Supervision versus Demonstration-Based In-Context Learning for Multiword Expression Classification
Pith reviewed 2026-06-27 22:02 UTC · model grok-4.3
The pith
Few-shot demonstrations let prompted LLMs match or beat a fine-tuned Turkish BERT on detecting idiomatic light verb constructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
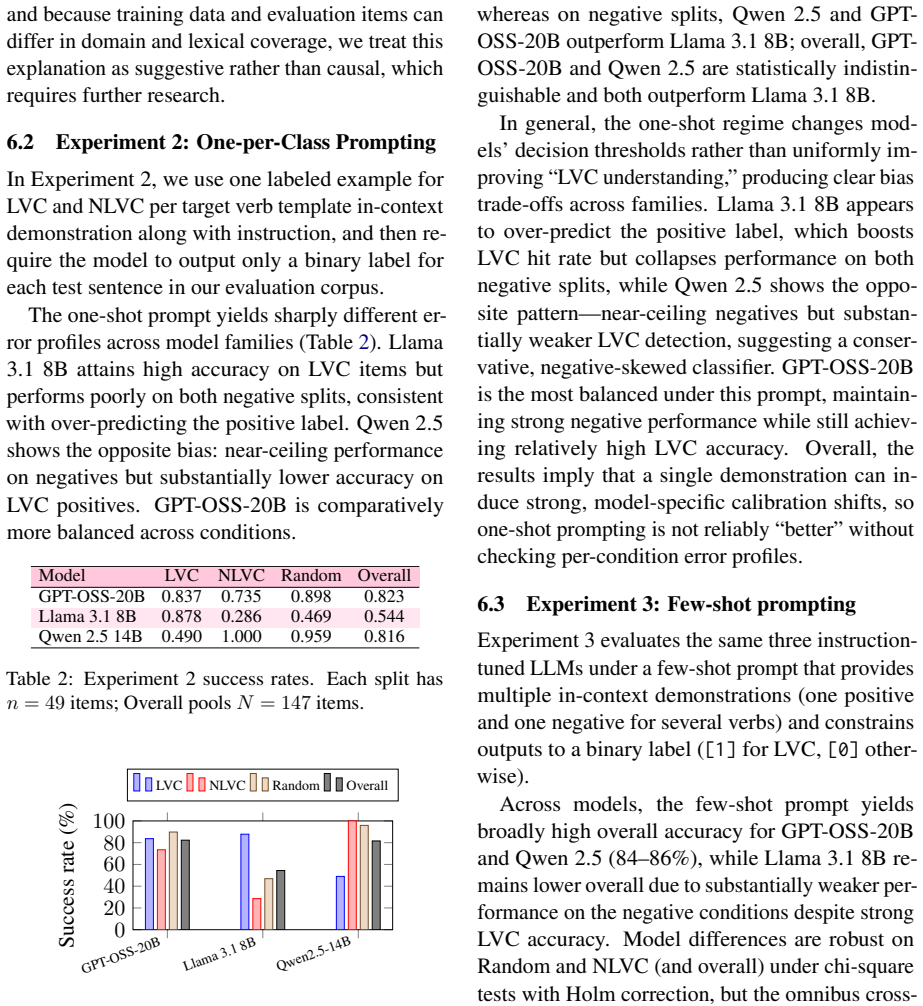
On a manually balanced test set of 147 Turkish verb-object sentences, few-shot prompting of instruction-tuned LLMs produces LVC detection performance that matches or exceeds a supervised BERTurk classifier, while zero- and one-shot regimes exhibit sharp shifts in recall and bias that are specific to each model family.
What carries the argument
Binary classification of literal versus idiomatic meaning for Turkish verb-object pairs, evaluated across zero-shot, one-shot, and few-shot prompts on a controlled N=147 set containing LVC positives, in-domain literal controls, and out-of-domain random negatives.
If this is right
- Carefully chosen demonstrations can shift LLM error profiles from under-prediction to balanced detection on LVCs.
- Model-specific biases appear even with a single demonstration and are reduced only when the prompt is enriched with multiple examples.
- The supervised Turkish encoder baseline stays competitive overall, but prompted LLMs can exceed it on the idiomatic class under favorable prompting.
- Prompt sensitivity is a dominant factor in metalinguistic classification tasks for Turkish.
Where Pith is reading between the lines
- If demonstration selection proves critical, automatic methods for choosing or generating examples could further close the gap between ICL and supervised approaches.
- The same controlled-set design could be applied to other languages with light-verb or other multiword-expression phenomena to test cross-lingual generality.
- Error-profile analysis suggests that hybrid systems combining a few-shot LLM with a lightweight supervised check might stabilize performance without full fine-tuning.
Load-bearing premise
The manually constructed set of 147 matched examples is representative enough to support general claims about relative performance and prompt sensitivity.
What would settle it
Evaluating the same models and prompt variants on a larger, independently sampled collection of Turkish LVC and literal verb-object sentences would show whether the reported few-shot gains and calibration improvements persist.
Figures


read the original abstract
Turkish idiomatic light verb constructions (LVCs) are challenging for multiword expression processing because they often share the same surface form as fully literal verb-object combinations while functioning as a single, partially idiomatic predicate. We frame Turkish LVC detection as a binary classification task (literal meaning vs. idiomatic meaning) and evaluate on a manually created controlled set (N=147) with matched negatives: out-of-domain random sentences and in-domain literal controls (NLVC), alongside LVC positives. We compare a supervised Turkish encoder baseline (BERTurk with a classifier head) to three instruction-tuned LLMs from different families under zero-shot, one-shot, and few-shot prompting, and analyze how demonstrations shift error profiles. In zero-shot, LLMs perform well on negatives but show very low LVC recall. One-shot prompting sharply improves LVC detection but can induce strong, model-specific biases, leading models to overpredict or underpredict LVCs. A richer few-shot prompt improves calibration and yields robust overall performance for GPT-OSS-20B and Qwen 2.5-14B. Overall, the results highlight substantial prompt sensitivity in Turkish metalinguistic classification: the supervised baseline remains competitive, while prompted LLMs can match or exceed it on LVCs with carefully constructed demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames Turkish LVC detection as binary classification (literal vs. idiomatic) and compares a supervised BERTurk baseline against instruction-tuned LLMs (including GPT-OSS-20B and Qwen 2.5-14B) under zero-, one-, and few-shot prompting on a manually constructed controlled test set of N=147 examples with matched in-domain (NLVC) and out-of-domain negatives. The central claim is that zero-shot LLMs show low LVC recall, one-shot prompting induces model-specific biases, and richer few-shot prompts improve calibration and allow some LLMs to match or exceed the supervised baseline on LVCs, while underscoring prompt sensitivity.
Significance. If the results hold, the work provides a controlled empirical comparison of supervision versus demonstration-based ICL for a challenging MWE task in Turkish, with useful analysis of how prompting regimes shift error profiles (recall, over/under-prediction). The matched-negative design and cross-family LLM comparison are strengths that could inform prompting strategies for metalinguistic classification in low-resource settings.
major comments (2)
- [Abstract / Dataset] Abstract and dataset description: The central claims about prompt robustness, calibration improvements, and LLM superiority over the supervised baseline rest entirely on a single hand-constructed collection of N=147 items that supplies both the 'carefully constructed demonstrations' and the evaluation instances. No statistical significance tests, bootstrap intervals, or external validation set are referenced, so observed differences in recall and error profiles could reflect idiosyncrasies of the chosen sentences rather than general properties of the methods.
- [Abstract / Results] Evaluation design (implied in abstract): Because the same small pool is used for both demonstration selection and testing, any reported gains from richer few-shot prompts (e.g., for GPT-OSS-20B and Qwen 2.5-14B) lack an independent test of generalization; this directly affects the load-bearing claim that prompted LLMs 'can match or exceed' the supervised baseline.
minor comments (1)
- [Abstract] Model naming: 'GPT-OSS-20B' is non-standard; clarify the exact model identifier and release used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation design. The controlled nature of the N=147 dataset was chosen to enable precise analysis of prompting effects, but we acknowledge the limitations raised and will revise the manuscript to address them explicitly.
read point-by-point responses
-
Referee: [Abstract / Dataset] Abstract and dataset description: The central claims about prompt robustness, calibration improvements, and LLM superiority over the supervised baseline rest entirely on a single hand-constructed collection of N=147 items that supplies both the 'carefully constructed demonstrations' and the evaluation instances. No statistical significance tests, bootstrap intervals, or external validation set are referenced, so observed differences in recall and error profiles could reflect idiosyncrasies of the chosen sentences rather than general properties of the methods.
Authors: We agree this is a genuine limitation of the current study. The dataset was deliberately hand-constructed with matched in-domain (NLVC) and out-of-domain negatives to isolate the impact of prompting strategies on LVC detection while controlling for surface-form confounds, which is difficult at larger scale in Turkish. We will add bootstrap confidence intervals and paired significance tests for all reported metrics in the revision. We will also revise the abstract and discussion to frame the work as an analysis of prompt sensitivity in a controlled low-resource setting rather than a general claim of LLM superiority. revision: partial
-
Referee: [Abstract / Results] Evaluation design (implied in abstract): Because the same small pool is used for both demonstration selection and testing, any reported gains from richer few-shot prompts (e.g., for GPT-OSS-20B and Qwen 2.5-14B) lack an independent test of generalization; this directly affects the load-bearing claim that prompted LLMs 'can match or exceed' the supervised baseline.
Authors: The shared pool is intentional to guarantee that demonstrations are high-quality, balanced examples of the exact phenomena under study, enabling direct comparison of zero-, one-, and few-shot regimes on identical items. We accept that this design precludes strong generalization claims. In the revision we will remove or qualify the phrasing 'can match or exceed' in the abstract, add an explicit limitations paragraph on the lack of held-out test data, and suggest larger independent corpora as future work. revision: yes
Circularity Check
No circularity: purely empirical comparison on fixed test set
full rationale
The paper reports direct experimental results comparing a supervised BERTurk baseline against zero/one/few-shot prompting of instruction-tuned LLMs on a manually constructed N=147 Turkish LVC classification dataset. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. All claims derive from observed metrics (recall, calibration, error profiles) on the held-out examples rather than any self-referential reduction. The small dataset size raises external-validity concerns but does not constitute circularity under the defined criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Sixth Conference on Computational Natural Language Learning (CoNLL 2002) , pages =
Baldwin, Timothy and Villavicencio, Aline , title =. Proceedings of the Sixth Conference on Computational Natural Language Learning (CoNLL 2002) , pages =. 2002 , url =
2002
-
[2]
1997 , url =
Karttunen, Lauri and Gaal, Tamas and Kempe, Andre , title =. 1997 , url =
1997
-
[3]
2015 , url =
Ramisch, Carlos , title =. 2015 , url =
2015
-
[5]
Advances in Neural Information Processing Systems , volume =
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[6]
Language Models for Text Classification: Is In-Context Learning Enough?
Edwards, Aleksandra and Camacho-Collados, Jose. Language Models for Text Classification: Is In-Context Learning Enough?. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[7]
Fine-Tuned
Bucher, Martin Juan Jos. Fine-Tuned. 2024 , eprint =
2024
-
[8]
2024 , eprint =
Fine-Tuning, Prompting, In-Context Learning and Instruction-Tuning: How Many Labelled Samples Do We Need? , author =. 2024 , eprint =
2024
-
[9]
Proceedings of the 38th International Conference on Machine Learning , pages =
Calibrate Before Use: Improving Few-shot Performance of Language Models , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[13]
Flaw or Artifact? Rethinking Prompt Sensitivity in Evaluating LLM s
Hua, Andong and Tang, Kenan and Gu, Chenhe and Gu, Jindong and Wong, Eric and Qin, Yao. Flaw or Artifact? Rethinking Prompt Sensitivity in Evaluating LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1006
-
[14]
Making Pre-trained Language Models Better Few-shot Learners
Gao, Tianyu and Fisch, Adam and Chen, Danqi. Making Pre-trained Language Models Better Few-shot Learners. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. 2021. doi:10.18653/v1/2021.acl-long.295
-
[16]
Language Teaching , year =
Siyanova-Chanturia, Anna and Sonbul, Suhad , title =. Language Teaching , year =
-
[17]
, title =
Arnon, Inbal and Clark, Eve V. , title =. Language Learning and Development , volume =. 2011 , doi =
2011
-
[18]
2020 , howpublished =
Schweter, Stefan , title =. 2020 , howpublished =
2020
-
[19]
Sentence Encoders on
Phang, Jason and F. Sentence Encoders on. 2018 , journal =
2018
-
[20]
, title =
Pruksachatkun, Yada and Phang, Jason and Liu, Haokun and Htut, Phu Mon and Zhang, Xiaoyi and Pang, Richard Yuanzhe and Vania, Clara and Kann, Katharina and Bowman, Samuel R. , title =. 2020 , journal =
2020
-
[22]
Journal of Language and Linguistic Studies , volume =
On. Journal of Language and Linguistic Studies , volume =. 2010 , url =
2010
-
[24]
Universal Dependencies v1: A Multilingual Treebank Collection , booktitle =
Nivre, Joakim and de Marneffe, Marie. Universal Dependencies v1: A Multilingual Treebank Collection , booktitle =. 2016 , url =
2016
-
[25]
Universal Dependencies:
- [26]
-
[27]
Resources for
T. Resources for. 2022 , month = mar, journal =
2022
-
[28]
Mar. Building the. Proceedings of the 11th Global Wordnet Conference , month = jan, year =. doi:10.18653/v1/2021.gwc-1.14 , pages =
-
[29]
Proceedings of the 14th Workshop on Treebanks and Linguistic Theories (TLT 14) , year =
A grammar-book treebank of Turkish , author =. Proceedings of the 14th Workshop on Treebanks and Linguistic Theories (TLT 14) , year =
-
[30]
Turkish Journal of Electrical Engineering & Computer Sciences , year =
Implementing Universal Dependency, Morphology and Multiword Expression Annotation Standards for Turkish Language Processing , author =. Turkish Journal of Electrical Engineering & Computer Sciences , year =
-
[31]
Proceedings of
Sulubacak, Umut and Gokirmak, Memduh and Tyers, Francis and. Proceedings of. 2016 , address =
2016
-
[32]
Zeman, Daniel and Popel, Martin and Straka, Milan and Haji. Proceedings of the. 2017 , address =. doi:10.18653/v1/K17-3001 , pages =
-
[33]
Mechanistic Interpretability for
Bereska, Leonard and Gavves, Efstratios , journal =. Mechanistic Interpretability for. 2024 , url =
2024
-
[34]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2022
-
[36]
Ali and Fincan, Ali Arda and G
Bayram, M. Ali and Fincan, Ali Arda and G. Tokenization Standards and Evaluation in Natural Language Processing: A Comparative Analysis of Large Language Models on. 2025 33rd Signal Processing and Communications Applications Conference (. 2025 , month = jun, pages =
2025
-
[37]
2021 , eprint =
Calibrate Before Use: Improving Few-Shot Performance of Language Models , author =. 2021 , eprint =
2021
-
[38]
Journal of Machine Learning Research , year =
Causal Abstraction: A Theoretical Foundation for Mechanistic Interpretability , author =. Journal of Machine Learning Research , year =
-
[39]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , title =. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022 (. 2022 , url =
2022
-
[40]
Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022 (
Takeshi Kojima and Shixiang Shane Gu and Machel Reid and Yutaka Matsuo and Yusuke Iwasawa , title =. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022 (
2022
-
[41]
Le and Ed H
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc V. Le and Ed H. Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , title =. The Eleventh International Conference on Learning Representations (. 2023 , url =
2023
-
[42]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , booktitle =
Denny Zhou and Nathanael Sch. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , booktitle =. 2023 , url =
2023
-
[43]
arXiv preprint arXiv:2112.00114 , year =
Maxwell Nye and Anders Johan Andreassen and Guy Gur-Ari and Henryk Michalewski and Jacob Austin and David Bieber and David Dohan and Aitor Lewkowycz and Maarten Bosma and David Luan and Charles Sutton and Augustus Odena , title =. arXiv preprint arXiv:2112.00114 , year =
-
[44]
Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection , booktitle =
Nivre, Joakim and de Marneffe, Marie. Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection , booktitle =. 2020 , url =
2020
-
[45]
Siyanova-Chanturia, Anna and Conklin, Kathy and van Heuven, Walter J. B. , title =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =. 2011 , doi =
2011
-
[47]
ACM Computing Surveys , year=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM Computing Surveys , year=
-
[48]
2024 , eprint=
In-context language learning: Architectures and algorithms , author=. 2024 , eprint=
2024
-
[49]
2021 , eprint=
Calibrate Before Use: Improving Few-shot Performance of Language Models , author=. 2021 , eprint=
2021
-
[50]
2022 , eprint=
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author=. 2022 , eprint=
2022
-
[51]
Beyond Accuracy: Behavioral Testing of
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer , booktitle =. Beyond Accuracy: Behavioral Testing of. 2020 , address =
2020
-
[52]
Findings of the Association for Computational Linguistics:
Evaluating Models' Local Decision Boundaries via Contrast Sets , author =. Findings of the Association for Computational Linguistics:. 2020 , address =
2020
-
[55]
Proceedings of the 29th International Conference on Computational Linguistics , month = oct, year =
Yang, Guanqun and Haque, Mirazul and Song, Qiaochu and Yang, Wei and Liu, Xueqing , editor =. Proceedings of the 29th International Conference on Computational Linguistics , month = oct, year =
-
[58]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =
Layer-wise Minimal Pair Probing Reveals Contextual Grammatical-Conceptual Hierarchy in Speech Representations , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =
2025
-
[59]
and Delaney, Eoin D
Mayne, Harry and Kearns, Ryan Othniel and Yang, Yushi and Bean, Andrew M. and Delaney, Eoin D. and Russell, Chris and Mahdi, Adam , booktitle =. 2025 , address =
2025
-
[61]
A Structural Probe for Finding Syntax in Word Representations , author =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , month = jun, year =
2019
-
[62]
Transactions of the Association for Computational Linguistics , year=
A Primer in BERTology: What We Know About How BERT Works , author=. Transactions of the Association for Computational Linguistics , year=
-
[63]
Integrating Morphology with Multi-word Expression Processing in
Oflazer, Kemal and. Integrating Morphology with Multi-word Expression Processing in. Proceedings of the Workshop on Multiword Expressions: Integrating Processing , month = jul, year =
-
[64]
Proceedings of the Second Workshop on Statistical Parsing of Morphologically Rich Languages , month = oct, year =
Multiword Expressions in Statistical Dependency Parsing , author =. Proceedings of the Second Workshop on Statistical Parsing of Morphologically Rich Languages , month = oct, year =
-
[66]
Enhancing the
Öztürk, Yağmur and Hadj Mohamed, Najet and Lion-Bouton, Adam and Savary, Agata , editor =. Enhancing the. Proceedings of the 18th Workshop on Multiword Expressions @LREC2022 , month = jun, year =
-
[67]
Proceedings of the Sixth Conference on Computational Natural Language Learning (CoNLL 2002) , year =
Extracting the Unextractable: A Case Study on Verb-Particles , author =. Proceedings of the Sixth Conference on Computational Natural Language Learning (CoNLL 2002) , year =
2002
-
[68]
Xerox Finite-State Tool , author =
-
[69]
Language Teaching , year =
The Processing of Multi-word Expressions: A Research Agenda for the Next 10 Years , author =. Language Teaching , year =
-
[70]
Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =
Seeing a Phrase ``Time and Again'' Matters: The Role of Phrasal Frequency in the Processing of Multiword Sequences , author =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =. 2011 , pages =
2011
-
[71]
Cognition , volume =
`Clap your hands' or `take your hands'? One-year-olds distinguish between frequent and infrequent multiword phrases , author =. Cognition , volume =. 2021 , pages =
2021
-
[72]
The Function of Word Order in Turkish Grammar , year =
Erguvanl. The Function of Word Order in Turkish Grammar , year =
-
[73]
Word Order and Scrambling , editor =
Kornfilt, Jaklin , title =. Word Order and Scrambling , editor =. 2003 , publisher =
2003
-
[74]
Linguistic Inquiry , year =
Kural, Murat , title =. Linguistic Inquiry , year =
-
[75]
1992 , note =
Kural, Murat , title =. 1992 , note =
1992
-
[76]
2003 , volume =
Information Structure in Turkish: The Word Order--Prosody Interface , journal =. 2003 , volume =
2003
-
[77]
2006 , number =
Bare Object NPs and Scrambling in Turkish , journal =. 2006 , number =
2006
-
[78]
Natural Language & Linguistic Theory , year =
Massam, Diane , title =. Natural Language & Linguistic Theory , year =
-
[79]
Case, Referentiality and Phrase Structure , year =
-
[80]
2009 , volume =
Incorporating Agents , journal =. 2009 , volume =
2009
-
[81]
Linguistic Inquiry , year =
Grimshaw, Jane and Mester, Armin , title =. Linguistic Inquiry , year =
-
[82]
Complex Predicates: Cross-linguistic Perspectives on Event Structure , editor =
Butt, Miriam , title =. Complex Predicates: Cross-linguistic Perspectives on Event Structure , editor =. 2010 , doi =
2010
-
[83]
Light Verb Constructions in
U. Light Verb Constructions in. Dil ve Edebiyat Dergisi / Journal of Linguistics and Literature , year =
-
[84]
The Function of Word Order in Turkish Grammar , publisher =
Erguvanl. The Function of Word Order in Turkish Grammar , publisher =. 1984 , series =
1984
-
[85]
Word Order and Scrambling , editor =
Kornfilt, Jaklin , title =. Word Order and Scrambling , editor =. 2003 , pages =
2003
-
[86]
2003 , volume =
Information structure in Turkish: the word order--prosody interface , journal =. 2003 , volume =
2003
-
[87]
Case, Referentiality and Phrase Structure , publisher =
\". Case, Referentiality and Phrase Structure , publisher =. 2005 , series =
2005
-
[88]
Proceedings of the Sixth Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
Oflazer, Kemal , title =. Proceedings of the Sixth Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[90]
and Baldwin, Timothy and Bond, Francis and Copestake, Ann and Flickinger, Dan , title =
Sag, Ivan A. and Baldwin, Timothy and Bond, Francis and Copestake, Ann and Flickinger, Dan , title =. Computational Linguistics and Intelligent Text Processing (CICLing) , year =
-
[91]
Handbook of Natural Language Processing , edition =
Baldwin, Timothy and Kim, Su Nam , title =. Handbook of Natural Language Processing , edition =. 2010 , url =
2010
-
[92]
Complex Predicates: Cross-Linguistic Perspectives on Event Structure , editor =
Butt, Miriam , title =. Complex Predicates: Cross-Linguistic Perspectives on Event Structure , editor =
-
[93]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =. 2020 , publisher =
2020
-
[96]
Integrating Morphology with Multi-Word Expression Processing in T urkish
Oflazer, Kemal and C etino g lu, \"O zlem and Say, Bilge. Integrating Morphology with Multi-Word Expression Processing in T urkish. Proceedings of the Workshop on Multiword Expressions: Integrating Processing. 2004
2004
-
[97]
Proceedings of the LREC 2022
Enhancing the T urkish Verbal Multiword Expressions Corpus. Proceedings of the LREC 2022. 2022
2022
-
[98]
and Baldwin, Timothy and Bond, Francis and Copestake, Ann and Flickinger, Dan
Sag, Ivan A. and Baldwin, Timothy and Bond, Francis and Copestake, Ann and Flickinger, Dan. Multiword Expressions: A Pain in the Neck for NLP. Proceedings of the 3rd International Conference on Intelligent Text Processing and Computational Linguistics (CICLing). 2002
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.