Insuring Every Action: An Authority Frontier Framework for Runtime Actuarial Control of Autonomous AI Agents
Pith reviewed 2026-06-29 21:35 UTC · model grok-4.3
The pith
A runtime contract prices every AI agent action against a safe default and gates execution by allocated reserve capital.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Authority Frontier framework, realized through the Actuarial Action Interface, supplies a benchmark-ready evaluation method for runtime actuarial control of autonomous agents by mapping heterogeneous actions to comparable authority units under a single time-consistent risk mapping, releasing authority only against reserve capital, and surfacing each domain's distinct actuarial geometry rather than imposing uniformity across domains.
What carries the argument
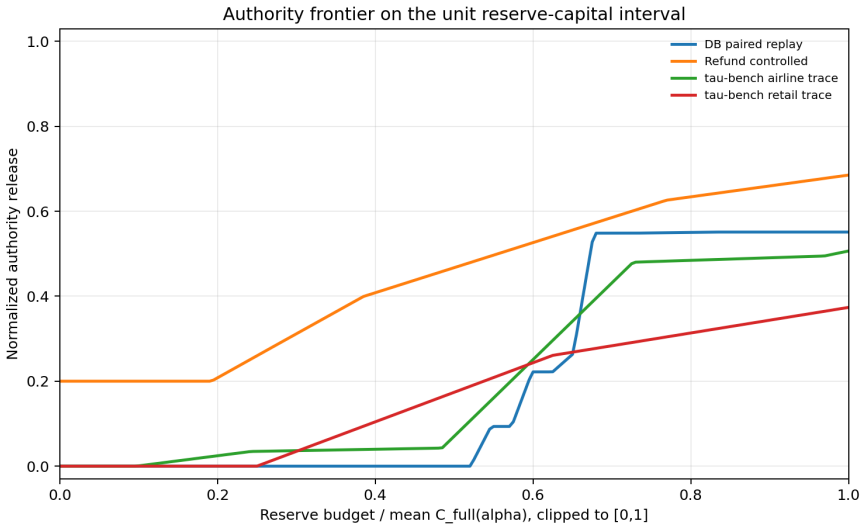
The Authority Frontier, an evaluation primitive that measures the quantity of autonomous authority the runtime releases at each level of reserve capital under a time-consistent risk mapping.
If this is right
- The quote-bind-commit protocol with toll-bounded capability tokens supplies deterministic execution control.
- Replay determinism and pathwise reserve coverage under alpha-spending guarantee that realized loss stays within budget.
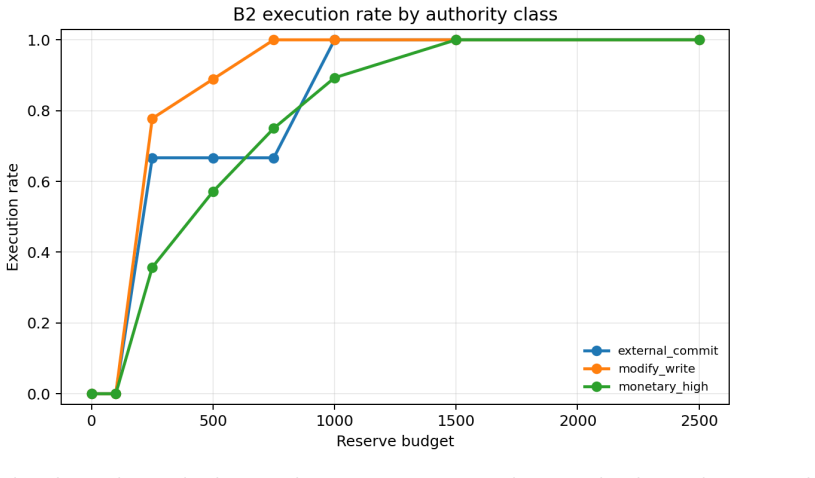
- Required reserve capital varies by domain (Capital@50 spans 289 to 6457 in tested cases).
- Model identity functions as an actuarial underwriting variable that affects persistence under denial.
Where Pith is reading between the lines
- Regulators could adopt Capital@k thresholds as minimum capital standards for deployed agents in specific sectors.
- The observed 22x spread in reserve demand suggests domain-specific actuarial tables rather than a single universal budget.
- Extending the taxonomy to novel action classes would require re-validating the time-consistent risk mapping.
Load-bearing premise
A universal seven-class action taxonomy can map every heterogeneous tool call to comparable authority units under one time-consistent risk mapping that remains valid across domains.
What would settle it
A new domain in which the seven-class taxonomy produces inconsistent authority units or in which allocated capital still permits realized loss.
Figures

read the original abstract
Autonomous AI agents increasingly issue side-effect-bearing actions: database mutations, refunds, payments, external commitments. We propose the Actuarial Action Interface (AAI), a deterministic runtime contract that prices each such action against a contractually fixed safe default under a time-consistent risk mapping, and gates execution against a per-boundary reserve capital budget. We then develop the Authority Frontier, an evaluation primitive measuring how much autonomous authority the runtime releases at each level of reserve capital. The framework provides (i) a deterministic quote-bind-commit protocol with toll-bounded capability tokens; (ii) a universal seven-class action taxonomy mapping heterogeneous tool calls to comparable authority units; (iii) replay determinism and pathwise reserve coverage under alpha-spending; (iv) cross-domain normalization via full reserve demand C_full and capital metrics Capital@k. We instantiate AAI across four agentic environments (database mutation, customer-service refund, and the public tau-bench retail and airline tool-use traces) and report a live Postgres panel in which three Azure-hosted models propose actions through the same contract. The frontier exhibits a common low-reserve refusal and intermediate-release pattern across domains, with saturation only where the budget grid reaches full reserve demand; required reserve capital varies by 22x (Capital@50 from 289 to 6457). The framework does not force domains into the same shape; it surfaces each domain's actuarial geometry. In the live panel the contract prevents realized loss across all three models at low budget while differing in underwriting persistence under denial: model identity is an actuarial underwriting variable. The contribution is a benchmark-ready evaluation framework for runtime actuarial control of autonomous-agent side effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Actuarial Action Interface (AAI), a deterministic runtime contract that prices agent actions against a safe default under a time-consistent risk mapping and gates them via per-boundary reserve capital budgets. It introduces the Authority Frontier as an evaluation primitive, a universal seven-class action taxonomy for mapping heterogeneous tool calls to comparable authority units, a quote-bind-commit protocol, and cross-domain normalization via C_full and Capital@k metrics. The framework is instantiated across four environments (database mutation, customer-service refund, tau-bench retail and airline traces) with three Azure models, reporting common low-reserve refusal patterns, 22x variation in Capital@50 (289 to 6457), and that the contract prevents realized loss at low budgets while model identity functions as an underwriting variable.
Significance. If the central assumptions hold—particularly that the seven-class taxonomy yields domain-invariant, time-consistent authority units and risk mappings—the work would supply a reproducible, benchmark-ready framework for runtime actuarial control of autonomous-agent side effects. The live Postgres panel, alpha-spending determinism, and explicit free parameters (per-boundary reserve budget, alpha-spending) are positive features that could support falsifiable evaluation; however, the absence of explicit mapping rules or invariance checks limits the immediate significance of the cross-domain claims.
major comments (3)
- [Abstract / instantiation description] The strongest claim—that the contract prevents realized loss across models and that model identity is an actuarial underwriting variable—depends on the universal seven-class taxonomy producing commensurable authority units under a single time-consistent risk mapping. No explicit mapping rules, class-weight definitions, or checks for invariance (e.g., same actuarial weight for database mutation versus airline tool-use actions) are supplied in the abstract or instantiation description, leaving the cross-domain normalization via C_full unverified.
- [Abstract / results panel] The reported Capital@50 values, frontier patterns, and loss-prevention results are presented without derivation details, error bars, statistical tests, or sensitivity analysis on the free parameters (per-boundary reserve capital budget, alpha-spending parameter). This makes it impossible to assess whether the 22x variation or the common low-reserve refusal pattern is robust or sensitive to implementation choices.
- [Framework definition (seven-class taxonomy)] The weakest assumption—that a single seven-class taxonomy remains valid across domains when action sequences cross class boundaries—is asserted but not demonstrated; the manuscript supplies no proof or empirical check that the risk mapping stays time-consistent or that class boundaries do not require domain-specific tuning.
minor comments (1)
- [Abstract] The abstract states results but provides no table or figure references for the live Postgres panel or the specific Capital@k values; adding numbered tables or figures would improve traceability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and note planned revisions to improve clarity on the taxonomy and results presentation.
read point-by-point responses
-
Referee: [Abstract / instantiation description] The strongest claim—that the contract prevents realized loss across models and that model identity is an actuarial underwriting variable—depends on the universal seven-class taxonomy producing commensurable authority units under a single time-consistent risk mapping. No explicit mapping rules, class-weight definitions, or checks for invariance (e.g., same actuarial weight for database mutation versus airline tool-use actions) are supplied in the abstract or instantiation description, leaving the cross-domain normalization via C_full unverified.
Authors: We agree the abstract omits explicit mapping rules. Section 3 of the manuscript defines the seven-class taxonomy and its application to tool calls, but detailed per-domain mappings and invariance tables were omitted. We will add an appendix with explicit mapping rules, class weights, and sample authority unit assignments across the four environments to verify commensurability under C_full. revision: yes
-
Referee: [Abstract / results panel] The reported Capital@50 values, frontier patterns, and loss-prevention results are presented without derivation details, error bars, statistical tests, or sensitivity analysis on the free parameters (per-boundary reserve capital budget, alpha-spending parameter). This makes it impossible to assess whether the 22x variation or the common low-reserve refusal pattern is robust or sensitive to implementation choices.
Authors: The values derive from the deterministic Postgres panel runs in Section 4. We will revise the results section to include derivation steps for the metrics, error bars from repeated trials, sensitivity analysis on reserve budget and alpha-spending, and statistical comparisons to demonstrate robustness of the 22x variation and refusal patterns. revision: yes
-
Referee: [Framework definition (seven-class taxonomy)] The weakest assumption—that a single seven-class taxonomy remains valid across domains when action sequences cross class boundaries—is asserted but not demonstrated; the manuscript supplies no proof or empirical check that the risk mapping stays time-consistent or that class boundaries do not require domain-specific tuning.
Authors: The taxonomy is offered as a pragmatic primitive enabling cross-domain comparison, with support from the observed common frontier patterns in the experiments. No formal proof of time-consistency is supplied, as the work is an empirical framework. We will add a limitations discussion outlining potential needs for domain tuning and suggesting empirical checks for future validation. revision: partial
- Formal mathematical proof of time-consistency and invariance for the seven-class taxonomy across arbitrary domains and action sequences
Circularity Check
No circularity: framework primitives defined independently of outcomes
full rationale
The paper introduces the Actuarial Action Interface, seven-class taxonomy, Authority Frontier, and Capital@k metrics as standalone definitions with deterministic protocols and cross-domain normalization. No equations, fitted parameters, or self-citations are shown that reduce the reported frontiers, reserve demands, or model-specific persistence results to inputs by construction. Experimental results across the four environments are presented as measurements under the fixed contract rather than as definitional constraints. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-boundary reserve capital budget
- alpha-spending parameter
axioms (2)
- domain assumption time-consistent risk mapping
- ad hoc to paper universal seven-class action taxonomy
invented entities (2)
-
Actuarial Action Interface (AAI)
no independent evidence
-
Authority Frontier
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Gaming-Resistant Insurance Contracts for Autonomous AI Agents: Strategy-Proof Toll Mechanism Design
The paper characterizes a five-attack space for AI-agent insurance and proves joint incentive compatibility by adding common-control aggregation, interface escalation fees, and model-identity menus to a base runtime, ...
-
Foundations of a Time-Consistent Counterfactual Actuarial Runtime for Autonomous AI Agents
Proposes a time-consistent counterfactual actuarial runtime for AI agents establishing four structural results on toll definition, no-splitting boundaries, authority premiums, and runtime gating.
Reference graph
Works this paper leans on
-
[1]
Viral V. Acharya, Lasse H. Pedersen, Thomas Philippon, and Matthew Richardson. Measuring systemic risk.The Review of Financial Studies, 30(1):2–47, 2017. doi: 10.1093/rfs/hhw088
-
[2]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
Anastasios N. Angelopoulos and Stephen Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification.arXiv preprint arXiv:2107.07511, 2021. doi: 10.48550/arXiv.2107.07511
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.07511 2021
-
[3]
Coherent measures of risk.Mathematical Finance, 9(3):203–228, 1999
Philippe Artzner, Freddy Delbaen, Jean-Marc Eber, and David Heath. Coherent measures of risk.Mathematical Finance, 9(3):203–228, 1999. doi: 10.1111/1467-9965.00068
-
[4]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Algorithmic insurance.arXiv preprint arXiv:2106.00839, 2021
Dimitris Bertsimas and Agni Orfanoudaki. Algorithmic insurance.arXiv preprint arXiv:2106.00839, 2021. doi: 10.48550/arXiv.2106.00839
-
[6]
Catastrophe insurance: An adaptive robust optimization approach
Dimitris Bertsimas et al. Catastrophe insurance: An adaptive robust optimization approach. arXiv preprint arXiv:2405.07068, 2024. doi: 10.48550/arXiv.2405.07068
-
[7]
Jocelyne Bion-Nadal. Dynamic risk measures: Time consistency and risk measures from bmo martingales.Finance and Stochastics, 12(2):219–244, 2008. doi: 10.1007/s00780-007-0057-1
-
[8]
Experience rating and credibility.ASTIN Bulletin, 4(3):199–207, 1967
Hans B¨ uhlmann. Experience rating and credibility.ASTIN Bulletin, 4(3):199–207, 1967. 33
1967
-
[9]
A time-consistent counterfactual actuarial runtime for autonomous AI agents
Hao-Hsuan Chen. A time-consistent counterfactual actuarial runtime for autonomous AI agents. SSRN Working Paper 6761960, Social Science Research Network, 2026. Companion mathematical foundations paper
2026
-
[10]
Patrick Cheridito, Freddy Delbaen, and Michael Kupper. Dynamic monetary risk measures for bounded discrete-time processes.Electronic Journal of Probability, 11:57–106, 2006. doi: 10.1214/EJP.v11-302
-
[11]
Algorithms for CVaR optimization in MDPs
Yinlam Chow and Mohammad Ghavamzadeh. Algorithms for CVaR optimization in MDPs. In Advances in Neural Information Processing Systems, volume 27, 2014
2014
-
[12]
Kai Detlefsen and Giacomo Scandolo. Conditional and dynamic convex risk measures.Finance and Stochastics, 9:539–561, 2005. doi: 10.1007/s00780-005-0159-6
-
[13]
Martin Eling and Werner Schnell. What do we know about cyber risk and cyber risk insurance? A systematization of literature.Journal of Risk Finance, 17(5):474–491, 2016. doi: 10.1108/JRF-09-2016-0122
-
[14]
Cand` es
Isaac Gibbs and Emmanuel J. Cand` es. Adaptive conformal inference under distribution shift. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[15]
Quantifying Trust: Financial Risk Management for Trustworthy AI Agents
Wenyue Hua, Tianyi Peng, Chi Wang, Jiaxin Pei, Ian Kaufman, Bryan Lim, and Chandler Fang. Quantifying trust: Financial risk management for trustworthy AI agents.arXiv preprint arXiv:2604.03976, 2026. doi: 10.48550/arXiv.2604.03976
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.03976 2026
-
[16]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In International Conference on Learning Representations, 2024
2024
-
[17]
Boda Kang and Jerzy A. Filar. Time consistent dynamic risk measures.Mathematical Methods of Operations Research, 63(1):169–186, 2006. doi: 10.1007/s00186-005-0045-1
-
[18]
Kochenderfer, Tim A
Mykel J. Kochenderfer, Tim A. Wheeler, and Kyle H. Wray.Algorithms for Decision Making. MIT Press, 2022
2022
-
[19]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, et al. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representations, 2024
2024
-
[20]
McNeil, R¨ udiger Frey, and Paul Embrechts.Quantitative Risk Management: Concepts, Techniques and Tools
Alexander J. McNeil, R¨ udiger Frey, and Paul Embrechts.Quantitative Risk Management: Concepts, Techniques and Tools. Princeton University Press, revised edition, 2015
2015
-
[21]
Miller.Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control
Mark S. Miller.Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control. PhD thesis, Johns Hopkins University, 2006
2006
-
[22]
Wainwright, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, 2022
2022
-
[23]
OWASP top 10 for large language model applications
OWASP Foundation. OWASP top 10 for large language model applications. https://owasp.org/www-project-top-10-for-large-language-model-applications, 2024
2024
-
[24]
Cambridge University Press, 2 edition, 2009
Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2 edition, 2009. 34
2009
-
[25]
NeMo Guardrails: A toolkit for controllable and safe LLM applications with programmable rails
Traian Rebedea, Razvan Dinu, Makesh Sreedhar, Christopher Parisien, and Jonathan Cohen. NeMo Guardrails: A toolkit for controllable and safe LLM applications with programmable rails. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 431–445. Association for Computational Linguistics,
2023
-
[26]
Tyrrell Rockafellar and Stanislav Uryasev
R. Tyrrell Rockafellar and Stanislav Uryasev. Optimization of conditional value-at-risk. Journal of Risk, 2:21–42, 2000
2000
-
[27]
Berend Roorda and J. M. Schumacher. Time consistency conditions for acceptability measures, with an application to tail value at risk.Insurance: Mathematics and Economics, 40(2): 209–230, 2007. doi: 10.1016/j.insmatheco.2006.04.003
-
[28]
Risk-averse dynamic programming for Markov decision processes
Andrzej Ruszczy´ nski. Risk-averse dynamic programming for Markov decision processes. Mathematical Programming, 125(2):235–261, 2010. doi: 10.1007/s10107-010-0393-3
-
[29]
SIAM, 2009
Alexander Shapiro, Darinka Dentcheva, and Andrzej Ruszczy´ nski.Lectures on Stochastic Programming: Modeling and Theory. SIAM, 2009
2009
-
[30]
Optimizing the CVaR via sampling
Aviv Tamar, Yonatan Glassner, and Shie Mannor. Optimizing the CVaR via sampling. In AAAI Conference on Artificial Intelligence, 2015
2015
-
[31]
Capital Allocation to Business Units and Sub-Portfolios: the Euler Principle
Dirk Tasche. Capital allocation to business units and sub-portfolios: The Euler principle. arXiv preprint arXiv:0708.2542, 2007. doi: 10.48550/arXiv.0708.2542
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.0708.2542 2007
-
[32]
Springer, 2005
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer.Algorithmic Learning in a Random World. Springer, 2005
2005
-
[33]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024. 35
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.