Linear Probes Detect Task Format, Not Reasoning Mode in Language Model Hidden States
Pith reviewed 2026-06-28 14:19 UTC · model grok-4.3
The pith
Linear probes on LLM hidden states separate reasoning types only due to task format differences like source and length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
High linear probe accuracy distinguishing deductive, inductive, and abductive reasoning in Qwen3-14B hidden states is driven entirely by format confounds; residualizing source identity, option count, and response length reduces accuracy to chance, while trace-anchor similarity and causal steering indicate shared reasoning mechanisms with no functional link to the observed geometry.
What carries the argument
Residualization of format features (source identity, option count, response length) that removes the apparent separation in hidden-state geometry.
If this is right
- Probe accuracy without format controls overestimates distinct computational structures for different reasoning types.
- Mechanistic interpretability studies using linear probes on reasoning tasks require routine deconfounding of format variables.
- Trace-anchor similarity and steering interventions can be used to check whether geometric separation reflects functional differences.
Where Pith is reading between the lines
- Many existing claims about specialized reasoning circuits in LLMs may need re-examination once format is controlled.
- Future benchmark design could prioritize matched formats to isolate reasoning signals more cleanly.
- The result raises the question of whether similar format confounds affect probes for other cognitive distinctions such as factuality or planning.
Load-bearing premise
Residualizing source identity, option count, and response length removes only format information and leaves any genuine reasoning-mode signals intact.
What would settle it
A new set of benchmarks that match source, option count, and response length across deductive, inductive, and abductive tasks but still yield probe accuracy above chance after residualization.
Figures







read the original abstract
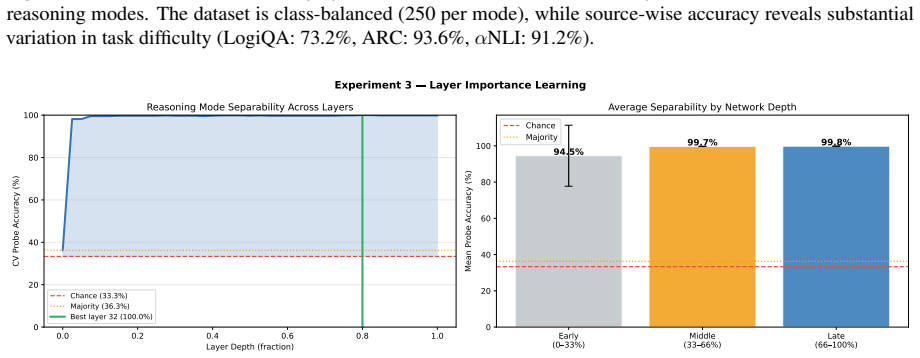
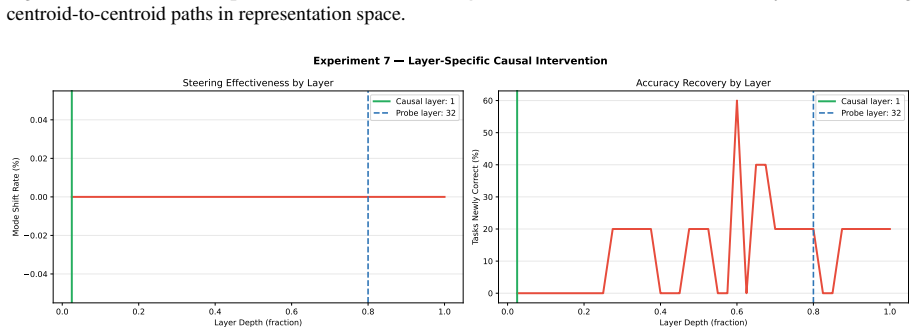
Linear probing of large language model (LLM) hidden states is widely used to claim that models learn distinct representations for different reasoning types. We test this by probing Qwen3-14B on three benchmarks spanning the classical trichotomy: LogiQA 2.0 (deductive), ARC-Challenge (inductive), and $\alpha$NLI (abductive). At layer 32 of 40, linear probes achieve 100\% cross-validated accuracy with well-separated geometry (intrinsic dimensionalities: 20.6, 28.5, 33.6; convex hull contamination $\leq$1.5\%). However, this separation is entirely driven by format confounds. Residualizing source identity, option count, and response length reduces accuracy to chance. Trace-anchor similarity indicates largely shared reasoning across tasks (42.5\% agreement vs.\ 33.3\% chance), and causal steering with random controls ($n=20$) shows no functional link between geometry and reasoning mode ($p=0.286$). Thus, high probe accuracy reflects task format rather than computational structure, motivating routine format deconfounding in mechanistic interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that high-accuracy linear probes on LLM hidden states for deductive (LogiQA 2.0), inductive (ARC-Challenge), and abductive (αNLI) reasoning tasks reflect task format confounds rather than distinct reasoning modes. At layer 32 of Qwen3-14B, probes reach 100% cross-validated accuracy with separated geometry, but residualizing source identity, option count, and response length drops accuracy to chance; trace-anchor similarity shows 42.5% agreement (vs. 33.3% chance) and causal steering with random controls (n=20) finds no functional link (p=0.286). The conclusion is that format deconfounding should be routine in mechanistic interpretability.
Significance. If the result holds after stronger controls, the work is significant because it supplies concrete empirical evidence (residualization, trace-anchor similarity, and random-control steering) that format confounds can fully explain probe separability in reasoning studies. This directly addresses a common methodological risk in the field and supplies a practical recommendation for future work. The multi-control design (rather than reliance on a single baseline) strengthens the contribution.
major comments (2)
- [Abstract] Abstract: The central claim that residualizing only source identity, option count, and response length removes all format-related variance (leaving any genuine reasoning-mode geometry intact) is load-bearing, yet the three benchmarks differ systematically in domain, question phrasing style, and lexical distributions, none of which are residualized. No diagnostic is reported showing that the post-residualization representations are orthogonal to remaining task-identity information.
- [Abstract] Abstract: The manuscript states that residualization reduces accuracy to chance but supplies no implementation details (regression form, per-layer vs. global application), cross-validation procedure for the post-residualization probes, or statistical power analysis, so the reported drop to chance is only partially supported as evidence against reasoning-mode signals.
minor comments (1)
- [Abstract] Abstract: The method used to compute the reported intrinsic dimensionalities (20.6, 28.5, 33.6) and convex-hull contamination values is not stated.
Simulated Author's Rebuttal
We thank the referee for their constructive comments highlighting areas where additional controls and details would strengthen the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that residualizing only source identity, option count, and response length removes all format-related variance (leaving any genuine reasoning-mode geometry intact) is load-bearing, yet the three benchmarks differ systematically in domain, question phrasing style, and lexical distributions, none of which are residualized. No diagnostic is reported showing that the post-residualization representations are orthogonal to remaining task-identity information.
Authors: We agree that domain, phrasing style, and lexical distributions represent additional potential confounds not explicitly residualized. Source identity residualization is intended to capture benchmark-specific format differences that correlate with these factors, but we acknowledge this is indirect. To directly test orthogonality to task identity, we will add a diagnostic in the revision: training linear probes on the residualized representations to predict task label and reporting chance-level performance. This will be included in the Results section alongside the existing residualization results. revision: partial
-
Referee: [Abstract] Abstract: The manuscript states that residualization reduces accuracy to chance but supplies no implementation details (regression form, per-layer vs. global application), cross-validation procedure for the post-residualization probes, or statistical power analysis, so the reported drop to chance is only partially supported as evidence against reasoning-mode signals.
Authors: We agree that these methodological details are required for reproducibility and to fully support the claim. In the revised manuscript we will expand the Methods section to specify: (i) ordinary least-squares linear regression applied independently per layer for residualization, (ii) 5-fold stratified cross-validation for the post-residualization probes, and (iii) a post-hoc power analysis confirming adequate power to detect deviations from chance. These additions will be placed in the main text rather than only the appendix. revision: yes
Circularity Check
No circularity; empirical controls are independent of fitted inputs
full rationale
The paper presents no derivation chain or first-principles result that reduces to its own inputs. Claims rest on direct measurements: cross-validated probe accuracy before/after residualizing three covariates, intrinsic dimensionality, convex hull overlap, trace-anchor agreement percentages, and p-values from steering experiments with random controls. These are falsifiable empirical quantities computed from model activations and task metadata; none are defined in terms of the target conclusion or obtained by fitting a parameter then relabeling it a prediction. No self-citation is invoked to establish uniqueness or forbid alternatives, and the residualization step is an explicit linear projection whose effect is reported rather than assumed by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- probe layer
axioms (2)
- domain assumption The three benchmarks isolate distinct reasoning modes (deductive, inductive, abductive) independent of format.
- domain assumption Residualization on source identity, option count, and response length removes only format information.
Reference graph
Works this paper leans on
-
[1]
When ai benchmarks plateau: A systematic study of benchmark saturation. Preprint, arXiv:2602.16763. Guillaume Alain and Yoshua Bengio
-
[2]
Abductive commonsense reasoning. Preprint, arXiv:1908.05739. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Win...
arXiv 1908
-
[3]
Language models are few-shot learners. Preprint, arXiv:2005.14165. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord
Pith/arXiv arXiv 2005
-
[4]
Think you have solved question answering? try arc, the ai2 reasoning challenge. Preprint, arXiv:1803.05457. Alexis Conneau, German Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni
-
[5]
Reasoning in large language models: A geometric perspective. Preprint, arXiv:2407.02678. Elena Facco, Maria d’Errico, Alex Rodriguez, and Alessandro Laio
-
[6]
Folio: Natural language reasoning with first-order logic. Preprint, arXiv:2209.00840. John Hewitt and Percy Liang
-
[7]
Designing and interpreting probes with control tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages 2733–2743, Hong Kong, China. Association for Computational Linguistics. John Hewitt and Christopher D. Manning
2019
-
[8]
A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4129–4138, Minneapolis, Minnesota. Association for Computational Linguistics. Jie Huang and Kevin Chen-Chuan Chang
2019
-
[9]
arXiv preprint arXiv:2310.06824
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. arXiv preprint arXiv:2310.06824. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov
-
[10]
Https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
In-context learning and induction heads. Https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html. OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, P...
2022
-
[11]
Gpt-4 technical report. Preprint, arXiv:2303.08774. Subramanyam Sahoo, Aman Chadha, Vinija Jain, and Divya Chaudhary
-
[12]
The reasoning trap – logical reasoning as a mechanistic pathway to situational awareness. Preprint, arXiv:2603.09200. Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, Davi...
-
[13]
Chain-of-thought prompting elicits reasoning in large language models. Preprint, arXiv:2201.11903. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others
-
[14]
Estimated via TwoNN (Facco et al., 2017)
Intrinsic dimensionality. Estimated via TwoNN (Facco et al., 2017). For each point, we compute µ = r2/r1 (ratio of second to first nearest-neighbor distance). The estimator is: ˆdID = 1 n nX i=1 log µi !−1 (2) Neighborhood size k = max(3, min(⌊√Ncorrect⌋, |Hm|/3)). Local curvature. For each point hi, we compute SVD of its k-nearest-neighbor patch. Curvatu...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.