Understanding Memory Modules on Learning Simple Algorithms
Pith reviewed 2026-05-25 12:15 UTC · model grok-4.3
The pith
Stack-augmented networks generalize on arithmetic expressions while neural Turing machines do not by monitoring different inputs and applying distinct memory policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
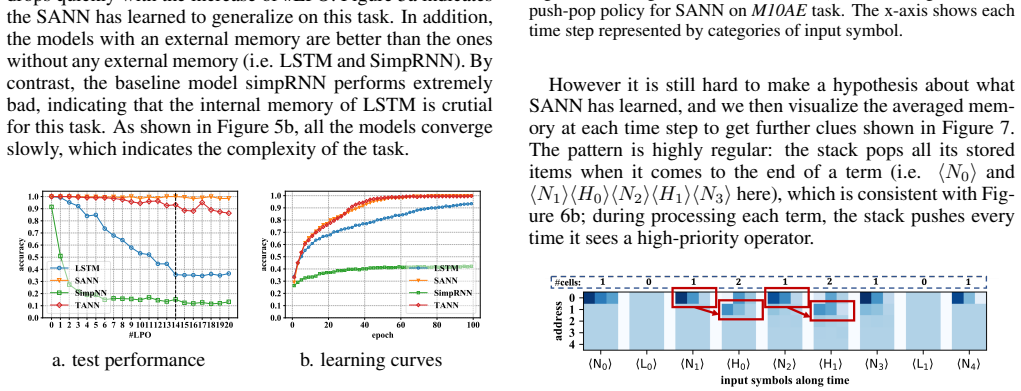
On the reversing task both models can learn to generalize and on the arithmetic task only the stack-augmented model can do so. Different strategies are learned by the models, in which specific categories of input are monitored and different policies are made based on that to change the memory. These strategies are identified through visualization and confirmed by the proposed qualitative analysis method based on dimension reduction.
What carries the argument
The two-step analysis pipeline that first forms hypotheses from memory visualizations and then verifies them with a dimension-reduction method applied to the memory states.
If this is right
- Both neural Turing machines and stack-augmented networks learn generalizing policies for sequence reversal.
- Only stack-augmented networks learn generalizing policies for arithmetic expression evaluation.
- The two architectures adopt different policies that watch different input categories and update memory accordingly.
- The same analysis pipeline can be used to compare strategies across other memory-augmented models.
Where Pith is reading between the lines
- The same visualization-plus-dimension-reduction approach could be applied to recurrent networks without explicit memory to see whether they discover analogous internal strategies.
- If the identified policies prove stable across random seeds, they could serve as diagnostic tests for whether a new memory module has acquired the expected algorithmic behavior.
- Extending the method to longer or more nested expressions might reveal whether the stack model’s advantage persists or breaks at greater depth.
Load-bearing premise
The dimension-reduction technique correctly identifies and confirms the strategies that were hypothesized from the visualizations.
What would settle it
Running the dimension-reduction analysis on the trained models and finding no distinct clusters or trajectories that match the hypothesized input-monitoring and memory-update policies would falsify the reported strategies.
Figures






read the original abstract
Recent work has shown that memory modules are crucial for the generalization ability of neural networks on learning simple algorithms. However, we still have little understanding of the working mechanism of memory modules. To alleviate this problem, we apply a two-step analysis pipeline consisting of first inferring hypothesis about what strategy the model has learned according to visualization and then verify it by a novel proposed qualitative analysis method based on dimension reduction. Using this method, we have analyzed two popular memory-augmented neural networks, neural Turing machine and stack-augmented neural network on two simple algorithm tasks including reversing a random sequence and evaluation of arithmetic expressions. Results have shown that on the former task both models can learn to generalize and on the latter task only the stack-augmented model can do so. We show that different strategies are learned by the models, in which specific categories of input are monitored and different policies are made based on that to change the memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a two-step analysis pipeline—first hypothesizing strategies from visualizations of memory-augmented networks, then verifying via a novel qualitative dimension-reduction method—to examine how Neural Turing Machines and stack-augmented networks learn reversing sequences and arithmetic expression evaluation. It reports that both models generalize on reversing while only the stack-augmented model succeeds on arithmetic, attributing this to distinct learned policies for monitoring input categories and updating memory.
Significance. If the dimension-reduction verification can be shown to provide independent support beyond the initial visualizations, the work would supply useful qualitative insights into strategy differences between memory architectures on algorithmic tasks. The empirical distinction in generalization performance is a concrete observation, though the paper supplies no machine-checked proofs, parameter-free derivations, or reproducible code artifacts.
major comments (1)
- [Method (qualitative analysis pipeline) and Results sections] The central claims about distinct input-category monitoring policies and memory-update strategies (abstract; results on reversing and arithmetic tasks) rest on the two-step pipeline. The verification step is itself a visualization technique with no described quantitative alignment metric, statistical test, or falsification criterion, so it cannot independently confirm the hypotheses and leaves the data-to-claim link vulnerable to confirmation bias.
minor comments (2)
- [Method section] The exact dimension-reduction technique (e.g., t-SNE parameters, distance metric) and how embeddings are aligned to hypothesized categories should be stated explicitly for reproducibility.
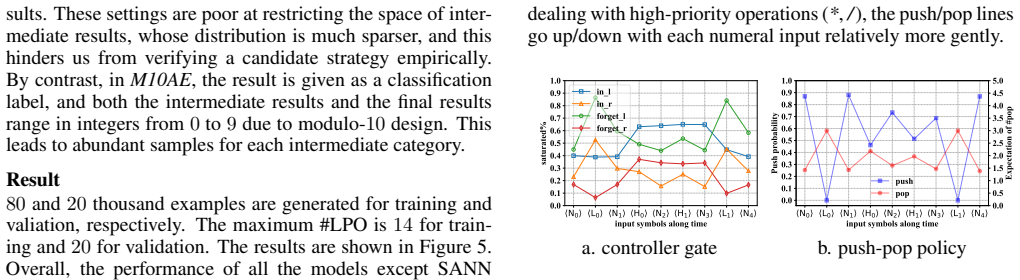
- [Results and figures] Figure captions and text should clarify which specific input categories (e.g., operators vs. operands) are being monitored in each policy description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below, acknowledging the qualitative character of our analysis while clarifying its intended role.
read point-by-point responses
-
Referee: [Method (qualitative analysis pipeline) and Results sections] The central claims about distinct input-category monitoring policies and memory-update strategies (abstract; results on reversing and arithmetic tasks) rest on the two-step pipeline. The verification step is itself a visualization technique with no described quantitative alignment metric, statistical test, or falsification criterion, so it cannot independently confirm the hypotheses and leaves the data-to-claim link vulnerable to confirmation bias.
Authors: We agree that the verification step relies on a qualitative dimension-reduction visualization without quantitative alignment metrics, statistical tests, or explicit falsification criteria. The method projects high-dimensional memory or activation states to reveal whether structures (e.g., category-specific clusters) emerge that are consistent with the strategies hypothesized from the initial visualizations. Because the approach is deliberately qualitative, it cannot supply independent quantitative confirmation. In revision we will (1) expand the method description to state the visual criteria used for verification more explicitly and (2) add a limitations paragraph discussing confirmation bias and the absence of statistical safeguards. These changes will make the evidential link more transparent without converting the analysis into a quantitative one. revision: partial
Circularity Check
No circularity: empirical observations on model behaviors with no derivations or self-referential reductions
full rationale
The paper describes an empirical pipeline of training memory-augmented networks on reversing and arithmetic tasks, generating visualizations, forming hypotheses about learned strategies, and applying a qualitative dimension-reduction method for verification. No equations, fitted parameters, predictions of derived quantities, or self-citation chains appear in the abstract or described content. The central claims concern observable differences in generalization and monitoring policies, framed as results of direct analysis rather than any derivation that reduces to its own inputs by construction. This is a standard empirical study whose claims rest on external task performance and visualization outputs, not on internal definitional loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Interpreting recurrent and attention-based neural models: a case study on natural language inference
Reza Ghaeini, Xiaoli Fern, and Prasad Tadepalli. Interpreting recurrent and attention-based neural models: a case study on natural language inference. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4952–4957. Association for Computa- tional Linguistics,
work page 2018
-
[2]
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. CoRR, abs/1410.5401,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Dynamic Neural Turing Machine with Soft and Hard Addressing Schemes
Caglar Gulcehre, Sarath Chandar, Kyunghyun Cho, and Yoshua Bengio. Dynamic neural turing machine with soft and hard addressing schemes. CoRR, abs/1607.00036,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Memory Augmented Neural Networks with Wormhole Connections
Caglar Gulcehre, Sarath Chandar, and Yoshua Bengio. Mem- ory augmented neural networks with wormhole connec- tions. CoRR, abs/1701.08718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Learning hierarchical structures on-the- fly with a recurrent-recursive model for sequences
Athul Paul Jacob, Zhouhan Lin, Alessandro Sordoni, and Yoshua Bengio. Learning hierarchical structures on-the- fly with a recurrent-recursive model for sequences. In Pro- ceedings of The Third Workshop on Representation Learn- ing for NLP , Rep4NLP@ACL 2018, Melbourne, Australia, July 20, 2018, pages 154–158,
work page 2018
-
[6]
Visualizing and Understanding Recurrent Networks
Andrej Karpathy, Justin Johnson, and Fei-Fei Li. Visu- alizing and understanding recurrent networks. CoRR, abs/1506.02078,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Skanda Koppula, Khe Chai Sim, and Kean K. Chin. Un- derstanding recurrent neural state using memory signa- tures. In 2018 IEEE International Conference on Acous- tics, Speech and Signal Processing, ICASSP 2018, Cal- gary, AB, Canada, April 15-20, 2018 , pages 2396–2400,
work page 2018
-
[8]
Vi- sualizing and understanding neural models in nlp
Jiwei Li, Xinlei Chen, Eduard Hovy, and Dan Jurafsky. Vi- sualizing and understanding neural models in nlp. In Pro- ceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 681–691,
work page 2016
-
[9]
Understanding Neural Networks through Representation Erasure
Jiwei Li, Will Monroe, and Dan Jurafsky. Understanding neural networks through representation erasure. CoRR, abs/1612.08220,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
State gradients for rnn memory anal- ysis
Lyan Verwimp, Hugo Van hamme, Vincent Renkens, and Patrick Wambacq. State gradients for rnn memory anal- ysis. In Proceedings of the 2018 EMNLP Workshop Black- boxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 344–346. Association for Computational Lin- guistics,
work page 2018
-
[12]
Techniques for visualizing LSTMs applied to electrocardiograms
Jos Van Der Westhuizen and Joan Lasenby. Techniques for visualizing lstms applied to electrocardiograms. arXiv preprint arXiv:1705.08153,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Memory architectures in recurrent neural network language models
Dani Yogatama, Yishu Miao, Gabor Melis, Wang Ling, Ad- higuna Kuncoro, Chris Dyer, and Phil Blunsom. Memory architectures in recurrent neural network language models. In International Conference on Learning Representations, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.