AGDN: Learning to Solve Traveling Salesman Problem with Anisotropic Graph Diffusion Network
Pith reviewed 2026-06-26 21:27 UTC · model grok-4.3
The pith
AGDN solves TSP more accurately than prior graph networks by diffusing information anisotropically on a similarity-distance matrix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AGDN addresses the lack of informative topological prior in fully connected TSP graphs and the connectivity losses from sparsification by constructing a MixScore transition matrix that merges node similarity with pairwise distance and applying an anisotropic graph diffusion strategy that supports efficient multi-hop information exchange, yielding higher-quality tours.
What carries the argument
MixScore transition matrix merged with anisotropic graph diffusion for multi-hop information exchange that preserves connectivity in TSP graphs.
If this is right
- AGDN produces higher-quality TSP solutions than existing graph-based methods across varied instance sizes and node distributions.
- Running times stay competitive with prior approaches.
- Solution quality holds when tested on problem sizes and distributions outside the training regime.
Where Pith is reading between the lines
- The same diffusion construction could be tested on related routing problems such as the capacitated vehicle routing problem to check for similar gains.
- Avoiding sparsification may allow the approach to scale to denser graphs that arise in other combinatorial tasks.
- The observed generalization hints that the learned features capture scale-invariant properties of TSP that might transfer to real logistics data.
Load-bearing premise
Merging node similarity with pairwise distance into a transition matrix and diffusing anisotropically will supply enough topological information to recover high-quality tours without the connectivity losses from sparsification.
What would settle it
If AGDN produces tour lengths no shorter than a standard graph neural network baseline on TSP instances with 500+ nodes drawn from a distribution absent from training, the claim of consistent outperformance and generalization would be refuted.
Figures

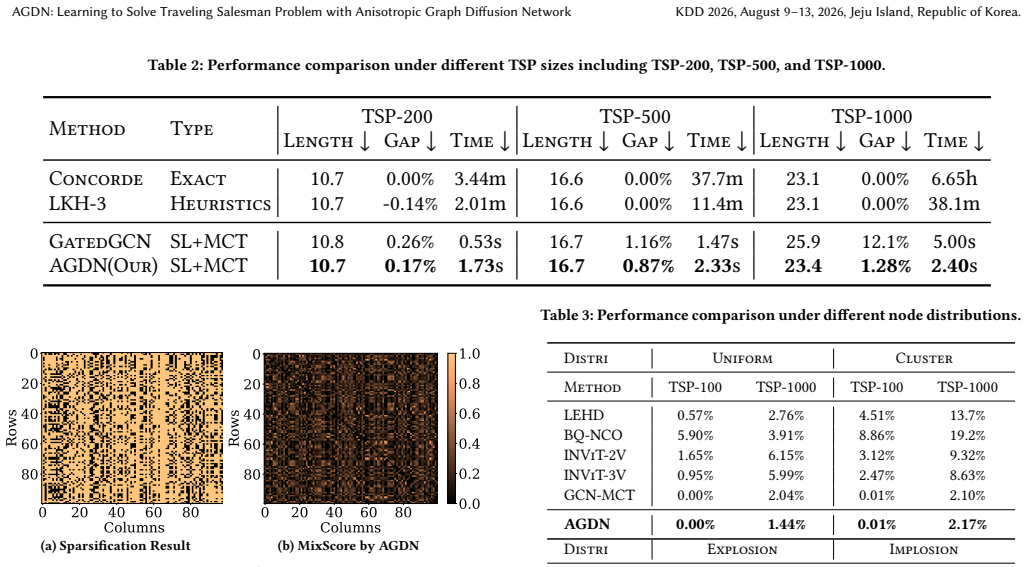
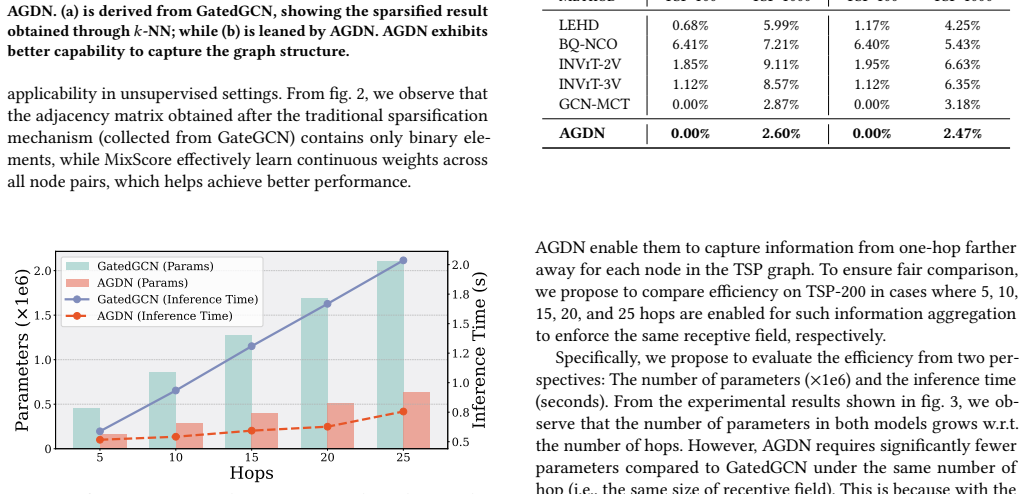
read the original abstract
The Traveling Salesman Problem (TSP) is a cornerstone of combinatorial optimization and arises in many practical scenarios. Although graph-based learning approaches have been explored for TSP, the question of how to exploit graph structure more effectively remains open. We present the Anisotropic Graph Diffusion Network (AGDN), a new Graph Neural Network framework designed to solve TSP. Our method tackles two central difficulties: (1) the lack of informative topological prior in fully connected TSP graphs, and (2) losing connected nodes in the optimal solution after the commonly used graph sparsification techniques. To overcome these issues, we construct a MixScore transition matrix that merges node similarity with pairwise distance, and we develop an anisotropic graph diffusion strategy that supports efficient information exchange across multiple hops. Comprehensive experiments spanning diverse instance sizes and node distributions show that AGDN consistently outperforms existing methods while keeping computation time competitive. Furthermore, AGDN generalizes well to problem sizes and distributions beyond those seen during training. The implementation is publicly available at: https://github.com/LabRAI/AGDN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Anisotropic Graph Diffusion Network (AGDN) for solving the Traveling Salesman Problem. It constructs a MixScore transition matrix that merges node similarity with pairwise distance and develops an anisotropic graph diffusion strategy to address the lack of informative topological priors in fully connected TSP graphs and the connectivity losses from standard sparsification. The authors claim that comprehensive experiments on diverse instance sizes and node distributions demonstrate consistent outperformance over existing methods with competitive computation time, plus strong generalization to unseen problem sizes and distributions. The implementation is publicly released.
Significance. If the performance and generalization claims hold after verification, AGDN would represent a meaningful advance in graph neural network approaches to combinatorial optimization by enabling effective multi-hop information exchange on dense graphs without sparsification-induced losses. The public code release is a clear strength supporting reproducibility.
major comments (2)
- [Introduction and §3] Introduction and §3 (Method): The central claim that the MixScore transition matrix combined with anisotropic graph diffusion supplies sufficient topological information to recover high-quality tours without the connectivity losses typical of sparsification is load-bearing, yet no derivation, connectivity metric (e.g., fraction of optimal edges retained post-diffusion), or ablation isolating the diffusion step's effect on multi-hop signal is provided to substantiate this assumption.
- [§4] §4 (Experiments): The abstract and reader's summary assert outperformance and generalization across instance sizes and distributions, but the provided description contains no quantitative results, error bars, baseline details, dataset descriptions, or statistical significance tests; without these, the empirical claims cannot be evaluated and the generalization statement remains unverified.
minor comments (2)
- [Abstract] Abstract: The summary of results would be strengthened by including at least one key quantitative metric (e.g., optimality gap on a standard benchmark) rather than qualitative statements alone.
- [§3] Notation: The definition of the MixScore transition matrix should be given explicitly with all terms defined at first use to avoid ambiguity in how node similarity is computed and merged with distance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Introduction and §3] Introduction and §3 (Method): The central claim that the MixScore transition matrix combined with anisotropic graph diffusion supplies sufficient topological information to recover high-quality tours without the connectivity losses typical of sparsification is load-bearing, yet no derivation, connectivity metric (e.g., fraction of optimal edges retained post-diffusion), or ablation isolating the diffusion step's effect on multi-hop signal is provided to substantiate this assumption.
Authors: We agree that additional analysis would strengthen the central claim. The current manuscript motivates and describes the MixScore matrix and anisotropic diffusion but does not include a formal derivation, connectivity metric, or dedicated ablation on the diffusion step. We will add a connectivity analysis (including fraction of optimal edges retained) and an ablation isolating the diffusion component to the revised §3. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and reader's summary assert outperformance and generalization across instance sizes and distributions, but the provided description contains no quantitative results, error bars, baseline details, dataset descriptions, or statistical significance tests; without these, the empirical claims cannot be evaluated and the generalization statement remains unverified.
Authors: We acknowledge that the experimental reporting in §4 requires greater detail to support the claims. The manuscript states that comprehensive experiments demonstrate outperformance and generalization, but does not supply the requested quantitative elements. We will expand §4 to include specific performance numbers with error bars, full baseline specifications, dataset descriptions, and statistical significance tests. revision: yes
Circularity Check
No circularity detected; AGDN is a novel construction with independent experimental claims
full rationale
The paper introduces AGDN via an original MixScore transition matrix and anisotropic diffusion strategy to address TSP graph issues. No equations, self-citations, or claims in the abstract reduce the method, its performance, or generalization to quantities fitted from the authors' prior work or by self-definition. The central claims rest on the proposed construction plus external experimental validation across instance sizes, which are not forced by the inputs. This is the common case of a self-contained new method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption TSP instances can be usefully represented as graphs with nodes as cities and edges carrying distances.
invented entities (2)
-
MixScore transition matrix
no independent evidence
-
Anisotropic graph diffusion strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://www.math.uwaterloo.ca/tsp
n.d.. https://www.math.uwaterloo.ca/tsp
-
[2]
Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. 2019. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. Ininternational conference on machine learning. PMLR, 21–29
2019
- [3]
-
[4]
David L Applegate, Robert E Bixby, Vašek Chvátal, William Cook, Daniel G Espinoza, Marcos Goycoolea, and Keld Helsgaun. 2009. Certification of an optimal TSP tour through 85,900 cities.Operations Research Letters37, 1 (2009), 11–15
2009
-
[5]
Gilbert Babin, Stéphanie Deneault, and Gilbert Laporte. 2007. Improvements to the Or-opt heuristic for the symmetric travelling salesman problem.Journal of the Operational Research Society58, 3 (2007), 402–407
2007
-
[6]
Paul I Barton and Constantinos C Pantelides. 1994. Modeling of combined discrete/continuous processes.AIChE journal40, 6 (1994), 966–979
1994
-
[7]
Dominique Beaini, Saro Passaro, Vincent Létourneau, Will Hamilton, Gabriele Corso, and Pietro Liò. 2021. Directional graph networks. InInternational Confer- ence on Machine Learning. PMLR, 748–758
2021
-
[8]
Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samoth- rakis, and Simon Colton. 2012. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games4, 1 (2012), 1–43
2012
- [9]
-
[10]
Ben Chamberlain, James Rowbottom, Maria I Gorinova, Michael Bronstein, Stefan Webb, and Emanuele Rossi. 2021. Grand: Graph neural diffusion. InInternational conference on machine learning. PMLR, 1407–1418
2021
-
[11]
Deli Chen, Yankai Lin, Wei Li, Peng Li, Jie Zhou, and Xu Sun. 2020. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. InProceedings of the AAAI conference on artificial intelligence, Vol. 34. 3438–3445
2020
-
[12]
Jinbiao Chen, Jiahai Wang, Zizhen Zhang, Zhiguang Cao, Te Ye, and Siyuan Chen. 2024. Efficient meta neural heuristic for multi-objective combinatorial optimization.Advances in Neural Information Processing Systems36 (2024)
2024
-
[13]
Zhan Cheng, Bolin Shen, Tianming Sha, Yuan Gao, Shibo Li, and Yushun Dong
-
[14]
InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Atom: A framework of detecting query-based model extraction attacks for graph neural networks. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 322–333
-
[15]
1997.Spectral graph theory
Fan RK Chung. 1997.Spectral graph theory. Vol. 92. American Mathematical Soc
1997
-
[16]
Geoff Clarke and John W Wright. 1964. Scheduling of vehicles from a central depot to a number of delivery points.Operations research12, 4 (1964), 568–581
1964
-
[17]
1989.Heat kernels and spectral theory
Edward Brian Davies. 1989.Heat kernels and spectral theory. Number 92. Cam- bridge university press
1989
-
[18]
Francesco Di Giovanni, Lorenzo Giusti, Federico Barbero, Giulia Luise, Pietro Lio, and Michael M Bronstein. 2023. On over-squashing in message passing neural networks: The impact of width, depth, and topology. InInternational Conference on Machine Learning. PMLR, 7865–7885
2023
-
[19]
Darko Drakulic, Sofia Michel, Florian Mai, Arnaud Sors, and Jean-Marc An- dreoli. 2024. Bq-nco: Bisimulation quotienting for efficient neural combinatorial optimization.Advances in Neural Information Processing Systems36 (2024)
2024
-
[20]
Matthias Englert, Heiko Röglin, and Berthold Vöcking. 2014. Worst case and probabilistic analysis of the 2-Opt algorithm for the TSP.Algorithmica68, 1 (2014), 190–264
2014
-
[21]
2022.Partial differential equations
Lawrence C Evans. 2022.Partial differential equations. Vol. 19. American Mathe- matical Society
2022
- [22]
-
[23]
Zhang-Hua Fu, Kai-Bin Qiu, and Hongyuan Zha. 2021. Generalize a small pre- trained model to arbitrarily large tsp instances. InProceedings of the AAAI con- ference on artificial intelligence, Vol. 35. 7474–7482
2021
- [24]
- [25]
-
[26]
Johannes Gasteiger, Stefan Weißenberger, and Stephan Günnemann. 2019. Diffu- sion improves graph learning.Advances in neural information processing systems 32 (2019)
2019
-
[27]
Jhony H Giraldo, Konstantinos Skianis, Thierry Bouwmans, and Fragkiskos D Malliaros. 2023. On the trade-off between over-smoothing and over-squashing in deep graph neural networks. InProceedings of the 32nd ACM international conference on information and knowledge management. 566–576
2023
-
[28]
Yong Liang Goh, Zhiguang Cao, Yining Ma, Yanfei Dong, Mohammed Haroon Dupty, and Wee Sun Lee. 2024. Hierarchical neural constructive solver for real-world tsp scenarios. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 884–895
2024
-
[29]
2009.Heat kernel and analysis on manifolds
Alexander Grigoryan. 2009.Heat kernel and analysis on manifolds. Vol. 47. Amer- ican Mathematical Soc
2009
-
[30]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
2017
-
[31]
2002.Ordinary differential equations
Philip Hartman. 2002.Ordinary differential equations. SIAM
2002
-
[32]
Keld Helsgaun. 2017. An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems.Roskilde: Roskilde University12 (2017), 966–980
2017
-
[33]
2015.Introduction to operations research
Frederick S Hillier and Gerald J Lieberman. 2015.Introduction to operations research. McGraw-Hill
2015
-
[34]
Ziwei Huang, Jianan Zhou, Zhiguang Cao, and Yixin Xu. 2025. Rethinking light decoder-based solvers for vehicle routing problems. InInternational conference on learning representations
2025
-
[35]
Yan Jin, Yuandong Ding, Xuanhao Pan, Kun He, Li Zhao, Tao Qin, Lei Song, and Jiang Bian. 2023. Pointerformer: Deep reinforced multi-pointer transformer for the traveling salesman problem. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 8132–8140
2023
- [36]
-
[37]
Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Scott Kirkpatrick, C Daniel Gelatt Jr, and Mario P Vecchi. 1983. Optimization by simulated annealing.science220, 4598 (1983), 671–680
1983
-
[39]
Wouter Kool, Herke Van Hoof, and Max Welling. 2018. Attention, learn to solve routing problems!arXiv preprint arXiv:1803.08475(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
2011.Combinatorial opti- mization
Bernhard H Korte, Jens Vygen, B Korte, and J Vygen. 2011.Combinatorial opti- mization. Vol. 1. Springer
2011
-
[41]
Yeong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Yoon, Youngjune Gwon, and Seungjai Min. 2020. Pomo: Policy optimization with multiple optima for KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Bolin Shen, Ziwei Huang, Zhiguang Cao, and Yushun Dong reinforcement learning.Advances in Neural Information Processing Systems33 (2020), 21188–21198
2020
-
[42]
Amy N Langville and Carl D Meyer. 2004. Deeper inside pagerank.Internet Mathematics1, 3 (2004), 335–380
2004
- [43]
-
[44]
Yang Li, Jinpei Guo, Runzhong Wang, and Junchi Yan. 2023. T2t: From distribution learning in training to gradient search in testing for combinatorial optimization. Advances in Neural Information Processing Systems36 (2023), 50020–50040
2023
- [45]
-
[46]
Fu Luo, Xi Lin, Fei Liu, Qingfu Zhang, and Zhenkun Wang. 2023. Neural com- binatorial optimization with heavy decoder: Toward large scale generalization. Advances in Neural Information Processing Systems36 (2023), 8845–8864
2023
-
[47]
Mary McGlohon, Leman Akoglu, and Christos Faloutsos. 2008. Weighted graphs and disconnected components: patterns and a generator. InProceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 524–532
2008
-
[48]
Yimeng Min, Yiwei Bai, and Carla P Gomes. 2024. Unsupervised learning for solv- ing the travelling salesman problem.Advances in Neural Information Processing Systems36 (2024)
2024
-
[49]
SG Ozden, Alice E Smith, and Kevin R Gue. 2017. Solving large batches of traveling salesman problems with parallel and distributed computing.Computers & Operations Research85 (2017), 87–96
2017
- [50]
-
[51]
Ruizhong Qiu, Zhiqing Sun, and Yiming Yang. 2022. Dimes: A differentiable meta solver for combinatorial optimization problems.Advances in Neural Information Processing Systems35 (2022), 25531–25546
2022
- [53]
-
[54]
Zhiqing Sun and Yiming Yang. 2023. Difusco: Graph-based diffusion solvers for combinatorial optimization.Advances in Neural Information Processing Systems 36 (2023), 3706–3731
2023
- [55]
-
[56]
A Vaswani. 2017. Attention is all you need.Advances in Neural Information Processing Systems(2017)
2017
-
[57]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks.arXiv preprint arXiv:1710.10903(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [58]
-
[59]
Mingzhao Wang, You Zhou, Zhiguang Cao, Yubin Xiao, Xuan Wu, Wei Pang, Yuan Jiang, Hui Yang, Peng Zhao, and Yuanshu Li. 2025. An Efficient Diffusion- based Non-Autoregressive Solver for Traveling Salesman Problem. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1. 1469–1480
2025
- [60]
-
[61]
Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning8 (1992), 229–256
1992
-
[62]
Chenguang Xi, Van Sy Mai, Ran Xin, Eyad H Abed, and Usman A Khan. 2018. Linear convergence in optimization over directed graphs with row-stochastic matrices.IEEE Trans. Automat. Control63, 10 (2018), 3558–3565
2018
-
[63]
Yifan Xia, Xianliang Yang, Zichuan Liu, Zhihao Liu, Lei Song, and Jiang Bian
- [64]
-
[65]
Yubin Xiao, Di Wang, Boyang Li, Huanhuan Chen, Wei Pang, Xuan Wu, Hao Li, Dong Xu, Yanchun Liang, and You Zhou. 2024. Reinforcement learning-based nonautoregressive solver for traveling salesman problems.IEEE Transactions on Neural Networks and Learning Systems(2024)
2024
-
[66]
Liang Xin, Wen Song, Zhiguang Cao, and Jie Zhang. 2021. Neurolkh: Combining deep learning model with lin-kernighan-helsgaun heuristic for solving the trav- eling salesman problem.Advances in Neural Information Processing Systems34 (2021), 7472–7483
2021
-
[67]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2018. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[68]
Rongchao Xu, Zhiqing Hong, and Guang Wang. 2025. AutoSTDiff: Autoregres- sive Spatio-Temporal Denoising Diffusion Model for Asynchronous Trajectory Generation. InProceedings of the 2025 SIAM International Conference on Data Mining (SDM). SIAM, 538–547
2025
-
[69]
Rongchao Xu, Lin Jiang, Dahai Yu, Ximiao Li, and Guang Wang. 2026. SynHAT: A Two-stage Coarse-to-Fine Diffusion Framework for Synthesizing Human Activity Traces.arXiv preprint arXiv:2604.14705(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[70]
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. 2023. Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys56, 4 (2023), 1–39
2023
-
[71]
Hang Yi, Ziwei Huang, Yining Ma, and Zhiguang Cao. 2026. RADAR: Learning to Route with Asymmetry-aware DistAnce Representations. InInternational conference on learning representations
2026
-
[72]
Dahai Yu, Lin Jiang, Rongchao Xu, and Guang Wang. 2026. HealthMamba: An Uncertainty-aware Spatiotemporal Graph State Space Model for Effective and Reliable Healthcare Facility Visit Prediction
2026
-
[73]
Dahai Yu, Dingyi Zhuang, Lin Jiang, Rongchao Xu, Xinyue Ye, Yuheng Bu, Shen- hao Wang, and Guang Wang. 2025. UQGNN: Uncertainty Quantification of Graph Neural Networks for Multivariate Spatiotemporal Prediction. InProceedings of the 33rd ACM International Conference on Advances in Geographic Information Systems. 52–65
2025
-
[74]
Ni Zhang and Zhiguang Cao. 2026. Hybrid-balance gflownet for solving vehicle routing problems.Advances in Neural Information Processing Systems38 (2026), 16797–16821
2026
-
[75]
Ni Zhang, Jingfeng Yang, Zhiguang Cao, and Xu Chi. 2025. Adversarial generative flow network for solving vehicle routing problems. InInternational conference on learning representations
2025
-
[76]
Kaixiang Zhao, Bolin Shen, Yuyang Dai, Shayok Chakraborty, and Yushun Dong
-
[77]
GraphIP-Bench: How Hard Is It to Steal a Graph Neural Network, and Can We Stop It?
GraphIP-Bench: How Hard Is It to Steal a Graph Neural Network, and Can We Stop It?arXiv preprint arXiv:2605.12827(2026). AGDN: Learning to Solve Traveling Salesman Problem with Anisotropic Graph Diffusion Network KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. A Proof of Theoretical Results Proof of Theorem 4.3. We are inspired by the proof s...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.