DenseSteer: Steering Small Language Models towards Dense Math Reasoning
Pith reviewed 2026-06-29 07:43 UTC · model grok-4.3
The pith
Steering small models toward dense reasoning raises math accuracy without raising uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
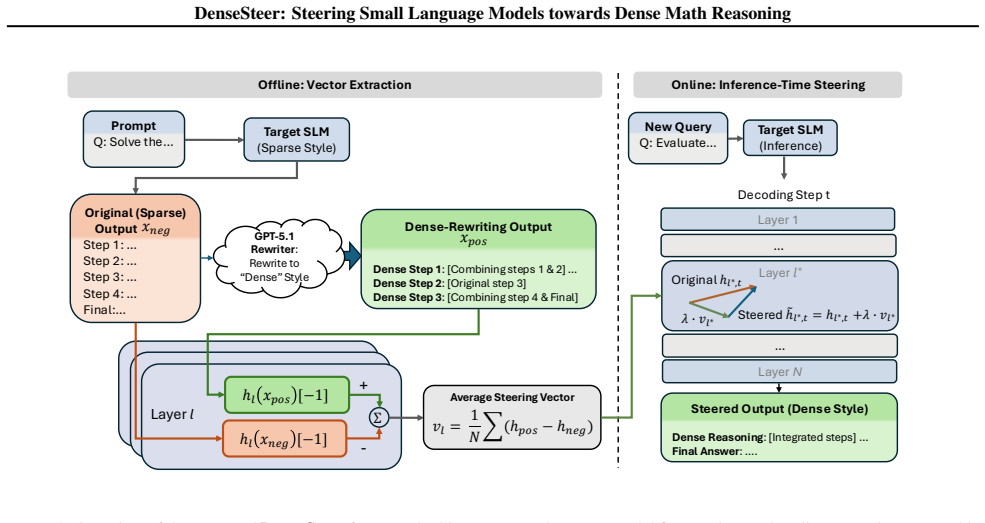
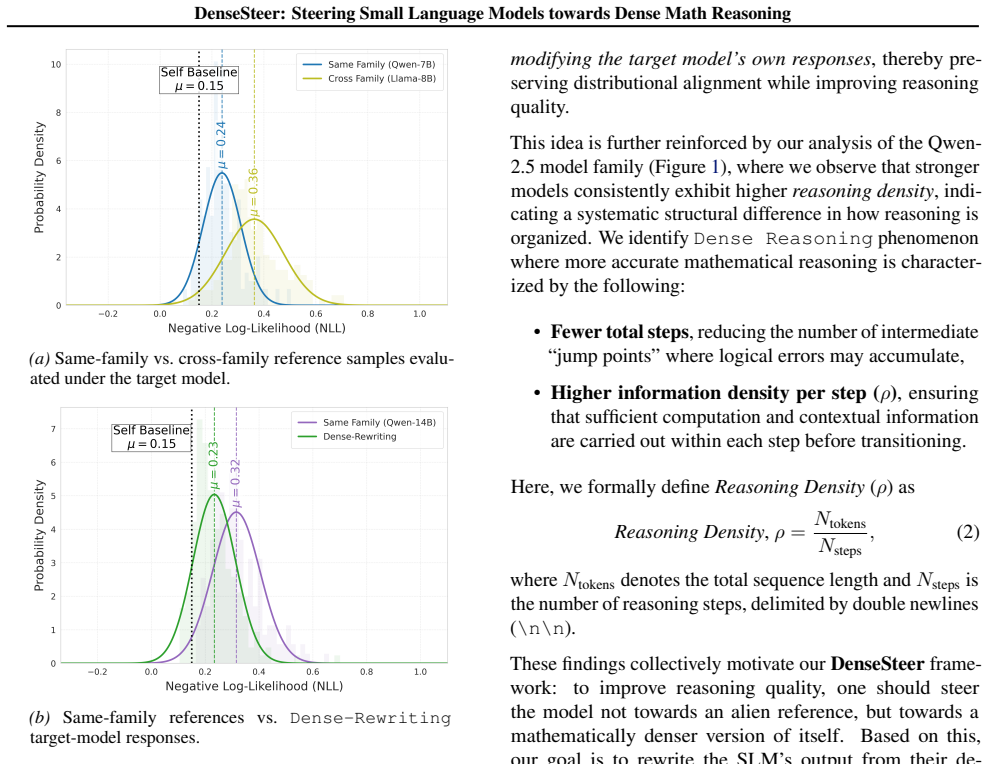
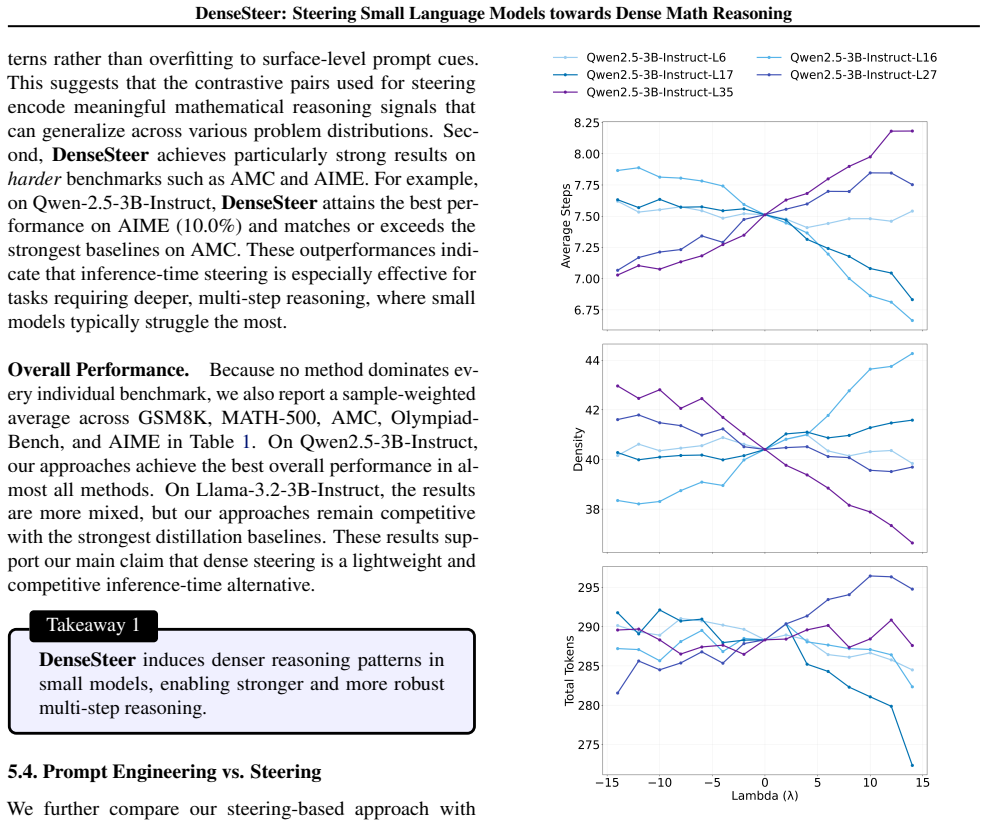
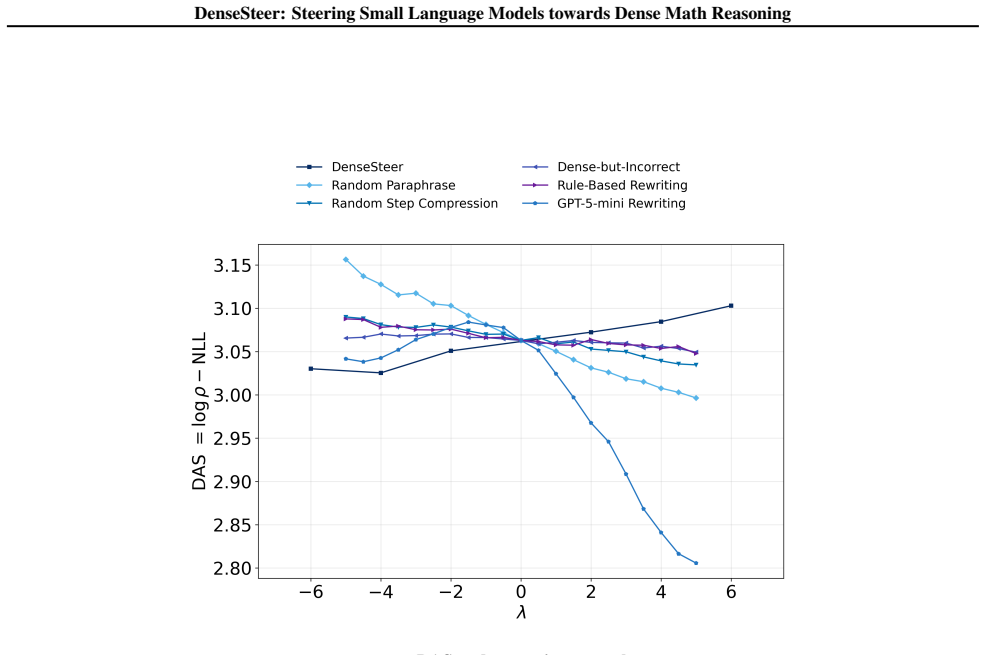
Analyses of the Qwen-2.5 family show that proficient reasoning correlates with fewer reasoning steps but higher information density per step. DenseSteer uses this observation to modulate internal representations of small models toward dense reasoning patterns during inference, producing consistent accuracy gains on mathematical problem-solving benchmarks without increasing token-level negative log-likelihood.
What carries the argument
DenseSteer, a training-free inference-time steering framework that modulates internal representations toward dense reasoning patterns.
If this is right
- Small models (<=3B) achieve higher accuracy on multi-step math tasks.
- Reasoning improvements occur without extra training or higher token uncertainty.
- Dense reasoning functions as a controllable structural property rather than an emergent effect of scale alone.
- The method transfers the observed step-density pattern across different small models.
Where Pith is reading between the lines
- The same modulation approach might transfer to non-mathematical reasoning domains that also rely on step-wise generation.
- If dense reasoning can be induced this way, combining it with other inference-time controls could further narrow the performance gap between small and large models.
- Testing whether the accuracy gains persist when the target pattern is taken from models outside the original family would clarify how general the density signal is.
Load-bearing premise
The correlation between fewer steps and higher per-step density observed in one model family can be induced in other small models by adjusting their internal states at inference time.
What would settle it
Applying DenseSteer to a small model on math benchmarks and finding neither an accuracy increase nor stable negative log-likelihood would falsify the central claim.
Figures




read the original abstract
Large language models (LLMs) demonstrate strong chain-of-thought (CoT) reasoning abilities, while smaller models (<= 3B parameters) significantly underperform on multi-step reasoning tasks. Based on empirical analyses of the Qwen-2.5 model family on math reasoning benchmarks, we find that more proficient reasoning is associated with fewer reasoning steps but higher information density per step, a property we term Dense Reasoning. Motivated by this observation, we propose DenseSteer, a training-free inference-time steering framework that enhances small-model reasoning by modulating internal representations toward dense reasoning patterns. Experiments show that our method yields consistent accuracy improvements without increasing token-level Negative Log-Likelihood, highlighting dense reasoning as an effective structural approach to mathematical problem solving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DenseSteer, a training-free inference-time steering framework that modulates internal representations in small language models (≤3B parameters) to induce 'dense reasoning' patterns—fewer reasoning steps with higher per-step information density—observed empirically in the Qwen-2.5 family on math benchmarks. It claims this yields consistent accuracy gains without increasing token-level negative log-likelihood.
Significance. If the claimed results hold with proper controls, the work would provide evidence that structural properties of reasoning (information density) can be induced via representation steering at inference time, offering a lightweight, training-free route to improve small-model math performance. The absence of NLL degradation would be a notable practical advantage.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent accuracy improvements' is stated without any description of the small models tested, the math benchmarks used, baselines, number of runs, statistical significance, or implementation details of the steering mechanism, leaving the empirical result unsupported by visible evidence.
- [Abstract] Abstract: the transfer assumption—that dense-reasoning patterns observed in Qwen-2.5 can be induced in other small models via internal representation modulation—is presented without ablations, controls for the steering vectors, or verification that the modulation actually produces fewer steps/higher density in the target models.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific small models and benchmarks to allow readers to assess the scope of the claimed gains.
Simulated Author's Rebuttal
We thank the referee for their detailed feedback on the abstract of our manuscript. We will revise the abstract to better support our claims with key experimental details. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent accuracy improvements' is stated without any description of the small models tested, the math benchmarks used, baselines, number of runs, statistical significance, or implementation details of the steering mechanism, leaving the empirical result unsupported by visible evidence.
Authors: The abstract is intended as a high-level summary, with full details provided in the body of the paper, including the specific models (≤3B parameters), benchmarks, and the steering approach in Section 3. Nevertheless, we agree that including more specifics in the abstract would strengthen it. We will revise the abstract to mention the models tested, the benchmarks, that results are consistent across multiple runs, and briefly note the steering mechanism. revision: yes
-
Referee: [Abstract] Abstract: the transfer assumption—that dense-reasoning patterns observed in Qwen-2.5 can be induced in other small models via internal representation modulation—is presented without ablations, controls for the steering vectors, or verification that the modulation actually produces fewer steps/higher density in the target models.
Authors: The empirical results in the manuscript demonstrate accuracy gains on target models when applying the steering derived from Qwen-2.5 patterns, supporting the transfer. Controls for the steering are implicit in the comparison to baselines. However, we recognize that explicit ablations and direct verification of reduced step count and increased density in the target models' outputs are not detailed in the current version. We will add such verification in the revised manuscript to more rigorously support the transfer assumption. revision: partial
Circularity Check
No significant circularity
full rationale
The provided abstract and description contain no equations, fitted parameters, predictions, or self-citations. The method is explicitly training-free and observation-driven from external Qwen-2.5 analyses, with the central claim resting on empirical accuracy improvements rather than any derivation that reduces to its own inputs by construction. This is the expected self-contained case.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Closing the Prior-Posterior Loop: Self-Reflective Molecular Design with Analysis-Driven LLM Iteration
LLM molecular design framework uses self-reflection on full physicochemical data from first-principles calculations to achieve low deviation on HOMO-LUMO gaps and generalize to other properties.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
Language Models are Few-Shot Learners
URL https:// arxiv.org/abs/2005.14165. Chen, R., Zhang, Z., Hong, J., Kundu, S., and Wang, Z. Seal: Steerable reasoning calibration of large language models for free.arXiv preprint arXiv:2504.07986, 2025a. Chen, X., Zhou, S., Liang, K., Sun, X., and Liu, X. Skip- thinking: Chunk-wise chain-of-thought distillation en- able smaller language models to reason...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[4]
URL https: //arxiv.org/abs/2412.19437. Gu, Y ., Dong, L., Wei, F., and Huang, M. Minillm: Knowl- edge distillation of large language models. InInterna- tional Conference on Learning Representations, volume 2024, pp. 32694–32717,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
URL https://arxiv.org/abs/2402.14008. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring mas- sive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[6]
Measuring Mathematical Problem Solving With the MATH Dataset
URLhttps://arxiv.org/abs/2103.03874. Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Distilling the Knowledge in a Neural Network
URL https: //arxiv.org/abs/1503.02531. Højer, B., Jarvis, O., and Heinrich, S. Improving reasoning performance in large language models via representation engineering.arXiv preprint arXiv:2504.19483,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Y ., Ra- masubramanian, B., and Poovendran, R
Li, Y ., Yue, X., Xu, Z., Jiang, F., Niu, L., Lin, B. Y ., Ra- masubramanian, B., and Poovendran, R. Small models struggle to learn from strong reasoners.arXiv preprint arXiv:2502.12143,
-
[9]
Liu, J., Cui, L., Liu, H., Huang, D., Wang, Y ., and Zhang, Y . Logiqa: A challenge dataset for machine reading comprehension with logical reasoning.arXiv preprint arXiv:2007.08124,
-
[10]
Steering Llama 2 via Contrastive Activation Addition
URL https: //arxiv.org/abs/2312.06681. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URL https://arxiv.org/abs/2402.03300. Son, W., Na, J., Choi, J., and Hwang, W. Densely guided knowledge distillation using multiple teacher as- sistants,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y ., Chung, H
URL https://arxiv.org/abs/ 2009.08825. Suzgun, M., Scales, N., Schärli, N., Gehrmann, S., Tay, Y ., Chung, H. W., Chowdhery, A., Le, Q., Chi, E., Zhou, D., et al. Challenging big-bench tasks and whether chain-of- thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 13003–13051,
-
[13]
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G
URL https: //transformer-circuits.pub/2024/ scaling-monosemanticity/index.html. Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. Llama: Open and efficient foundation lan- guage models,
2024
-
[14]
LLaMA: Open and Efficient Foundation Language Models
URL https://arxiv.org/ abs/2302.13971. Turner, A. M., Thiergart, L., Leech, G., Udell, D., Vazquez, J. J., Mini, U., and MacDiarmid, M. Steering language 10 DenseSteer: Steering Small Language Models towards Dense Math Reasoning models with activation engineering,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Steering Language Models With Activation Engineering
URL https: //arxiv.org/abs/2308.10248. Wang, Z., Wang, Y ., Zhang, Z., Zhou, Z., Jin, H., Hu, T., Sun, J., Li, Z., Zhang, Y ., and Xu, Z.-Q. J. Un- derstanding the language model to solve the symbolic multi-step reasoning problem from the perspective of buffer mechanism,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https://arxiv. org/abs/2405.15302. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. arXiv:2201.11903,
-
[17]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
URL https://arxiv.org/abs/ 2201.11903. Xu, H., Peng, B., Awadalla, H., Chen, D., Chen, Y .-C., Gao, M., Kim, Y . J., Li, Y ., Ren, L., Shen, Y ., Wang, S., Xu, W., Gao, J., and Chen, W. Phi-4-mini-reasoning: Exploring the limits of small reasoning language models in math.arXiv preprint arXiv:2504.21233,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
URL https://arxiv.org/abs/2504.21233. Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., Lu, K., Xue, M., Lin, R., Liu, T., Ren, X., and Zhang, Z. Qwen2.5-math techni- cal report: Toward mathematical expert model via self- improvement,
-
[19]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
URL https://arxiv.org/ abs/2409.12122. Yang, Y ., Sun, H., Wang, J., Qi, Q., Zhuang, Z., Wang, H., Ren, P., Wang, J., and Liao, J. Unveiling internal reason- ing modes in LLMs: A deep dive into latent reasoning vs. factual shortcuts with attribute rate ratio. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 218...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhutdinov, R., and Manning, C. D. HotpotQA: A dataset for diverse, explainable multi-hop question an- swering. In Riloff, E., Chiang, D., Hockenmaier, J., and Tsujii, J. (eds.),Proceedings of the 2018 Confer- ence on Empirical Methods in Natural Language Pro- cessing, pp. 2369–2380, Brussels, Belgiu...
2018
-
[21]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Association for Computational Lin- guistics. doi: 10.18653/v1/D18-1259. URL https: //aclanthology.org/D18-1259/. Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.-K., Goel, S., Li, N., Byun, M. J., Wang, Z., Mallen, A., Basart, S., Koyejo, S., Song, D., Fredrikson, M., Kolter, J. Z., and Hendrycks, ...
-
[22]
Representation Engineering: A Top-Down Approach to AI Transparency
URL https://arxiv.org/abs/2310.01405. 11 DenseSteer: Steering Small Language Models towards Dense Math Reasoning Appendix A. Prompts details A.1. Baseline: Chain-of-Thought Prompt Normal Chain-of-Thought Prompt Solve the following math problem. Present the final answer in the format: Final Answer: \\boxed{your_answer}.\nProblem: {{problem}}\nAnswer: A.2. ...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.