EditCaption: Human-Refined SFT and HAE-DPO for Image Editing Instruction Synthesis
Pith reviewed 2026-05-10 17:18 UTC · model grok-4.3
The pith
A two-stage SFT and DPO pipeline aligns vision-language models to cut critical errors in image editing instructions from 47% to 23%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
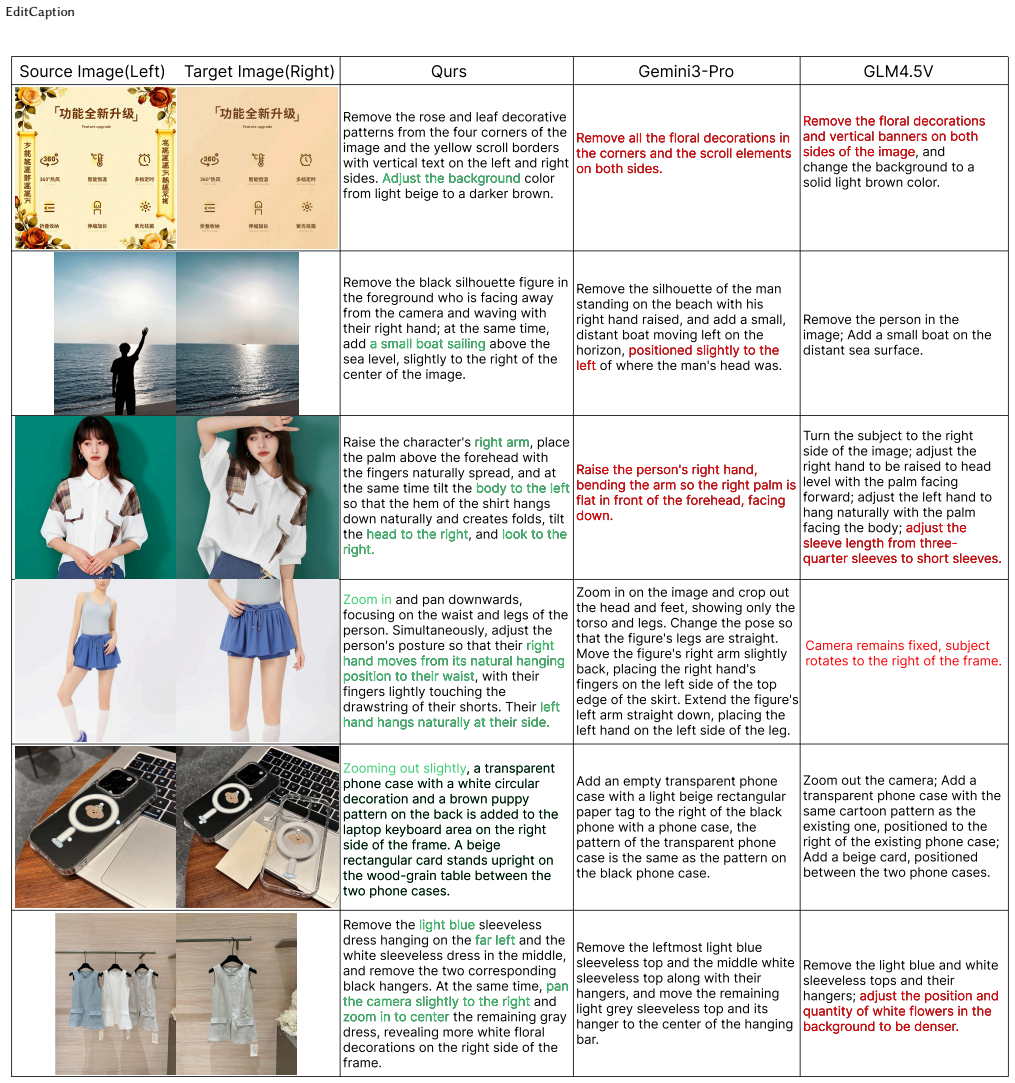
The central claim is that supervised fine-tuning on a 100K human-refined dataset followed by direct preference optimization on 10K targeted preference pairs produces editing instructions whose quality exceeds that of strong baseline VLMs. The resulting fine-tuned Qwen3-VL models reach 4.712 on Eval-400 and 4.588 on ByteMorph-Bench, matching or surpassing Gemini-3-Pro and GPT-4.1, while human raters record critical errors dropping from 47.75% to 23% and correctness rising from 41.75% to 66%.
What carries the argument
EditCaption, a two-stage post-training pipeline that first performs supervised fine-tuning on GLM-annotated and human-refined image-pair instructions, then applies direct preference optimization on human preference pairs explicitly collected for orientation, viewpoint, and attribute errors.
If this is right
- Fine-tuned Qwen3-VL models outperform open-source baselines on Eval-400, ByteMorph-Bench, and HQ-Edit.
- The 235B model reaches benchmark scores comparable to or higher than Gemini-3-Pro and GPT-4.1.
- Human evaluation shows critical errors halved and instruction correctness increased by more than 50%.
- The pipeline offers a repeatable method to generate large volumes of human-aligned editing data without full manual annotation.
Where Pith is reading between the lines
- The same diagnosis-and-target approach could reduce analogous spatial or attribute errors when synthesizing instructions for video or 3D editing tasks.
- Collecting preference data only after identifying concrete failure modes may be more data-efficient than generic alignment methods for creative generation.
- Widespread adoption would lower the barrier for open models to serve as reliable data generators for instruction-tuned editing systems.
Load-bearing premise
The three identified failure modes are the dominant sources of unusable instructions and the collected human preference data faithfully captures them without introducing new selection biases.
What would settle it
A controlled experiment that trains identical image-editing models on instructions produced by the fine-tuned VLM versus instructions from an unaligned baseline and measures downstream editing success rate or user preference scores.
Figures



read the original abstract
High-quality source-target image pairs with precise editing instructions are essential for instruction-guided image editing, yet constructing such training triplets at scale remains costly. Recent pipelines often rely on vision-language models to synthesize editing instructions automatically, but we find that strong VLMs still struggle to describe visual transformations between image pairs. In particular, they exhibit three recurring failure modes: orientation inconsistency, viewpoint ambiguity, and missing fine-grained attributes. In a human evaluation on 400 image pairs, several open-source VLM baselines produce critical-error rates above 47\%, making many synthesized instructions unsuitable for downstream training. To address this, we propose EditCaption, a two-stage post-training pipeline for image editing instruction synthesis. First, we construct a 100K supervised fine-tuning dataset through GLM-based auto-captioning, EditScore filtering, and human refinement. Second, we collect 10K human-annotated preference pairs, where each rejected instruction is labeled with its primary error type and severity. Based on this dataset, we propose Hardness-Adaptive Error-Aware DPO (HAE-DPO), a task-adapted DPO objective that introduces an adaptive margin based on human-labeled severity, failure-mode type, and reference-model hardness. Experiments across three benchmarks demonstrate that our 235B model with SFT+HAE-DPO achieves state-of-the-art performance among open-source and closed models, scoring 4.720 on Eval-400, 4.672 on HQ-Edit, and 4.651 on ByteMorph-Bench -- surpassing Gemini-3-Pro on all three. Human evaluation confirms critical error rates drop from 47.75\% to 17.50\%, with correct rates improving from 41.75\% to 70.25\%, surpassing Gemini-3-Pro (66.00\%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs exhibit three systematic failure modes when synthesizing image editing instructions (orientation inconsistency, viewpoint ambiguity, and insufficient fine-grained attribute description), with over 47% of outputs containing critical errors. It introduces EditCaption, a two-stage pipeline: (1) construction of a 100K SFT dataset via GLM annotation, EditScore filtering, and human refinement; (2) collection of 10K human preference pairs targeting the failure modes followed by DPO. Fine-tuned Qwen3-VL models (particularly the 235B variant) outperform open-source baselines and are competitive with closed models on Eval-400 (4.712), ByteMorph-Bench (4.588), and HQ-Edit, while human evaluation shows critical errors dropping from 47.75% to 23% and correctness rising from 41.75% to 66%.
Significance. If the results hold, the work provides a practical, scalable approach to generating human-aligned training data for instruction-guided image editing, addressing a recognized bottleneck. Concrete benchmark scores and human error-rate reductions are reported, and the two-stage SFT+DPO pipeline is a clear methodological contribution that could be adopted by others working on VLM post-training for vision tasks.
major comments (2)
- Stage 2 (human preference data collection for DPO): The manuscript states that the 10K pairs 'target the three failure modes' but reports no inter-annotator agreement, no breakdown of pairs by failure mode, and no analysis or controls for annotator biases, selection artifacts, or inconsistent criteria. Because DPO directly optimizes on these pairs, the absence of such validation is load-bearing for the central claim that the pipeline produces instructions with substantially fewer critical errors (47.75% to 23%).
- Evaluation section (benchmark and human results): The 235B model reports 4.712 on Eval-400 versus Gemini-3-Pro at 4.706 and 4.588 on ByteMorph-Bench versus 4.522; these margins are small, yet no standard deviations, number of evaluation runs, statistical significance tests, or exact data splits are provided. This makes it difficult to assess whether the reported gains are robust or could be affected by post-hoc choices.
minor comments (2)
- Abstract and introduction: The human evaluation protocol (number of annotators, exact scoring rubric, image sampling method) is not summarized, which would help readers interpret the 47.75% to 23% error reduction.
- Related work: No explicit comparison is drawn to prior DPO applications in vision-language tasks (e.g., for captioning or VQA), which would clarify the novelty of applying it specifically to editing-instruction synthesis.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work. We address each of the major comments in detail below.
read point-by-point responses
-
Referee: Stage 2 (human preference data collection for DPO): The manuscript states that the 10K pairs 'target the three failure modes' but reports no inter-annotator agreement, no breakdown of pairs by failure mode, and no analysis or controls for annotator biases, selection artifacts, or inconsistent criteria. Because DPO directly optimizes on these pairs, the absence of such validation is load-bearing for the central claim that the pipeline produces instructions with substantially fewer critical errors (47.75% to 23%).
Authors: We agree that documenting the quality and composition of the preference dataset is crucial for substantiating the DPO improvements. In the revised manuscript, we will provide inter-annotator agreement statistics, a breakdown of the 10K pairs according to the three failure modes, and an analysis of our annotation process including measures to control for biases and ensure consistent criteria. These additions will directly support the validity of the reported error reductions. revision: yes
-
Referee: Evaluation section (benchmark and human results): The 235B model reports 4.712 on Eval-400 versus Gemini-3-Pro at 4.706 and 4.588 on ByteMorph-Bench versus 4.522; these margins are small, yet no standard deviations, number of evaluation runs, statistical significance tests, or exact data splits are provided. This makes it difficult to assess whether the reported gains are robust or could be affected by post-hoc choices.
Authors: We acknowledge the need for more rigorous statistical reporting to contextualize the benchmark results. We will revise the evaluation section to include standard deviations computed over multiple runs, the number of evaluation runs performed, results of statistical significance tests, and precise descriptions of the data splits. Although the numerical margins on the automatic metrics are modest, the human evaluation demonstrates a substantial and consistent improvement in instruction quality, which we believe strengthens the overall conclusions. revision: yes
Circularity Check
No circularity: empirical pipeline evaluated on independent benchmarks
full rationale
The paper describes a two-stage empirical pipeline (SFT on 100K dataset followed by DPO on 10K human preference pairs) without any mathematical derivations, equations, or self-definitional reductions. Performance is measured on separate external benchmarks (Eval-400, ByteMorph-Bench, HQ-Edit) and fresh human evaluations that are independent of the training data. No load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work appear in the text. The central claims rest on standard supervised and preference optimization steps whose outputs are validated externally rather than by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human annotators can consistently identify and correct orientation, viewpoint, and attribute-level errors in image editing instructions
- domain assumption SFT followed by DPO on VLM outputs will generalize beyond the collected preference data to new image pairs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage post-training pipeline... 100K supervised fine-tuning (SFT) dataset... 10K human preference pairs... Direct Preference Optimization (DPO)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
orientation inconsistency, viewpoint ambiguity, and insufficient fine-grained attribute description
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.