Auditing Demonstration Curation Metrics: Action-Only Scorers Fail on the Structural Defects That Degrade Imitation Policies
Pith reviewed 2026-06-28 01:50 UTC · model grok-4.3
The pith
Action-only metrics for curating imitation demonstrations miss structural errors like wrong actions at key moments, and some score the defective data higher, leaving policies no better than the uncurated baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
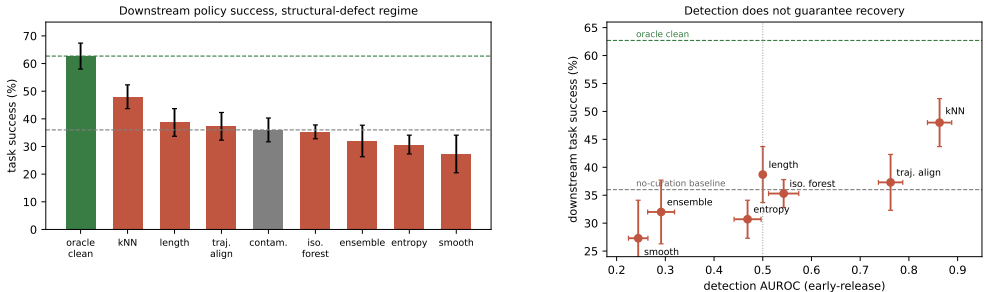
In a testbed with known injected defects, structural errors where a demonstration takes a wrong action at a key moment remain invisible to action-only curation metrics, and two such metrics score the defective demonstrations as higher quality; when used to curate training data, these metrics produce policies no better than or worse than the uncurated baseline. Metrics that inspect state trajectories detect the structural errors, yet the best of them recovers only one third of the downstream performance gap. High accuracy at separating clean from defective data does not guarantee improvement in the imitation policy trained on the curated set.
What carries the argument
The controlled testbed that injects known defect types into demonstrations and evaluates curation metrics on both separation accuracy and downstream policy success after filtering.
If this is right
- Subtle perturbations such as correlated action noise or truncation can be removed by multivariate outlier scoring to recover the full downstream performance gap.
- Action-only metrics remain blind to structural errors and two of them assign higher quality scores to defective demonstrations.
- Curation with the inverted action-only metrics leaves the trained policy at or below the uncurated baseline.
- Metrics that examine state trajectories detect structural errors, but the strongest recovers only one third of the downstream gap.
- High detection accuracy on defective demonstrations does not ensure downstream policy improvement.
Where Pith is reading between the lines
- If real human demonstrations contain structural errors at key moments, relying on action-only metrics for curation may systematically preserve or amplify harmful data.
- Future metrics that combine action sequences with state trajectories could close more than one third of the performance gap left by current methods.
- The released testbed provides a standard way to evaluate whether new curation scores improve actual policy success rather than only detection accuracy.
Load-bearing premise
The injected defects of the tested types are representative of the structural and subtle errors that occur in real human-collected demonstration data.
What would settle it
Apply the same set of metrics to a collection of real human demonstrations that contain independently verified structural errors at known moments, then measure whether the downstream policy success rates match the patterns observed in the controlled testbed.
Figures

read the original abstract
Imitation-learning policies inherit the quality of the demonstrations they are trained on, and a growing set of curation metrics promise to score and filter low-quality demonstrations automatically. These metrics are each validated on different data with different protocols, so it is unclear which of them actually identify the demonstrations that harm a policy. We build a controlled testbed in which demonstration defects are injected with known type, and audit seven curation metrics along two axes: how well each separates defective from clean demonstrations, and whether training a behavior-cloning policy on each metric's curated subset improves task success. We study two defect regimes. Subtle perturbations (correlated action noise, tremor, truncation) are detectable by multivariate outlier scoring and, once removed, recover the full downstream gap. Structural errors, where the demonstration executes a wrong action at a key moment, are invisible to every action-only metric we test, and two of them are inverted: they score defective demonstrations as higher quality and, used for curation, tend to leave the policy at or below the uncurated baseline rather than above it. Only metrics that examine the state trajectory detect structural errors, and even the best of them recovers just a third of the downstream gap. High detection accuracy does not guarantee downstream improvement. We release the testbed and all curation implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a controlled testbed by injecting known defects (subtle perturbations like correlated noise/tremor/truncation, and structural errors like wrong actions at key moments) into demonstrations. It audits seven curation metrics along two axes: separation of defective vs. clean demos, and whether curation improves downstream behavior-cloning policy success. Findings: subtle defects are detectable by outlier scoring with full gap recovery; structural errors are invisible to all action-only metrics (with two inverted, yielding policies at or below baseline); state-trajectory metrics detect them but recover only ~1/3 of the gap. High detection accuracy does not guarantee downstream gains. The testbed and implementations are released.
Significance. If the results hold, the work is significant as an empirical audit exposing limitations of action-only curation metrics in imitation learning, showing they can be blind or counterproductive to structural defects that harm policies. The controlled testbed design with known defect types supports clear evaluation axes. Releasing the testbed and code is a clear strength for reproducibility and community follow-up. The observation that detection accuracy does not imply policy improvement is a useful cautionary finding.
major comments (2)
- [Testbed construction] Testbed construction (defect injection protocol): The central claims about action-only metrics failing on structural errors rest on the specific synthetic injection of 'wrong action at key moments,' but the manuscript provides no quantitative comparison (e.g., action histogram divergence or state-transition statistics) to real human demonstration errors with labeled defects; this is load-bearing for transfer to practical curation scenarios.
- [Evaluation results] Downstream evaluation results: The claim that even the best state-trajectory metric recovers only one-third of the downstream gap requires explicit reporting of the number of random seeds, variance, and statistical significance to substantiate the quantitative recovery fraction and the inversion results for the two action-only metrics.
minor comments (2)
- The abstract refers to seven metrics without naming or categorizing them (action-only vs. state-trajectory); adding a summary table would improve immediate clarity.
- Clarify in the methods how 'key moments' for structural error injection are identified or selected, as this affects reproducibility of the testbed.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Testbed construction] Testbed construction (defect injection protocol): The central claims about action-only metrics failing on structural errors rest on the specific synthetic injection of 'wrong action at key moments,' but the manuscript provides no quantitative comparison (e.g., action histogram divergence or state-transition statistics) to real human demonstration errors with labeled defects; this is load-bearing for transfer to practical curation scenarios.
Authors: The testbed uses controlled synthetic injection precisely to isolate known defect types and attribute metric/policy effects without confounding factors. We make no claim that the injected defects match the statistical distribution of real human errors (which would require labeled real data that does not exist in public benchmarks). The core result is that action-only metrics are blind or inverted on structural defects of this form; we will add an explicit limitations paragraph stating the synthetic scope and that transfer to unlabeled real curation remains an open question. revision: partial
-
Referee: [Evaluation results] Downstream evaluation results: The claim that even the best state-trajectory metric recovers only one-third of the downstream gap requires explicit reporting of the number of random seeds, variance, and statistical significance to substantiate the quantitative recovery fraction and the inversion results for the two action-only metrics.
Authors: We agree these details are necessary. The revised manuscript will report the exact number of random seeds (10 per condition), mean and standard deviation of success rates across seeds, and paired t-test p-values for the one-third recovery claim and the two inversion cases. revision: yes
Circularity Check
No circularity; empirical audit with external testbed
full rationale
The paper is an empirical audit that constructs a controlled testbed, injects known defect types into demonstrations, and measures metric performance via separation accuracy and downstream behavior-cloning success rates. No derivations, equations, or first-principles predictions are present that could reduce to fitted inputs or self-referential definitions. Central claims rest on direct experimental comparisons against the externally constructed testbed rather than any self-citation chain or ansatz. This is the most common honest finding for purely empirical work that remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Behavior cloning performance is a monotonic function of demonstration quality when defects are of the tested types.
Reference graph
Works this paper leans on
-
[1]
ALVINN: An autonomous land vehicle in a neural network,
D. A. Pomerleau, “ALVINN: An autonomous land vehicle in a neural network,” inAdvances in Neural Information Processing Systems, 1989
1989
-
[2]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProc. AISTATS, 2011
2011
-
[3]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inProc. RSS, 2023
2023
-
[4]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, “Open X-Embodiment: Robotic learning datasets and RT-X models,” arXiv:2310.08864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
BridgeData V2: A dataset for robot learning at scale,
H. Walkeet al., “BridgeData V2: A dataset for robot learning at scale,” inProc. CoRL, 2023
2023
-
[6]
DROID: A large-scale in-the-wild robot manipu- lation dataset,
A. Khazatskyet al., “DROID: A large-scale in-the-wild robot manipu- lation dataset,” inProc. RSS, 2024
2024
-
[7]
LeRobot: An open-source library for end-to-end robot learning,
R. Cadeneet al., “LeRobot: An open-source library for end-to-end robot learning,” inProc. ICLR, 2026, arXiv:2602.22818
-
[8]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekaret al., “What matters in learning from offline human demonstrations for robot manipulation,” inProc. Conf. on Robot Learn- ing (CoRL), 2021, arXiv:2108.03298
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Isolation forest,
F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation forest,” inProc. IEEE Int. Conf. Data Mining (ICDM), 2008
2008
-
[10]
A robust and sensitive metric for quantifying movement smoothness,
S. Balasubramanian, A. Melendez-Calderon, and E. Burdet, “A robust and sensitive metric for quantifying movement smoothness,”IEEE Trans. Biomed. Eng., vol. 59, no. 8, pp. 2126–2136, 2012
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.