Alpha-RTL: Test-Time Training for RTL Hardware Optimization
Pith reviewed 2026-06-28 07:09 UTC · model grok-4.3
The pith
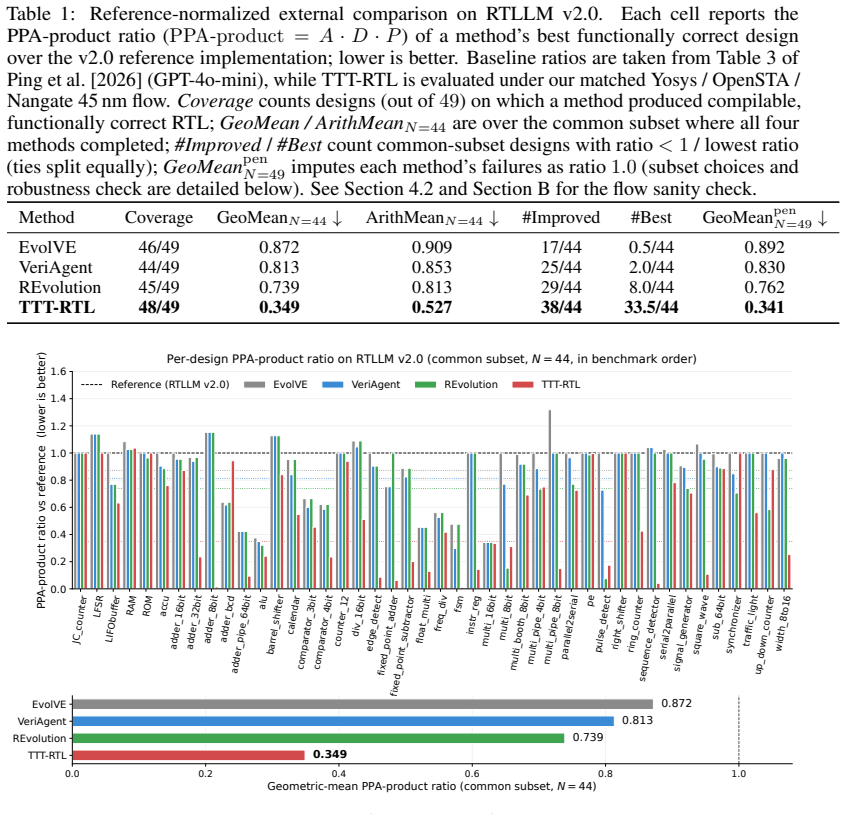
Test-time reinforcement learning lets an LLM policy adapt to per-design EDA feedback, reducing geometric-mean PPA product by 65.1 percent on RTLLM v2.0 benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
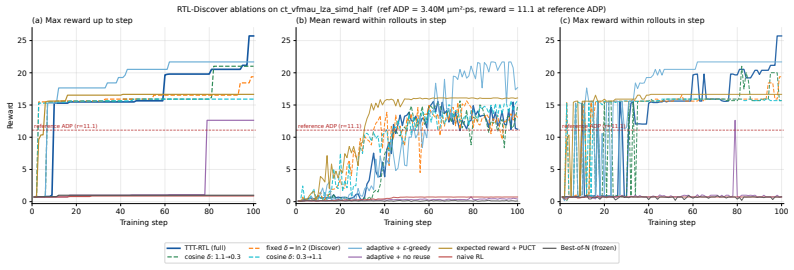
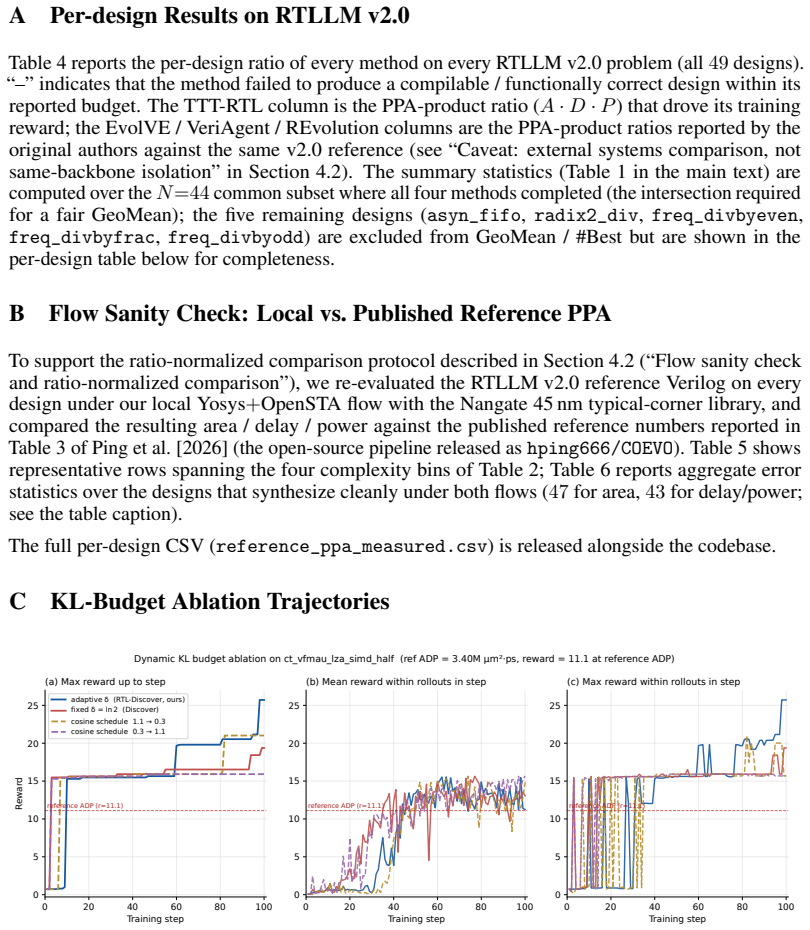
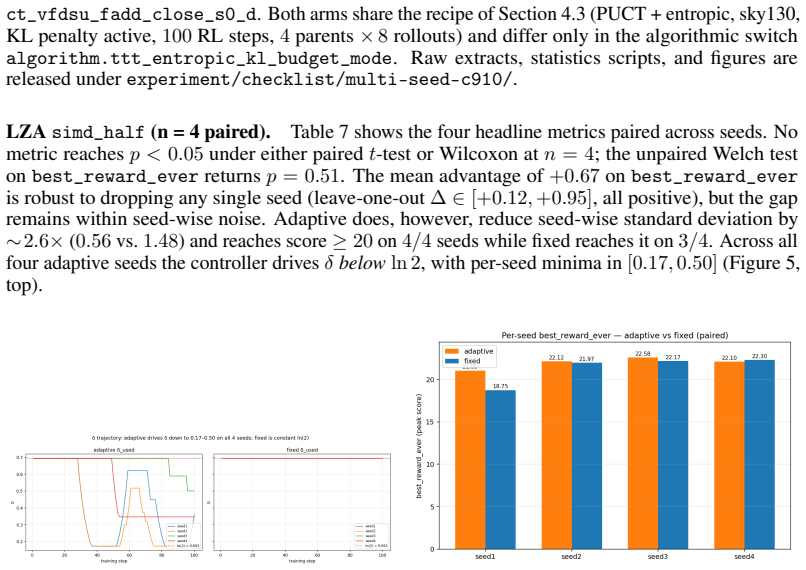
TTT-RTL performs reinforcement learning at test time by sampling candidate RTL implementations, verifying them through syntax and simulation, scoring valid designs with synthesis-derived PPA product, reusing high-reward variants via a PUCT-indexed design-state pool, and updating the LLM policy with an entropic policy-gradient objective; an adaptive KL-budget controller adjusts the entropy constraint using reference KL, effective sample size, and reward saturation signals to stabilize updates under sparse or plateaued EDA rewards, producing a 65.1 percent geometric-mean PPA reduction over the reference on RTLLM v2.0 and a 59.4 percent ADP reduction on the XuanTie C910 leading-zero-anticipatio
What carries the argument
The adaptive KL-budget controller that adjusts the entropy constraint using reference KL, effective sample size, and reward saturation signals to stabilize policy-gradient updates under sparse EDA rewards.
If this is right
- Policy adaptation at test time produces larger PPA gains than frozen-policy agent baselines.
- Reusing high-reward designs through the PUCT-indexed state pool measurably improves sample efficiency.
- The KL-budget controller is required to keep updates stable when rewards plateau or become sparse.
- The overall loop moves LLM-based RTL generation from functional correctness toward physically optimized hardware.
Where Pith is reading between the lines
- The same per-design adaptation loop could be applied to other optimization domains that supply executable but sparse feedback, such as compiler tuning or analog circuit sizing.
- Combining the test-time updates with a stronger offline initialization policy might further accelerate convergence on complex industrial designs.
- The method implies that instance-specific policy adjustment may be more important than scaling the base model size for hardware optimization tasks.
Load-bearing premise
The adaptive KL-budget controller can stabilize policy-gradient updates under the sparse or plateaued rewards typical of EDA feedback for arbitrary RTL problems.
What would settle it
Applying TTT-RTL to a fresh collection of RTL designs where the resulting PPA or ADP values show no improvement or are worse than those obtained by the strongest frozen-policy baseline would falsify the claim of consistent outperformance.
Figures

read the original abstract
Large language models (LLMs) have shown increasing promise in generating functionally correct register-transfer-level (RTL) hardware designs. Recent systems improve further through EDA-integrated reinforcement learning with syntax, simulation, and PPA rewards, but train a general RTL generator before deployment while test-time approaches search with a frozen policy. We instead perform reinforcement learning at test time, allowing the LLM policy to adapt to executable EDA feedback for the specific RTL problem at hand. We propose TTT-RTL, to our knowledge the first per-design test-time training framework that closes the loop between an LLM policy and an EDA pipeline for RTL optimization. TTT-RTL samples candidate implementations, verifies them through syntax checking and simulation, scores valid designs using synthesis-derived PPA product, reuses high-reward variants through a PUCT-indexed design-state pool, and updates the policy with an entropic policy-gradient objective. To stabilize policy updates under sparse or plateaued rewards, we introduce an adaptive KL-budget controller that adjusts the entropy constraint using reference KL, effective sample size, and reward saturation signals. On RTLLM v2.0 under Nangate 45nm, TTT-RTL reduces the geometric-mean PPA product by 65.1% over the reference, outperforming the strongest published frozen-policy agent baseline at 26.1%. On an industrial XuanTie C910 FPU leading-zero-anticipation unit under Sky130, TTT-RTL achieves a 59.4% ADP reduction, and ablations confirm that policy adaptation, state reuse, and KL-budget control each contribute. These results suggest that test-time training with executable EDA feedback can move LLM-based RTL generation beyond functional correctness toward physically optimized hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TTT-RTL, a per-design test-time training framework for LLM-based RTL hardware optimization. It samples candidate designs, verifies them via syntax/simulation, scores via synthesis-derived PPA, reuses high-reward variants in a PUCT-indexed pool, and performs entropic policy-gradient updates at test time. An adaptive KL-budget controller (using reference KL, effective sample size, and reward saturation) is introduced to stabilize updates under sparse or plateaued EDA rewards. Central claims are a 65.1% geometric-mean PPA product reduction on RTLLM v2.0 (outperforming the strongest frozen-policy baseline at 26.1%) and a 59.4% ADP reduction on an industrial XuanTie C910 FPU leading-zero-anticipation unit under Sky130, with ablations attributing gains to adaptation, reuse, and KL control.
Significance. If the reported gains hold and are shown to result from stable test-time policy updates rather than search heuristics alone, the work would provide concrete evidence that closing the LLM-EDA loop at test time can move beyond functional correctness to substantial physical optimization. This would strengthen the case for adaptive rather than frozen policies in hardware generation and could influence EDA-integrated agent research.
major comments (2)
- [Description of the adaptive KL-budget controller] The adaptive KL-budget controller is load-bearing for the central claim that test-time policy-gradient updates (rather than the frozen-policy baseline) produce the 65.1% and 59.4% gains. The manuscript states that the controller adjusts the entropy constraint using reference KL, effective sample size, and reward saturation signals, yet provides no explicit combination rule, weighting, or per-signal ablation; without these, it is not possible to verify that the controller reliably prevents collapse or divergence on the sparse/plateaued reward landscapes typical of EDA feedback.
- [Experimental results and ablations] Ablations are cited to confirm that 'policy adaptation, state reuse, and KL-budget control each contribute,' but the reported results do not isolate the controller's contribution (e.g., no comparison of fixed-KL vs. adaptive-KL budgets or controller failure rates). This leaves open whether the performance edge over the 26.1% frozen-policy baseline can be attributed to the proposed stabilization mechanism.
minor comments (1)
- The abstract positions TTT-RTL as 'to our knowledge the first per-design test-time training framework'; a short related-work paragraph distinguishing it from prior test-time adaptation or online RL methods in other domains would strengthen the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency on the adaptive KL-budget controller. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Description of the adaptive KL-budget controller] The adaptive KL-budget controller is load-bearing for the central claim that test-time policy-gradient updates (rather than the frozen-policy baseline) produce the 65.1% and 59.4% gains. The manuscript states that the controller adjusts the entropy constraint using reference KL, effective sample size, and reward saturation signals, yet provides no explicit combination rule, weighting, or per-signal ablation; without these, it is not possible to verify that the controller reliably prevents collapse or divergence on the sparse/plateaued reward landscapes typical of EDA feedback.
Authors: We agree that the manuscript does not provide the explicit combination rule or weighting scheme for the three signals (reference KL, effective sample size, and reward saturation). In the revision we will add the precise update rule, the weighting coefficients, and per-signal ablation studies showing the effect of each term on stability and final PPA. These additions will allow verification that the controller prevents collapse under sparse EDA rewards. revision: yes
-
Referee: [Experimental results and ablations] Ablations are cited to confirm that 'policy adaptation, state reuse, and KL-budget control each contribute,' but the reported results do not isolate the controller's contribution (e.g., no comparison of fixed-KL vs. adaptive-KL budgets or controller failure rates). This leaves open whether the performance edge over the 26.1% frozen-policy baseline can be attributed to the proposed stabilization mechanism.
Authors: We acknowledge that the existing ablations do not isolate the KL controller via a fixed-KL versus adaptive-KL comparison or report failure rates. The revision will include these experiments on both RTLLM v2.0 and the industrial FPU benchmark, together with failure-rate statistics, to directly attribute gains to the adaptive mechanism rather than search heuristics alone. revision: yes
Circularity Check
No significant circularity; derivation relies on external EDA signals and empirical ablations.
full rationale
The paper describes a test-time RL loop that samples RTL candidates, verifies via syntax/simulation, scores with synthesis PPA, reuses via PUCT pool, and updates via entropic policy gradient stabilized by an adaptive KL controller using reference KL, ESS, and reward saturation. None of these steps reduce by construction to pre-fitted parameters or self-citations; the controller is presented as a composite heuristic whose contribution is checked via ablations on external benchmarks (RTLLM v2.0, XuanTie C910). The central performance numbers (65.1% PPA reduction, 59.4% ADP) are reported as measured outcomes against frozen baselines, not derived quantities. No load-bearing self-citation, self-definitional loop, or fitted-input-renamed-as-prediction appears in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning to Discover at Test Time
Yuksekgonul, Mert and Koceja, Daniel and Li, Xinhao and Bianchi, Federico and McCaleb, Jed and Wang, Xiaolong and Kautz, Jan and Choi, Yejin and Zou, James and Guestrin, Carlos and Sun, Yu , title =. 2026 , doi =. 2601.16175 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Liu, Mingjie and Pinckney, Nathaniel and Khailany, Brucek and Ren, Haoxing , title =. 2023 , doi =. 2309.07544 , eprinttype =
-
[3]
Liu, Shang and Fang, Wenji and Lu, Yao and Zhang, Qijun and Zhang, Hongce and Xie, Zhiyao , title =. 2023 , doi =. 2312.08617 , eprinttype =
-
[4]
Blocklove, Jason and Garg, Siddharth and Karri, Ramesh and Pearce, Hammond , title =. 2023 , doi =. 2305.13243 , eprinttype =
-
[5]
David Silver and Aja Huang and Chris J. Maddison and Arthur Guez and Laurent Sifre and George van den Driessche and Julian Schrittwieser and Ioannis Antonoglou and Veda Panneershelvam and Marc Lanctot and Sander Dieleman and Dominik Grewe and John Nham and Nal Kalchbrenner and Ilya Sutskever and Timothy P. Lillicrap and Madeleine Leach and Koray Kavukcuog...
2016
-
[6]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
David Silver and Thomas Hubert and Julian Schrittwieser and Ioannis Antonoglou and Matthew Lai and Arthur Guez and Marc Lanctot and Laurent Sifre and Dharshan Kumaran and Thore Graepel and Timothy P. Lillicrap and Karen Simonyan and Demis Hassabis , title =. CoRR , volume =. 2017 , url =. 1712.01815 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Proximal Policy Optimization Algorithms
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. CoRR , volume =. 2017 , url =. 1707.06347 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
2025 , doi =. 2501.12948 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , title =. 2024 , doi =. 2402.03300 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , title =. 2024 , doi =. 2408.03314 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Wu, Yangzhen and Sun, Zhiqing and Li, Shanda and Welleck, Sean and Yang, Yiming , title =. 2024 , doi =. 2408.00724 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Zhang, Di and Huang, Xiaoshui and Zhou, Dongzhan and Li, Yuqiang and Ouyang, Wanli , title =. 2024 , doi =. 2406.07394 , eprinttype =
-
[13]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , title =. 2024 , doi =. 2409.19256 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Shang Liu and Yao Lu and Wenji Fang and Mengming Li and Zhiyao Xie , title =. 2025 , url =. 2503.15112 , eprinttype =
-
[16]
Bandit Based
Levente Kocsis and Csaba Szepesv. Bandit Based. Machine Learning:. 2006 , doi =
2006
-
[17]
Rosin , title =
Christopher D. Rosin , title =. Annals of Mathematics and Artificial Intelligence , volume =. 2011 , doi =
2011
-
[18]
Efros and Moritz Hardt , title =
Yu Sun and Xiaolong Wang and Zhuang Liu and John Miller and Alexei A. Efros and Moritz Hardt , title =. Proceedings of the 37th International Conference on Machine Learning , series =. 2020 , publisher =
2020
-
[19]
ChipSeek: Optimizing Verilog Generation via EDA-Integrated Reinforcement Learning
Zhirong Chen and Kaiyan Chang and Zhuolin Li and Cangyuan Li and Xinyang He and Chujie Chen and Mengdi Wang and Haobo Xu and Yinhe Han and Huawei Li and Ying Wang , title =. 2025 , doi =. 2507.04736 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Hsin, Wei-Po and Deng, Ren-Hao and Hsieh, Yao-Ting and Huang, En-Ming and Hung, Shih-Hao , title =. 2026 , doi =. 2601.18067 , eprinttype =
-
[21]
Wang, Yaoxiang and Shi, Qi and Li, ShangZhan and Hu, Qingguo and Yin, Xinyu and Guo, Bo and Han, Xu and Sun, Maosong and Su, Jinsong , title =. 2026 , doi =. 2603.17613 , eprinttype =
-
[22]
Min, Kyungjun and Cho, Kyumin and Jang, Junhwan and Kang, Seokhyeong , title =. 2025 , note =. doi:10.48550/ARXIV.2510.21407 , url =. 2510.21407 , eprinttype =
-
[23]
Ping, Heng and Zhang, Peiyu and Li, Shixuan and Yang, Wei and Cheng, Anzhe and Duan, Shukai and Zhang, Xiaole and Bogdan, Paul , title =. 2026 , doi =. 2604.15001 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Junyang Lin and Jingren Zhou and others , title =. 2025 , doi =. 2505.09388 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph E. Gonzalez and Hao Zhang and Ion Stoica , title =. Proceedings of the 29th Symposium on Operating Systems Principles (. 2023 , doi =. 2309.06180 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Proceedings of the 47th International Symposium on Computer Architecture (
Chen Chen and Xiaoyan Xiang and Chang Liu and Yunhai Shang and Ren Guo and Dongqi Liu and Yimin Lu and Ziyi Hao and Jiahui Luo and Zhijian Chen and Chunqiang Li and Yu Pu and Jianyi Meng and Xiaolang Yan and Yuan Xie and Xiaoning Qi , title =. Proceedings of the 47th International Symposium on Computer Architecture (. 2020 , doi =
2020
-
[27]
Proceedings of the 21st Austrian Workshop on Microelectronics (Austrochip) , year =
Clifford Wolf and Johann Glaser , title =. Proceedings of the 21st Austrian Workshop on Microelectronics (Austrochip) , year =
-
[28]
Proceedings of the 29th Asia and South Pacific Design Automation Conference (
Yao Lu and Shang Liu and Qijun Zhang and Zhiyao Xie , title =. Proceedings of the 29th Asia and South Pacific Design Automation Conference (. 2024 , doi =. 2308.05345 , eprinttype =
-
[29]
Mingjie Liu and Teodor-Dumitru Ene and Robert Kirby and Chris Cheng and Nathaniel Pinckney and Rongjian Liang and Jonah Alben and Himyanshu Anand and Sanmitra Banerjee and Ismet Bayraktaroglu and Bryan Catanzaro and Arjun Chaudhuri and Brucek Khailany and Haoxing Ren and others , title =. 2023 , doi =. 2311.00176 , eprinttype =
-
[30]
Betterv: Con- trolled verilog generation with discriminative guidance,
Zehua Pei and Hui-Ling Zhen and Mingxuan Yuan and Yu Huang and Bei Yu , title =. Proceedings of the 41st International Conference on Machine Learning (. 2024 , publisher =. 2402.03375 , eprinttype =
-
[31]
Eric Zelikman and Yuhuai Wu and Jesse Mu and Noah D. Goodman , title =. Advances in Neural Information Processing Systems 35 (. 2022 , url =. 2203.14465 , eprinttype =
-
[32]
Chhabria and Mateus Fogaça and Soheil Hashemi and Abdelrahman Hosny and Andrew B
Tutu Ajayi and Vidya A. Chhabria and Mateus Fogaça and Soheil Hashemi and Abdelrahman Hosny and Andrew B. Kahng and Minsoo Kim and Jeongsup Lee and Uday Mallappa and Marina Neseem and Geraldo Pradipta and Sherief Reda and Mehdi Saligane and Sachin S. Sapatnekar and Carl Sechen and Mohamed Shalan and William Swartz and Lutong Wang and Mingyu Woo and Bang X...
2019
- [33]
-
[34]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo and Kaiyan Zhang and Li Sheng and Shang Qu and Ganqu Cui and Xuekai Zhu and Haozhan Li and Yuchen Zhang and Xinwei Long and Ermo Hua and Biqing Qi and Youbang Sun and Zhiyuan Ma and Lifan Yuan and Ning Ding and Bowen Zhou , title =. Advances in Neural Information Processing Systems 38 (. 2025 , url =. 2504.16084 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Jiahe Shi and Zhengqi Gao and Ching-Yun Ko and Duane Boning , title =. 2025 , url =. 2511.12033 , eprinttype =
-
[36]
2025 , howpublished =
Yaoyu Zhu and contributors , title =. 2025 , howpublished =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.