Particle-Lund Multimodality in Jet Taggers
Pith reviewed 2026-06-29 17:14 UTC · model grok-4.3
The pith
Explicit Lund plane splittings remain complementary to particle constituents in transformer jet taggers for b-jet topologies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
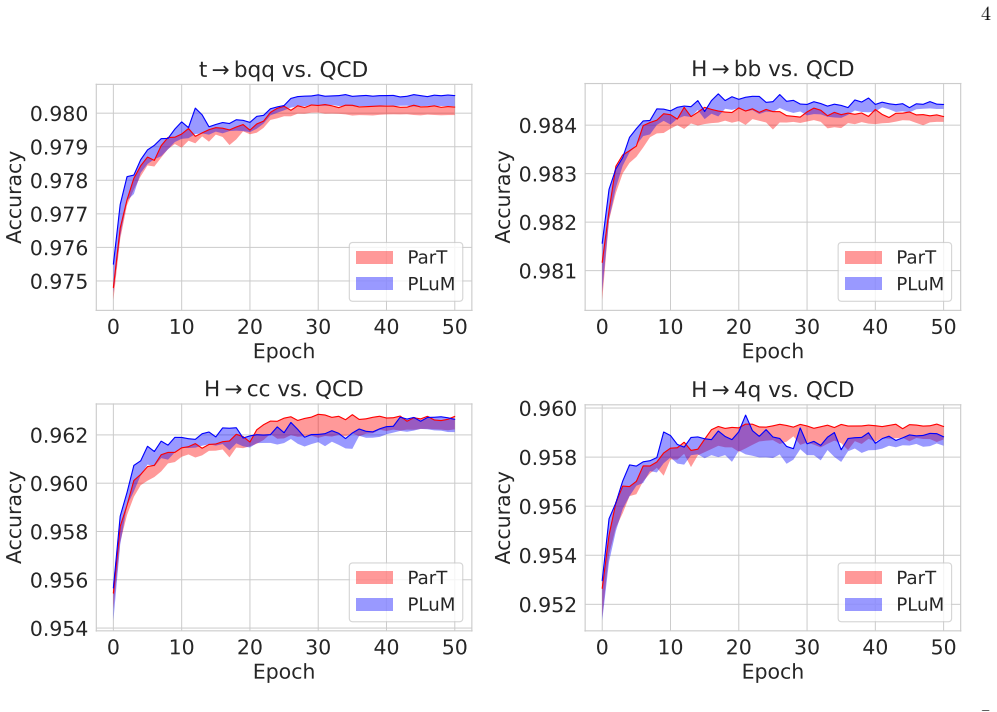
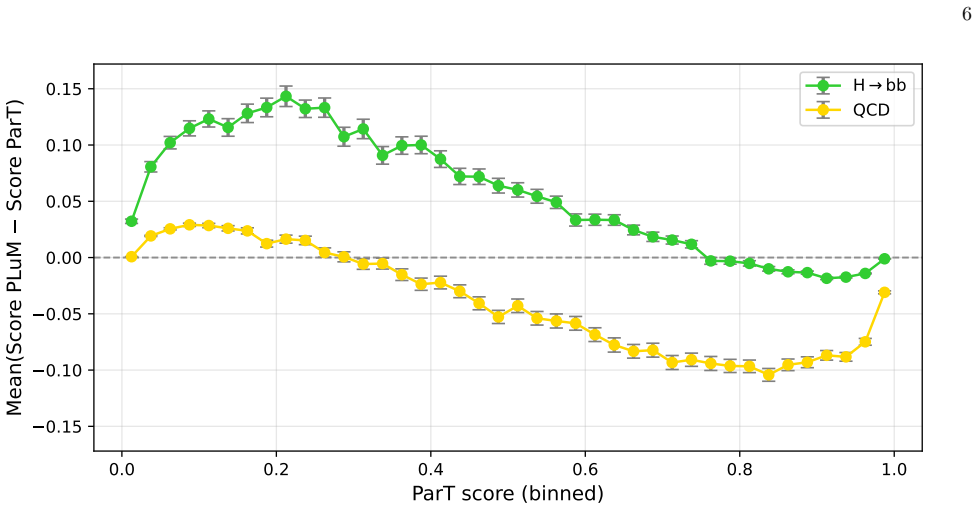
PLuM projects particle constituents and Lund plane splittings into a shared latent space and processes them jointly inside a unified transformer equipped with cross-attention. This architecture produces systematic improvements in top-quark and H to bb tagging while leaving H to cc and H to 4q performance unchanged. The pattern indicates that explicit hierarchical information about b-jet formation supplies discriminating power beyond what particle representations alone encode. At the 25 percent di-Higgs efficiency working point the model therefore achieves 25 percent higher background rejection than the particle-only baseline in the HH(4b) channel.
What carries the argument
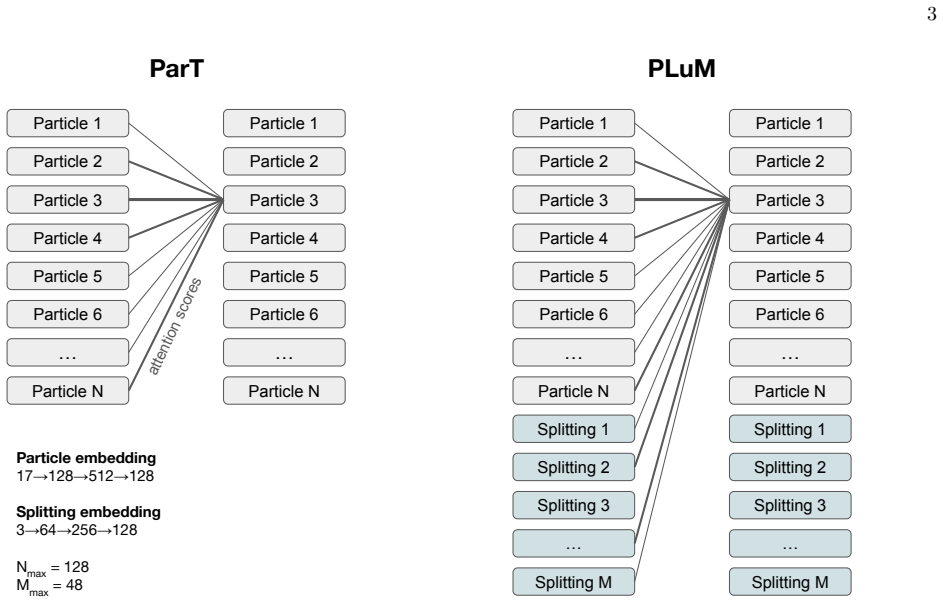
PLuM, the multimodal transformer that fuses particle constituents with Lund plane splittings through a shared latent space and cross-attention layers.
If this is right
- Top-quark tagging receives a systematic boost from explicit Lund information.
- H to bb tagging receives a systematic boost from explicit Lund information.
- H to cc and H to 4q tagging receive no comparable boost.
- Background rejection in boosted HH(4b) searches rises by 25 percent at 25 percent signal efficiency.
Where Pith is reading between the lines
- Transformers trained only on particles may leave some hierarchical aspects of b-jet formation under-exploited.
- Selective addition of physics representations could be tested on other decay channels or grooming observables.
- The topology dependence observed here supplies a diagnostic for which jet features still require explicit encoding.
- Similar multimodal fusion might be examined for quark-gluon discrimination or energy correlator inputs.
Load-bearing premise
The measured gains come from the added Lund plane information rather than from extra model capacity, altered training dynamics, or dataset fluctuations.
What would settle it
A particle-only transformer of equal or larger capacity trained on the identical datasets and working points that matches or exceeds PLuM performance on top and H to bb tasks would falsify the claim of complementarity.
Figures
read the original abstract
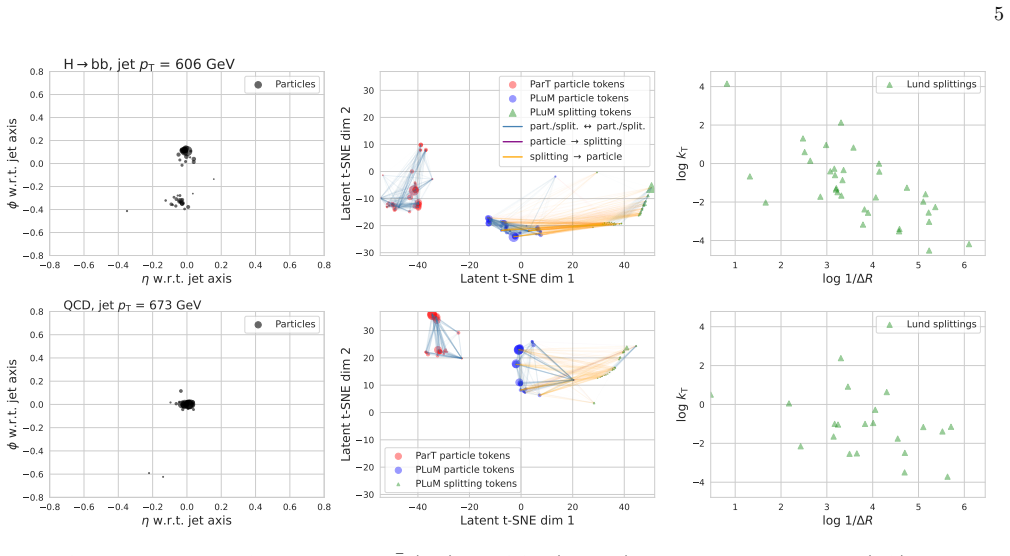
The Lund plane offers a physics-motivated, hierarchical representation of QCD radiation within jets, while transformer-based taggers have reached state-of-the-art performance by learning directly from raw particle constituents and their pairwise relations. We investigate whether transformers implicitly capture hierarchical QCD structure from constituent-level inputs, or whether explicit physics representations remain complementary. To test this, we introduce PLuM, a multimodal architecture that projects particle constituents and Lund plane splittings into a shared latent space, processing both jointly with a unified transformer. Cross-attention allows the model to probe whether structured QCD information provides discriminating power beyond what particles alone encode. We observe systematic gains for top-quark and $\mathrm{H}\to\mathrm{b}\bar{\mathrm{b}}$ tagging, while finding no comparable improvement for $\mathrm{H}\to\mathrm{c}\bar{\mathrm{c}}$ or $\mathrm{H}\to 4\mathrm{q}$ topologies. This selective enhancement suggests that explicit hierarchical information about b-jet formation remains complementary to raw particle representations even in highly expressive architectures, while other topologies are already well-captured at constituent level. For high-impact LHC analyses such as Lorentz-boosted di-Higgs searches in the four $\mathrm{b}$ quark final state ($\mathrm{H}\mathrm{H}(4\mathrm{b})$), the gains are substantial: at a $25\%$ di-Higgs efficiency working point, PLuM achieves $25\%$ higher background rejection than the baseline. Our results indicate that physically structured representations of QCD radiation retain discriminating value in the transformer era, motivating further study into how different aspects of jet dynamics are encoded by deep learning algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PLuM, a multimodal transformer that projects particle constituents and Lund-plane splittings into a shared latent space and processes them jointly via cross-attention. It reports systematic gains in top-quark and H o bb tagging performance, no comparable gains for H o cc or H o4q, and a concrete 25% improvement in background rejection for HH(4b) at the 25% signal-efficiency working point relative to a particle-only baseline. The central interpretation is that explicit hierarchical QCD information remains complementary to raw constituent representations even in expressive architectures.
Significance. If the reported gains are shown to arise specifically from Lund-plane complementarity rather than from increased model capacity or altered training dynamics, the result would provide evidence that physics-motivated representations retain discriminating power in the transformer era and could inform tagging strategies for boosted di-Higgs analyses. The selective pattern of improvement (present for b-jets, absent for other topologies) is a potentially useful observation if substantiated by controlled experiments.
major comments (1)
- [Abstract] Abstract: the 25% background-rejection gain for HH(4b) at 25% efficiency is presented as evidence of Lund complementarity, yet the description of the particle-only baseline does not state whether parameter count, optimizer schedule, or regularization strength were matched to the multimodal PLuM model. Adding cross-attention layers necessarily increases expressivity and changes gradient flow, so the selective improvement could reflect these architectural differences rather than orthogonal physics information.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the baseline comparison. We address the point below and will revise the manuscript to improve clarity on this issue.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 25% background-rejection gain for HH(4b) at 25% efficiency is presented as evidence of Lund complementarity, yet the description of the particle-only baseline does not state whether parameter count, optimizer schedule, or regularization strength were matched to the multimodal PLuM model. Adding cross-attention layers necessarily increases expressivity and changes gradient flow, so the selective improvement could reflect these architectural differences rather than orthogonal physics information.
Authors: We agree that the abstract should explicitly address the construction of the particle-only baseline to support the interpretation of Lund complementarity. In the full manuscript the particle-only baseline was constructed to have matched total parameter count (by adjusting transformer width and depth), identical optimizer schedule, and the same regularization strength as PLuM; these choices are described in the methods section. Nevertheless, we acknowledge that the abstract does not state this matching. We will revise the abstract to add a clause clarifying that the baselines were matched in parameter count, optimizer schedule, and regularization. We will also add a short sentence in the methods reiterating the matching procedure. These changes directly address the concern that the observed gains could arise from architectural differences rather than the addition of Lund-plane information. revision: yes
Circularity Check
No circularity: empirical performance comparison on held-out data
full rationale
The paper reports an empirical ML architecture comparison (PLuM multimodal transformer vs. particle-only baseline) with tagging efficiencies measured on simulated held-out samples. No equations, fitted parameters, or derivations are presented that could reduce the reported gains to a definitional identity or self-referential quantity. The central claim rests on observed performance differences rather than any self-citation chain, ansatz smuggling, or renaming of known results. This is the standard case of a self-contained experimental result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Lund plane splittings encode hierarchical QCD radiation structure that is not fully redundant with raw particle four-momenta
- domain assumption Simulated samples used for training and evaluation faithfully represent real LHC data for the tagging tasks considered
Reference graph
Works this paper leans on
-
[1]
ParticleNet: Jet Tagging via Particle Clouds,
H. Qu and L. Gouskos, ParticleNet: Jet Tagging via Particle Clouds, Phys. Rev. D101, 056019 (2020), arXiv:1902.08570 [hep-ph]
- [2]
-
[3]
Y. Wang, Y. Sun, Z. Liu, S. E. Sarma, M. M. Bron- stein, and J. M. Solomon, Dynamic graph CNN for learn- ing on point clouds, CoRRabs/1801.07829(2018), 1801.07829
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, At- tention is all you need, CoRRabs/1706.03762(2017), 1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
G. Aadet al.(ATLAS), Transforming jet flavour tag- ging at ATLAS, Nature Commun.17, 541 (2026), arXiv:2505.19689 [hep-ex]
-
[6]
Particle transformers for identifying Lorentz-boosted Higgs bosons decaying to a pair of W bosons
A. Hayrapetyanet al.(CMS), Particle transformers for identifying Lorentz-boosted Higgs bosons decay- ing to a pair of W bosons, arXiv preprint (2026), arXiv:2604.09809 [hep-ex]
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [7]
-
[8]
J. Spinner, V. Bres´ o, P. de Haan, T. Plehn, J. Thaler, and J. Brehmer, Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics, arXiv preprint (2024), arXiv:2405.14806 [physics.data-an]
-
[9]
G. Qu´ etant, J. A. Raine, M. Leigh, D. Sengupta, and T. Golling, Generating variable length full events from partons, Phys. Rev. D110, 076023 (2024), arXiv:2406.13074 [hep-ph]
-
[10]
S. Caron, N. Dobreva, A. F. S´ anchez, J. D. Mart´ ın- Guerrero, U. Odyurt, R. R. Ruiz de Austri Bazan, 7 Z. Wolffs, and Y. Zhao, Trackformers: in search of transformer-based particle tracking for the high- luminosity LHC era, Eur. Phys. J. C85, 460 (2025), arXiv:2407.07179 [hep-ex]
-
[11]
J. Brehmer, V. Bres´ o, P. de Haan, T. Plehn, H. Qu, J. Spinner, and J. Thaler, A Lorentz-equivariant trans- former for all of the LHC, SciPost Phys.19, 108 (2025), arXiv:2411.00446 [hep-ph]
-
[12]
S. Van Stroud, P. Duckett, M. Hart, N. Pond, S. Rettie, G. Facini, and T. Scanlon, Transformers for Charged Par- ticle Track Reconstruction in High-Energy Physics, Phys. Rev. X15, 041046 (2025), arXiv:2411.07149 [hep-ex]
- [13]
-
[14]
F. A. Dreyer, G. P. Salam, and G. Soyez, The Lund Jet Plane, JHEP12, 064, arXiv:1807.04758 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv
- [15]
- [16]
- [17]
- [18]
-
[19]
A. Hayrapetyanet al.(CMS), Measurement of the pri- mary Lund jet plane density in proton-proton collisions at √s = 13 TeV, JHEP05, 116, arXiv:2312.16343 [hep- ex]
-
[20]
G. Aadet al.(ATLAS), Measurement of the Lund jet plane in hadronic decays of top quarks and W bosons with the ATLAS detector, Eur. Phys. J. C85, 416 (2025), arXiv:2407.10879 [hep-ex]
-
[21]
Aaijet al.(LHCb), Measurement of the Lund plane for light- and beauty-quark jets, Phys
R. Aaijet al.(LHCb), Measurement of the Lund plane for light- and beauty-quark jets, Phys. Rev. D112, 072015 (2025), arXiv:2505.23530 [hep-ex]
-
[22]
A. Hayrapetyanet al.(CMS), A method for correcting the substructure of multiprong jets using the Lund jet plane, JHEP11, 038, arXiv:2507.07775 [hep-ex]
-
[23]
A. Hayrapetyanet al.(CMS), Machine-learning tech- niques for model-independent searches in dijet final states, arXiv preprint 10.5281/zenodo.16656501 (2025), arXiv:2512.20395 [hep-ex]
-
[24]
A. Belyaevet al.(CMS), Probing early parton emissions in heavy ion collisions using the Lund jet plane, arXiv preprint (2026), arXiv:2602.09271 [nucl-ex]
- [25]
-
[26]
Y. L. Dokshitzer, G. D. Leder, S. Moretti, and B. R. Webber, Better jet clustering algorithms, JHEP08, 001, arXiv:hep-ph/9707323
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
M. Wobisch and T. Wengler, Hadronization corrections to jet cross-sections in deep inelastic scattering, inWork- shop on Monte Carlo Generators for HERA Physics (Ple- nary Starting Meeting)(1998) pp. 270–279, arXiv:hep- ph/9907280
-
[28]
S. D. Ellis and D. E. Soper, Successive combination jet algorithm for hadron collisions, Phys. Rev. D48, 3160 (1993), arXiv:hep-ph/9305266
work page internal anchor Pith review Pith/arXiv arXiv 1993
-
[29]
DELPHES 3, A modular framework for fast simulation of a generic collider experiment
J. de Favereau, C. Delaere, P. Demin, A. Giammanco, V. Lemaˆ ıtre, A. Mertens, and M. Selvaggi (DELPHES 3), DELPHES 3, A modular framework for fast simu- lation of a generic collider experiment, JHEP02, 057, arXiv:1307.6346 [hep-ex]
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
A. Tumasyanet al.(CMS), Search for Nonresonant Pair Production of Highly Energetic Higgs Bosons Decaying to Bottom Quarks, Phys. Rev. Lett.131, 041803 (2023), arXiv:2205.06667 [hep-ex]
-
[31]
G. Aadet al.(ATLAS), Search for nonresonant pair pro- duction of Higgs bosons in the bb¯bb¯final state in pp collisions at s=13 TeV with the ATLAS detector, Phys. Rev. D108, 052003 (2023), arXiv:2301.03212 [hep-ex]
-
[32]
van der Maaten and G
L. van der Maaten and G. Hinton, Visualizing data us- ing t-sne, Journal of Machine Learning Research9, 2579 (2008)
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.