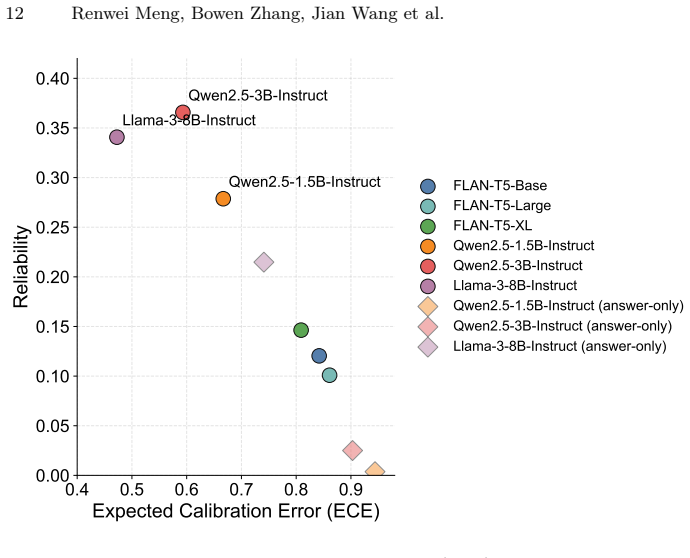
- Qwen2.5-3B-Instruct achieves the best overall reliability among tested models.
- Answer-expected zones remain difficult and calibration remains poor across models.
- Benign-item refusal persists even in stronger models.
- Prompt and parser robustness analyses preserve the main ranking and qualitative conclusions.
Where Pith is reading between the lines
- Developers could use the contamination metadata to filter evaluation sets for cleaner model comparisons.
- The dual parser method suggests that robustness checks are necessary for reliable abstention metrics in future benchmarks.
- This framework highlights the need for models that handle knowledge boundaries more consistently across domains.
- Integration with existing refusal benchmarks could create combined reliability scores.
Load-bearing premise
The frozen build-time labels, multi-zone assignments, and contamination-risk metadata correctly identify knowledge boundaries without being confounded by prompt idiosyncrasy or generic refusal behavior.
What would settle it
If re-running the evaluations with varied prompt templates or different parsers significantly alters the model rankings or the distinction between zones, the benchmark's ability to isolate these dimensions would be challenged.
Figures
read the original abstract
Reliable evaluation of large language models should separate supported answering from unsupported guessing without conflating either with data contamination, prompt idiosyncrasy, or generic refusal behavior. We present a contamination-aware, multi-zone benchmark for measuring the transition from answerable knowledge to abstention-expected unknowns under frozen build-time labels. The benchmark contains 1,200 items across five domains, explicit abstention expectations, contamination-risk metadata, and dual parsing with an official strict parser plus a normalized robustness parser. We evaluate FLAN-T5, Qwen2.5-Instruct, and Llama-3-Instruct models under locked answer-or-abstain prompts, answer-only controls, and prompt-template variants. The benchmark is not solved by generic non-answer behavior: FLAN baselines remain weak on productive abstention, while stronger instruction-tuned models expose a selective but incomplete transition from answering to abstaining. Qwen2.5-3B-Instruct achieves the best overall reliability, but answer-expected zones remain difficult, calibration remains poor, and benign-item refusal persists. Prompt and parser robustness analyses preserve the main ranking and qualitative conclusions. The benchmark therefore provides a reproducible protocol for auditing answerability, abstention, refusal, and contamination as distinct but interacting dimensions of LLM reliability.The dataset is publicly available at https://github.com/renweimeng/Know2Guess-A-Contamination-Aware-Multi-Zone-Benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Know2Guess, a contamination-aware multi-zone benchmark with 1,200 items across five domains, frozen build-time labels, explicit abstention expectations, and contamination-risk metadata. It evaluates FLAN-T5, Qwen2.5-Instruct, and Llama-3-Instruct models under locked answer-or-abstain prompts, answer-only controls, and prompt variants, using dual parsers (strict and normalized). Results indicate Qwen2.5-3B-Instruct achieves the best overall reliability, but answer-expected zones remain difficult, calibration is poor, and benign refusal persists; prompt and parser robustness preserve main rankings and conclusions. The work claims to deliver a reproducible protocol for auditing answerability, abstention, refusal, and contamination as distinct dimensions, with the dataset released publicly at the cited GitHub repository.
Significance. If the zone assignments and labels hold, the benchmark would provide a useful addition to LLM evaluation by attempting to disentangle supported knowledge from guessing, refusal, and contamination effects in a structured, multi-zone setup. The public data release and reported robustness checks to prompt/parser variants are concrete strengths that could support community use for reliability auditing.
major comments (2)
- [Abstract] Abstract: The central claim that the benchmark provides a reproducible protocol separating answerability, abstention, refusal, and contamination rests on the frozen build-time labels and multi-zone assignments correctly demarcating knowledge boundaries. However, no description of the label-generation process, inter-annotator agreement, or external validation against held-out sources is provided, leaving open the possibility that zone assignments are confounded by annotation choices or unmodeled training overlap as raised in the stress-test note.
- [Abstract] Abstract (evaluation results): The reported model performances, qualitative findings on selective abstention, and claims about benchmark validity are presented without error bars, statistical tests, full exclusion criteria, or detailed methods, which directly limits verification of the support for the reliability-auditing protocol.
minor comments (1)
- [Abstract] The abstract is information-dense; separating the benchmark-construction details from the model-evaluation results into distinct paragraphs would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional methodological detail would strengthen the manuscript. We address each point below and will revise accordingly to improve clarity and verifiability of the Know2Guess benchmark.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the benchmark provides a reproducible protocol separating answerability, abstention, refusal, and contamination rests on the frozen build-time labels and multi-zone assignments correctly demarcating knowledge boundaries. However, no description of the label-generation process, inter-annotator agreement, or external validation against held-out sources is provided, leaving open the possibility that zone assignments are confounded by annotation choices or unmodeled training overlap as raised in the stress-test note.
Authors: We agree that the current manuscript lacks sufficient detail on label generation. The zones were assigned via a build-time process combining domain-expert curation with automated contamination-risk flagging to create the five-zone structure, but this was not described. In the revised manuscript we will add a dedicated Methods subsection specifying the exact assignment criteria per domain, annotator involvement (including any agreement metrics), and how contamination metadata was used to reduce overlap risks. We will also expand the limitations section to discuss the absence of post-build external validation against held-out sources and the implications for potential annotation confounding. revision: yes
-
Referee: [Abstract] Abstract (evaluation results): The reported model performances, qualitative findings on selective abstention, and claims about benchmark validity are presented without error bars, statistical tests, full exclusion criteria, or detailed methods, which directly limits verification of the support for the reliability-auditing protocol.
Authors: We concur that the results presentation would benefit from greater statistical transparency. While the experiments used fixed prompt templates and dual parsers, variability measures and formal tests were not included. In the revision we will add error bars (standard deviation across prompt variants), report statistical tests (e.g., McNemar or Wilcoxon where appropriate) for model comparisons, provide the complete item exclusion criteria, and expand the evaluation methods with precise protocol steps, parser pseudocode, and exclusion logic. These additions will directly support the claims regarding the benchmark's utility for reliability auditing. revision: yes
Circularity Check
No circularity: benchmark construction and evaluations are independent
full rationale
The paper introduces a multi-zone benchmark with frozen build-time labels, abstention expectations, and contamination metadata, then reports empirical evaluations on specific models under controlled prompts. No equations, fitted parameters, or predictions are present that reduce to inputs by construction. No self-citations appear in the abstract or described claims, and the central protocol claim rests on the benchmark's design and observed model behaviors rather than any self-referential loop or renamed known result. The derivation chain is self-contained as an empirical auditing tool.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Instruction-Finetuned Language Models
Chung, H.W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., et al.: Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416 (2022),https://arxiv.org/abs/2210.11416
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
arXiv preprint arXiv:2402.15938 (2024),https://arxiv.org/abs/2402
Dong, Y., Jiang, X., Liu, H., Jin, Z., Gu, B., Yang, M., Li, G.: Generalization or memorization: Data contamination and trustworthy evaluation for large language models. arXiv preprint arXiv:2402.15938 (2024),https://arxiv.org/abs/2402. 15938 14 Renwei Meng, Bowen Zhang, Jian Wang et al
-
[3]
Gebru, T., Morgenstern, J., Vecchione, B., Wortman Vaughan, J., Wallach, H., DauméIII,H.,Crawford,K.:Datasheetsfordatasets.CommunicationsoftheACM 64(12), 86–92 (2021).https://doi.org/10.1145/3458723,https://arxiv.org/ abs/1803.09010
-
[4]
In: Proceedings of the 36th International Conference on Ma- chine Learning
Geifman, Y., El-Yaniv, R.: Selectivenet: A deep neural network with an inte- grated reject option. In: Proceedings of the 36th International Conference on Ma- chine Learning. Proceedings of Machine Learning Research, vol. 97, pp. 2151–2159. PMLR (2019),https://proceedings.mlr.press/v97/geifman19a.html
2019
-
[5]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024),https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
In: Proceedings of the 34th International Conference on Machine Learn- ing
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: Proceedings of the 34th International Conference on Machine Learn- ing. Proceedings of Machine Learning Research, vol. 70, pp. 1321–1330. PMLR (2017),https://proceedings.mlr.press/v70/guo17a.html
2017
-
[7]
Joshi, M., Choi, E., Weld, D.S., Zettlemoyer, L.: Triviaqa: A large scale dis- tantly supervised challenge dataset for reading comprehension. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1601–1611. Association for Computational Lin- guistics, Vancouver, Canada (2017).https://doi.o...
-
[8]
Language Models (Mostly) Know What They Know
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al.: Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221 (2022),https: //arxiv.org/abs/2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Li, J., Cheng, X., Zhao, X., Nie, J.Y., Wen, J.R.: Halueval: A large-scale hal- lucination evaluation benchmark for large language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 6449–6464. Association for Computational Linguistics, Singapore (2023). https://doi.org/10.18653/v1/2023.emnlp-main.397,ht...
-
[10]
In: Pro- ceedings of the AAAIConference on Artificial Intelligence.vol
Li, Y., Guerin, F., Lin, C.: Latesteval: Addressing data contamination in language model evaluation through dynamic and time-sensitive test construction. In: Pro- ceedings of the AAAIConference on Artificial Intelligence.vol. 38, pp. 18600–18607 (2024).https://doi.org/10.1609/aaai.v38i17.29822,https://ojs.aaai.org/ index.php/AAAI/article/view/29822
-
[11]
Li, Y., Guo, Y., Guerin, F., Lin, C.: An open-source data contamination report for large language models. In: Findings of the Association for Computational Linguis- tics:EMNLP2024.pp.528–541.AssociationforComputationalLinguistics,Miami, Florida, USA (2024).https://doi.org/10.18653/v1/2024.findings-emnlp.30, https://aclanthology.org/2024.findings-emnlp.30/
-
[12]
Holistic Evaluation of Language Models
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., et al.: Holistic evaluation of language models. arXiv preprint arXiv:2211.09110 (2022),https://arxiv.org/abs/2211.09110
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
In: Proceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers)
Lin, S., Hilton, J., Evans, O.: Truthfulqa: Measuring how models mimic human falsehoods. In: Proceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers). pp. 3214–3252. Association for Computational Linguistics, Dublin, Ireland (2022).https://doi.org/10.18653/ v1/2022.acl-long.229,https://aclanthology....
2022
-
[14]
In: Proceedings of the Conference on Health, Inference, and Learning
Pal, A., Umapathi, L.K., Sankarasubbu, M.: Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In: Proceedings of the Conference on Health, Inference, and Learning. Proceedings of Machine Learning Research, vol. 174, pp. 248–260. PMLR (2022),https://arxiv.org/abs/2203. 14371
2022
-
[15]
In: Proceedings of the 1st Workshop on Data Contamination (CONDA)
Palavalli, M., Bertsch, A., Gormley, M.: A taxonomy for data contamina- tion in large language models. In: Proceedings of the 1st Workshop on Data Contamination (CONDA). pp. 22–40. Association for Computational Linguis- tics, Bangkok, Thailand (2024).https://doi.org/10.18653/v1/2024.conda-1.3, https://aclanthology.org/2024.conda-1.3/
-
[16]
Qwen Team, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., et al.: Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2025),https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Talmor, A., Herzig, J., Lourie, N., Berant, J.: Commonsenseqa: A question an- swering challenge targeting commonsense knowledge. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 4149–4158. Association for Computational L...
-
[18]
In: Proceedings of the 7th Workshop on Representation Learn- ing for NLP
Varshney, N., Mishra, S., Baral, C.: Towards improving selective prediction ability of NLP systems. In: Proceedings of the 7th Workshop on Representation Learn- ing for NLP. pp. 221–226. Association for Computational Linguistics, Dublin, Ireland (2022).https://doi.org/10.18653/v1/2022.repl4nlp-1.23,https:// aclanthology.org/2022.repl4nlp-1.23/
-
[19]
Vu, T., Iyyer, M., Wang, X., Constant, N., Wei, J., Wei, J., Tar, C., Sung, Y.H., Zhou, D., Le, Q., Luong, T.: Freshllms: Refreshing large language models with searchengineaugmentation.In:FindingsoftheAssociationforComputationalLin- guistics: ACL 2024. pp. 13697–13720. Association for Computational Linguistics, Bangkok, Thailand (2024).https://doi.org/10....
-
[20]
Crowdsourcing Multiple Choice Science Questions
Welbl, J., Liu, N.F., Gardner, M.: Crowdsourcing multiple choice science questions. In: Proceedings of the 3rd Workshop on Noisy User-generated Text. pp. 94–106. Association for Computational Linguistics, Copenhagen, Denmark (2017).https: //doi.org/10.18653/v1/W17-4413,https://arxiv.org/abs/1707.06209
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/w17-4413 2017
-
[21]
Wen, B., Yao, J., Feng, S., Xu, C., Tsvetkov, Y., Howe, B., Wang, L.L.: Know your limits: A survey of abstention in large language models. Transactions of the Association for Computational Linguistics13, 529–556 (2025).https://doi.org/ 10.1162/tacl_a_00754,https://aclanthology.org/2025.tacl-1.26/
-
[22]
In: Proceedings of the 2018 Conference on Empirical Methods in Natu- ral Language Processing
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W.W., Salakhutdinov, R., Man- ning, C.D.: Hotpotqa: A dataset for diverse, explainable multi-hop question an- swering. In: Proceedings of the 2018 Conference on Empirical Methods in Natu- ral Language Processing. pp. 2369–2380. Association for Computational Linguis- tics, Brussels, Belgium (2018).https://doi...
-
[23]
Yin,X.,Zhang,X.,Ruan,J.,Wan,X.:Benchmarkingknowledgeboundaryforlarge language models: A different perspective on model evaluation. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers). pp. 2270–2286. Association for Computational Linguistics, 16 Renwei Meng, Bowen Zhang, Jian Wang et al. Ban...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.